📄 SPAM: Style Prompt Adherence Metric for Prompt-Based TTS
#语音合成 #对比学习 #模型评估 #大语言模型 #预训练
✅ 7.0/10 | 前50% | #语音合成 | #对比学习 | #模型评估 #大语言模型
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Chanhee Cho†(Chung-Ang University)
- 通讯作者:Bugeun Kim(Chung-Ang University)
- 作者列表:Chanhee Cho†(Chung-Ang University)、Nayeon Kim†(Chung-Ang University)、Bugeun Kim(Chung-Ang University)。其中†表示“同等贡献”。
💡 毒舌点评
亮点:精准抓住了基于提示的语音合成评估中的核心痛点——现有方法缺乏“合理性”(与人类判断一致)和“忠实性”(对语义变化敏感),并设计了针对性的解决方案。短板:实验说服力打了折扣,既没有与当前流行的“LLM-as-a-judge”评估范式(如用GPT-4o直接打分)进行对比,也缺少对自身方法在极端或边界案例下的鲁棒性分析,使得结论的普适性存疑。
🔗 开源详情
根据论文全文内容:
- 代码:论文中未提及代码链接或开源计划。
- 模型权重:论文中未提及公开SPAM模型权重。
- 数据集:论文使用了TextrolSpeech、SpeechCraft和LibriTTS-P,但未说明是否为所用全部数据,也未提供独有数据集。
- Demo:未提及。
- 复现材料:未给出详细的训练超参数、配置文件或检查点。
- 引用的开源项目/模型:论文中明确提及并依赖了以下开源工作:WavLM、X-Vector、Llama-3.1、TextrolSpeech数据集、SpeechCraft数据集、LibriTTS-P数据集。
📌 核心摘要
- 要解决的问题:现有的基于提示的语音合成(Prompt-based TTS)系统缺乏可靠、自动化的指标来评估合成语音对文本提示(尤其是风格描述)的遵循程度。传统MOS评估成本高昂,现有自动方法或依赖主观的嵌入聚类分析,或使用可能不忠实于提示内容的LLM评估。
- 方法核心:提出Style Prompt Adherence Metric(SPAM),一个受CLAP启发的对比学习框架。它将语音波形、说话人特征和转录文本编码后融合,再通过并行分支提取和强化全局波形、语速、音高、能量等声学属性特征,最终与使用Llama-3编码的文本提示嵌入计算相似度。
- 与已有方法相比新在哪里:a) 显式地因子化并监督学习关键的声学属性(音高、语速、能量),确保评估基于这些具体特征;b) 针对一个提示可能对应多个语音(多正样本)的问题,采用监督对比损失(SupCon)替代标准CLAP损失,提升训练稳定性;c) 使用强大的Llama-3作为文本编码器,以更好地区分提示中的细微语义差别。
- 主要实验结果:实验包括合理性(与人类MOS的相关性)和忠实性(对正/负提示的区分能力)。合理性:在TextrolSpeech数据集上,SPAM(WavLM版)与MOS的线性相关系数(LCC)为0.584,高于基线RA-CLAP(0.520)。忠实性:SPAM在Adherence Rate(AR)上达到0.862,表明它能有效区分正负提示;配对t检验显示,SPAM能接受负提示得分显著低于原提示的假设(H2),且对正提示的评分与原提示无显著差异(拒绝H1),优于RA-CLAP。详见表1。
| 实验 | 指标 | 数据集 | SPAM (WavLM) | SPAM (CLAP) | RA-CLAP |
|---|---|---|---|---|---|
| 合理性 | LCC | TextrolSpeech | 0.584 | 0.554 | 0.520 |
| LCC | LibriTTS-P | 0.580 | 0.516 | 0.429 | |
| 忠实性 | AR | TextrolSpeech | 0.862 | 0.841 | 0.852 |
| AR | LibriTTS-P | 0.771 | 0.766 | 0.750 | |
| 原提示均值 | TextrolSpeech | 0.361±0.153 | 0.039±0.026 | 0.400±0.324 | |
| 正提示均值 (p值) | TextrolSpeech | 0.357±0.143 (-2.025) | 0.035±0.025 (-3.699*) | 0.380±0.312 (-3.479) | |
| 负提示均值 (p值) | TextrolSpeech | 0.050±0.221 (-20.145) | -0.005±0.030 (-17.538) | -0.020±0.219 (-16.912*) |
表1:论文中关于SPAM合理性和忠实性的核心实验结果。SPAM (WavLM)在各项关键指标上表现最佳。
- 实际意义:为Prompt-based TTS的自动化、标准化评估提供了一个可选的、可解释的度量工具有助于加速该领域模型的迭代与比较。
- 主要局限性:实验仅基于两个开源数据集,未覆盖更多样化的提示风格或非英语语言;基线对比未包含当前先进的“LLM-as-a-Judge”评估方法,未能证明其绝对优越性;未公开代码和模型,限制了研究的可复现性和社区采纳。
🏗️ 模型架构
SPAM的整体架构(见图1)由三个主要模块组成,旨在将语音和文本提示映射到同一语义空间并计算相似度得分。
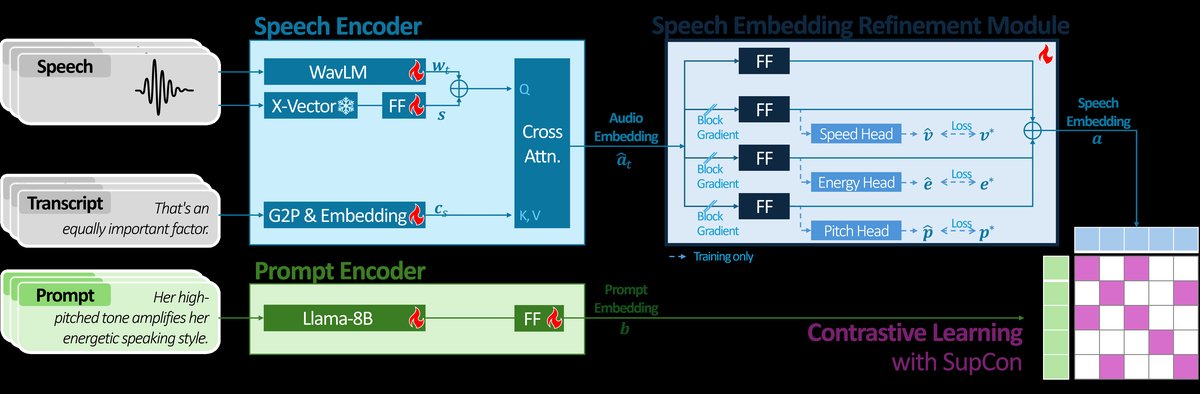 图1:SPAM架构图。 该图展示了数据从输入到输出相似度分数的完整流程。
图1:SPAM架构图。 该图展示了数据从输入到输出相似度分数的完整流程。
语音编码器:负责生成信息丰富的音频嵌入。它融合了三种信息源:
- 波形:使用预训练的WavLM模型处理16kHz音频,得到时间步级别的嵌入
w_t。 - 说话人:使用冻结的X-Vector模型提取说话人特征,再通过一个前馈适配器映射到与
w_t相同的维度,得到s。 - 转录文本:通过字素到音素模块和嵌入查找表,得到转录文本嵌入
c_s。 - 融合:使用交叉注意力层,以
w_t + s为查询,c_s为键/值,计算出每个时间步的融合音频嵌入â_t。
- 波形:使用预训练的WavLM模型处理16kHz音频,得到时间步级别的嵌入
提示编码器:将文本提示
b编码为提示嵌入。论文采用Llama-3.1 8B模型配合一个前馈适配器来实现,旨在精细区分提示中的风格描述。语音嵌入细化模块:对音频嵌入
â_t进行声学属性特异性的处理和增强。这是SPAM区别于通用CLAP模型的关键。- 它包含四个并行分支:全局波形分支、语速分支、能量分支和音高分支。
- 全局波形分支:生成一个全局表示,起到正则化训练、防止过拟合的作用。
- 声学属性分支:每个分支通过一个前馈层将
â_t转换为属性特定的嵌入。同时,每个分支都连接一个辅助预测头(语速用方差预测器,能量和音高用MLP),预测时间级别的属性值(û_t,ê_t,p̂_t)。这些辅助预测头引导各分支学习正确的声学信号。 - 聚合:将四个分支的输出嵌入按时间步相加,然后跨时间步平均,得到最终的语音嵌入
a。
相似度计算:在推理时,计算语音嵌入
a和提示嵌入b之间的余弦相似度,作为SPAM分数。
💡 核心创新点
- 引入监督对比损失处理多正样本问题:在训练中,一个文本提示可能对应多个风格相似的语音(多正样本),标准InfoNCE损失无法有效处理。SPAM采用监督对比损失(SupCon),利用风格键(Style Key)定义正样本对,能更好地从一个提示的多个正例中学习,提升了训练的稳定性和指标的“忠实性”。
- 显式声学属性因子分解与监督:通过并行分支和辅助预测头,显式地将语音的声学特征(音高、语速、能量)解耦并分别监督学习。这迫使模型在评估时真正关注这些被提示指定的具体属性,而不仅仅是整体的相似度,增强了评估的“合理性”和可解释性。
- 基于强大语言模型的提示编码器:采用Llama-3.1 8B作为文本编码器,相比传统的BERT等模型,能更深入、更细致地理解提示中微妙的语气、情绪等风格描述,从而更准确地与语音特征进行对齐。
🔬 细节详述
- 训练数据:使用TextrolSpeech和SpeechCraft两个数据集的训练集合并,仅使用高质量的ground-truth语音数据。未说明具体样本数量或预处理细节。
- 损失函数:总损失为加权和:
L = λcLcon + λpLδ(ˆp) + λvLδ(ˆv) + λeLδ(ˆe)。Lcon:监督对比损失(SupCon),在音频-文本嵌入对之间和文本-音频嵌入对之间对称计算,Lcon = (Lsup(a, b) + Lsup(b, a)) / 2。Lδ:Huber损失,分别用于预测的语速(ˆp)、语速方差(ˆv)和能量(ˆe)与其真实值的回归。未说明损失权重λc, λp, λv, λe的具体取值。
- 训练策略:未说明学习率、优化器、batch size、训练步数/轮数、warmup等具体策略。
- 关键超参数:
- 波形编码器:WavLM 或 CLAP编码器。
- 提示编码器:Llama-3.1 8B(带适配器)。
- 隐藏维度
h:未说明。 - 层数、注意力头数等:未说明(但依赖预训练的WavLM和Llama-3)。
- 训练硬件:未说明。
- 推理细节:直接计算余弦相似度作为分数。未说明是否涉及温度缩放或其他后处理。
- 正则化/稳定训练技巧:未明确提及。引入全局波形分支可视为一种正则化手段。使用冻结的预训练模型(X-Vector)和适配器也是一种常见的稳定训练方法。
📊 实验结果
实验在两个视角展开:合理性(与人类MOS的相关性)和忠实性(对语义变化的区分能力)。数据集为TextrolSpeech和LibriTTS-P。
- 合理性实验结果 与人类MOS的皮尔逊相关系数(LCC)是核心指标。
| 模型/数据集 | TextrolSpeech (LCC) | LibriTTS-P (LCC) |
|---|---|---|
| SPAM (WavLM) | 0.584 | 0.580 |
| SPAM (CLAP) | 0.554 | 0.516 |
| RA-CLAP | 0.520 | 0.429 |
表2:不同模型与指标在整体测试集上与MOS的LCC。SPAM (WavLM) 在两个数据集上均取得最高相关性。
论文进一步分析了在不同TTS模型生成语音上的表现(见原表2),显示SPAM的相关性在多数情况下更稳定(例如,在真实语音上约0.72),而RA-CLAP在跨数据集时波动较大。
- 忠实性实验结果 通过比较模型对原始提示、语义等价的正提示和语义不等价的负提示的评分来评估。
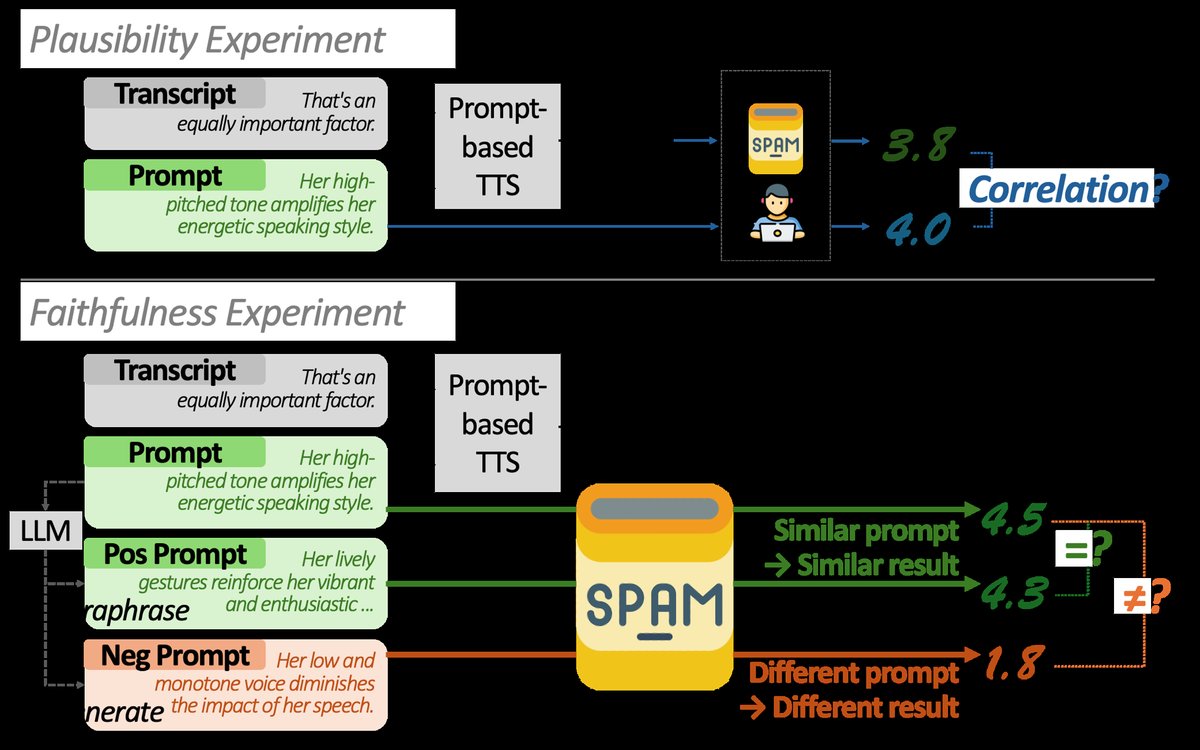 图2:合理性与忠实性实验示意图。 左图展示了合理性实验中计算MOS与指标相关性的过程;右图展示了忠实性实验中生成正、负提示并检验指标反应的过程。
图2:合理性与忠实性实验示意图。 左图展示了合理性实验中计算MOS与指标相关性的过程;右图展示了忠实性实验中生成正、负提示并检验指标反应的过程。
关键指标包括:
- Adherence Rate (AR):正提示得分 > 负提示得分的平均概率。SPAM (WavLM) AR最高(TextrolSpeech: 0.862, LibriTTS-P: 0.771)。
- 配对t检验:
- H1 (µ+ ≠ µ0):检验正提示均分与原提示是否相等。一个忠实的指标应拒绝此假设(即认为无差异)。SPAM (WavLM) 在TextrolSpeech上p=-2.025,未达显著(通常|t|>1.96),故“✓”表示拒绝H1;在LibriTTS-P上p=3.200**,未能拒绝,这是其一个小缺陷。而SPAM (CLAP) 和 RA-CLAP 在多个情况下无法拒绝H1。
- H2 (µ- < µ0):检验负提示均分是否低于原提示。所有指标都成功接受此假设(p值显著为负,*),说明它们都能识别出负面提示。
消融研究:论文简要指出,在LibriTTS-P上,将SPAM的损失从SupCon换成InfoNCE后,模型无法通过H1检验(p < 0.05),即正提示得分与原提示产生显著差异,这反向证明了SupCon损失对于保证“忠实性”的关键作用。
⚖️ 评分理由
学术质量:5.5/7
- 创新性(适中):解决了具体且重要的评估问题,引入SupCon和声学属性分解是有价值的设计,但属于现有框架(CLAP、监督对比学习)的改进与适配,非范式级创新。
- 技术正确性(良好):架构设计合理,有清晰的动机和辅助任务支持。
- 实验充分性(一般):实验设计了合理性和忠实性两个维度,有创新性。但基线单一(仅RA-CLAP),未与更通用的LLM评估器对比;数据集规模未明;消融实验(SupCon vs InfoNCE)结果仅文字提及,未完整展示。
- 证据可信度(良好):使用了多个相关性指标和统计检验,部分结果有显著性标记。但缺乏跨更多TTS系统和提示类型的泛化验证。
选题价值:1.5/2
- 前沿性:紧跟基于提示的语音合成这一前沿方向,评估是其中不可或缺的一环。
- 潜在影响/应用空间:为研究社区和产业界提供了一个有潜力的标准化评估工具,可促进模型比较和迭代。对所有从事Prompt-based TTS研究的人员直接相关。
- 扣分点:评估任务本身垂直,虽重要但应用范围限于TTS领域。
开源与复现加成:0/1
- 论文中未提及提供代码、预训练模型、详细训练配置或数据获取指引,可复现性差。