📄 Solving the Helmholtz Equation Via Physics-Informed Neural Networks with an Adaptive Weighting Strategy
#声学建模 #物理信息神经网络 #自适应学习
✅ 6.5/10 | 前50% | #声学建模 | #物理信息神经网络 | #自适应学习
学术质量 5.0/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 中
👥 作者与机构
- 第一作者:Yanan Guo(国防科技大学气象与海洋学院)
- 通讯作者:未说明
- 作者列表:Yanan Guo(国防科技大学气象与海洋学院),Junqiang Song(国防科技大学气象与海洋学院),Xiaoqun Cao(国防科技大学气象与海洋学院),Hongze Leng(国防科技大学气象与海洋学院)
💡 毒舌点评
论文的核心动机——解决PINN训练中多损失项收敛速率不平衡的问题——是真实且重要的,提出的“逆残差衰减率”权重机制在理论上具有吸引力。然而,其验证过程显得过于“温室化”,仅用两个低维、规则、解析解已知的“玩具问题”就宣称方法有效,缺乏对高频波、复杂几何或实际噪声数据等更具挑战性场景的拷问,大大削弱了其声称的普适性和鲁棒性,读起来更像一个初步的概念验证而非完整的解决方案。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:未提及(论文使用自构造的合成数据)。
- Demo:未提及。
- 复现材料:论文描述了网络架构(层数、神经元数、激活函数)、优化器(Adam)、学习率(三维为0.001)、训练步数(三维为20k)。但核心的自适应参数(如β_w, β_s, ε)的具体值、损失函数中γ^R/γ^B的取值、采样策略等细节未充分提供。
- 论文中引用的开源项目:未提及依赖的特定开源工具或模型。
- 论文中未提及开源计划。
📌 核心摘要
这篇论文旨在解决物理信息神经网络(PINN)在求解亥姆霍兹方程时,因不同损失项(PDE残差、边界残差)收敛速率不一致而导致的训练缓慢和精度不足问题。核心方法是提出一种点级自适应加权策略,通过计算每个配点的“逆残差衰减率”(基于当前残差与历史残差四阶矩的比值),动态分配权重,给予收敛慢的点更高关注度;同时引入全局缩放因子以维持有效学习率稳定。与传统使用固定权重或简单基于残差大小的自适应方法相比,该方法更精细地刻画了训练过程中的时空异质性,并提供了训练稳定性的理论分析。在二维和三维的规则域、具有解析解的亥姆霍兹方程数值实验中,该方法相对于标准PINN显著降低了预测误差(二维相对L2误差从5.70e-3降至7.85e-4,三维从8.02e-3降至9.55e-4),并将训练时间缩短至约一半。该研究为利用PINN进行复杂声场重建提供了一种更高效的训练框架,但其在复杂实际问题中的有效性仍需进一步验证。主要局限性是实验场景过于简单,未与其它先进的自适应PINN方法进行直接对比,且缺乏对超参数敏感性和泛化能力的分析。
🏗️ 模型架构
论文所提出的改进型PINN整体架构如图1所示。其核心是在标准PINN框架上增加了自适应加权模块。
- 输入与输出:输入为空间坐标 x(例如二维的(x, y)),输出为神经网络预测的声压场 uθ(x)。该网络被设计为输出双通道,分别对应复声压的实部和虚部。
- 主网络:使用一个全连接神经网络来近似解。实验中,二维问题采用5层、每层128个神经元的网络,三维问题采用6层、每层128个神经元的网络,激活函数为正弦函数(SIREN),权重初始化使用Glorot uniform。
- 损失函数构建:网络训练目标是最小化一个加权复合损失函数 L(θ; w, s, γ)(公式14)。该函数包含两部分:
- PDE残差项:在域内采样点 XR 上计算亥姆霍兹算子施加于网络输出得到的残差 R(x) 的平方,并乘以逐点权重 w^R_i 和系数 γ^R。
- 边界残差项:在边界采样点 XB 上计算边界条件残差 B(x) 的平方,并乘以逐点权重 w^B_i 和系数 γ^B。
- 自适应加权模块(核心创新):这是区别于标准PINN的关键组件。
- 逐点权重 w_i:其值动态更新,基于“逆残差衰减率”IRDR(公式6),该指标用当前残差的平方除以历史残差四阶矩的平方根,对收敛慢的点(IRDR高)赋予更大权重。权重通过指数滑动平均(EMA)更新以平滑波动(公式7)。
- 全局缩放因子 s:一个乘在损失函数外的标量,其调整旨在使有效学习率 η 保持在理论稳定条件(公式9)允许的最大值附近,从而加速收敛。s 也通过EMA更新(公式11)。
- 权重归一化:所有逐点权重的平均值被约束为1(公式5),以确保加权后的损失尺度与原损失一致。
- 小批量与异步更新:为了扩展到大规模问题,论文引入了异步更新机制,对采样点的时间补偿EMA更新(公式12,13),以保证在随机采样和小批量训练下权重和统计量的无偏估计。
- 训练:使用Adam优化器最小化上述综合损失函数。
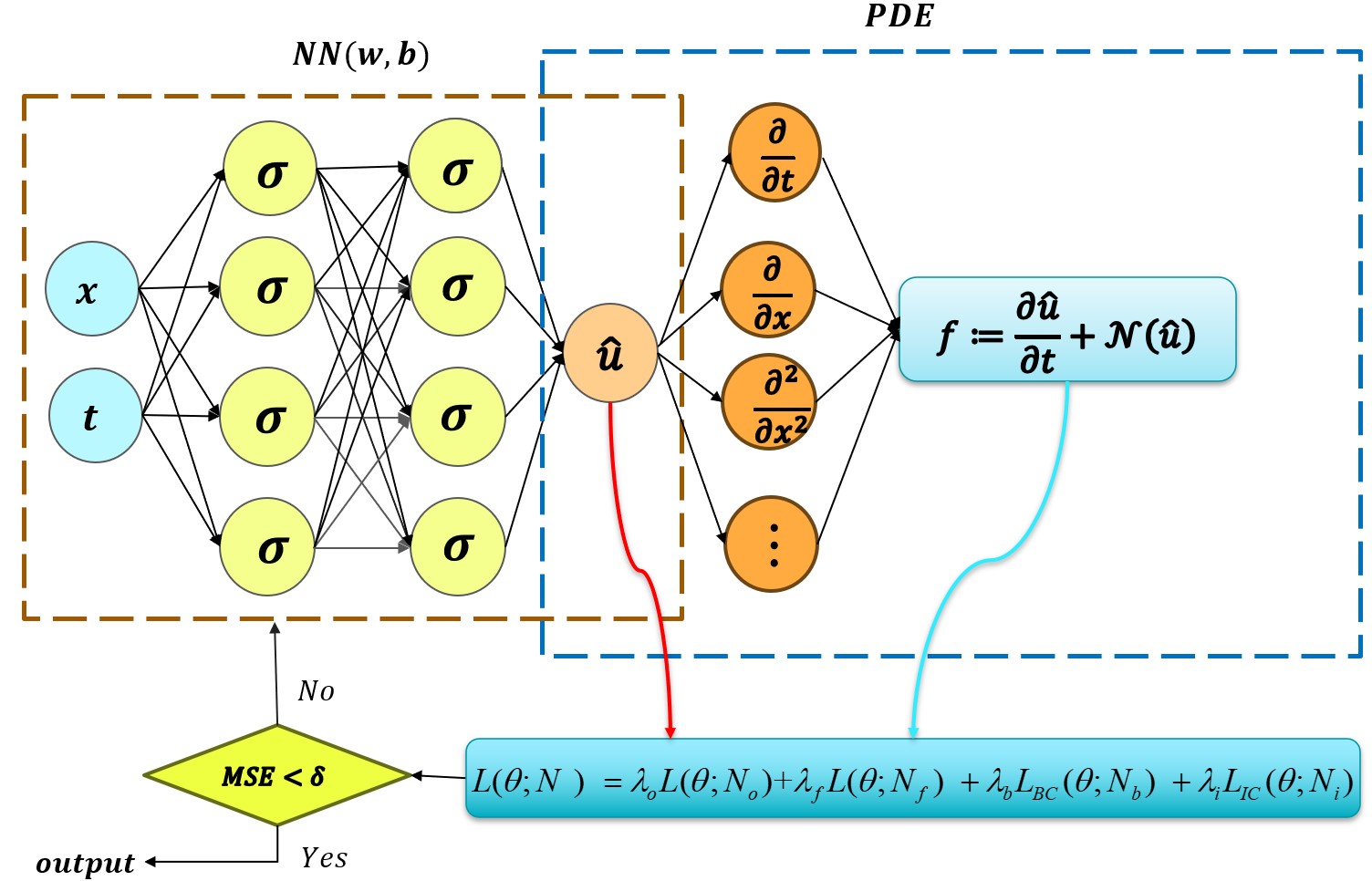 图1 展示了用于亥姆霍兹问题的物理信息神经网络架构。输入空间坐标,通过全连接网络得到声压预测。损失函数由加权的PDE残差和边界残差组成,其中权重w和全局缩放因子s由自适应模块动态计算。
图1 展示了用于亥姆霍兹问题的物理信息神经网络架构。输入空间坐标,通过全连接网络得到声压预测。损失函数由加权的PDE残差和边界残差组成,其中权重w和全局缩放因子s由自适应模块动态计算。
💡 核心创新点
- 基于逆残差衰减率(IRDR)的逐点自适应权重:不同于仅根据当前残差大小或随机采样,该方法利用历史残差的四阶矩统计量(公式6)来量化每个点的收敛“困难程度”。IRDR高的点被赋予更高权重,从而将优化资源动态集中在收敛慢的区域,直接针对PINN训练中损失项收敛异质性这一核心痛点。
- 动态全局缩放因子 s 以维持稳定学习率:通过理论推导(公式8-10),论文建立了全局缩放因子 s 与有效学习率 η 及损失函数曲率的关系。通过动态调整 s,旨在使训练过程始终以接近最优的学习率进行,防止在损失曲率大的区域出现不稳定,这是一种新颖的训练稳定性控制机制。
- 适配小批量训练的异步更新框架:论文将逐点权重和四阶矩统计量的更新推广到随机采样场景(公式12-13),通过时间补偿的EMA,使自适应策略能够应用于更实际的小批量训练设置,增强了方法的可扩展性。
🔬 细节详述
- 训练数据:论文未使用现有标准数据集。数据是作者根据亥姆霍兹方程的解析解(公式17和20)在规则域(二维[0,1]²,三维[0,1]³)内自行构造的。训练点(配置点)在域内和边界上随机采样,但未说明具体采样策略(如均匀、拉丁超立方)和每轮采样数量。三维问题中提到“每150次迭代重新随机采样训练点”。
- 损失函数:如公式(14)所示: L(θ; w, s, γ) = s [ γ^R/NR Σ w^R_i R²(x^R_i) + γ^B/NB Σ w^B_i B²(x^B_i) ]。其中 R 是PDE残差,B是边界条件残差。γ^R和γ^B是预设系数,实验中未说明具体值,可能设为1。
- 训练策略:
- 优化器:ADAM。
- 学习率:三维实验明确为0.001,二维实验未明确说明,可能相同。
- 训练步数:三维实验为20,000次迭代,二维实验未说明。
- Batch size:未说明是全批量还是小批量。但论文提到了小批量训练和异步更新机制,暗示使用了小批量。
- 调度策略:学习率未提及调度策略,可能为常数。自适应权重w和缩放因子s本身在训练过程中动态调整。
- 关键超参数:
- 网络结构:二维:5隐藏层,每层128神经元;三维:6隐藏层,每层128神经元。激活函数:sin。初始化:Glorot uniform。
- 自适应策略参数:平滑因子 β_w 和 β_s 未在实验部分给出具体值。稳定性参数 ε 未说明。所有自适应参数初始化为1。
- 其他:波数 k = 4π (λ=0.5)。γ^R, γ^B 未说明。
- 训练硬件:论文中未提及GPU型号、数量或训练时长。
- 推理细节:无。PINN在训练完成后直接输出预测值,无需解码。
- 正则化或稳定训练技巧:核心的自适应权重和缩放因子机制本身就是一种训练稳定技巧。此外,权重归一化(公式5)和EMA更新也是稳定措施。
📊 实验结果
论文在二维和三维两个数值算例上进行了验证,并与“原始PINN”(标准PINN,即使用固定权重)进行了对比。
表1:二维亥姆霍兹方程求解性能对比
| 方法 | 相对L2误差 | 训练时间占比 |
|---|---|---|
| 原始PINN | 5.70 × 10⁻³ | 100% |
| 改进PINN(本文) | 7.85 × 10⁻⁴ | 47.3% |
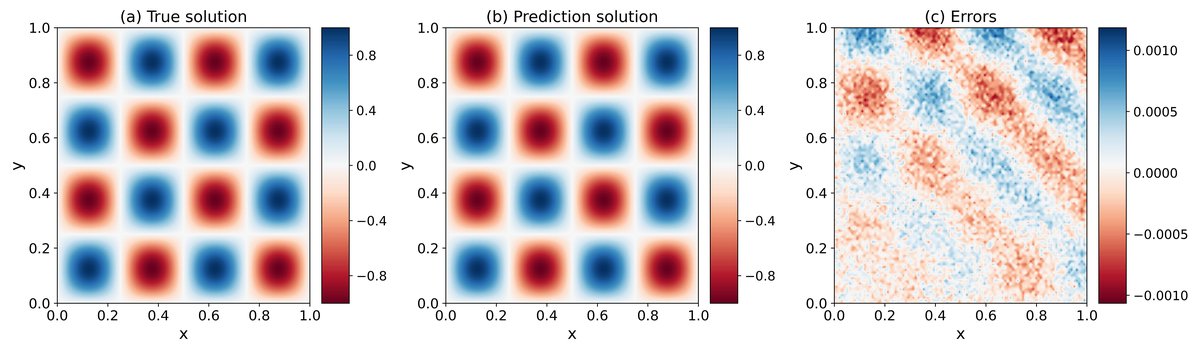 图2 展示了二维问题的精确解与改进PINN预测解,视觉上吻合良好。
图2 展示了二维问题的精确解与改进PINN预测解,视觉上吻合良好。
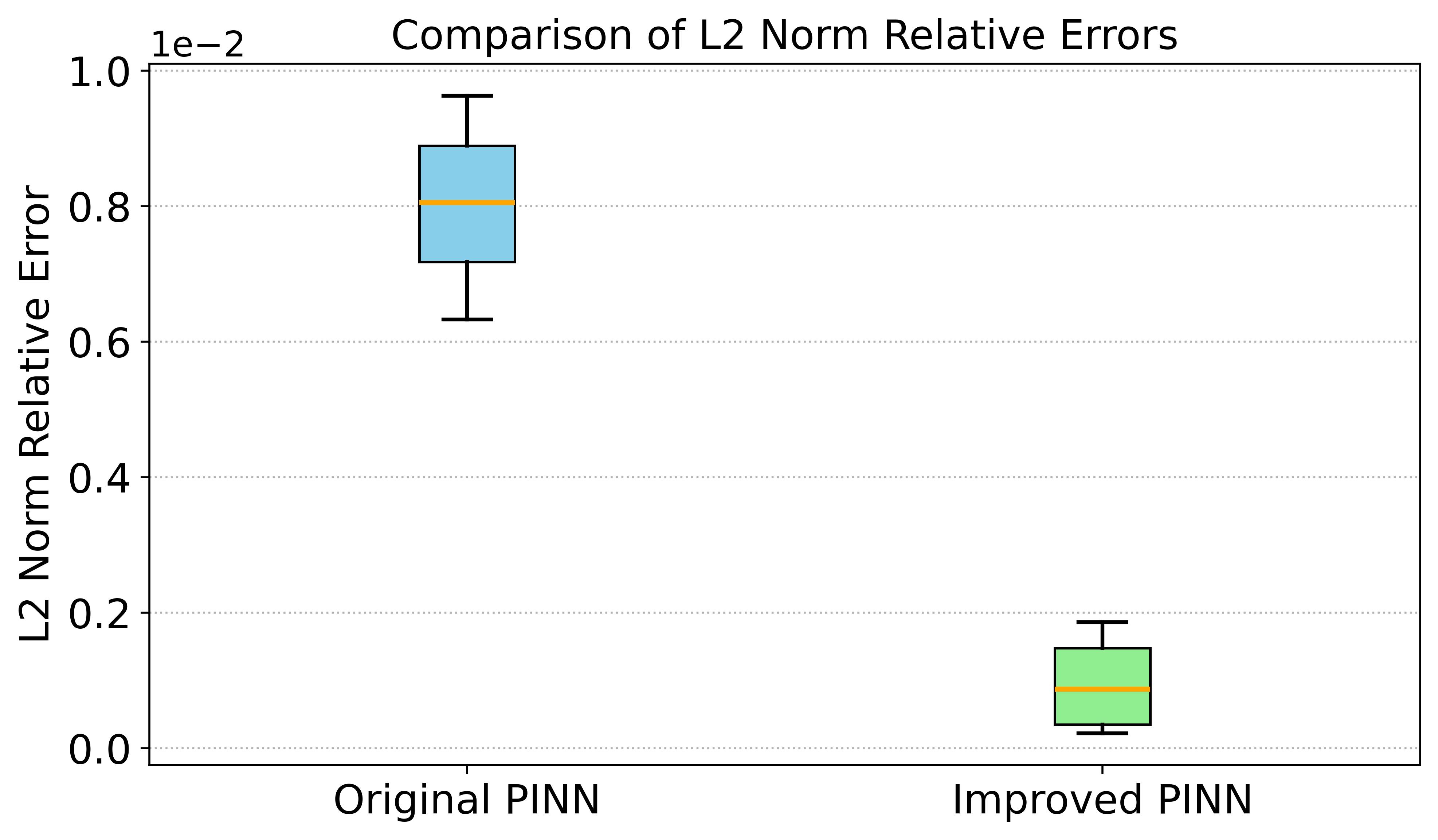 图3 展示了二维问题的预测误差统计分析,表明改进PINN的误差在幅值和不确定性上均显著低于原始PINN。
图3 展示了二维问题的预测误差统计分析,表明改进PINN的误差在幅值和不确定性上均显著低于原始PINN。
表2:三维亥姆霍兹方程求解性能对比
| 方法 | 相对L2误差 | 训练时间占比 |
|---|---|---|
| 原始PINN | 8.02 × 10⁻³ | 100% |
| 改进PINN(本文) | 9.55 × 10⁻⁴ | 50.7% |
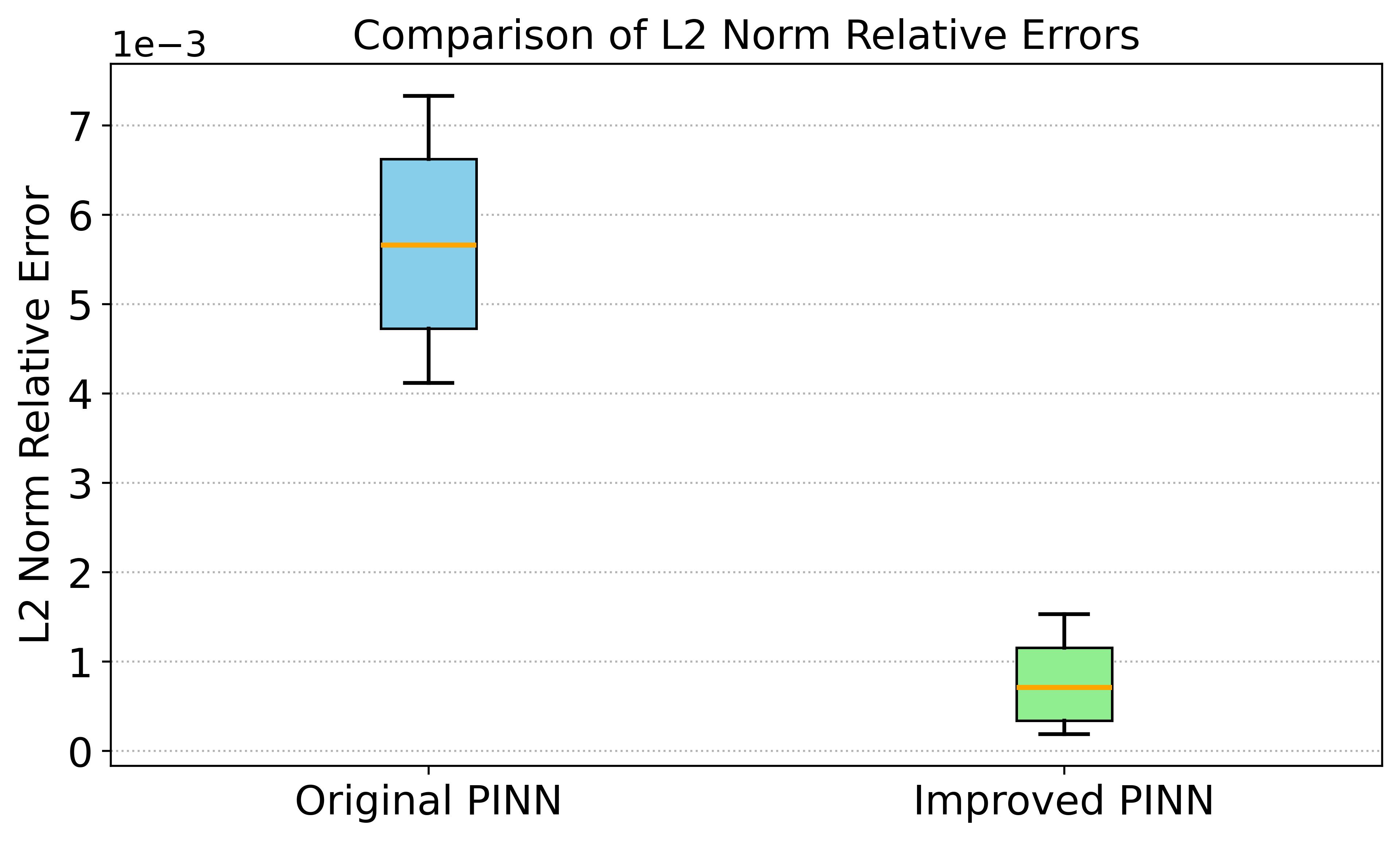 图4 展示了三维问题的精确解与改进PINN预测解,同样显示出高一致性。
图4 展示了三维问题的精确解与改进PINN预测解,同样显示出高一致性。
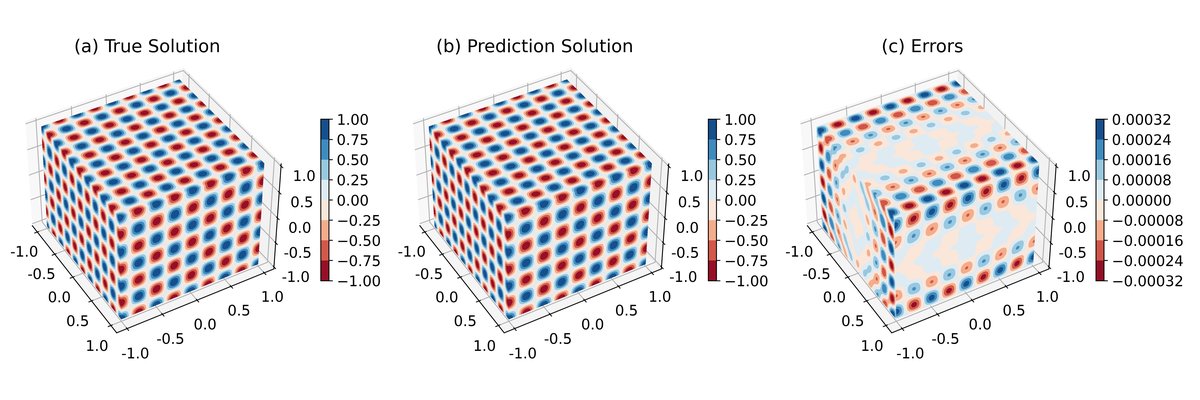 图5 展示了三维问题的预测误差统计分析,进一步证实了改进方法在降低误差幅度和方差方面的优势。
图5 展示了三维问题的预测误差统计分析,进一步证实了改进方法在降低误差幅度和方差方面的优势。
主要结论:
- 精度提升:在二维和三维测试中,改进PINN的相对L2误差分别比原始PINN降低了约一个数量级。
- 加速收敛:训练时间分别减少至原始方法的47.3%和50.7%。
- 实验局限性:所有实验均在具有解析解的规则立方体域上进行,边界条件简单(Dirichlet或Neumann),未涉及复杂几何、高频波、非齐次边界或逆问题。未与其他文献中提出的自适应PINN方法(如[18])进行对比。
⚖️ 评分理由
- 学术质量:5.0/7。创新性在于将高阶矩统计量和动态缩放因子引入自适应权重设计,技术思路有一定新意且推导自洽。然而,实验验证的充分性是最大短板:仅用两个“玩具”算例验证,缺乏与SOTA方法的对比和对复杂场景的测试,使得结论的普适性和影响力大打折扣。技术正确性基于标准PINN框架扩展,假设成立。
- 选题价值:1.5/2。求解亥姆霍兹方程是声学、地震学的经典问题,改进PINN训练效率是当前研究热点,选题具有明确的理论意义和应用潜力。
- 开源与复现加成:-0.5/1。论文未提供代码,关键自适应超参数(β_w, β_s, ε)的具体取值未在实验部分详细列出,尽管网络结构和优化器信息已知,但完全复现其自适应策略存在不确定性。