📄 SoundCompass: Navigating Target Sound Extraction with Effective Directional Clue Integration in Complex Acoustic Scenes
#语音分离 #麦克风阵列 #信号处理 #多通道 #空间音频
✅ 7.5/10 | 前25% | #语音分离 | #麦克风阵列 | #信号处理 #多通道
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Dayun Choi(韩国科学技术院电气工程学院)
- 通讯作者:Jung-Woo Choi(韩国科学技术院电气工程学院)
- 作者列表:Dayun Choi(韩国科学技术院电气工程学院)、Jung-Woo Choi(韩国科学技术院电气工程学院)
💡 毒舌点评
论文亮点在于将球谐函数(SH)这种连续、旋转不变的表示与精心设计的SPIN模块相结合,优雅地解决了传统DoA编码的离散化和信息损失问题,理论动机非常扎实。然而,所有实验都在重新生成的静态声源场景(gpuRIR)上进行,虽然控制了变量,但削弱了对“复杂声学场景”中动态性和真实混响的验证说服力,这让其声称的“鲁棒性”略显成色不足。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:训练数据基于ASA2数据集(
https://huggingface.co/datasets/donghoney22/ASA2_dataset)使用gpuRIR重新生成,论文中提供了配置说明。 - Demo:论文提供了在线音频演示链接:
https://choishio.github.io/demo-SoundCompass/。 - 复现材料:给出了主要的训练超参数(学习率、优化器、batch size、epoch数等)和硬件配置,但一些关键模型参数(如编码器通道数D、注意力头数、Mamba状态维度等)未详细说明。
- 论文中引用的开源项目:gpuRIR (RIR模拟), SemanticHearing (用于ITD计算), torchinfo (用于计算模型复杂度), 以及基线代码SSDQ和DSENet。
📌 核心摘要
本文旨在解决复杂声学场景中,现有基于到达方向(DoA)的目标声源提取(TSE)方法因使用手工特征或离散编码而导致的精细空间信息丢失和适应性受限问题。核心方法是提出SoundCompass框架,其包含三个关键组件:1)光谱成对交互(SPIN)模块,在复数谱图域捕获所有通道间的成对空间相关性,保留完整的空间信息;2)球谐函数(SH)嵌入,作为DoA线索的连续、无离散化的表示,描述球面上的位置;3)基于推理链(CoI)的迭代细化策略,将前一阶段估计的声源时间激活与DoA线索递归融合,逐步优化提取结果。与已有方法相比,新在提出了一套端到端、保留连续空间信息的线索集成方案,并创新性地将迭代细化引入基于DoA的TSE。实验在重新生成的ASA2数据集上进行,消融研究证明了SPIN、SH和CoI的有效性。与基线方法(如SSDQ, DSENet)相比,SoundCompass在信噪比改善(SNRi)和空间一致性(∆ILD, ∆IPD, ∆ITD)上均取得更优结果,同时保持了较低的计算复杂度。实际意义在于为助听器、AR/VR等应用提供了更精准、高效的声音提取方案。主要局限性是实验验证依赖静态声源的模拟数据集,对动态场景和更复杂真实环境的泛化能力有待进一步验证。
🏗️ 模型架构
模型整体架构(图1(a))基于DeepASA骨干网络,是一个端到端的多通道声源分离框架。
- 输入与特征提取:输入为M通道混合音频,经短时傅里叶变换(STFT,使用可学习高斯窗)得到形状为2M×T×F的复数谱图。通过一个2D卷积编码器,将通道维度从2M映射到D,提取包含局部时空模式的空间特征。
- 方向线索融合模块:这是核心创新所在(图1(b))。该模块接收编码器特征和DoA线索(θ, ϕ)。
- SPIN模块:首先,将多通道复数谱图的正弦/余弦分量进行成对相乘,生成形状为(2M)^2×T×F的特征,显式建模所有通道间的空间相关性。
- 子带划分:采用基于12-TET音乐音阶的重叠子带划分(K=31),在每个子带内独立进行后续操作,以捕获频率相关的空间线索。
- SH编码与融合:DoA线索被编码为5阶球谐函数(SH)的实部与虚部堆叠,得到维度为2(N+1)^2=72的嵌入向量。在每个子带内,通过一个FiLM层(生成缩放γ和偏移β参数)将SH嵌入与SPIN特征融合,并加入残差连接。
- 特征聚合与解码:融合后的特征送入多个特征聚合(FA)块,沿频谱和时间维度分别应用多头自注意力和Mamba前馈网络,进行目标源的特征分离。最后,两个并行的音频解码器(结构相同)将特征维度从D恢复到2M,分别重建直达声和混响,经逆STFT(iSTFT)得到最终波形。
- 迭代细化(CoI):如图2所示,第一阶段的输出被送入一个声音事件检测(SED)解码器,预测帧级二值时间掩码。该掩码与原始SH嵌入结合,形成时变方向线索,线性插值后注入到第二个相同的TSE阶段,实现迭代优化。
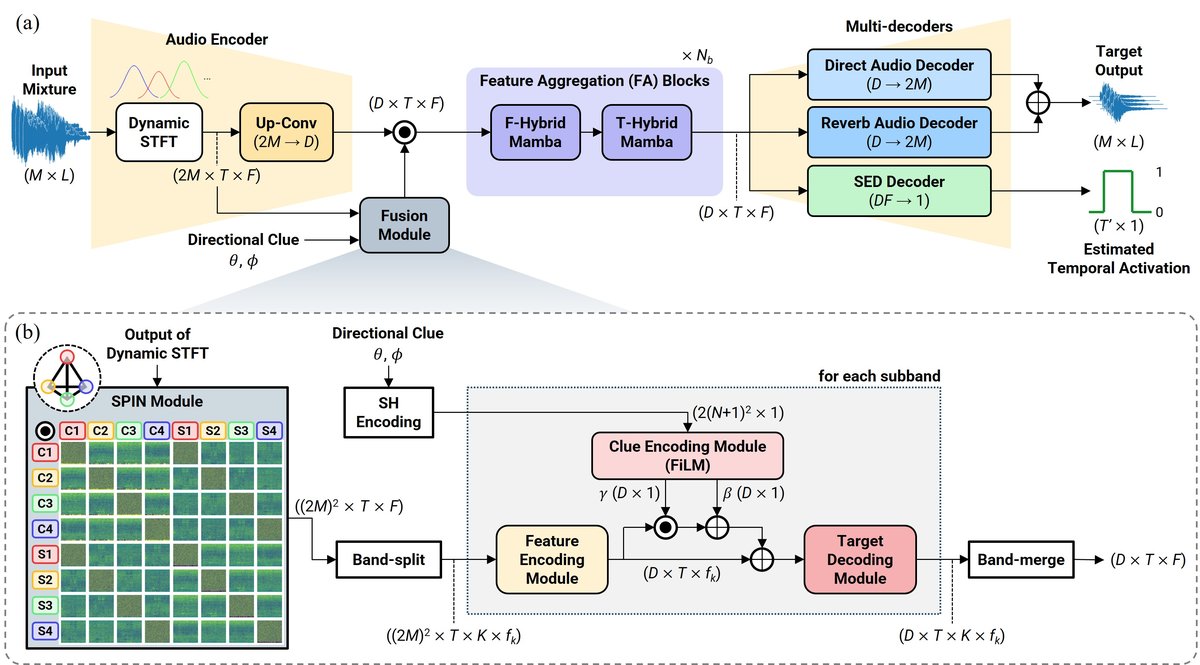 图1:(a) SoundCompass整体架构图,展示了从多通道混合输入到最终目标波形提取的完整流程,核心是融合模块。(b) 融合模块内部细节,展示了SPIN如何处理复数谱图,以及如何与SH编码的方向线索在K个子带内通过FiLM层融合。
图1:(a) SoundCompass整体架构图,展示了从多通道混合输入到最终目标波形提取的完整流程,核心是融合模块。(b) 融合模块内部细节,展示了SPIN如何处理复数谱图,以及如何与SH编码的方向线索在K个子带内通过FiLM层融合。
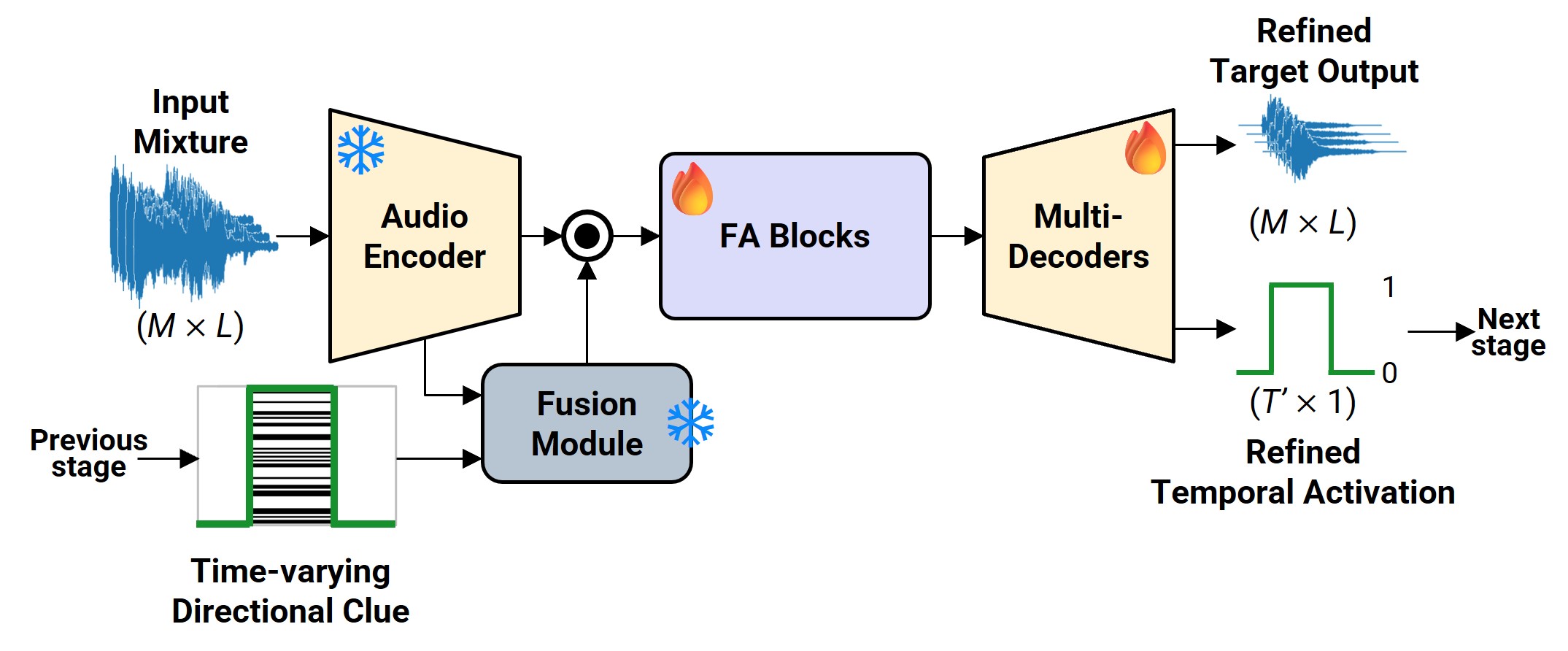 图2:迭代细化(CoI)策略细节图。第一阶段TSE的输出经SED解码器得到时间激活序列,与SH嵌入结合生成时变线索,输入到第二阶段TSE进行精细化处理。
图2:迭代细化(CoI)策略细节图。第一阶段TSE的输出经SED解码器得到时间激活序列,与SH嵌入结合生成时变线索,输入到第二阶段TSE进行精细化处理。
💡 核心创新点
- 光谱成对交互(SPIN)输入特征:是什么:在复数谱图域,对所有通道的正弦/余弦分量进行两两相乘,生成高维空间相关性特征。之前方法的局限:依赖手工特征(如IPD/ILD),会损失信息;或使用原始复数谱图,未显式建模通道间关系。如何起作用:直接、无损地建模任意两通道间的相位和幅度差异,且乘积值范围稳定(±1)。收益:消融实验表明,移除该交互导致SNRi大幅下降(从17.865降至5.663 dB),证明了其对捕获丰富空间信息的关键作用。
- 球谐函数(SH)嵌入:是什么:使用球谐函数对2D球面上的连续DoA角度进行编码。之前方法的局限:使用离散的one-hot/binary编码(维度高、泛化差),或循环位置嵌入(分离方位角和俯仰角,不满足旋转不变性)。如何起作用:提供连续、旋转不变的表示,无需离散化即可处理任意角度。收益:相比cyc-pos嵌入,SH嵌入在ΔIPD和ΔITD误差上略有改善,且理论优势更明显。
- 基于推理链(CoI)的迭代细化:是什么:将第一阶段估计的声源时间激活(SED)与方向线索结合,作为第二阶段的时变输入线索。之前方法的局限:通常只使用静态DoA线索,忽略了声源活动的时间动态性。如何起作用:模型能利用更精确的“何时”信息来指导“何方”的分离,形成闭环优化。收益:二次迭代(×2)后,SNRi从17.884提升至18.196 dB,空间误差进一步减小,证明了迭代细化的有效性。
🔬 细节详述
- 训练数据:使用gpuRIR库在ASA2数据集基础上重新生成。数据集包含13类音频,每段混合2-5个前景声源和1个背景噪声,声源位置固定(静态)。训练/验证/测试集规模为50k/2k/2k条,每段4秒,16kHz采样,4通道四面体麦克风阵列(半径4.2cm),房间为长方体。
- 损失函数:直接声/混响解码器及总输出的损失为SNR损失与SI-SNR损失的线性组合(权重比9:1)。SED解码器使用二元交叉熵(BCE)损失。所有损失项以相同权重求和。
- 训练策略:优化器AdamW,初始学习率0.0005,采用耐心机制(验证损失连续5个epoch不下降则乘以0.1)。梯度范数裁剪阈值5。训练100个epoch,batch size 2,在4块GeForce RTX 4090 GPU上进行。第二阶段CoI模型微调时,第一阶段模型固定,编码器和融合模块也固定。
- 关键超参数:基于DeepASA骨干。SPIN特征维度为(2M)^2。子带数K=31。SH编码阶数N=5,嵌入维度72。FiLM层包含线性层、自适应层归一化(AdaNorm)和PReLU。音频解码器为2D卷积层(核大小3,步长1)。
- 训练硬件:4块GeForce RTX 4090 GPU。
- 推理细节:使用训练好的完整流水线进行端到端推理。CoI策略中,第二阶段的输入是第一阶段SED输出与SH嵌入结合并线性插值后的时变线索。
- 正则化或稳定训练技巧:梯度范数裁剪。使用可学习的STFT窗(高斯窗,参数可学习)。
📊 实验结果
主要评估指标为信噪比改善(SNRi,dB)和尺度不变信噪比改善(SI-SNRi,dB),以及衡量空间一致性的平均绝对误差:∆ILD(dB)、∆IPD(rad)和∆ITD(µs)。数据集为重新生成的ASA2。
表1:模型性能对比与消融实验结果
| Model | SNR Metrics ↑ | Spatial Errors ↓ | Complexities ↓ |
|---|---|---|---|
| SNRi (dB) | SI-SNRi (dB) | ∆ILD (dB) | |
| Universal source separation | |||
| DeepASA [25] | 15.636 | 12.976 | 0.261 |
| Target sound extraction | |||
| SSDQ (w. point spatial query) [12] | 5.949 | -1.171 | - |
| DSENet (w. cyc-pos (θ, ϕ)) [18] | 16.419 | 16.025 | - |
| Proposed (DoA before FA) | 17.865 | 16.717 | 0.099 |
| Proposed (DoA after FA) | 15.977 | 14.508 | 0.146 |
| remove an interaction in SPIN | 5.663 | 15.854 | 0.115 |
| replace SH to cyc-pos (θ, ϕ) | 17.696 | 16.538 | 0.100 |
| remove a band-split structure | 17.524 | 16.238 | 0.104 |
| add an SED decoder | 17.884 | 16.780 | 0.098 |
| refine iteratively (×2) | 18.196 | 17.079 | 0.093 |
关键结论:
- 整体性能:完整的SoundCompass(DoA before FA + CoI×2)在所有SNR指标上显著优于无指导的DeepASA基线(SNRi: 15.6 -> 18.2 dB)和两个DoA-based基线SSDQ(性能极差)与DSENet。同时,其参数量(2.7M)和计算量(20.49G)远低于DSENet(4.88M, 86.89G)。
- 消融研究:
- SPIN的成对交互至关重要,移除后SNRi暴跌。
- SH嵌入略优于cyc-pos嵌入,尤其在空间误差上。
- 子带划分结构能稳定提升性能,减少空间误差。
- 增加SED解码器为CoI奠定基础,并带来小幅提升。
- CoI迭代细化(×2)带来进一步性能提升。
- 可视化分析:
- 图3(FiLM scale参数的t-SNE可视化):显示方位角变化形成近圆流形且不同俯仰角下保持分离,俯仰角轨迹收敛。不同子带的模式不同,证明模型学习到了频率特定的空间相关性。
- 图4(SI-SNRi灵敏度轮廓图):在±15°偏离真实方向时,性能下降,但圆形高性能区域表明模型有效利用了方向引导,且存在一定容错性。
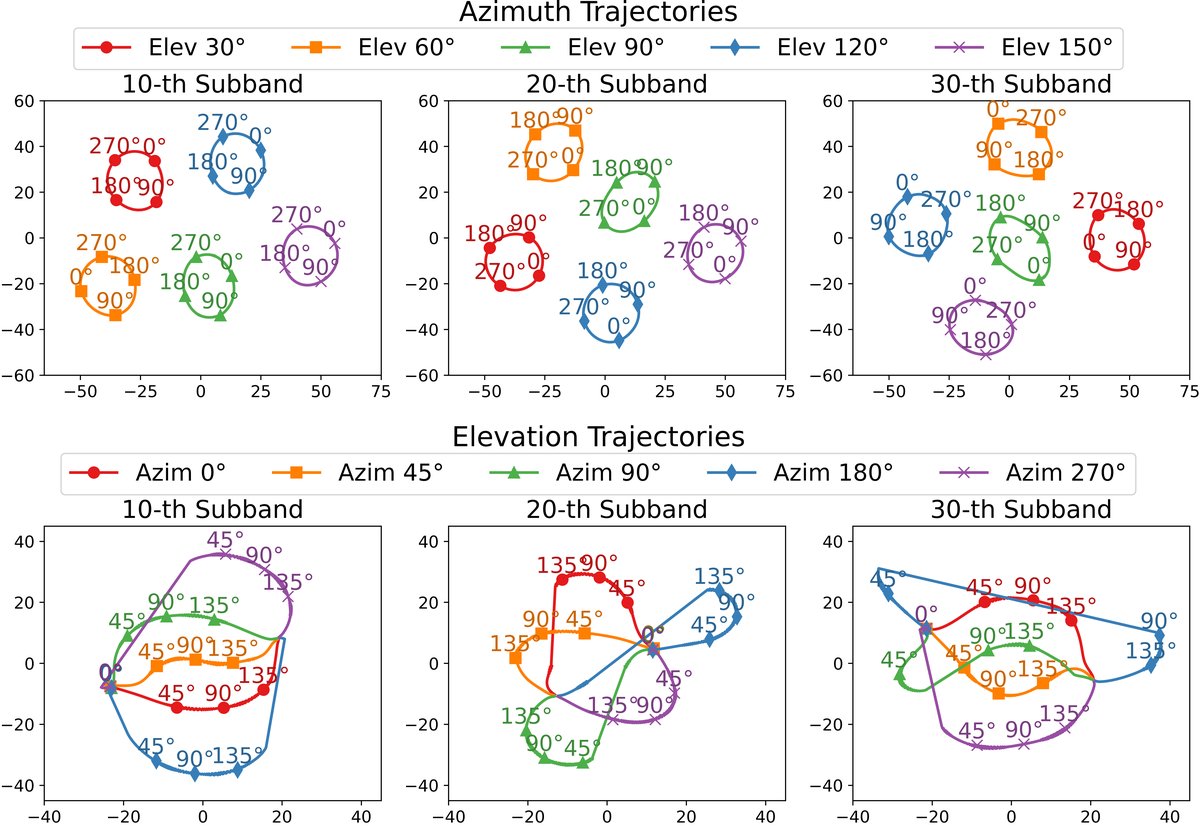 图3:三个不同子带中,FiLM层缩放(γ)参数随方位角(上)和俯仰角(下)变化的t-SNE轨迹可视化。证明了SH嵌入有效编码了连续角度,且子带处理捕获了频率依赖的空间信息。
图3:三个不同子带中,FiLM层缩放(γ)参数随方位角(上)和俯仰角(下)变化的t-SNE轨迹可视化。证明了SH嵌入有效编码了连续角度,且子带处理捕获了频率依赖的空间信息。
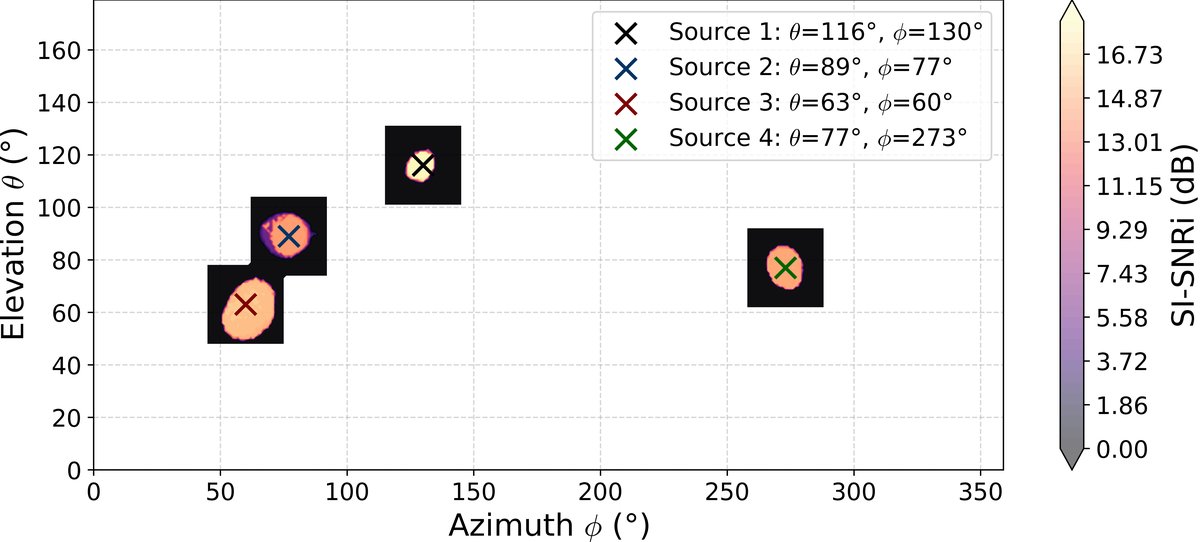 图4:在真实目标方向(“X”标记)附近±15°范围内,SI-SNRi的灵敏度轮廓图。显示性能峰值靠近真实方向,随偏离而下降,展示了模型的方向敏感性和一定的鲁棒性。
图4:在真实目标方向(“X”标记)附近±15°范围内,SI-SNRi的灵敏度轮廓图。显示性能峰值靠近真实方向,随偏离而下降,展示了模型的方向敏感性和一定的鲁棒性。
⚖️ 评分理由
- 学术质量:6.0/7:创新点清晰且互补,技术实现合理。实验设计完整,包含与基线的定量对比、详细的消融研究、以及对模型内部表示(图3)和外在表现(图4)的可视化分析。所有核心主张都有实验数据支撑。主要扣分项在于:1)骨干网络为现有工作;2)实验场景(静态声源)相对理想化,未充分挑战模型的极限;3)论文未明确对比所有最新相关工作,SOTA地位未宣称。
- 选题价值:1.5/2:DoA-based TSE是一个重要且活跃的研究方向,具有明确的实用需求。本文提出的连续空间表示和迭代细化思想对该方向有实质贡献,技术方案可迁移性强。
- 开源与复现加成:0.0/1:论文提供了数据集来源链接和基线代码链接,但未提供自身模型代码、权重���详细的训练配置(如具体的子带划分参数、FiLM层维度等)。这降低了工作的可复现性。