📄 SpatialNet-Echo: Real-Time Acoustic Echo Cancellation via Integrated Narrow-Band and Cross-Band Processing
#语音增强 #声学回声消除 #端到端 #流式处理 #Mamba
✅ 7.5/10 | 前25% | #语音增强 | #自回归模型 | #声学回声消除 #端到端
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Ziyin Chen(浙江大学,杭州,中国)
- 通讯作者:Xiaofei Li(西湖大学 & 西湖高等研究院,杭州,中国)
- 作者列表:Ziyin Chen(浙江大学),Xiaofei Li(西湖大学 & 西湖高等研究院)
💡 毒舌点评
论文巧妙地将Mamba架构引入AEC的窄带处理,解决了传统RNN和Transformer的长序列建模效率问题,是一个有价值的工程实践。但其高达28.31G的MACs和1.71M参数的“标准版”模型,离真正的“实时”轻量化部署似乎还有距离,论文中“轻量级变体”的性能也仅比对比方法略好,且未公开代码,让“可部署性”的宣称打了折扣。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开模型权重。
- 数据集:使用了公开数据集(DNS5录音,ICASSP 2023 AEC Challenge盲测集和部分训练数据),但如何获取完整的训练混合脚本未说明。
- Demo:未提及在线演示。
- 复现材料:论文提供了关键的训练细节(数据构成、损失函数、优化器、超参数值、模型结构图),但缺乏硬件配置、完整训练步骤、预处理脚本和检查点等信息。
- 论文中引用的开源项目:引用了Adam优化器、Mamba模型、oSpatialNet、ULCNetAENR等,但未明确说明这些作为依赖项的开源实现是否被直接使用。
- 开源计划:论文中未提及开源计划。
📌 核心摘要
这篇论文旨在解决实时通信中声学回声消除(AEC)的难题,特别是传统窄带处理方法的局限性和信号的非线性失真。论文提出了SpatialNet-Echo,这是首个集成窄带时间建模与跨带谱一致性的端到端实时AEC模型。其核心方法是结合时间-频率卷积块(TFCB)捕捉联合谱时特征、挤压-激励(SE)块进行动态通道加权,以及基于Mamba的窄带处理器进行高效的长上下文建模。同时,采用了一个结合SI-SNR、幅度谱和实/虚部损失的相位感知混合损失函数。
与已有方法相比,该模型的创新点在于首次将上述组件统一到一个针对AEC设计的端到端架构中,强调窄带与跨带处理的协同作用。在ICASSP 2023 AEC挑战赛盲测集上,SpatialNet-Echo在远端单讲(ST-FE)场景下取得了SOTA的4.81 EMOS,在双讲(DT)场景下取得了竞争性的4.59 EMOS和4.05 DMOS,优于或持平于其他四个SOTA方法。
该工作的实际意义在于推动了基于深度学习的端到端AEC模型的发展,并验证了Mamba在该任务中的有效性。主要的局限性在于其标准模型的计算复杂度(28.31G MACs)仍然较高,且论文未提供开源代码和模型,限制了其复现性和直接应用。
表1:与SOTA方法在ICASSP 2023 AEC挑战赛盲测集上的性能对比
| 模型 | 参数量 (M) | MACs (G) | ST-FE EMOS | DT EMOS | DT DMOS | ST-NE DMOS |
|---|---|---|---|---|---|---|
| Baseline [21] | 1.30 | - | 4.66 | 4.14 | 3.35 | 4.03 |
| DeepVQE [24] | 7.50 | - | 4.69 | 4.70 | 4.29 | - |
| ULCNetAENR [8] | 0.69 | 0.10 | 4.73 | 4.54 | 3.58 | 4.15 |
| Align-ULCNet [9] | 0.69 | 0.10 | 4.77 | 4.60 | 3.80 | 4.28 |
| SpatialNet-Echo-lite | 0.78 | 7.44 | 4.70 | 4.51 | 3.86 | 4.09 |
| SpatialNet-Echo | 1.71 | 28.31 | 4.81 | 4.59 | 4.05 | 4.17 |
表2:消融实验结果
| 模型 | 参数量 (M) | MACs (G) | 损失函数 | ST-FE EMOS | DT EMOS | DT DMOS | ST-NE DMOS |
|---|---|---|---|---|---|---|---|
| oSpatialNet | 1.67 | 27.59 | SI-SNR | 4.36 | 4.47 | 3.91 | 4.20 |
| oSpatialNet | 1.67 | 27.59 | Hybrid | 4.41 | 4.47 | 3.98 | 4.22 |
| +TFCB | 1.70 | 28.31 | SI-SNR | 4.55 | 4.51 | 4.03 | 4.28 |
| +SE | 1.68 | 27.59 | SI-SNR | 4.71 | 4.57 | 3.95 | 4.10 |
| SpatialNet-Echo | 1.71 | 28.31 | SI-SNR | 4.74 | 4.59 | 4.01 | 4.21 |
| SpatialNet-Echo | 1.71 | 28.31 | Hybrid | 4.81 | 4.59 | 4.05 | 4.17 |
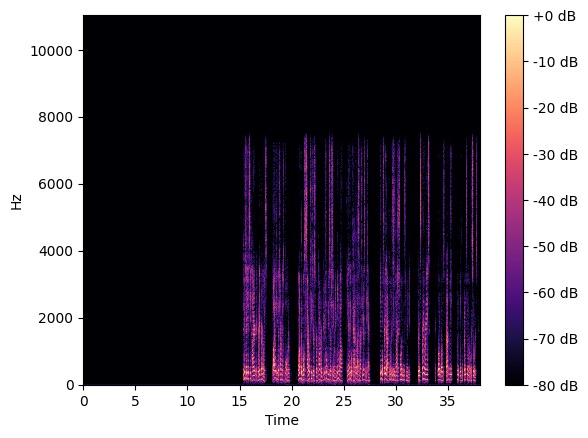
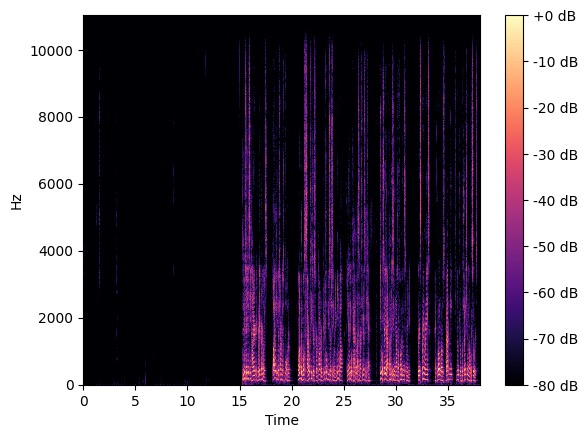 图2展示了在一个双讲场景下,原始麦克风信号(a)、参考信号(b)、基线模型估计的近端语音(c)以及本文提出模型估计的近端语音(d)的时频谱图。可以直观地看出,本文提出的方法在从混合信号中提取近端语音方面优于基线模型,其时频能量表示更为完整和准确。
图2展示了在一个双讲场景下,原始麦克风信号(a)、参考信号(b)、基线模型估计的近端语音(c)以及本文提出模型估计的近端语音(d)的时频谱图。可以直观地看出,本文提出的方法在从混合信号中提取近端语音方面优于基线模型,其时频能量表示更为完整和准确。
🏗️ 模型架构
SpatialNet-Echo是一个端到端的流式AEC网络,其整体架构(图1(a))输入为参考信号和麦克风信号的实部虚部频谱 [Xr, Xi, Yr, Yi],输出为估计的近端语音实部虚部频谱 [Ŝr, Ŝi],最终通过iSTFT恢复时域信号。其核心是一个由输入卷积层(T-Conv1d)、N个重复的跨带块-SE块-窄带块组合构成的编码器-解码器结构。
- (a) 整体结构:展示了数据流:STFT -> T-Conv1d -> N次重复的[跨带块 -> SE块 -> 窄带块] -> Linear -> iSTFT。其中,跨带块和窄带块通过SE块进行连接和通道注意力加权。
- (b) 时间-频率卷积块 (TFCB):一个轻量级的残差单元。它首先通过逐点2D卷积(P-Conv2D)调整通道数,然后通过一个3x3的深度可分离卷积(D-Conv2D)进行时频分析。残差连接确保了信息流的畅通。该模块以较少的参数高效提取时频联合特征。
- (c) 跨带块:该模块在每个时间帧独立处理所有频率带。它包含两个频率维度的卷积模块(F-Conv Module)和一个全带线性模块(Full-band Linear Module)。频率卷积模块(含LayerNorm, F-GConv1d, PReLU)建模相邻频率间的相关性;全带线性模块(含压缩、F-Linear、恢复)则捕获全局的跨频率依赖关系。这种设计旨在学习回声的结构化频谱模式。
- (d) 挤压-激励 (SE) 块:作为通道注意力机制,它位于跨带块和窄带块之间。通过全局平均池化(公式2)压缩空间-时间信息,再通过两层全连接网络(公式3)生成通道权重,用于动态增强近端语音通道、抑制回声主导通道(公式4)。
- (e) 窄带块:该模块对每个频率点独立沿时间轴处理,共享参数。其核心是两个顺序堆叠的Mamba模块(含残差连接)。Mamba模块内部对输入
X先进行深度可分离CNN处理,再通过选择性状态空间模型(SSM)进行建模。论文明确指出,Mamba的输入依赖参数A(t), B(t), C(t)使其能在回声主导期增强回声路径跟踪,并在双讲时抑制被污染的频带,且其线性时间复杂度保证了实时性。
关键设计选择:该架构的核心创新在于集成。跨带块负责捕捉频谱维度上的全局结构(应对非线性失真的宽带特性),窄带块(Mamba)负责捕捉每个频率上时间维度的长程依赖(高效回声路径跟踪),而SE块则在二者之间进行智能的通道信息分配。这种分工协作的设计是针对AEC任务中同时存在的谱间和时序复杂性的直接回应。
💡 核心创新点
- 集成的窄带与跨带处理架构:首次在AEC领域明确地将针对跨频率相关性(跨带)和单频率时序建模(窄带)的模块进行端到端集成。之前的方法要么只做窄带建模,要么混合方法中线性滤波器处理全局但难以处理非线性。此架构通过分工与协作,能更全面地建模回声路径。
- 基于Mamba的高效窄带时序建模:将新兴的选择性状态空间模型(Mamba)应用于AEC的窄带处理,替代了传统的RNN或Transformer。Mamba的线性复杂度解决了长序列建模的效率瓶颈,其输入依赖的参数使得模型能动态适应回声状态变化(如在回声强和双讲时调整行为),提升了跟踪精度和鲁棒性。
- 相位感知的混合损失函数:设计了
L_Hybrid = L_SI-SNR + λ(L_MAG + L_RI)的损失函数。除了优化时域质量(SI-SNR)和幅度谱,还显式优化实部和虚部,确保了估计语音的相位一致性。这对于AEC任务中保持近端语音质量和消除伪影至关重要,消融研究证实了其在复杂场景(如双讲)下的提升效果。
🔬 细节详述
- 训练数据:使用了动态混合生成的方式。近端语音来自DNS5数据集;回声数据包含ICASSP AEC挑战赛提供的真实全频带远端单讲录音和合成全频带回声信号;噪声数据来自DNS5。混合时,信噪比(SNR)范围[0, 40]dB,信回比(SER)范围[-10, 15]dB。所有录音重采样至24kHz,每条时长10秒。
- 损失函数:
L_Hybrid = L_SI-SNR + λ(L_MAG + L_RI)。其中L_SI-SNR是负的尺度不变信噪比,优化时域波形质量;L_MAG是估计与目标幅度谱的均方误差;L_RI是估计与目标实部及虚部的均方误差。权重λ=1,通过验证实验确定。 - 训练策略:使用Adam优化器,初始学习率1e-3,采用指数学习率衰减(γ=0.98)。批大小为16。训练轮数未说明。
- 关键超参数:
- STFT:汉宁窗,帧长20ms,帧移10ms。
- 模型通道数:T-Conv1d输出通道H=64;跨带块和窄带块输入通道C=96;全带线性模块压缩通道C’=8。
- SE块:缩减比r=16。
- Mamba模块:状态维度D=16,卷积核大小K=4。
- 架构重复次数:N=8。
- 轻量级变体(SpatialNet-Echo-lite):H=32, C=48, D=8, K=2。
- 训练硬件:论文中未提及具体GPU型号、数量和训练时长。
- 推理细节:作为流式模型,以帧移10ms进行处理。解码策略未涉及(因为是回归模型)。
- 正则化技巧:使用了BatchNorm和LayerNorm。
📊 实验结果
主要评估在ICASSP 2023 AEC挑战赛的盲测集上进行,使用AECMOS(包含EMOS和DMOS)作为非侵入式评估指标。
- 与SOTA方法对比(见上文表1):
- 远端单讲 (ST-FE):SpatialNet-Echo以4.81 EMOS排名第一,比次优的Align-ULCNet(4.77)高0.04,展示了强大的回声抑制能力。
- 双讲 (DT):SpatialNet-Echo的EMOS为4.59,与Align-ULCNet(4.60)持平;DMOS为4.05,略低于Align-ULCNet(4.28),但论文称其“具有竞争力”。这表明在保留近端语音质量方面仍有提升空间,但回声抑制表现优秀。
- 近端单讲 (ST-NE):DMOS为4.17,与Align-ULCNet(4.28)和DeepVQE(4.29)接近,表明能较好地保留干净的近端语音。
- 计算复杂度:SpatialNet-Echo的MACs(28.31G)远高于ULCNet系列(0.10G),但低于DeepVQE(未报告)。轻量级变体(7.44G MACs)在性能上接近标准方法,但MACs仍高于ULCNet系列。
- 消融实验(见上文表2):
- 模块贡献:在基线oSpatialNet上逐步添加TFCB(+0.19 ST-FE EMOS)和SE块(+0.35 ST-FE EMOS)均有显著提升,证明了各模块的有效性。
- 损失函数贡献:使用混合损失相比仅用SI-SNR,在ST-FE EMOS上提升0.07,在DT DMOS上提升0.04,验证了其在保持相位一致性和复杂场景下质量的重要性。
- 整体提升:所有组件和混合损失的综合应用,使ST-FE EMOS从4.36提升至4.81(+0.45),DT DMOS从3.91提升至4.05(+0.14),证明了架构设计的合理性。
- 可视化分析(图2): 图2的时频图直观显示,在双讲场景下,本文提出模型的输出(d)比基线模型(c)更好地抑制了回声成分,同时更完整地保留了近端语音的时频结构,与定量结果一致。
⚖️ 评分理由
- 学术质量:6.0/7:论文提出了一个逻辑严密、组件创新的集成架构,技术实现正确。实验在标准挑战赛数据集上进行,对比了多个SOTA方法,并提供了详细的消融研究,结果可信。然而,核心思想(窄带+跨带)在前作oSpatialNet中已有体现,对AEC的适配属于工程优化,且计算复杂度较高,创新性未达到突破级别。
- 选题价值:1.5/2:AEC是实时通信系统的关键技术,持续面临双讲、非线性失真等挑战。本论文针对这些痛点提出改进方案,并考��了轻量化部署,具有明确的应用前景和较高的实用价值,对音频处理领域的研究者和工程师相关性很强。
- 开源与复现加成:0.0/1:论文详细描述了数据来源、模型结构和超参数,为复现提供了蓝图。但是,论文中未提及任何开源代码、预训练模型权重、数据生成脚本的链接或获取方式,也未提供训练硬件和完整训练时长信息,这使得完全复现该工作存在较高门槛,因此加成分为0。