📄 Sounding Highlights: Dual-Pathway Audio Encoders for Audio-Visual Video Highlight Detection
#视频高光检测 #音视频 #多模态融合 #自适应模型 #精细音频处理
🔥 8.5/10 | 前10% | #视频高光检测 | #多模态融合 | #音视频 #自适应模型
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Seohyun Joo(GIST电气工程与计算机科学学院)
- 通讯作者:论文中未明确说明通讯作者。
- 作者列表:Seohyun Joo(GIST电气工程与计算机科学学院)、Yoori Oh(首尔国立大学音乐与音频研究组)
💡 毒舌点评
亮点在于其“双通路”音频编码器的设计非常精巧,通过一个动态通路显式捕获频谱动态(如突变声音事件),并与语义通路进行门控式融合,有效解决了以往音频特征利用不足的痛点,在大规模数据集上效果显著。短板是其在较小规模、类别更多样的TVSum数据集上优势不明显,可能暗示模型的泛化能力或对不同视频风格的适应性仍有提升空间。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及。
- 数据集:使用了Mr.HiSum和TVSum公开数据集,但未在文中提供获取方式链接(假设读者已知)。
- Demo:提供了在线演示链接:https://seohyj.github.io/soundhd.github.io/。
- 复现材料:提供了详细的训练细节(优化器、学习率、批量大小、训练轮数、权重衰减、梯度裁剪)、关键超参数(K值、特征维度、频谱图参数)和模型架构描述,便于复现。
- 论文中引用的开源项目:引用了多个预训练模型作为基线或组件,包括PANNs (用于音频语义编码器)、ResNet-34、Inception-v3 (用于视觉编码器),以及作为基线比较的PGL-SUM, Joint-VA, UMT, CSTA等。
- 总结:论文中未提及开源计划,但提供了Demo和详细的复现参数。
📌 核心摘要
- 要解决什么问题:现有音视频视频高光检测模型对音频模态的利用过于简单,通常只提取高层语义特征,忽略了声音丰富的、动态的声学特性(如瞬态事件、能量突变),而这些特性对于识别视频中的亮点时刻至关重要。
- 方法核心是什么:提出名为DAViHD的框架,其核心是双通路音频编码器。它包含两个并行路径:1)语义通路(基于PANNs)处理原始波形,提取“听到了什么”的高层语义信息;2)动态通路(基于频率自适应卷积)处理对数梅尔频谱图,捕获“声音如何变化”的低层、时变动态特性。两条通路的输出经过自注意力后,通过元素级乘法进行融合(动态特征作为门控调制语义特征)。最终融合后的音频表征与视觉表征进行双向跨模态注意力融合,预测高光分数。
- 与已有方法相比新在哪里:主要创新在于显式地、并行地建模音频的语义内容与谱时动态,并通过精心设计的“早期自注意力+乘法融合”策略将两者结合。这与以往将音频视为单一流或仅使用通用预训练特征(如PANNs)的方法有本质区别。
- 主要实验结果如何:在大规模Mr.HiSum数据集上取得全面SOTA,例如在F1、mAP_50、ρ、τ等指标上均显著超越最强基线UMT。在TVSum数据集上部分指标也达到最优。消融实验证明,仅使用双通路音频(V+A_s+A_d)的性能已接近甚至超过一些传统音视频模型(V+A_s),凸显了精细音频表征的关键作用。
模型 Mr.HiSum F1 ↑ Mr.HiSum ρ ↑ TVSum F1 ↑ TVSum ρ ↑ UMT (强基线) 58.18±0.29 0.239±0.006 57.54±0.87 0.175±0.022 DAViHD (本文) 59.73±0.41 0.299±0.012 57.67±1.27 0.200±0.032 - 实际意义是什么:证明了在音视频理解任务中,对音频信号进行更物理、更精细的建模(如考虑其动态变化)能带来巨大性能提升。为视频摘要、检索等应用提供了更准确的技术基础。
- 主要局限性是什么:1)模型复杂度有所增加(双通路);2)在数据量较小、视频类别多样的TVSum上提升幅度相对有限,表明其优势在大规模、风格可能更统一的互联网视频数据上更为突出;3)论文未讨论模型的计算开销与推理速度。
🏗️ 模型架构
DAViHD的整体框架(图2(a))是一个端到端的音视频高光检测模型,输入是视频帧序列和对应的音频波形,输出是每1秒片段的高光分数。
- 视觉编码器 (Ev):
- 输入:视频帧序列 V ∈ R^{T_f × H × W × C},T_f为帧数(1 fps)。
- 处理:使用预训练的CNN(如ResNet-34, Inception-v3)提取帧级视觉特征 Z_v ∈ R^{T_f × D_v}。然后通过一个多头自注意力机制,捕捉帧间的长程依赖,得到最终视觉表征 Z’_v。
- 输出:Z’_v ∈ R^{T_f × D_v}。
- 双通路音频编码器: 这是论文的核心创新,包含两个并行的子编码器。
2.1 音频语义编码器 (E^s_a):
- 输入:原始音频波形 A ∈ R^L。
- 处理:将波形切分为不重叠的1秒片段。使用在AudioSet上预训练的PANNs模型独立处理每个片段,提取高层语义嵌入(维度D_s=2048)。然后按时间顺序拼接。
- 输出:语义特征序列 Z^s_a ∈ R^{T_f × D_s}。
2.2 音频动态编码器 (E^d_a): (详细架构见图2(b))
- 输入:对数梅尔频谱图 S ∈ R^{F × T}。
- 处理:采用一个多分支架构:
- 时间注意力分支:对S应用2D卷积块,通过softmax生成时间注意力图α。
- 显著性门控分支:对S应用另一个2D卷积块,通过sigmoid生成显著性门控向量x_s。
- 速度注意力分支:计算帧间差ΔS = |S_t - S_{t-1}|,再通过2D卷积块和softmax生成速度注意力图β。
- 全局上下文分支:对S进行全局平均池化,提取全局上下文向量。
- 上述分支输出(α⊗x_s, β⊗x_s, 全局上下文向量)被组合成一个综合向量f_combined。该向量通过一个1D卷积块,为一组K=4个可学习的基卷积核{W_k}生成频率特定的调制权重γ_k(f)。
- 频率自适应卷积层:使用调制后的动态滤波器对原始频谱图S进行2D卷积,公式为:Z^d_a = Σ_{k=1}^K γ_k ⊗ (W_k * S)。此机制允许滤波器自适应地关注特定频带和时变模式,而非标准2D卷积的固定感受野。
- 最后,对卷积输出进行通道与频率维度展平、时间对齐(自适应平均池化至T_f)和线性投影。
- 输出:动态特征序列 Z^d_a ∈ R^{T_f × D_d}, D_d=2048。
2.3 音频特征融合 (F_a):
- 处理(Early-SA策略):Z^s_a和Z^d_a首先分别通过两个独立的自注意力层,得到上下文感知的Z’^s_a和Z’^d_a。然后进行元素级乘法:Z’_a = Z’^s_a ⊗ Z’^d_a。这种乘法操作起到了门控作用,让动态特征可以调制语义特征。
- 输出:统一的音频表征 Z’_a ∈ R^{T_f × D_a}, D_a=2048。
- 多模态融合与分数预测:
- 融合:使用双向跨模态注意力。视觉表征Z’v作为查询(Q_v),音频表征Z’a作为键(K_a)和值(V_a),计算音频上下文化的视觉特征Z’{a→v}。对称地计算视觉上下文化的音频特征Z’{v→a}。然后通过残差连接得到增强后的S_v和S_a。
- 预测:将原始自注意力特征(Z’_v, Z’_a)与增强后的跨注意力特征(S_v, S_a)拼接,输入一个3层MLP,回归得到归一化的高光分数序列ŷ。
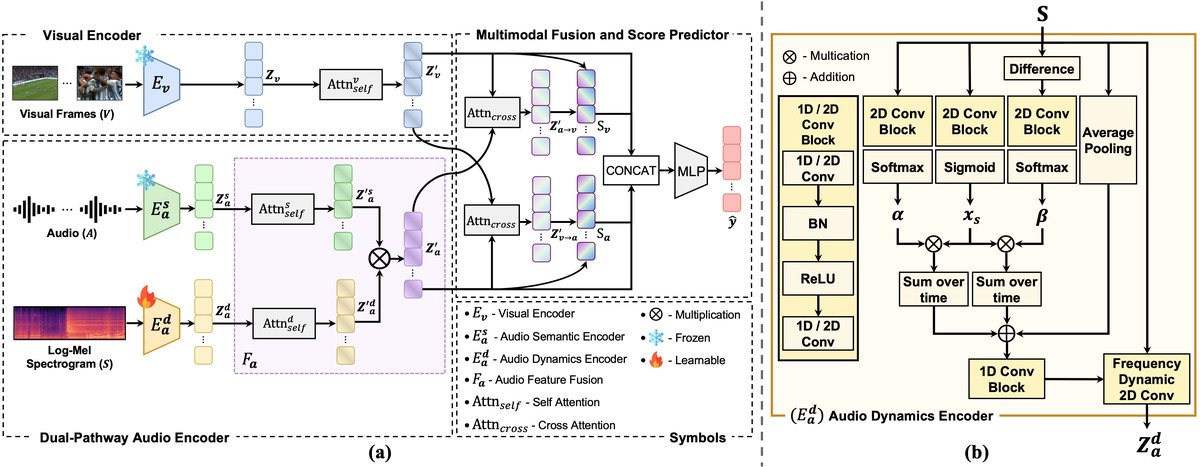 图2: (a) DAViHD框架概览。视觉编码器(E_v)和双通路音频编码器(E^s_a, E^d_a)并行处理输入。音频特征通过F_a融合,然后与视觉特征进行跨模态注意力融合,最后由MLP预测分数。(b) 音频动态编码器(E^d_a)的详细架构,展示了多分支结构和频率自适应卷积层。
图2: (a) DAViHD框架概览。视觉编码器(E_v)和双通路音频编码器(E^s_a, E^d_a)并行处理输入。音频特征通过F_a融合,然后与视觉特征进行跨模态注意力融合,最后由MLP预测分数。(b) 音频动态编码器(E^d_a)的详细架构,展示了多分支结构和频率自适应卷积层。
💡 核心创新点
双通路音频编码器架构:
- 是什么:将音频表征分解为语义通路(内容)和动态通路(变化)两个独立流。
- 之前局限:以往方法要么仅使用单一音频流(如PANNs特征),要么将音频简单处理,无法同时有效捕获“是什么”和“如何变”。
- 如何起作用:两个通路从不同粒度和视角(高层语义 vs. 低层频谱动态)分析音频,提供了更全面、互补的音频理解。
- 收益:消融实验(表2)显示,仅动态通路(A_d)就显著优于仅视觉(V)或仅语义(A_s),且双通路(A_s+A_d)性能接近完整模型,证明了该设计的必要性和有效性。
基于频率自适应卷积的音频动态编码器:
- 是什么:引入频率动态卷积(FDC),根据输入频谱动态生成频率特定的卷积核权重。
- 之前局限:标准CNN假设时间和频率轴是空间等价的,无法精确建模声音信号中瞬态事件的频谱变化。
- 如何起作用:通过多分支(时间注意力、速度注意力、显著性门控)感知动态,动态生成调制权重γ_k(f),使卷积核能自适应地聚焦于关键频带和时变模式。
- 收益:模型能够显式地识别“突变的听觉事件”(如图1中黄色框所示),这是高光时刻的强信号,从而提升了检测精度。
“早期自注意力 + 乘法”的音频特征融合策略:
- 是什么:在融合前对各音频通路分别施加自注意力(Early-SA),然后用元素级乘法进行融合。
- 之前局限:简单拼接(Concat)或晚期融合(Late-SA)无法充分利用各通路的独立时序上下文,且融合方式缺乏交互。
- 如何起作用:Early-SA让每个通路先建模自身的时间依赖;乘法融合让动态特征作为“开关”或“放大器”,有选择性地强调语义特征中与动态事件相关的部分。
- 收益:消融实验(表3)表明,Early-SA比Late-SA效果更好,乘法融合优于拼接融合,两者结合达到最优性能。
🔬 细节详述
训练数据:
- Mr.HiSum:大规模数据集,包含31,892个YouTube视频(过滤后30,656个),平均长度201.9秒。高光分数源自YouTube“Most replayed”统计数据。
- TVSum:50个来自10个类别的网络视频。
- 预处理:所有视频被处理成1秒片段(1 fps)。视觉特征提取:Mr.HiSum使用Inception-v3(预训练于ImageNet)+ PCA,特征维度D_v=1024;TVSum使用3D CNN (ResNet-34 backbone, 预训练于Kinetics-400),特征维度D_v=512。音频动态通路使用16kHz采样,2048点FFT,256跳点,128个梅尔频率箱生成对数梅尔频谱图。
- 数据增强:论文中未提及。
损失函数:
- 使用均方误差损失 (MSE Loss),公式为L_MSE = (1/T) * Σ_{t=1}^T (y_t - ŷ_t)^2,直接回归分数。
训练策略:
- 优化器:Adam。
- 学习率:Mr.HiSum为1×10⁻⁵;TVSum为5×10⁻⁶。
- 批量大小:Mr.HiSum为16;TVSum为8。
- 训练轮数:Mr.HiSum为200 epochs;TVSum为400 epochs。
- 权重衰减:1×10⁻⁴。
- 梯度裁剪:最大范数0.5。
- 调度策略:论文中未提及具体学习率调度策略。
关键超参数:
- 频率自适应卷积的基卷积核数量 K = 4。
- 音频特征维度:D_s = D_d = D_a = 2048。
- 视觉特征维度:D_v因数据集而异(512或1024)。
- 模型总参数量:论文中未提供。
训练硬件:
- 论文中未说明具体的GPU/TPU型号、数量和训练时长。
推理细节:
- 以1 fps处理视频片段。
- 输出为归一化的0-1之间的连续分数序列。
- 没有提及解码策略、温度或beam size,因为是回归任务。
正则化或稳定训练技巧:除了梯度裁剪外,论文中未提及Dropout等其他正则化技巧。自注意力机制本身有一定的正则化作用。
📊 实验结果
主要结果对比(表1):论文在Mr.HiSum和TVSum两个基准上与多个SOTA方法进行了比较,证明了DAViHD的优越性。
| 模型 | Mr.HiSum F1 ↑ | Mr.HiSum mAP_50 ↑ | Mr.HiSum mAP_15 ↑ | Mr.HiSum ρ ↑ | Mr.HiSum τ ↑ | TVSum F1 ↑ | TVSum mAP_50 ↑ | TVSum mAP_15 ↑ | TVSum ρ ↑ | TVSum τ ↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| PGL-SUM† | 53.34±0.10 | 59.73±0.17 | 25.71±0.30 | 0.104±0.003 | 0.070±0.002 | 52.93±1.75 | 56.68±2.33 | 23.18±1.96 | 0.056±0.040 | 0.038±0.027 |
| CSTA† | 54.32±0.17 | 61.12±0.39 | 28.35±0.48 | 0.138±0.005 | 0.095±0.004 | 57.32±1.99 | 62.36±2.81 | 27.52±5.08 | 0.205±0.056 | 0.141±0.041 |
| Joint-VA‡ | 54.71±0.04 | 61.82±0.11 | 29.09±0.22 | 0.152±0.001 | 0.104±0.001 | 55.03±2.20 | 60.94±3.19 | 26.66±3.40 | 0.142±0.046 | 0.097±0.031 |
| UMT‡ | 58.18±0.29 | 65.81±0.31 | 33.79±0.35 | 0.239±0.006 | 0.174±0.004 | 57.54±0.87 | 61.49±2.91 | 25.24±5.05 | 0.175±0.022 | 0.121±0.015 |
| DAViHD (Ours)‡ | 59.73±0.41 | 67.27±0.52 | 36.55±0.51 | 0.299±0.012 | 0.213±0.009 | 57.67±1.27 | 63.52±2.58 | 28.94±3.11 | 0.200±0.032 | 0.138±0.022 |
| † 视频仅, ‡ 视频与音频 |
关键结论:
- 在Mr.HiSum上:DAViHD在所有指标上均大幅超越最强音频-视频基线UMT。例如F1分数提升约1.55个百分点,ρ(Spearman相关系数)提升约0.06,显示其预测分数与真实动态的匹配度显著提高。
- 在TVSum上:DAViHD在F1和mAP_50上也取得了最优,但提升幅度相对Mr.HiSum较小。这可能是因为TVSum数据集规模小、视频类别多样,而Mr.HiSum的YouTube视频风格可能更统一,动态音频线索更明显。
模态贡献消融实验(表2):
| V | A_s | A_d | F1 | mAP_50 | mAP_15 | ρ | τ |
|---|---|---|---|---|---|---|---|
| ✓ | 52.98 | 58.93 | 25.31 | 0.101 | 0.069 | ||
| ✓ | 53.25 | 60.11 | 28.21 | 0.109 | 0.075 | ||
| ✓ | 57.53 | 63.88 | 33.15 | 0.244 | 0.175 | ||
| ✓ | ✓ | 54.79 | 61.95 | 28.94 | 0.153 | 0.105 | |
| ✓ | ✓ | 58.25 | 65.84 | 35.51 | 0.269 | 0.191 | |
| ✓ | ✓ | 59.09 | 66.12 | 35.62 | 0.282 | 0.203 | |
| ✓ | ✓ | ✓ | 60.17 | 68.01 | 36.96 | 0.312 | 0.224 |
关键结论:
- 仅使用音频动态通路(A_d)的性能(F1=57.53)远超仅使用视觉(V, F1=52.98)或仅使用音频语义(A_s, F1=53.25)。
- 双音频通路(A_s + A_d)的组合(F1=59.09)性能非常接近完整模型(F1=60.17),且显著优于传统的音视频组合(V + A_s, F1=54.79)。这强有力地证明了精细音频表征的核心作用。
音频融合策略消融实验(表3)(在Mr.HiSum上):
| SA Placement | Combination | F1 | mAP_50 | mAP_15 | ρ | τ |
|---|---|---|---|---|---|---|
| Late | Concat | 58.71 | 66.24 | 35.61 | 0.280 | 0.198 |
| Late | Multiply | 58.40 | 66.01 | 35.93 | 0.276 | 0.195 |
| Early | Concat | 59.42 | 67.36 | 36.21 | 0.294 | 0.208 |
| Early | Multiply | 60.17 | 68.01 | 36.96 | 0.312 | 0.224 |
关键结论:早期自注意力(Early-SA)显著优于晚期自注意力(Late-SA)。在Early-SA设置下,乘法融合(Multiply)优于拼接(Concat)。这验证了论文提出的设计选择。
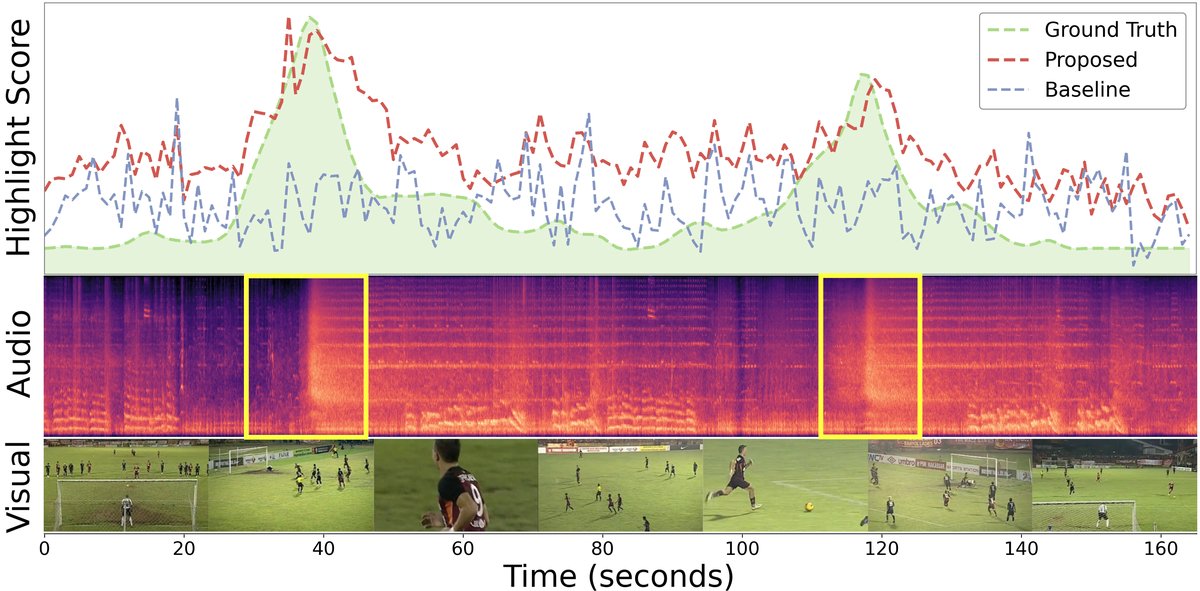 图1: 基线模型(蓝色)与DAViHD(红色)的输出对比。基线模型的预测分数均匀,无法匹配真实高光(绿色)。DAViHD能通过建模频谱图中黄框所示的“突变听觉事件”,生成与真实动态高度吻合的分数曲线。
图1: 基线模型(蓝色)与DAViHD(红色)的输出对比。基线模型的预测分数均匀,无法匹配真实高光(绿色)。DAViHD能通过建模频谱图中黄框所示的“突变听觉事件”,生成与真实动态高度吻合的分数曲线。
⚖️ 评分理由
- 学术质量:6.5/7:创新点(双通路音频编码器、频率自适应动态卷积、Early-SA乘法融合)清晰且有明确动机。技术路线正确,实现细节描述充分。实验设计全面,在大规模数据集上取得了显著的SOTA性能,并通过详尽的消融实验(模态贡献、融合策略)有力地支持了其主张。主要扣分点在于未公开核心代码,且未讨论计算效率。
- 选题价值:1.5/2:音视频高光检测是多媒体内容分析的基础任务,具有明确的实际应用价值(视频摘要、推荐)。论文聚焦于被忽视的音频模态精细化建模,这一视角具有启发性,能推动相关领域的研究。但任务本身并非最前沿的基础模型或通用AI方向。
- 开源与复现加成:0.5/1:论文提供了在线Demo链接,增强了结果的可信度。在“实现细节”部分给出了极为详尽的训练超参数、数据预处理参数和模型维度配置,使得复现门槛较低。然而,未提供代码仓库、预训练模型权重或训练日志,限制了社区的直接应用和改进,因此只能给予部分加成。