📄 Snore Sound Classification Based on Physiological Features and Adaptive Loss Function
#音频分类 #时频分析 #信号处理 #生物声学 #鲁棒性
✅ 6.5/10 | 前25% | #音频分类 | #时频分析 | #信号处理 #生物声学
学术质量 5.5/7 | 选题价值 1.2/2 | 复现加成 0.1 | 置信度 高
👥 作者与机构
- 第一作者:Hongxi Wu(中国科学院声学研究所、中国科学院大学)
- 通讯作者:Xueshuai Zhang(中国科学院声学研究所、中国科学院大学),Qingwei Zhao(中国科学院声学研究所、中国科学院大学)
- 作者列表:Hongxi Wu(中国科学院声学研究所、中国科学院大学)、Xueshuai Zhang(中国科学院声学研究所、中国科学院大学)、Shaoxing Zhang(北京大学第三医院)、Qingwei Zhao(中国科学院声学研究所、中国科学院大学)、Yonghong Yan(中国科学院声学研究所、中国科学院大学)
💡 毒舌点评
亮点:将鼾声病理生理机制(气道阻塞导致的高能爆发、不稳定频谱)巧妙地转化为具体的音频特征(STD、SIM)和损失函数权重设计,使模型具有明确的医学可解释性,而非黑箱。 短板:整体贡献更像一个精心设计的工程流水线,而非具有广泛影响力的模型创新。在未公开核心数据集和代码的情况下,其声称的性能增益难以被社区独立验证和直接应用。
🔗 开源详情
- 代码:论文中未提及代码链接或开源计划。
- 模型权重:未提及。
- 数据集:数据集来源于北京大学第三医院,但论文未提及是否公开或如何申请获取。
- Demo:未提及。
- 复现材料:论文提供了详细的训练配置(优化器、学习率调度、batch size、epoch数)、特征提取参数(FFT点数、滤波器数、帧长帧移)以及关键超参数(高能量帧比例20%、损失函数中的k和α),复现所需的核心技术细节较为充分。
- 论文中引用的开源项目:未明确提及依赖的开源工具或模型。使用了华为M5平板进行数据采集,但这不是软件工具。
📌 核心摘要
- 问题:传统多导睡眠图(PSG)侵入性强、成本高,阻碍了阻塞性睡眠呼吸暂停(OSA)的广泛筛查。基于鼾声的非接触分析受噪声、数据不平衡和特征可解释性差的困扰。
- 方法核心:提出一个生理学启发的鼾声分类框架,包括:a) 高能量帧选择:选取能量最高的20%帧,以抑制边界噪声并聚焦于区分性最强的病理声学区域;b) 三个生理特征提取:从高能量帧中提取频带能量比(ER)、帧位置时间标准差(STD)和帧间频谱余弦相似度(SIM),分别对应频域能量分布、时间集中度和频谱稳定性;c) 自适应能量比损失函数:根据样本的ER值动态调整病理性鼾声类别的损失权重,以缓解类别不平衡并强调典型病理模式。
- 创新点:与传统数据驱动特征相比,新方法的核心在于特征设计的生理可解释性以及损失函数的自适应性,两者均根植于病理鼾声与简单鼾声的声学差异。
- 实验结果:在来自北京大学第三医院的115例患者数据集上进行验证。最佳配置(特征拼接 + 自适应损失,k=4, α=2)相比基线,AUC提升1.9%(0.819→0.838),准确率(ACC)提升2.3%(75.7%→78.0%),非加权平均召回率(UAR)提升3.3%(72.3%→75.6%),病理性鼾声的灵敏度(SEN)提升6.9%(58.5%→65.4%),同时特异性(SPE)保持可比水平。关键实验结果如下表所示:
表2:不同生理特征对鼾声分类性能的影响
| Method | AUC | ACC(%) | UAR(%) | SEN(%) | SPE(%) |
|---|---|---|---|---|---|
| Base | 0.819 | 75.7 | 72.3 | 58.5 | 86.1 |
| + ER | 0.825 | 75.7 | 71.1 | 52.5 | 89.8 |
| + STD | 0.826 | 75.9 | 73.2 | 62.2 | 84.3 |
| + SIM | 0.836 | 76.3 | 73.6 | 62.4 | 84.8 |
| + STD + SIM + ER | 0.827 | 76.0 | 72.7 | 59.3 | 86.1 |
表3:自适应能量比损失函数性能(节选关键行)
| Method | Concat | (k, α) | AUC | ACC(%) | UAR(%) | SEN(%) | SPE(%) |
|---|---|---|---|---|---|---|---|
| Base | × | – | 0.819 | 75.7 | 72.3 | 58.5 | 86.1 |
| Adaptive Loss | ✓ | (4,2) | 0.838 | 78.0 | 75.6 | 65.4 | 85.7 |
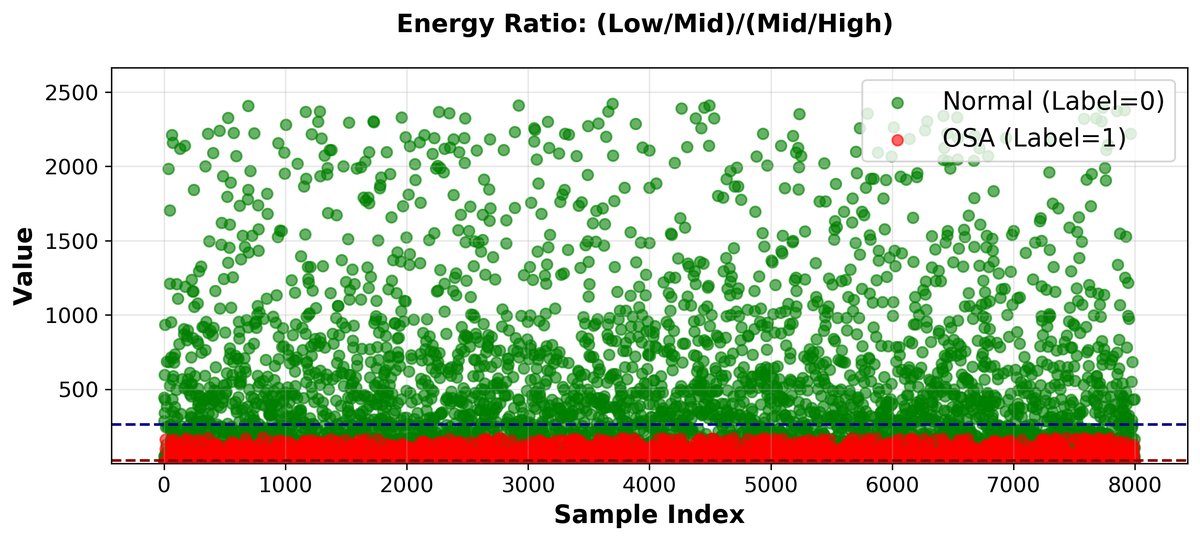 图2展示了三个生理特征(ER、STD、SIM)在简单鼾声(蓝色)和病理性鼾声(橙色)上的箱线图分布。STD和SIM特征显示出明显的可分性:病理性鼾声的STD更高、SIM更低。
图2展示了三个生理特征(ER、STD、SIM)在简单鼾声(蓝色)和病理性鼾声(橙色)上的箱线图分布。STD和SIM特征显示出明显的可分性:病理性鼾声的STD更高、SIM更低。
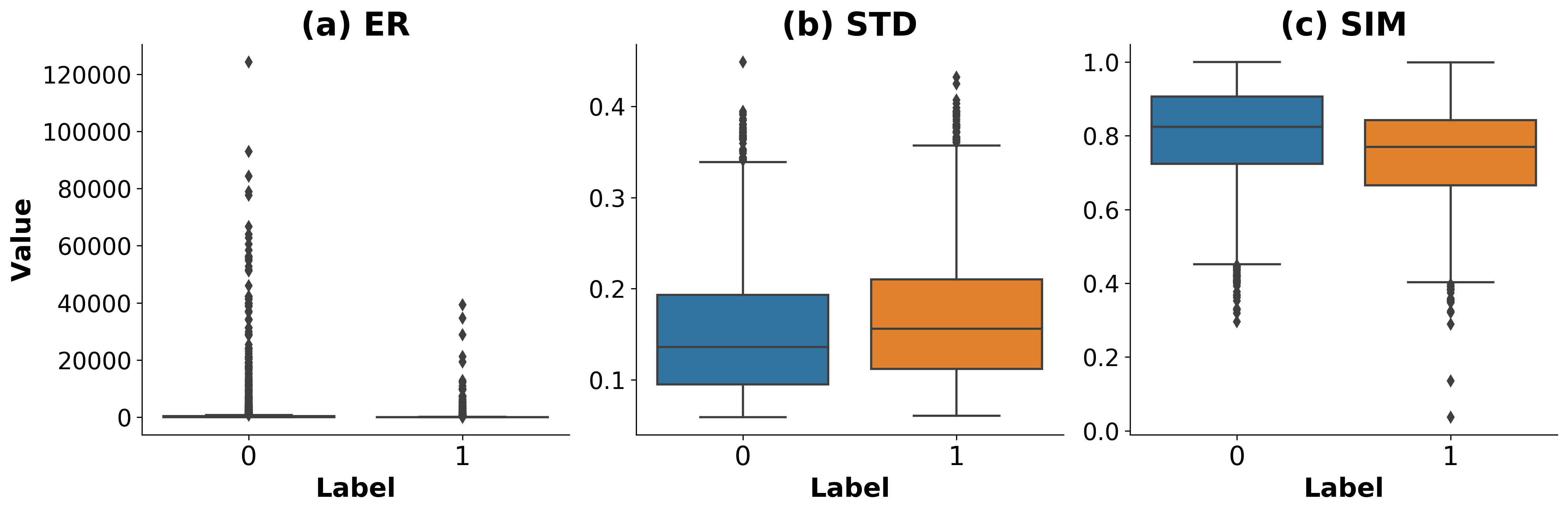 图3展示了10,000个鼾声片段的频带能量比(ER)分布,简单鼾声整体呈现更高的ER值,而病理性鼾声的ER值相对集中且较低。
图3展示了10,000个鼾声片段的频带能量比(ER)分布,简单鼾声整体呈现更高的ER值,而病理性鼾声的ER值相对集中且较低。
- 实际意义:为家庭环境下的OSA非接触、可解释筛查提供了一种有潜力的技术方案,模型决策过程具有明确的生理依据。
- 主要局限性:a) 数据源单一(仅一家医院),模型的泛化性未验证;b) 核心创新集中在特征工程和损失函数,分类网络本身较为常规;c) 论文未提供公开数据集或代码,限制了复现与后续研究。
🏗️ 模型架构
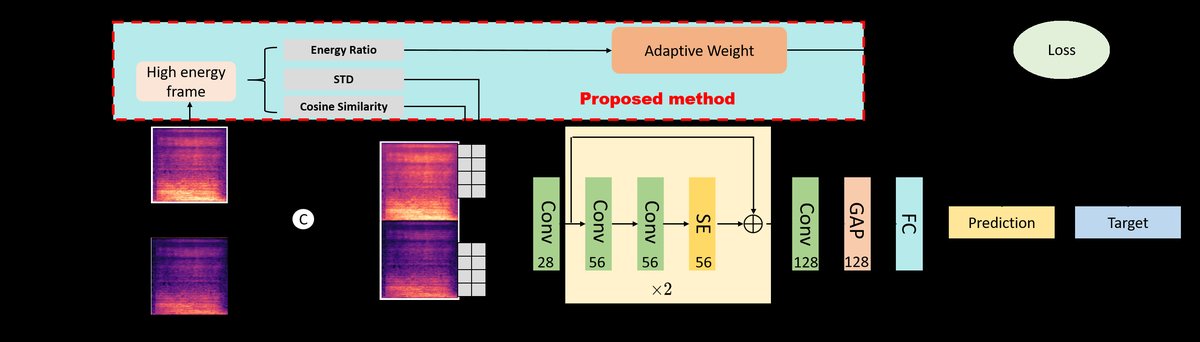 图1:提出方法的流程图。SE表示Squeeze-and-Excitation模块,GAP表示全局平均池化,Adaptive Weight根据能量比调整损失。
图1:提出方法的流程图。SE表示Squeeze-and-Excitation模块,GAP表示全局平均池化,Adaptive Weight根据能量比调整损失。
整体架构:该方法是一个特征工程+浅层神经网络的流程,而非端到端的深度学习模型。其架构可分为三个主要阶段,如图1所示:
输入与高能量帧选择:
- 输入:原始音频信号被转换为梅尔频谱图(Mel Spectrogram)。
- 处理:根据公式(1),计算每帧的总能量
e_t,并选取能量最高的20%帧,构成高能量帧集合T_high,用于后续特征提取。此步骤旨在降噪并聚焦于信息量最大的部分。
特征提取与表示:
- 该阶段分为两个并行路径:
- 路径A - 基础特征:对梅尔频谱图进行处理,可能涉及其他变换(如论文中提到的小波频谱图),得到基础的时频表示。
- 路径B - 生理特征:仅从
T_high中提取三个互补特征:- 频带能量比(ER):根据公式(2)-(3),计算低、中、高三个频带的平均能量,然后计算非线性比率
ER = (E_H * E_L) / (E_M)^2。 - 帧位置时间标准差(STD):根据公式(4),计算高能量帧归一化时间位置的标准差,衡量其时间集中度。
- 帧间频谱余弦相似度(SIM):根据公式(5)-(6),计算所有相邻高能量帧频谱向量的余弦相似度均值,衡量频谱稳定性。
- 频带能量比(ER):根据公式(2)-(3),计算低、中、高三个频带的平均能量,然后计算非线性比率
- 特征融合:三个生理特征(ER经量化)与基础特征沿时间轴拼接(Concat),形成增强后的特征表示。图1中展示了特征提取后经过“SE”(Squeeze-and-Excitation)模块和“GAP”(全局平均池化)的过程,这属于特征聚合与维度压缩。
- 该阶段分为两个并行路径:
分类与自适应损失:
- 融合后的特征被输入到一个分类网络中(论文未详述网络结构,图中示意为全连接层)。
关键创新在于损失函数(图1中的“Adaptive Weight”)。在训练时,根据当前样本的ER值和病理性样本的平均ER值
E0,通过公式(7)计算一个动态权重weight,该权重仅应用于病理性样本(y=1)。最终的损失loss = weight CEloss(公式8)。这个机制使得模型能够自适应地关注那些ER值接近典型病理模式E0的样本。
- 融合后的特征被输入到一个分类网络中(论文未详述网络结构,图中示意为全连接层)。
关键创新在于损失函数(图1中的“Adaptive Weight”)。在训练时,根据当前样本的ER值和病理性样本的平均ER值
设计动机与交互:整个架构的核心动机是将病理生理知识编码到特征和训练目标中。高能量帧选择对应“病理鼾声在气道重新开放时产生突发高能”的认知;三个特征分别对应频域分布、时域集中度和频域稳定性;自适应损失则对应“简单鼾声ER通常更高”的统计规律,动态调整学习重点。
💡 核心创新点
高能量帧选择策略:
- 是什么:在特征提取前,仅保留梅尔频谱图中能量最高的20%帧。
- 局限:传统方法通常使用所有帧或固定窗口,易受边界噪声和低信噪比帧干扰。
- 如何起作用:基于病理鼾声(高能爆发)与简单鼾声(平稳)的生理差异,通过能量阈值筛选,自动聚焦于最具判别性的声学事件。
- 收益:提升了模型对关键病理声学模式的感知能力,增强了对噪声的鲁棒性。
生理可解释的辅助特征(ER, STD, SIM):
- 是什么:设计了三个具有明确生理对应意义的统计特征。
- 局限:数据驱动特征(如直接从频谱图学习)缺乏可解释性,可能学习到与病理无关的模式。
- 如何起作用:ER捕捉频域能量向高频或低频的偏移(与气道狭窄相关);STD量化高能事件的时间聚集度;SIM度量频谱结构的稳定性。
- 收益:为分类决策提供了医学上的可解释性,并实验证明能提升分类性能(表2)。图2直观展示了STD和SIM的可分性。
基于频带能量比的自适应损失函数:
- 是什么:一种动态损失加权机制,权重由样本自身的ER特征和全局病理ER均值共同决定。
- 局限:传统的类别平衡方法(如固定权重、Focal Loss)缺乏生理依据,可能无法精准聚焦于最具代表性的病理模式。
- 如何起作用:当病理性样本的ER值接近该类别的典型值
E0时,获得最大权重;偏离时(可能是噪声或变异样本),权重降低。这引导模型更专注于学习“标准”的病理模式。 - 收益:在缓解类别不平衡的同时,提升了模型对典型病理鼾声的识别灵敏度,并保持了整体分类平衡(表3)。
🔬 细节详述
训练数据:
- 数据集名称:未公开命名,来源于北京大学第三医院耳鼻咽喉头颈外科睡眠实验室。
- 来源与规模:115名患者。使用华为M5平板在PSG监测期间,以16kHz采样率、0.5米距离录制睡眠音频。
- 预处理与标注:由经验丰富的耳鼻喉科医生基于PSG报告进行标注,病理鼾声(呼吸暂停期间)标记为“OSA”,其他标记为“Normal”。数据按患者级别随机划分为训练集(80人,46092段)、验证集(12人,5011段)和测试集(23人,11851段)。具体事件数量见表1。
- 数据增强:未明确提及传统数据增强方法。其“高能量帧选择”可视为一种基于信号强度的数据筛选策略。
损失函数:
- 名称:自适应能量比损失函数(Adaptive Energy Ratio Loss Function)。
- 作用:为病理性鼾声样本(y=1)分配动态权重,以处理类别不平衡并增强模型对典型病理模式的敏感性。
- 权重:权重公式为
weight = 1 + α [1 - σ(k (log E - log E0))] * I{y=1}。其中E是当前样本的ER,E0是病理性样本的平均ER,σ是sigmoid函数,k控制过渡陡度,α缩放最大权重。论文探索了k和α的不同组合(见表3)。
训练策略:
- 优化器:Adam,权重衰减设为1e-4。
- 学习率调度:余弦退火+热重启(Cosine Annealing with Warm Restarts)。初始学习率1e-4,
T0=15,Tmult=2。 - Batch Size:64。
- 训练轮数:90个epoch。
- 特征输入:梅尔频谱图与小波频谱图沿频率轴拼接。参数:1024点FFT,128个梅尔滤波器,帧移256,帧长1024。
关键超参数:特征工程参数(如ER的频带划分0-1kHz,1-3kHz,3-8kHz;高能量帧占比20%)和损失函数超参数(k, α)是关键。分类网络的具体结构(层数、维度)未说明。
训练硬件:未说明。
推理细节:未说明(如是否有特定的解码策略)。分类网络应直接输出概率。
正则化或稳定训练技巧:使用了学习率热重启策略以应对训练数据的变异性。
📊 实验结果
主要Benchmark:在自定义的、来自北京大学第三医院的鼾声数据集上进行评估。
主要指标与数值:实验旨在验证两个主要贡献:生理特征的有效性和自适应损失函数的有效性。
生理特征贡献(表2):在基线模型(Base,可能仅使用基础梅尔-小波特征)上,逐一添加ER、STD、SIM特征。结果表明,SIM特征单独加入时提升最大(AUC +0.017, UAR +1.3%),而三个特征同时加入的收益反而低于SIM单独加入,论文归因于ER特征的主导作用可能削弱了其他特征的贡献。
自适应损失函数贡献(表3):该表对比了多种方法。关键发现:
- 固定损失权重(1:4)大幅提高灵敏度(SEN=81.3%),但严重损害准确率(ACC=72.5%)和特异性(SPE=67.2%),失去平衡。
- 本文提出的自适应损失函数(在不拼接STD+SIM特征的情况下,如
k=3, α=2),已能平衡提升各项指标(AUC 0.836, ACC 76.2%, UAR 75.5%, SEN 72.5%, SPE 78.5%)。 - 最佳性能:当自适应损失函数与特征拼接(Concat)结合,特别是
(k=4, α=2)设置时,取得最全面提升:AUC 0.838, ACC 78.0%, UAR 75.6%, SEN 65.4%, SPE 85.7%。与基线相比,SEN提升6.9%,且其他指标均有改善。 - 论文指出,在低能量帧高STD和低SIM的片段中,SIM特征尤为重要,能帮助模型识别被噪声掩盖的病理鼾声。
图2和图3提供了特征分布的可视化证据,支持了特征设计的合理性。实验结论通过与基线及部分先前工作(如Hu[18], Luo[19])的对比,以及详细的消融实验得出。
⚖️ 评分理由
- 学术质量:5.5/7:论文在方法设计上体现了清晰的生理学思路,特征工程和损失函数设计有创新性和可解释性。实验设计包含充分的消融研究,数据划分合理。但核心贡献局限于特征与损失函数的改进,未提出新的模型架构,技术深度和普适性有限。
- 选题价值:1.2/2:针对OSA家庭筛查的实际医疗需求,非接触式鼾声分析具有明确的应用价值和一定的市场潜力。然而,任务垂直,与主流音频/语音研究(如识别、合成)的关联度较弱,对更广泛领域的影响力有限。
- 开源与复现加成:0.1/1:论文提供了非常详尽的训练超参数、数据集统计和特征描述,为复现提供了良好基础。然而,完全未提供代码、预训练模型、数据集下载渠道或在线演示,这是重大的复现障碍。仅因其详细的描述给予微小加成。