📄 Sounds that Shape: Audio-Driven 3D Mesh Generation with Attribute-Decoupled Score Distillation Sampling
#音频生成 #3D音频 #扩散模型 #知识蒸馏 #跨模态
✅ 7.0/10 | 前25% | #音频生成 | #扩散模型 | #3D音频 #知识蒸馏
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Bumsoo Kim(Chung-Ang University, Republic of Korea)
- 通讯作者:Sanghyun Seo†(Chung-Ang University, Republic of Korea)
- 作者列表:Bumsoo Kim(Chung-Ang University, Republic of Korea), Sanghyun Seo(Chung-Ang University, Republic of Korea)
💡 毒舌点评
亮点在于巧妙地绕过了构建昂贵的音频-3D数据集的难题,直接利用现有强大的音频-图像扩散模型知识,通过“属性解耦引导”这一符合3D Gaussian Splatting特性的设计,将文本和音频的各自优势“分配”到几何和纹理上,实现了1+1>2的效果。短板则是其验证强度略显不足,仅用80个样本的微型数据集就得出“SOTA”结论,且未展示对非环境音、非语义音等复杂音频的处理能力,让人对其在真实世界中的鲁棒性和泛化性打个问号。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:评估数据集从公开数据集中提取,但未说明是否完整公开或如何获取其筛选后的版本。
- Demo:提供了项目页面链接用于展示音频演示和额外样本(但链接未在文本中给出)。
- 复现材料:给出了部分实现细节(如优化器、引导尺度、时间步退火等),但关键的学习率、训练步数等信息缺失。
- 论文中引用的开源项目:CLAP [5], CLIP [19], 3D Gaussian Splatting [9], DreamFusion [8], SonicDiffusion [15], MVDream [18]等。
📌 核心摘要
- 问题:如何将非结构化的音频信息整合到3D内容生成中,以创建更沉浸式的媒体,这是一个尚未被充分探索的挑战。
- 方法核心:提出“Sounds That Shape”系统,利用基于分数蒸馏采样的框架,将音频信息注入到条件生成流程中。核心是采用显式3D表示(3D Gaussian Splatting),并引入属性解耦引导,让文本提示主要指导几何形状的优化,而音频线索主要指导颜色和纹理的优化。
- 新意:无需收集配对的音频-3D数据集。首次将预训练的音频-图像扩散模型与3D Gaussian Splatting结合,并利用其属性可独立优化的特性,提出了针对音频-3D生成任务的解耦监督策略。
- 主要实验结果:
- 定量结果(Table 1)显示,所提方法在音频-3D对齐度(CLAP360: 0.1110)、3D一致性(CLIPi-v: 0.0010)和文本-3D对齐度(CLIP360: 0.2214)上均优于所有基线方法。
- 定性结果(图3)表明,该方法能生成语义连贯的3D物体,而其他基线方法(如两阶段的S-AI3D, S-AT3D)在反映音频语义或保持形状一致性上存在缺陷。
- 消融实验(图4)验证了属性解耦引导(ADG)和纹理监督项的关键作用。
- 实际意义:为音频-3D计算领域提供了一个可行的端到端解决方案,展示了在无需大规模多模态标注数据的情况下,利用现有生成模型知识进行跨模态生成的可能性。
- 主要局限性:实验数据集规模小(仅80个样本),对复杂、非典型音频的鲁棒性未知;方法依赖于特定的预训练音频-图像模型;生成网格的质量评估缺乏更直接的3D几何指标。
🏗️ 模型架构
本文提出的“Sounds That Shape”系统是一个基于分数蒸馏采样的迭代优化框架,旨在从音频和可选文本提示生成显式的3D高斯表示,并最终提取网格。其整体架构如图2所示。

核心流程与组件:
- 输入与编码:
- 音频输入:原始音频
y_audio通过一个预训练的音频编码器(采用CLAP [5])和投影器Φ_a(·)转换为文本兼容的嵌入向量a。 - 文本输入:可选文本提示
y_prompt通过CLIP [19]的文本编码器和投影器Φ_p(·)转换为文本嵌入p。该设计使得音频和文本嵌入处于同一语义空间。
- 音频输入:原始音频
- 3D表示与渲染:
- 3D场景由一组3D高斯基元表示,每个高斯参数包括中心位置
μ、旋转r、缩放s、不透明度o和颜色c。 - 渲染器(采用3D Gaussian Splatting [9]的光栅化器)将这些高斯参数渲染为RGB图像
g(θ)。
- 3D场景由一组3D高斯基元表示,每个高斯参数包括中心位置
- 迭代优化(SDS过程):
- 扩散模型:使用两个冻结的预训练扩散模型U-Net:一个音频条件模型
ϵ_ϕ(来自[15])和一个文本条件模型ϵ_ψ(来自[18])。 - 噪声预测:对渲染图像
g(θ)添加噪声得到z_t(θ)。两个扩散模型分别预测噪声。 - 损失计算与梯度更新:
ℒ_SDS-A:基于音频条件模型ϵ_ϕ和音频嵌入a计算损失,其梯度用于更新纹理参数{o, c}。ℒ_SDS-T:基于文本条件模型ϵ_ψ和文本嵌入p计算损失,其梯度用于更新几何参数{μ, r, s, o}。注意,不透明度o接收来自两个目标的梯度。
- 该过程通过Adam优化器迭代更新高斯参数,使渲染出的3D物体在音频和文本语义上逐步对齐。
- 扩散模型:使用两个冻结的预训练扩散模型U-Net:一个音频条件模型
- 网格提取:优化��成后,通过计算每个空间点的占用率
O(x)并应用Marching Cubes算法,从高斯表示中提取出最终的多边形网格Ω(x)。
关键设计选择:
- 属性解耦引导(ADG):这是架构的核心创新。它利用了3D Gaussian Splatting参数可分离的特性,建立了“文本→几何,音频→纹理”的软归纳偏置。这解决了音频模态在表达粗糙几何语义上的不足,让两种模态各司其职,生成更合理的结果。
- 统一的文本条件:在两个SDS目标中共享同一个文本嵌入
p,确保了音频驱动的优化能与文本提供的粗略结构保持一致。
💡 核心创新点
- 直接利用预训练音频-图像模型进行3D生成:突破了需要昂贵的音频-3D配对数据集的限制。通过将音频嵌入投影到文本条件扩散模型的同一空间,直接复用了其丰富的语义生成知识来指导3D重建。
- 属性解耦引导:针对音频和文本模态在信息表达上的互补性(音频擅长氛围/纹理,文本擅长结构/几何),创新性地设计了梯度解耦策略。让不同模态的监督信号分别作用于高斯属性的不同子集(纹理 vs. 几何),实现了更高效、更合理的联合优化。
- 在显式3D表示上应用音频条件SDS:将音频条件分数蒸馏与3D Gaussian Splatting这一高效、可编辑的显式表示相结合,实现了数分钟内生成可编辑的3D资产,相较于许多基于神经辐射场的方法在速度和实用性上有优势。
🔬 细节详述
- 训练数据:未提供完整的训练集,但评估使用了从“Greatest Hits”和“Landscape + Into the Wild”数据集中提取的80个样本,包含音频和配对文本提示。未说明训练阶段使用的具体数据量。
- 损失函数:主要损失为两个分数蒸馏采样(SDS)损失,如公式(1)和(4)所示。无其他额外损失项(如正则化损失)的明确说明。
- 训练策略:
- 优化器:Adam优化器。
- 调度策略:采用了时间步退火(t-annealing)[13],时间步
t从t_max(设为1000)按平方根形式退火至0,以稳定训练。 - 引导尺度:分类器自由引导(CFG)尺度
τ设为100。 - 学习率:未明确给出具体数值。
- 训练步数:未明确给出。
- 关键超参数:
- 渲染图像分辨率:512×512。
- 音频采样率:44.1kHz。
- 占用率阈值
τ_occ:用于Marching Cubes,设为1。 - 模型大小:未提供。
- 训练硬件:提到所有推理在单张A100 GPU上完成,总收敛时间在3分钟内。未说明训练阶段的具体硬件和时长。
- 推理细节:采用DDPM前向过程和DDIM调度器进行迭代优化。最终通过Marching Cubes从占用场提取网格。
📊 实验结果
定量对比(Table 1): 论文在“音频驱动文本到3D生成”任务上进行了定量评估。
| 方法 | Audio-3D Alig. (CLAP360 ↑) | 3D Cons. (CLIPi-v ↓) | Text-3D Alig. (CLIP360 ↑) |
|---|---|---|---|
| S-AI3D | 0.0175 | 0.0014 | 0.1833 |
| S-AT3D | 0.0112 | 0.0012 | 0.2147 |
| Baseline | 0.0891 | 0.0013 | 0.2082 |
| Ours | 0.1110 | 0.0010 | 0.2214 |
结论:本文方法(Ours)在所有三个指标上均取得最佳结果,表明其生成的3D物体在音频语义对齐、多视角一致性和文本语义对齐方面均优于基线。与最强基线“Baseline”(即单独使用音频条件SDS)相比,CLAP360提升了约24.6%,CLIP360提升了约6.5%,CLIPi-v降低了约23.1%。
定性对比(图3):
 说明:图3展示了四组定性比较。对于“椅子”配不同音频(火焰爆裂、森林、水下冒泡),基线方法(S-AI3D, S-AT3D, Baseline)要么生成失败,要么形状与文本提示不符,要么纹理与音频语义不匹配。而本文方法(Ours)能稳定生成形状符合“椅子”文本、纹理/氛围(如火焰的橙红色、森林的绿色、水下的蓝色气泡)反映对应音频语义的3D物体。
说明:图3展示了四组定性比较。对于“椅子”配不同音频(火焰爆裂、森林、水下冒泡),基线方法(S-AI3D, S-AT3D, Baseline)要么生成失败,要么形状与文本提示不符,要么纹理与音频语义不匹配。而本文方法(Ours)能稳定生成形状符合“椅子”文本、纹理/氛围(如火焰的橙红色、森林的绿色、水下的蓝色气泡)反映对应音频语义的3D物体。
消融实验(图4):
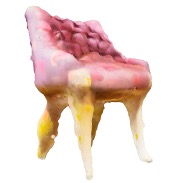 说明:图4展示了消融研究,文本提示为“a chair”,音频为“fire cracking”。
说明:图4展示了消融研究,文本提示为“a chair”,音频为“fire cracking”。
w/o ADG:去除属性解耦,直接用音频条件SDS更新所有参数,导致纹理混乱,形状结构不清晰。w/o ℒ_SDS-T:去除文本条件SDS,仅用音频更新纹理,几何由随机初始化发展而来,导致形状完全错误(一个球体)。Full model (Ours):完整模型生成形状合理的椅子,且表面带有火焰爆裂的橙红纹理。 结论:验证了属性解耦引导(ADG)和纹理监督项(ℒ_SDS-T)对生成合理3D结果的关键作用。
⚖️ 评分理由
- 学术质量:5.5/7:方法创新(属性解耦)有清晰动机和技术支撑,且与所选3D表示(3DGS)高度契合。技术路线正确,实验结果显示了性能提升。主要缺陷在于评估实验规模过小(仅80个测试样本),缺乏对音频类型多样性和模型泛化能力的深入验证,结论的普遍性有待更多实验支撑。
- 选题价值:1.5/2:选题具有前沿性,位于音频、视觉和3D生成的交叉点,符合沉浸式媒体的发展趋势。虽然当前应用场景相对垂直,但为后续研究提供了新的问题定义和基线方法。
- 开源与复现加成:0.0/1:论文未提供代码、模型、数据集或详细的训练配置,严重限制了社区的复现和后续研究。仅在文中引用了部分开源工具。