📄 Spatially Aware Self-Supervised Models for Multi-Channel Neural Speaker Diarization
#说话人分离 #自监督学习 #麦克风阵列 #多通道 #语音活动检测
🔥 8.0/10 | 前25% | #说话人分离 | #自监督学习 #麦克风阵列 | #自监督学习 #麦克风阵列
学术质量 8.0/7 | 选题价值 8.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:未说明(论文按顺序列出作者,但未明确标注第一作者)
- 通讯作者:未说明
- 作者列表:Jiangyu Han(布尔诺理工大学),Ruoyu Wang(中国科学技术大学),Yoshiki Masuyama(三菱电机研究所),Marc Delcroix(NTT公司),Johan Rohdin(布尔诺理工大学),Jun Du(中国科学技术大学),Lukáš Burget(布尔诺理工大学)
💡 毒舌点评
这篇论文巧妙地利用WavLM的早期层注入空间信息,避免了从头训练多通道模型的高成本,方法设计轻量且通用。不过,其核心创新更多是工程上的“缝合”而非理论突破,且第二阶段的融合策略依赖于第一阶段的通道注意力权重,限制了端到端优化的可能。
🔗 开源详情
- 代码:是。提供了GitHub仓库链接:https://github.com/BUTSpeechFIT/DiariZen。
- 模型权重:未提及。
- 数据集:未提及新数据集。使用五个公开数据集:AMI, AISHELL-4, AliMeeting, NOTSOFAR-1, CHiME-6。
- Demo:未提及。
- 复现材料:论文详细说明了模型配置、训练和评估细节。代码开源是主要复现材料。
- 论文中引用的开源项目:
- DiariZen [5]
- WavLM [3]
- pyannote.audio [28]
- VBx聚类 [35]
- WPE [33]
- BeamformIt [34]
- 论文中未提及开源计划以外的其他内容。
📌 核心摘要
- 问题:当前基于自监督学习(如WavLM)的说话人分离系统通常在单通道数据上预训练,无法有效利用多通道录音中的空间信息。传统的后融合方法(如DOVER-Lap)计算成本高且空间信息利用不充分。
- 核心方法:在现有DiariZen管线(结合WavLM的EEND与向量聚类)基础上,提出一种轻量级方法:在预训练单通道WavLM的早期层中插入可学习的“通道通信模块”,使其能感知空间信息。该模块对麦克风数量和阵列拓扑结构通用。在聚类阶段,提出利用通道注意力权重来融合多通道说话人嵌入。
- 创新点:a) 在特征提取器内部注入空间感知能力,而非依赖后期融合;b) 使用结构化剪枝后的WavLM,在保持性能的同时大幅降低计算量;c) 提出基于注意力权重的说话人嵌入融合策略,无需额外训练。
- 主要实验结果:在五个公开数据集(AMI, AISHELL-4, AliMeeting, NOTSOFAR-1, CHiME-6)上进行评估。
- 表1(Oracle聚类下):所提的ChannelAttention(ChAtt)多通道模型在所有数据集上均优于单通道基线,且使用剪枝WavLM(18.8M参数)的性能接近未剪枝版本(94.4M参数)。
System WavLM Pruned DER (%) AMI Single-channel - - 13.5 Single-channel - ✓ 13.3 ChAtt - - 13.1 ChAtt - ✓ 12.9 TAC - ✓ 12.8 - 表2(VBx聚类下):所提方法的“attentive weighted fusion”变体在CHiME-6数据集上将DER降至27.5%,接近当时SOTA系统(27.5% vs ~25%),且计算效率优于DOVER-Lap基线。
System DER (%) AMI Single-channel 15.3 DOVER-Lap 14.7 Average probs & embs 14.9 ChAtt, DOVER-Lap 14.8 ChAtt, average embed. 14.9 ChAtt, att. argmax 14.9 ChAtt, att. weighted fusion 14.8 - 图2(推理时间):显示“attentive argmax”方法的推理时间显著低于DOVER-Lap,因为其仅从注意力最高的通道提取嵌入。
- 图3(注意力权重):分析了CHiME-6上的通道注意力权重,显示不同层对通道的关注度不同,且模式随输入变化,表明模型在利用空间线索。
- 图4(麦克风依赖性):分析了不同数据集上各单通道性能的方差,解释了为何在AliMeeting和CHiME-6上多通道增益更大(其录音配置导致通道间性能差异显著)。
- 表1(Oracle聚类下):所提的ChannelAttention(ChAtt)多通道模型在所有数据集上均优于单通道基线,且使用剪枝WavLM(18.8M参数)的性能接近未剪枝版本(94.4M参数)。
- 实际意义:提供了一种高效、通用且易于实施的框架,将强大的单通道自监督预训练模型扩展到多通道说话人分离场景,性能超越传统后期融合方法,且计算成本更低,更适合实际部署。
- 主要局限性:a) 第二阶段的说话人嵌入提取仍基于单通道,未利用多通道信息(论文指出这是未来工作);b) 所提方法在录音条件均匀的数据集(如AMI)上提升有限,其优势主要体现在空间线索明显的复杂场景。
🏗️ 模型架构
本文的工作建立在DiariZen系统(一个EEND-VC管线)之上,并对其进行了多通道扩展。整体架构分为两个阶段:
第一阶段:多通道端到端神经分离(Multi-channel EEND)
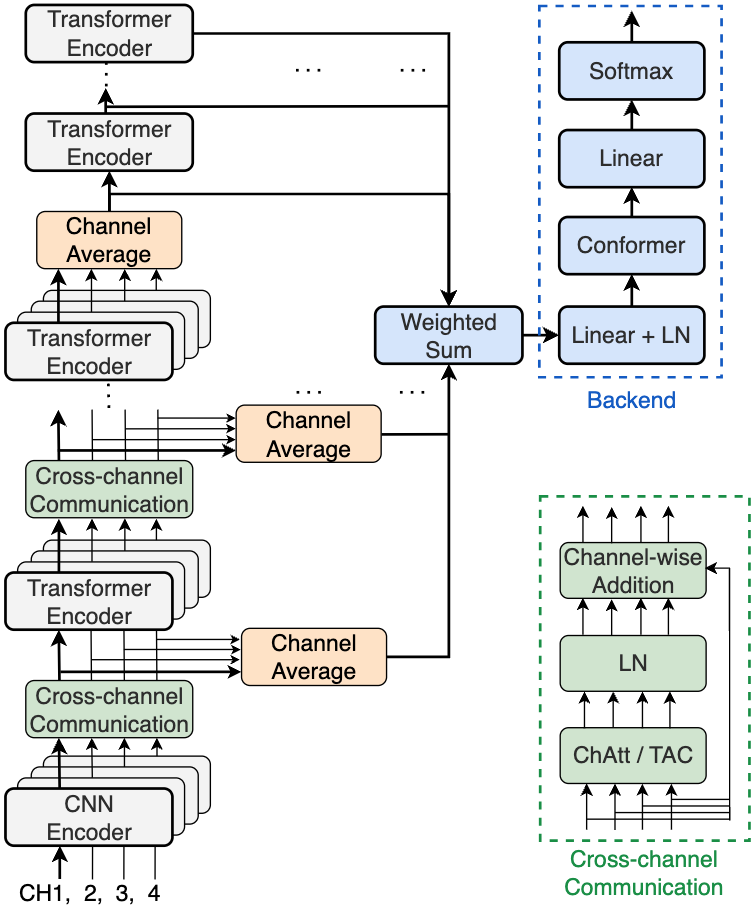
- 输入:C个麦克风通道的音频。
- 前端特征提取(多通道WavLM):
- 选择WavLM模型的前几层(论文中为前4层)在每个通道上并行运行,参数共享。
- 在每一层之后,执行通道平均(Channel Average),将C个通道的输出序列平均为一个序列。
- 在这些早期层的通道平均之后,插入跨通道通信模块(Cross-channel Communication Blocks)。论文考察了两种变体:ChannelAttention(ChAtt) 和Transform-Average-Concatenate(TAC)。ChAtt使用多头自注意力层在通道间交换信息;TAC则使用共享线性层、PReLU、通道平均、拼接和投影来混合信息。
- 为了减少计算量,后续的WavLM层直接在平均后的单通道表示上运行。
- 所有WavLM层的输出通过SUPERB风格的加权求和组合成一个最终的序列表示。
- 后端(Conformer):将上述加权和后的序列输入Conformer后端,输出帧级别的说话人活动(以幂集类别形式建模)。
设计动机:通过在早期层插入轻量级通信模块,使模型在保持预训练知识的同时,能逐步学习融合跨通道的空间线索。初始化这些新模块为恒等映射,确保训练从稳定的单通道基线开始。
第二阶段:说话人嵌入聚类
- 嵌入提取:虽然第一阶段是多通道输入,但说话人嵌入的提取仍为单通道。对每个通道,分别用单通道嵌入提取器从检测到的每个说话人的语音段中提取嵌入。
- 嵌入融合(本文创新):提出利用第一阶段训练好的ChannelAttention模块中的注意力权重(S ∈ ℝ^{T×H×C×C})来融合各通道的嵌入。
- 将注意力权重在帧(T)和头(H)维度上平均,得到全局表示 S_g ∈ ℝ^{C×C}。
- 将 S_g 按查询(行)维度平均,得到每个通道的权重 ˆS_g ∈ ℝ^C。
- 基于这些权重,对同一说话人在同一本地窗口内的各通道嵌入进行融合,策略包括:attentive argmax(选择权重最高通道的嵌入)或 attentive weighted fusion(计算加权平均)。
- 聚类:使用VBx聚类方法,将融合后(或平均后)的说话人嵌入序列映射到全局说话人身份。
💡 核心创新点
在预训练模型早期层注入空间感知模块:
- 局限:传统方法要么在后期融合各通道输出(如DOVER-Lap),要么需要设计并训练全新的多通道模型,无法有效利用强大的预训练单通道模型。
- 如何起作用:在参数共享的并行WavLM早期层后插入通道通信模块(ChAtt/TAC),让模型在特征提取过程中逐步整合空间信息。
- 收益:在不破坏原始预训练表示的前提下,使模型适配多通道输入,并在五个数据集上一致优于单通道基线。
兼容并优化使用结构化剪枝的WavLM:
- 局限:多通道扩展通常会显著增加计算量,使模型更臃肿。
- 如何起作用:将之前工作中提出的结构化剪枝WavLM(80%稀疏度)应用于多通道场景。
- 收益:实验(表1)证明,剪枝后的多通道模型(18.8M参数)性能与未剪枝模型(94.4M参数)相当,实现了效率与性能的良好平衡。
无需额外训练的基于空间注意力的嵌入融合:
- 局限:简单的通道平均或为每个通道独立聚类再融合(DOVER-Lap)无法智能地利用空间线索。
- 如何起作用:直接利用多通道EEND模型内部学到的通道注意力权重来指导说话人嵌入的加权融合或选择。
- 收益:在CHiME-6等复杂场景中显著降低DER(表2),且计算开销低于DOVER-Lap(图2)。
🔬 细节详述
- 训练数据:在由五个公开数据集(AMI, AISHELL-4, AliMeeting, NOTSOFAR-1, CHiME-6)组成的复合数据集上训练和评估。对AISHELL-4划分了验证集。对CHiME-6应用了WPE和BeamformIt预处理。
- 损失函数:论文未明确说明,但引用的DiariZen系统[5]和pyannote管线[28,29]通常使用幂集多类交叉熵损失(Powerset Multi-class Cross Entropy Loss)。
- 训练策略:超参数与[5]相同。学习率、优化器等细节未说明。新插入的跨通道通信模块初始化为恒等映射(LayerNorm的scale和bias设为零)。
- 关键超参数:WavLM Base+(参数量94.4M)及其剪枝版本(80%稀疏,参数量18.8M)。跨通道通信模块插入在WavLM的前四层,输入/隐藏维度为768/256,ChannelAttention的头数为8。聚类使用VBx。
- 训练硬件:未说明。
- 推理细节:使用单张A5000 GPU进行推理时间分析。批大小为32。在聚类阶段,DOVER-Lap需要为每个通道独立运行EEND和嵌入提取/聚类,然后融合结果;而所提方法(如attentive argmax)仅运行一次EEND并选择性提取嵌入,更高效。
- 评估指标:主要使用Diarization Error Rate (DER)。对于CHiME-6使用0.25秒的宽容度(collar),其他数据集不使用。还报告了跨数据集的宏平均DER(Macro DER)。
📊 实验结果
- 主要Benchmark与指标:在五个多通道说话人分离数据集上,使用DER作为主要指标。关键对比基线包括:单通道系统、DOVER-Lap融合系统、平均概率与嵌入系统。
- 与最强基线/SOTA对比:在CHiME-6数据集上,所提的“attentive weighted fusion”方法达到27.5%的DER,论文声称这“接近SOTA系统[27](该系统未分离语音)”,同时设计更简单、效率更高。
- 关键消融实验与数字变化:
- 模型剪枝的影响(表1):在多通道条件下,使用剪枝WavLM(✓)的系统性能与未剪枝系统非常接近,证实了剪枝的有效性。
- 通信模块选择(表1):ChannelAttention(ChAtt)和TAC性能相当,最终因简单性选择ChAtt。
- 嵌入融合策略对比(表2):在VBx聚类下,“attentive weighted fusion”(27.5%)优于“average embed.”(28.5%)、“att. argmax”(29.5%)以及“ChAtt, average embed.”(28.5%)和DOVER-Lap(30.9%)。
- 不同条件下的细分结果:
- 数据集间差异:在AliMeeting和CHiME-6上多通道方法增益显著,而在AMI、AISHELL-4和NOTSOFAR-1上增益较小。图4的分析表明,这与各数据集录音中单通道性能的方差有关。
- 推理效率(图2):显示了各阶段(EEND、嵌入提取、聚类)的耗时。嵌入提取是主要瓶颈。DOVER-Lap需对所有通道重复整个流程,而“attentive argmax”方法通过仅从一个通道提取嵌入,大幅减少了总时间。
- 注意力权重可视化(图3):展示了CHiME-6一个音频块上,不同WavLM层(第2层和第4层)的通道注意力权重模式,证明模型学习到了依赖于输入的空间线索。
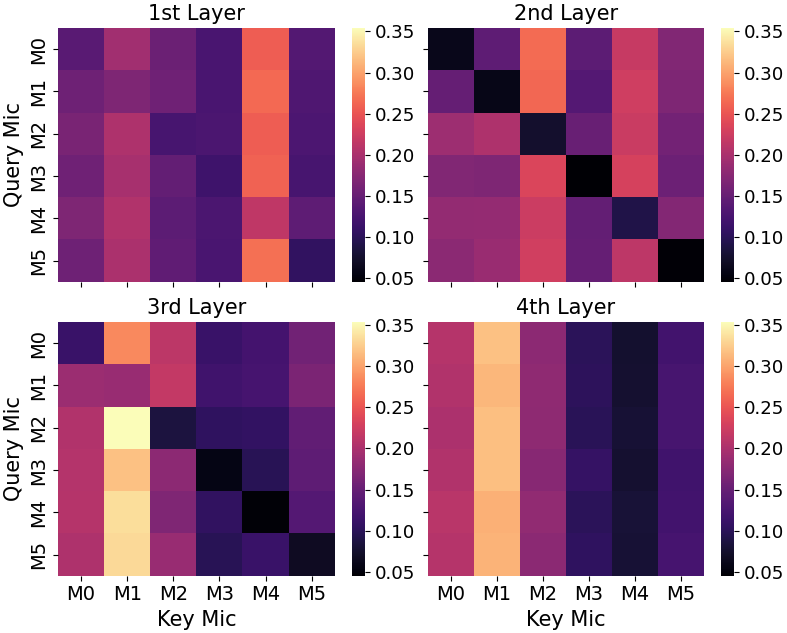 图2: 各种方法在不同阶段的推理时间比较。CA代表ChannelAttention。结果表明,所提方法(尤其是attentive argmax)显著比DOVER-Lap高效。
图2: 各种方法在不同阶段的推理时间比较。CA代表ChannelAttention。结果表明,所提方法(尤其是attentive argmax)显著比DOVER-Lap高效。
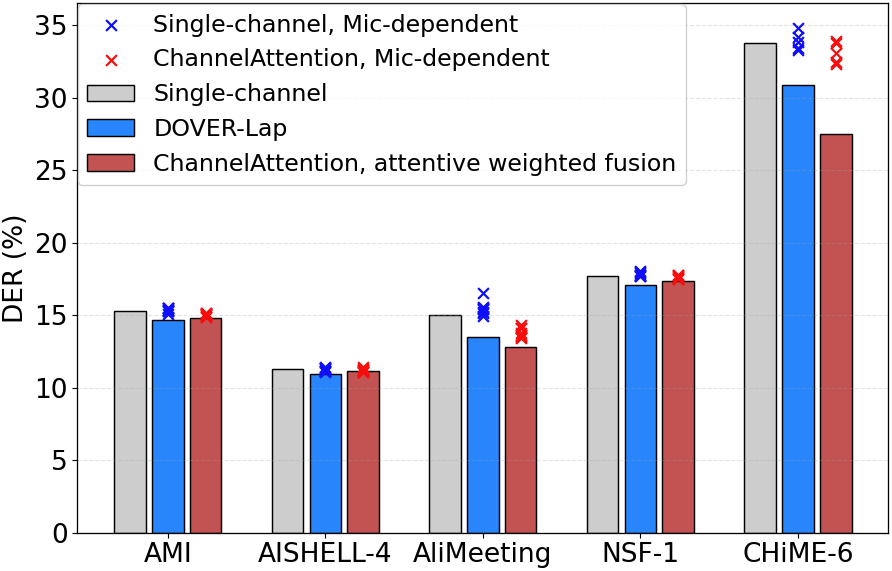 图3: 在CHiME-6数据集上,通道注意力权重在帧和头维度上平均后的层间分布。不同层表现出不同的行为模式,表明模型在利用空间线索。
图3: 在CHiME-6数据集上,通道注意力权重在帧和头维度上平均后的层间分布。不同层表现出不同的行为模式,表明模型在利用空间线索。
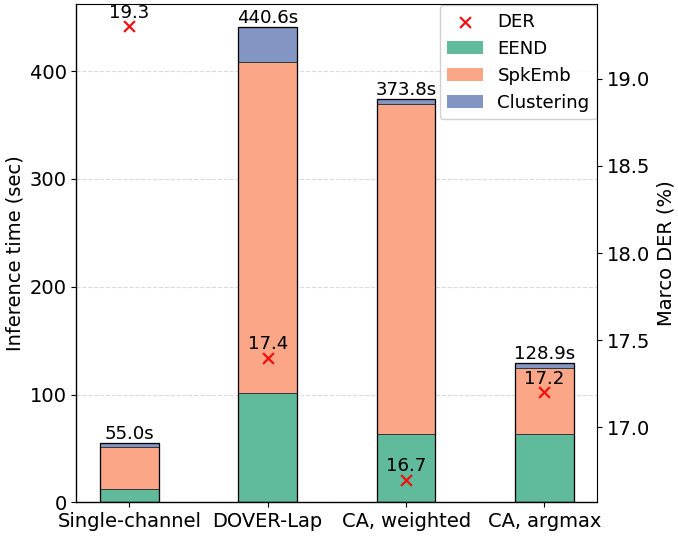 图4: 单麦克风依赖(Mic-dependent)性能、单通道系统、DOVER-Lap和ChAtt(attentive weighted fusion)的DER对比。AliMeeting和CHiME-6上各通道性能方差大,解释了多通道方法的增益来源。
图4: 单麦克风依赖(Mic-dependent)性能、单通道系统、DOVER-Lap和ChAtt(attentive weighted fusion)的DER对比。AliMeeting和CHiME-6上各通道性能方差大,解释了多通道方法的增益来源。
⚖️ 评分理由
学术质量:6.0/7
- 创新性:将自监督模型适配到多通道场景的方法有工程创新性,嵌入融合策略新颖。
- 技术正确性:方法设计合理,初始化策略避免了灾难性遗忘,实验设置严谨。
- 实验充分性:在五个代表性数据集上进行了全面评估,包括Oracle聚类和实际聚类场景,并进行了充分的消融研究(模型剪枝、模块选择、融合策略)和深入分析(注意力权重、麦克风依赖性)。
- 证据可信度:提供了开源代码,实验结果可复现。与强基线对比,数据详实。
选题价值:1.5/2
- 前沿性:多通道神经说话人分离是当前活跃的研究方向,尤其是在会议转录等实际应用中。
- 潜在影响与应用空间:该方法计算效率高、通用性强,易于集成到现有管线中,有直接的工业应用前景。
- 读者相关性:对于从事语音处理、说话人分离、多通道信号处理的读者非常相关。
开源与复现加成:0.5/1
- 代码:提供了明确的代码仓库链接(https://github.com/BUTSpeechFIT/DiariZen)。
- 模型权重:未提及公开权重。
- 数据集:使用公开数据集,未提供新数据集。
- 复现材料:论文详细描述了模型架构、训练策略、超参数和评估设置,代码公开有助于复现。但训练的具体超参数(如学习率调度)细节在论文正文中未完全展开。