📄 Spectral or Spatial? Leveraging Both for Speaker Extraction in Challenging Data Conditions
#语音分离 #多通道 #波束成形 #鲁棒性
✅ 7.0/10 | 前25% | #语音分离 | #波束成形 | #多通道 #鲁棒性
学术质量 5.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Aviad Eisenberg(Bar-Ilan大学工程学院, OriginAI)
- 通讯作者:未说明
- 作者列表:Aviad Eisenberg(Bar-Ilan大学��程学院, OriginAI)、 Sharon Gannot(Bar-Ilan大学工程学院)、 Shlomo E. Chazan(OriginAI)
💡 毒舌点评
这篇论文的亮点在于其训练策略的巧妙设计,通过故意引入错误的注册信息(随机DOA或随机说话人声音)进行联合训练,并辅以一个轻量级分类器,使模型学会了在一种线索失效时自动“偏信”另一种,这在处理真实世界不完美数据时非常实用。不过,论文的“新意”更多体现在工程组合与稳健性训练上,其核心架构(U-Net + FiLM)并非独创,且实验中评估的“SOTA”基线相对有限,主要与自身的单通道和仅空间基线对比,缺乏与近年来其他复杂多通道分离方法的直接较量。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开权重。
- 数据集:使用Librispeech和DNS数据集合成,未提及是否公开合成后的具体数据。
- Demo:未提及在线演示。
- 复现材料:论文详细描述了模型架构(U-Net + SA + FiLM)、特征提取(RI STFT)、训练策略(三种配置并行)、损失函数(SI-SDR + CE)、优化器(AdamW)和主要超参数(LR=0.0001, Batch=14),提供了较好的复现基础。具体的网络层数、维度等细节未说明。
- 论文中引用的开源项目:未明确提及依赖的特定开源代码库。
- 开源计划:论文中未提及开源计划。
📌 核心摘要
这篇论文旨在解决多通道说话人提取任务中,当用于引导模型的参考信息(如说话人语音注册或目标说话人方向DOA)存在错误或噪声时,系统性能严重下降的问题。其核心方法是设计一个集成网络,同时接受频谱参考(一段注册语音)和空间参考(DOA)作为输入,并通过一个场景分类器动态评估两者的可靠性,从而在训练中学会优先利用更准确的信息源,甚至在某一参考完全失效时仍能稳定工作。与已有方法通常只依赖单一类型线索或简单结合不同,该方法强调了在错误参考下的鲁棒性,并通过专门的训练策略(引入随机错误参考进行联合训练)来实现这一点。实验结果表明,在包括说话人空间接近(CSP)、同性别混合(SGM)、随机DOA参考(SGM-RDR)、随机频谱参考(SGM-RSR)和低信噪比频谱注册(SGM-LSSE)等六种挑战性场景下,所提模型(SI-SDRi)均优于或持平于仅使用频谱或仅使用空间信息的基线模型。例如,在SGM-RSR(频谱参考错误)场景下,所提模型达到8.86 dB,显著优于纯空间基线(8.33 dB);在SGM-RDR(DOA参考错误)场景下,所提模型达到7.8 dB,而纯频谱基线为6.83 dB,纯空间基线则完全失效。该工作的实际意义在于提升了说话人提取系统在真实复杂声学环境(参考信息易出错)下的可靠性。其主要局限性在于,分类器训练时模拟的错误类型(随机DOA或随机说话人)可能与实际推理时遇到的错误分布不完全匹配,这可能影响其泛化能力。
🏗️ 模型架构
模型基于一个增强的U-Net架构,集成了自注意力机制,并采用特征线性调制(FiLM)来融合参考信息。整体流程分为编码、参考融合与条件化、瓶颈处理和解码几个阶段。
完整输入输出流程:
- 输入:多通道混合信号(STFT的实部和虚部,维度 [T, K, 2J])、单通道频谱注册信号(维度 [T, K, 2])、目标说话人DOA(标量,通过嵌入表示)。
- 输出:提取出的目标说话人单通道信号(STFT的实部和虚部,维度 [T, K, 2])。
主要组件与数据流:
- 混合信号编码器:处理多通道混合信号。它由6个卷积层堆叠而成,每层后接批归一化(Batch Normalization)和PReLU激活函数。随后,通道维和频率维被合并,通过一个全连接层降维。这部分的功能是从混合信号中提取高级的时空特征表示。
- 频谱注册编码器:架构与混合信号编码器类似,但输入是单通道的注册语音。其输出向量在时间帧维度上进行平均池化,生成一个固定长度的向量,作为频谱注册的表示。这个表示旨在从音色上引导模型找到目标说话人。
- 空间注册表示:DOA(θd)通过一个查找表(Lookup Table)学习其嵌入表示,将其转化为一个与频谱注册嵌入同维度的向量。
- 统一嵌入与FiLM条件化:频谱注册嵌入与空间注册嵌入相加,形成一个统一的“参考”嵌入向量。这个向量被送入两个前馈网络,生成γ和β参数,对混合信号编码器的输出(混合嵌入)进行特征线性调制(FiLM)。数学上为:
FiLM(x,r) = embx * γ(embr) + β(embr)。这个操作在每一个时间帧上独立进行,其动机是让参考信息能灵活地调制混合信号在不同帧、不同频段上的激活,从而突出目标说话人。 - 瓶颈处理与自注意力:混合嵌入经过一个自注意力(Self-Attention, SA)层,以捕获长程依赖关系。随后,一个轻量级分类器(由三层前馈网络构成)对该自注意力输出进行分类,判断当前场景属于三类中的哪一类:(i)两种参考均有效,(ii)仅空间参考有效,(iii)仅频谱参考有效。
- 第二次自注意力与引导:这是关键的设计。模型执行第二次自注意力处理。这一次,自注意力模块的输入除了原始嵌入,还接收由分类器输出嵌入(
embc)和统一参考嵌入共同调制(再次通过FiLM)得到的引导信号(FiLM(r, c))。通过一个特殊的前缀token,模型被告知这是第二次迭代。这个机制允许分类器的决策动态地影响自注意力机制,引导模型“关注”更可靠的参考信息。 - 解码器:采用转置卷积层,通过跳跃连接(Skip Connections)与编码器的相应层相连,以融合不同尺度的特征,最终重建出目标说话人的单通道时频表示。
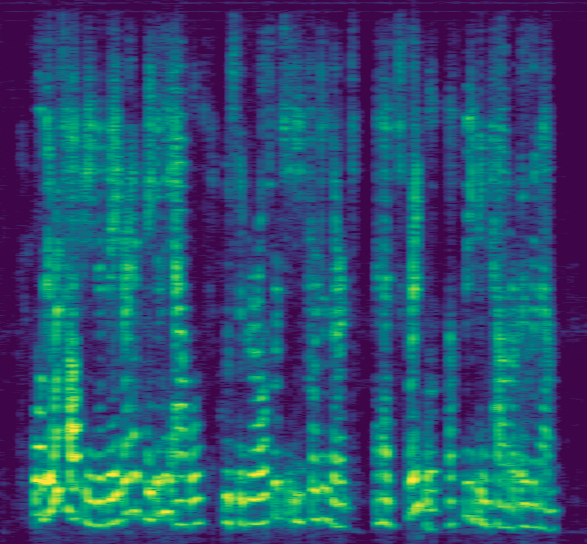
图1清晰地展示了上述流程。左侧是混合信号和频谱注册信号分别进入各自的编码器。空间注册通过查找表得到嵌入,并与频谱嵌入相加。这个和作为FiLM的条件,去调制混合嵌入(“乘号”所示)。中间是两次自注意力(SA)处理,第一次SA的输出送入分类器(Cls)。分类器的输出与参考嵌入结合,再次调制原始参考嵌入,作为第二次SA的条件。最后通过解码器输出。
💡 核心创新点
- 双线索集成与自适应权衡:提出一个端到端模型,明确地将频谱注册和空间DOA作为两种独立的线索输入,并通过一个分类器网络学习动态评估其可靠性,实现自适应融合。此前方法多侧重于利用单一线索或将两者简单拼接,缺乏在一种线索失效时的自适应退化机制。
- 面向鲁棒性的联合训练策略:设计了包含三种配置(正确配置、随机DOA、随机频谱注册)的联合训练流程。这种策略迫使模型在训练时就必须处理错误的参考信息,从而学习到一种“不信任”不可靠线索的能力,显著提升了模型在推理时面对不完美参考的鲁棒性。这是该论文最核心的贡献。
- 轻量级分类器引导机制:引入一个专门的分类模块,不仅用于训练时的损失计算,其输出嵌入更在推理时通过第二次自注意力机制来直接引导模型的注意力焦点。这为模型提供了一种显式的、可解释的方式来处理不确定的参考信息。
🔬 细节详述
- 训练数据:
- 数据集:使用Librispeech数据集(干净语音)和DNS数据集(噪声)合成训练数据。论文中未提及具体子集。
- 规模:合成20,000个训练样本,1,000个验证样本,1,000个测试样本。每个样本长4秒。
- 预处理:下采样至8kHz。STFT使用256点汉明窗,50%重叠,仅取前129个频率bin。使用RI(实部-虚部)特征。
- 数据增强:通过合成过程隐式增强,包括随机SNR(5-20 dB)、随机混响(RT60 0.2-0.8秒)、随机房间尺寸、随机声源位置(半径1-4米)。
- 损失函数:
- 主损失:SI-SDR损失(
L_SI-SDR),用于衡量提取信号与真实目标信号的相似度,是语音分离任务的标准损失。 - 辅助损失:交叉熵损失(
L_CE),用于训练场景分类器。 - 总损失:
L_overall = Σ_{a={d, dθrnd, dsrnd}} L_SI-SDR(˜s_d, ˆ˜s_a) + L_CE。即三种训练配置下的SI-SDR损失之和,再加上分类器损失。
- 主损失:SI-SDR损失(
- 训练策略:
- 优化器:AdamW。
- 学习率:0.0001。
- 批大小:14。
- 训练步数/轮数:未说明。
- 调度策略:未说明。
- 联合训练:每个批次同时包含三种配置的数据(正确配置、随机DOA、随机频谱注册),确保模型同时学习处理正确和错误的参考。
- DOA扰动:为增加对小DOA误差的鲁棒性,在训练时对正确DOA(θd)加入±4°、±2°或0°的离散均匀扰动。
- 关键超参数:未明确给出模型大小、层数、隐藏维度等具体数值。仅描述了编码器为6个卷积层,瓶颈有1个自注意力层。
- 训练硬件:论文中未提及。
- 推理细节:
- DOA估计:训练了一个与混合信号编码器结构相似的小型网络,用于从混合信号中估计两个说话人的DOA。该网络使用二元交叉熵损失训练,仅预测语音源的DOA。
- DOA-频谱注册匹配:提出了一种基于提取信号质量的匹配方法。分别用正确频谱+随机DOA、随机噪声+正确DOA提取两对信号,然后通过计算SI-SDR来确定最佳的DOA与频谱注册配对(公式6)。
- 正则化或稳定训练技巧:批归一化(Batch Normalization)用于卷积层后,以稳定训练。PReLU用于避免“死神经元”。
📊 实验结果
主要实验结果(SI-SDRi, 单位:dB): 论文在六种挑战性测试场景下,对比了五种模型变体。下表完整复现了论文中的Table 1:
| 测试集 / 模型 | 未处理 | 仅频谱 | 仅空间 | 所提方法 | 所提方法 w/o (3b) | 所提方法 w. DOA推理 |
|---|---|---|---|---|---|---|
| CSP (空间接近) | -0.76 | 6.85 | -3.36 | 7.58 | 5.9 | 6.4 |
| MSP (中等接近) | -0.79 | 8.14 | 7.19 | 10.3 | 9.73 | 7.51 |
| SGM (同性别) | -0.77 | 6.83 | 8.33 | 9.58 | 9.61 | 7.95 |
| SGM-RDR (随机DOA) | -0.77 | 6.83 | × | 7.8 | -3.41 | × |
| SGM-RSR (随机频谱) | -0.77 | × | 8.33 | 8.86 | 7.01 | 5.23 |
| SGM-LSSE (低信噪比频谱) | -0.77 | -2.08 | 8.33 | 9.24 | 7.6 | 5.48 |
关键结论:
- 鲁棒性验证:在参考信息错误(SGM-RDR, SGM-RSR, SGM-LSSE)的场景下,所提方法均表现最佳或接近最佳。例如,在SGM-RSR(频谱注册错误)下达到8.86 dB,优于仅空间基线的8.33 dB;在SGM-RDR(DOA错误)下达到7.8 dB,而仅空间基线完全失效(×)。
- 分类器的作用:对比“所提方法”与“所提方法 w/o (3b)”(即训练时不引入错误参考)。在DOA错误(SGM-RDR)场景下,后者性能急剧下降至-3.41 dB,而前者为7.8 dB,证明训练策略和分类器对处理错误空间信息至关重要。
- DOA推理的影响:当使用从混合信号估计的DOA(可能不准确)时(“所提方法 w. DOA推理”),性能在依赖空间信息多的场景(如MSP)下降更明显(10.3 -> 7.51 dB),而在依赖频谱信息多的场景(如CSP)下降较少(7.58 -> 6.4 dB),这符合预期。
图表分析:
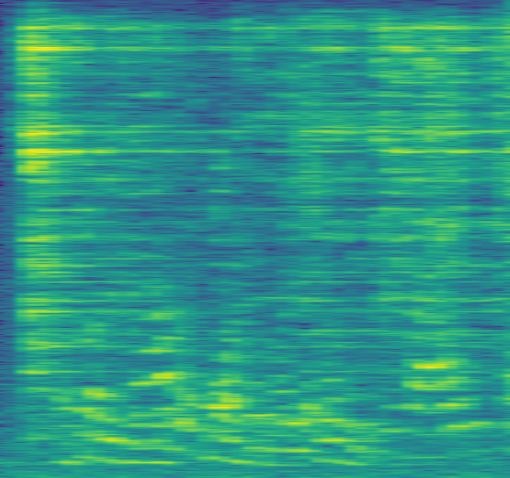 图2展示了在两个说话人(分别位于54°和122°)固定位置下,不同DOA注册角度对模型性能的影响。
图2展示了在两个说话人(分别位于54°和122°)固定位置下,不同DOA注册角度对模型性能的影响。
- 上图:对比了四种配置的SI-SDRi。纯频谱模型(蓝色线)性能平稳,不受DOA误差影响。纯空间模型(橙色线)仅在DOA正确匹配目标说话人且与干扰者分开时性能高,否则急剧下降。所提方法(有分类器)(绿色线)即使在DOA注册指向干扰者时,仍能保持较高的SI-SDRi(约8-10 dB),展现了极强的鲁棒性。所提方法(无分类器)(红色线)在DOA错误时性能显著下降,证明分类器是关键。
- 中图与下图:显示了分类器对两个说话人的输出概率。当DOA注册接近真实目标说话人角度(54°或122°)时,对应说话人的概率高;当DOA注册指向其他方向时,模型能降低该注册的置信度,从而依赖频谱信息。这直观地解释了模型“权衡”线索的机制。
⚖️ 评分理由
- 学术质量:5.0/7:论文针对实际问题(参考信息不准确)提出了有效的解决方案,技术路线(双线索融合+鲁棒训练)正确且合理。实验设计全面,消融实验充分证明了各个组件(分类器、训练策略)的有效性。创新性主要体现在方法组合与稳健性设计上,而非基础架构的突破。
- 选题价值:1.5/2:多通道说话人提取是音频前端处理的核心技术之一,提升其在非理想条件下的鲁棒性具有很高的实用价值,符合当前领域从理想假设走向复杂真实场景的研究趋势。
- 开源与复现加成:0.5/1:论文详细描述了模型结构、训练数据合成方法、损失函数和关键超参数,为复现提供了充足的信息。然而,未提供代码、预训练模型或具体训练时长等细节,略有减分。