📄 SIRUP: A Diffusion-Based Virtual Upmixer of Steering Vectors for Highly-Directive Spatialization with First-Order Ambisonics
#空间音频 #声源定位 #扩散模型 #波束成形 #麦克风阵列
✅ 7.0/10 | 前25% | #声源定位 | #扩散模型 | #空间音频 #波束成形
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 中
👥 作者与机构
- 第一作者:Emilio Picard(法国索邦大学,日本RIKEN高级智能项目中心)
- 通讯作者:未说明
- 作者列表:Emilio Picard(法国索邦大学,日本RIKEN高级智能项目中心)、Diego Di Carlo(日本RIKEN高级智能项目中心)、Aditya Arie Nugraha(日本RIKEN高级智能项目中心)、Mathieu Fontaine(法国巴黎电信学院LTCI实验室,日本RIKEN高级智能项目中心)、Kazuyoshi Yoshii(日本京都大学工程研究生院,日本RIKEN高级智能项目中心)
💡 毒舌点评
亮点:将图像领域的潜在扩散模型“上采样”思路巧妙地移植到空间音频的波束成形向量超分辨率问题上,是一个非常具体且聪明的类比应用,实验结果也清晰展示了在狭窄波束和低旁瓣方面的显著提升。短板:整篇论文的验证完全依赖于模拟数据,对于真实世界中复杂的声场、阵列误差和未知噪声的鲁棒性只字未提,这极大地限制了其结论的说服力和实际应用价值的判断。
🔗 开源详情
- 代码:论文明确提供了代码仓库链接
https://github.com/emilio-pcrd/sirup,并注明“upon acceptance”(接收后发布)。目前(基于论文阅读时间)可能尚未公开。 - 模型权重:未提及。
- 数据集:使用了公开的LibriSpeech数据集的部分音频(dev-clean文件夹)作为声源,但用于训练的房间脉冲响应和混合数据是论文作者自己模拟生成的,未提及是否会公开这些模拟数据或生成脚本。
- Demo:未提及。
- 复现材料:论文提供了详细的模型配置(参数量、训练超参数)、评估设置和损失函数描述,但训练硬件等关键信息缺失。
- 引用的开源项目:主要依赖
pyroomacoustics进行房间模拟,以及bss_eval工具包进行评估。
📌 核心摘要
- 问题:现有的高空间分辨率音频系统(如高阶Ambisonics, HOA)需要昂贵的麦克风阵列。常见的一阶Ambisonics(FOA)系统空间分辨率低,导致声源定位不精确,波束成形效果差。传统上混方法(先估计声源参数再渲染)会误差传播。
- 方法:本文提出SIRUP,一种基于潜在扩散模型的波束成形向量(SV)虚拟上混方法。其核心是直接学习将低阶FOA SV映射到高阶HOA SV的潜在空间。具体分为两步:首先,用变分自编码器(VAE)学习HOA SV的紧凑潜在表示;然后,训练一个以FOA SV为条件的扩散模型,在该潜在空间中生成高阶SV的嵌入。
- 创新:与传统“估计-渲染”级联方法不同,SIRUP直接操作和超分辨率波束成形向量本身,避免了中间参数估计误差的传播。它利用扩散模型在数据分布上的强大生成能力,学习FOA与HOA SV之间的复杂非线性映射。
- 结果:实验在模拟房间环境中进行。与FOA基线相比,SIRUP上混后的SV在声源定位(DOA误差)、空间滤波质量(-3dB波束宽度平均提升+10°,旁瓣抑制-9dB)和双声源语音分离(SIR,SAR等指标)上均取得显著改进,性能接近真实HOA系统。关键数据见表1与表2。
- 意义:为低成本FOA设备提供了一种软件方式,使其能够虚拟达到接近昂贵HOA设备的空间分析和渲染性能,对空间音频应用、机器人听觉等有潜在价值。
- 局限:所有实验基于模拟数据,缺乏真实世界复杂环境的验证;混响增大时,相对于HOA基线的优势减小;模型目前仅适用于单声源SV估计场景。
🏗️ 模型架构
SIRUP模型是一个条件潜在扩散模型,旨在将M通道的FOA SV(估计值或代数值)上混为M‘通道(M‘>M)的HOA SV。其整体流程分为训练和推理两个阶段,核心组件包括变分自编码器(VAE) 和潜在扩散模型(LDM)。
模型架构与数据流:
 图1:SIRUP用于下游任务的上混流程图。FOA信号首先经过STFT,然后从空间协方差矩阵(SCM)估计SV,接着SIRUP模型进行上混,最后进行波束成形、声源合成、DOA估计等。
图1:SIRUP用于下游任务的上混流程图。FOA信号首先经过STFT,然后从空间协方差矩阵(SCM)估计SV,接着SIRUP模型进行上混,最后进行波束成形、声源合成、DOA估计等。
输入与条件化:
- 输入:测量得到的M通道FOA SV ˆA ∈ ℂ^{F×M}(F为频率点数)。论文将复数SV表示为实部/虚部堆叠,因此实际张量形状为
(2, F, M)。 - 条件张量c:将FOA SV与大小为
F×(M‘-M)的零填充拼接,得到c = [ˆA, 0_{F×(M‘-M)}]。如果已知声源方向,未测量通道也可用代数SV填充。此条件张量c作为扩散模型的输入条件。
- 输入:测量得到的M通道FOA SV ˆA ∈ ℂ^{F×M}(F为频率点数)。论文将复数SV表示为实部/虚部堆叠,因此实际张量形状为
VAE组件:
- 编码器 Eϕ:将高阶的目标HOA SV(训练时)或条件化张量
c(推理时)编码到一个低维、紧凑的潜在空间z0。它学习HOA SV的本质特征。 - 解码器 Dψ:将潜在向量
z解码回SV空间,得到重建或生成的HOA SV ˆA_up ∈ ℂ^{F×M’}。 - VAE通过KL散度正则化,确保潜在空间具有良好的结构,便于扩散过程。
- 编码器 Eϕ:将高阶的目标HOA SV(训练时)或条件化张量
扩散模型:
- 这是一个在VAE潜在空间
z中运行的条件去噪扩散概率模型(DDPM)。 - 前向过程:将
z0逐步加噪至zT。 - 反向过程:一个UNet去噪网络 ϵθ(zt, t; Eϕ(c)) 被训练来预测噪声。其条件
Eϕ(c)通过两种方式注入UNet:1) 在输入层与噪声潜在表示zt拼接;2) 在网络块内通过交叉注意力。 - 推理时:从纯噪声
zT ~ N(0, I)开始,迭代去噪得到z0,然后解码得到上混后的HOA SVˆA_up。
- 这是一个在VAE潜在空间
关键设计选择:
- 直接上混SV:绕过传统的参数估计-渲染管线,减少误差传播。
- 潜在扩散:在VAE的低维潜在空间中进行扩散,计算效率更高,且能利用生成模型的强大分布学习能力。
- 条件注入:通过拼接和交叉注意力双重机制,确保FOA信息被充分用于指导高阶SV的生成。
- 网络改进:在UNet中沿频率轴引入扩张卷积,以增强跨频率的空间一致性。
💡 核心创新点
- 将潜在扩散模型应用于波束成形向量超分辨率:这是将先进的图像生成AI技术迁移到一个具体、重要的空间音频信号处理任务中的创新应用。之前的方法多为参数化或确定性映射,而SIRUP利用生成模型学习FOA与HOA SV之间的复杂分布映射。
- 直接上混波束成形向量(而非声源参数):与传统DirAC、COMPASS等“分析-渲染”框架不同,SIRUP直接操作底层的SV。这避免了DOA估计误差传播到波束成形或渲染阶段,且SV本身更丰富地编码了直达声和早期反射信息。
- 针对SV特性的复合损失与架构设计:为提升SV的重建质量,设计了结合余弦相似度、特征匹配和MSE的复合损失函数。引入频率轴扩张卷积以强制跨频率的空间相干性,这是对通用UNet架构针对音频SV数据的特定优化。
🔬 细节详述
- 训练数据:
- 数据集:使用pyroomacoustics库的图像源模型(ISM)模拟生成。
- 规模:生成了30个不同的房间声学场景。训练使用了3000对从单源含噪混合物中估计的测量FOA SV和对应的目标HOA SV。
- 预处理:音频采样率16kHz,使用512样本帧长、50%重叠、汉明窗的STFT。
- 数据增强:未明确提及,但场景参数(信噪比DSNR、混响时间RT60)在模拟时随机变化,可视为一种数据增强。
- 损失函数:
- VAE训练:结合了ℓ2重建损失、余弦损失、感知损失和KL散度项。
- 扩散模型训练:标准的噪声预测损失
E[||ϵ - ϵθ(zt, t, c)||^2]。
- 训练策略:
- 两阶段训练:第一阶段训练完整的VAE(编码器+解码器);第二阶段冻结编码器,仅微调解码器。
- 优化器:AdamW。
- 学习率:VAE阶段为 3e-4,解码器微调阶段使用指数学习率调度。
- 训练轮数:VAE阶段40 epochs,解码器微调20 epochs,扩散模型100 epochs。
- 扩散步数:训练时T=1000,推理时T=200。
- 关键超参数:
- 模型大小:VAE(3.1M参数),UNet扩散模型(4.1M参数)。
- 输入/输出通道:FOA输入 M=4,目标HOA M’=16。
- SV表示:将复数SV转为实部/虚部堆叠,因此通道维度为2。
- 训练硬件:未说明。
- 推理细节:从纯噪声出发,通过200步迭代去噪得到潜在码,再经解码器得到HOA SV。
- 正则化/稳定训练技巧:VAE的KL散度正则化;对潜在值进行缩放至[-1, 1];采用特征匹配损失提升学习稳定性。
📊 实验结果
实验在模拟环境中进行,评估了SSL性能、SV空间质量和波束成形性能。
主要Benchmark与数据集:模拟房间声学环境(DSNR设置:SNR变化[5,20]dB,RT60=0.2s;DRT60设置:RT60变化[0.2,0.7]s,SNR=20dB)。
主要指标与数值:
表1:不同空间表示的性能(30个模拟房间平均)
| 指标 | 方向 | FOA | SIRUP上混 | HOA(真实值) |
|---|---|---|---|---|
| DRT60 | DI [dB] ↑ | 10.0 ± 2.6 | 19.8 ± 2.3 | 20.0 ± 2.2 |
| 3-dB BW [°] ↓ | 30 ± 6 | 24.0 ± 3.3 | 24 ± 2 | |
| SL [dB] ↓ | -0.9 ± 0.7 | -9.5 ± 3.1 | -11.2 ± 2.8 | |
| DSNR | DI [dB] ↑ | 8.1 ± 2.7 | 17.1 ± 2.1 | 17.7 ± 2.0 |
| 3-dB BW [°] ↓ | 48.0 ± 6.7 | 27.0 ± 3.5 | 26.0 ± 2.2 | |
| SL [dB] ↓ | -1.2 ± 0.9 | -9.6 ± 3.4 | -11.7 ± 2.7 | |
| 注:DI(指向性指数,越高越好),3-dB BW(3分贝波束宽度,越窄越好),SL(旁瓣电平,越低越好)。 |
关键结论:SIRUP上混的SV在所有指标上均大幅优于FOA,波束宽度平均改善约10°,旁瓣抑制约9dB,且非常接近真实HOA的性能。
表2:双声源混合的源合成增强性能
| 方法 | SDR [dB] | SIR [dB] | SAR [dB] |
|---|---|---|---|
| 测量SV-FOA | 17.2 ± 3.2 | 38.8 ± 3.6 | 17.3 ± 3.2 |
| 测量SV-SIRUP-M | 17.4 ± 3.1 | 38.8 ± 3.3 | 17.4 ± 3.1 |
| 代数SV-FOA后SSL | 12.6 ± 7.4 | 33.5 ± 7.8 | 12.6 ± 7.3 |
| 代数SV-SIRUP后SSL | 13.0 ± 7.2 | 34.0 ± 7.5 | 13.0 ± 7.2 |
| 注:SDR(源失真比),SIR(源干扰比),SAR(源伪影比),均为越高越好。 |
关键结论:直接使用SIRUP输出的前M通道(SV-SIRUP-M)进行波束成形,性能略优于原始FOA测量SV,体现了模型的去噪能力。使用SIRUP进行SSL后再用代数SV波束成形(SV-alg SIRUP),性能也略优于FOA版本。
实验图表:
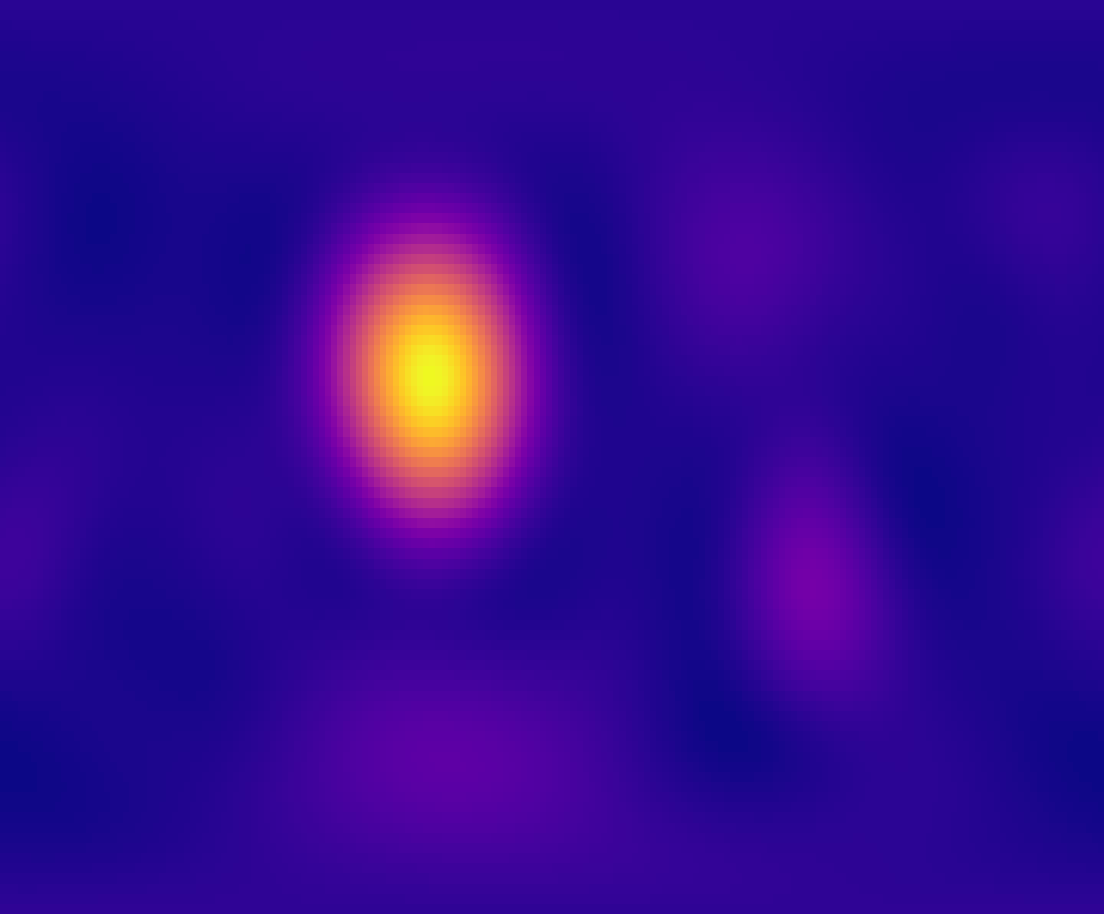 图2:不同定位方法和SV模型的平均角度误差。(a) SNR变化 (b) RT60变化。SIRUP在噪声条件下性能接近真实HOA,但随混响增加优势减弱。
图2:不同定位方法和SV模型的平均角度误差。(a) SNR变化 (b) RT60变化。SIRUP在噪声条件下性能接近真实HOA,但随混响增加优势减弱。
 图3:估计SV的2D热图对比。FOA的SV波束宽且有高旁瓣,而SIRUP上混后的SV与真实HOA SV同样尖锐,空间分辨率显著提升。
图3:估计SV的2D热图对比。FOA的SV波束宽且有高旁瓣,而SIRUP上混后的SV与真实HOA SV同样尖锐,空间分辨率显著提升。
⚖️ 评分理由
- 学术质量:6.5/7:创新性体现在模型迁移和直接上混SV的思路,技术实现清晰正确。实验设计系统,在模拟数据上进行了充分的定量对比,结果有说服力。主要扣分点在于完全依赖模拟数据,缺乏真实世界验证,且消融实验(如条件注入方式、损失函数各部分作用)描述不足。
- 选题价值:1.5/2:问题具体且实际,指向降低空间音频系统的硬件成本。对从事空间音频、波束成形、阵列信号处理的研究人员和工程师有直接参考价值。但受众面相对较窄。
- 开源与复现加成:-0.5/1:论文在“未来工作”或附录中提供了代码仓库链接(https://github.com/emilio-pcrd/sirup),这是一个积极信号。然而,论文提交时代码未公开,也未提及模型权重、完整训练数据、硬件环境等详细复现信息,因此无法给予高分,目前为负分。