📄 Sing What You Fit: A Perception-Based Dataset and Benchmark for Vocal-Song Suitability Analysis
#音乐信息检索 #监督学习 #数据集 #模型评估 #零样本
✅ 7.0/10 | 前25% | #音乐信息检索 | #监督学习 | #数据集 #模型评估
学术质量 5.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Yingzhou Zhao(大连理工大学计算机科学与技术学院)
- 通讯作者:Liang Yang(大连理工大学计算机科学与技术学院)
- 作者列表:Yingzhou Zhao(大连理工大学计算机科学与技术学院)、Jingjie Zeng(未说明)、Zewen Bai(未说明)、Liang Yang(大连理工大学计算机科学与技术学院)、Shaowu Zhang(未说明)、Hongfei Lin(未说明)
💡 毒舌点评
这篇论文最大的贡献是“开山立派”——为个性化唱歌推荐这个细分但实用的场景明确定义了任务(VSSA)并构建了首个专用数据集(VSS-Dataset),填补了从“听歌推荐”到“唱歌推荐”的关键空白,数据集构建的“跨库配对+动态调平+专家标注”流程也颇为扎实。然而,论文在方法层面的创新相对有限,监督学习基线大多直接套用现成模型(如ResNet处理梅尔谱),零样本评估也只是测试了通用MLLMs,并未提出为VSSA任务量身定制的新模型或学习范式,其“Spectrogram+ResNet”最优的结论更像是一次成功的应用验证而非方法突破。
🔗 开源详情
- 代码:论文中提供了数据集的GitHub仓库链接(https://github.com/zyz2002/VSS-Dataset/),但未明确说明是否同时提供基线模型的训练和评估代码。
- 模型权重:论文中未提及是否公开任何基线模型或MLLMs微调后的权重。
- 数据集:VSS-Dataset已通过上述GitHub链接公开,可获取标注文件,但原始音频文件的获取方式未在文中明确说明(可能需要遵循原始数据集MERGE, GTSinger, SingStyle111的许可协议)。
- Demo:论文中未提供在线演示。
- 复现材料:论文详细描述了数据集构建流程、标注协议、基线模型架构和训练超参数(学习率、批量大小、优化器),这为复现提供了重要信息。
- 论文中引用的开源项目:
- 数据源:MERGE [5], GTSinger [4], SingStyle111 [10]
- 工具:Demucs [17](用于音源分离)
- 预训练模型:Whisper [11], MERT [12]
- 基准模型:MFCC [20], ResNet [21]
- 评估MLLMs:Qwen2.5-Omni [13], Kimi-Audio [14], GPT-4o [15], Gemini-2.5-Pro [16]
📌 核心摘要
- 要解决什么问题:现有音乐推荐系统主要基于用户“听歌”偏好(听觉侧写),忽视了用户在用户生成内容(UGC)场景(如K歌、上传演唱)下的“唱歌”需求(歌手侧写),即“哪首歌最适合我的嗓音”这一关键问题。
- 方法核心是什么:提出了“人声-歌曲适配性分析”(VSSA)任务,并构建了首个配对数据集VSS-Dataset。数据集通过跨库匹配(将MERGE歌曲库与GTSinger/SingStyle111人声库配对)和三位音乐制作人专家在三个维度(音色-流派融合度、技巧-编排匹配度、情感表达一致性)上的标注而成,包含3203个样本对。同时,建立了包含监督学习基线和多模态大模型(MLLMs)零样本评估的基准测试。
- 与已有方法相比新在哪里:这是首次针对“人声与歌曲艺术适配性”这一主观感知任务,系统性地定义问题、构建专用数据集并设立基准。与现有数据集(如GTSinger专注人声合成、MERGE专注情感识别)相比,VSS-Dataset首次提供了配对的孤立人声与完整歌曲以及连续的适配性标签。
- 主要实验结果如何:监督学习中,基于梅尔谱的“Spectrogram + ResNet”模型表现最佳(MAE=0.1040, Pearson=0.8913);零样本评估中,Gemini-2.5-Pro表现最好(MAE=0.2154, Pearson=0.6703),但所有MLLMs的预测均表现出明显的量化效应。监督学习基线在准确率和趋势预测上均显著优于零样本模型。
| 模型/方法 | MAE (↓) | Pearson (↑) |
|---|---|---|
| 监督学习基线 | ||
| MFCC + MLP | 0.2048 | 0.6156 |
| Spectrogram + ResNet | 0.1040 | 0.8913 |
| MERT + Transformer | 0.3289 | 0.6971 |
| Whisper + Transformer | 0.1729 | 0.7182 |
| 零样本基线 | ||
| Kimi-Audio-7B | 0.3221 | 0.4326 |
| Qwen2.5-Omni-7B | 0.2198 | 0.4975 |
| GPT-4o | 0.2613 | 0.5021 |
| Gemini-2.5-Pro | 0.2154 | 0.6703 |
- 实际意义是什么:为个性化音乐推荐系统(MRS)开辟了新的维度,从单纯的“听觉推荐”拓展到“演唱推荐”,有望提升K歌应用等UGC音乐平台的用户体验和互动性。为相关研究提供了首个标准化的任务定义、数据集和评估基准。
- 主要局限性是什么:数据集规模(3k+)对于深度学习模型可能仍显有限,且通过跨库配对构建的数据可能存在分布偏差(如源数据集的风格限制)。任务定义高度依赖主观专家标注,标注的主观性和可重复性有待更大规模验证。论文未提出针对该任务设计的新模型,现有最佳方案依赖通用计算机视觉模型处理音频谱图,可能存在优化空间。
🏗️ 模型架构
本文的核心贡献并非提出一个新的端到端神经网络架构,而是为VSSA任务建立了评估基线。因此,架构分析主要围绕这四种监督学习基线展开,其共同目标是:给定一段孤立人声和一首完整歌曲,预测一个0到1的适配性得分。
MFCC + MLP 基线:
- 输入:分别将人声和歌曲音频重采样至16kHz,提取20维MFCC系数。 特征处理:对MFCC序列计算均值和标准差统计量,得到202*2=80维向量(人声和歌曲各40维)。
- 融合与预测:将人声和歌曲的统计向量拼接成一个80维向量,输入一个三层MLP,最终通过Sigmoid激活输出得分。
Spectrogram + ResNet 基线(表现最佳):
- 输入:将人声和歌曲音频重采样至22.05kHz,计算224维的梅尔频谱图。
- 特征提取:将梅尔谱图视为单通道图像,分别输入一个预训练且冻结的ResNet-18模型(原始用于图像分类),提取各512维的特征向量。
- 融合与预测:将人声和歌曲的特征向量拼接成1024维向量,通过一个包含ReLU和Dropout的两层MLP头(256->1)进行回归预测。
Whisper / MERT + Transformer 基线:
- 输入:Whisper将音频重采样至16kHz;MERT重采样至24kHz。
- 特征提取:分别使用预训练的Whisper-large-v3编码器和MERT-v1-330M编码器,提取上下文嵌入向量(Whisper为1280维,MERT维度未明确说明)。
- 融合与预测:将人声和歌曲的嵌入序列送入一个两层的Transformer编码器(4个注意力头)进行跨模态融合,经过平均池化后,接入全连接层和Sigmoid输出预测得分。此架构中,仅下游Transformer和预测头参数可训练。
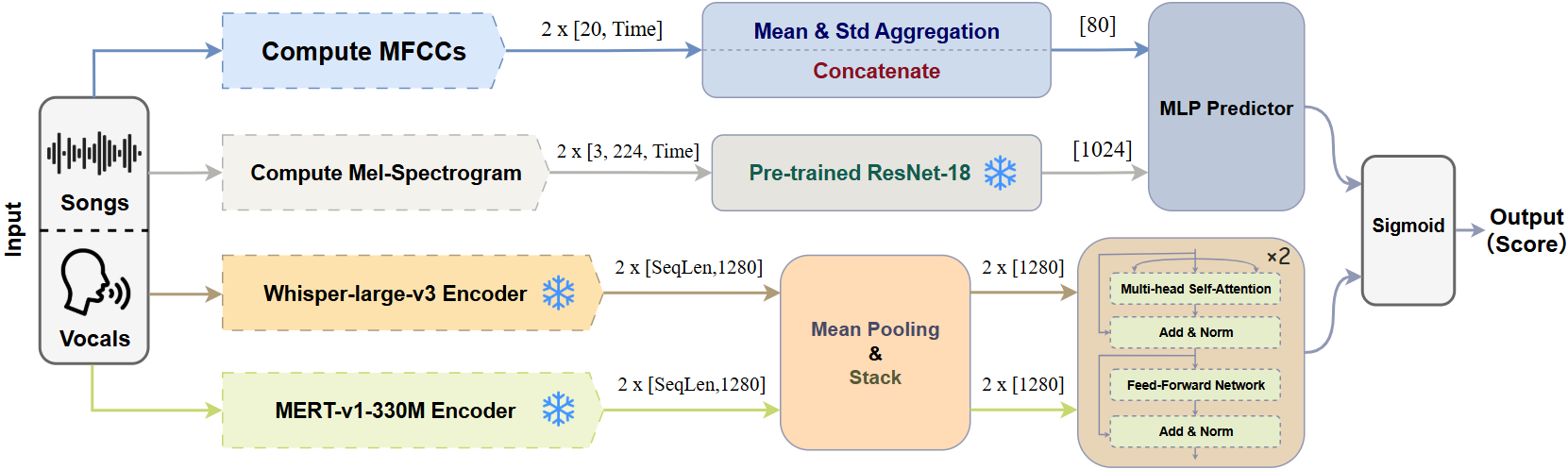 图3展示了四种监督学习基线的架构比较。左侧两幅为传统特征方法(MFCC+MLP和梅尔谱+ResNet),右侧两幅为预训练编码器方法(Whisper和MERT,它们共享相同的下游Transformer融合块)。
图3展示了四种监督学习基线的架构比较。左侧两幅为传统特征方法(MFCC+MLP和梅尔谱+ResNet),右侧两幅为预训练编码器方法(Whisper和MERT,它们共享相同的下游Transformer融合块)。
💡 核心创新点
- 首次定义“人声-歌曲适配性分析”(VSSA)任务:在音乐推荐领域,首次明确区分并针对“输出”(唱歌)推荐需求,提出一个全新的、基于主观感知的计算任务。之前的工作要么关注“输入”(听歌)推荐,要么聚焦于音乐信息检索(MIR)中的客观特征分析。
- 构建首个VSSA专用配对数据集(VSS-Dataset):通过创新的“跨数据集动态匹配”策略,解决了人声与歌曲数据长期分离的难题,构建了首个包含孤立人声、完整歌曲及多维度连续适配性标签的大规模配对数据集(3203样本)。其标注流程(三位专家+AI辅助质检)保证了数据质量。
- 建立全面的基准测试与深入分析:设计了涵盖传统机器学习(MFCC+MLP)、计算机视觉迁移(梅尔谱+ResNet)、音频预训练模型(Whisper, MERT)以及最新多模态大模型(MLLMs)零样本评估的基准。分析揭示了梅尔谱表示的优势、MLLMs的预测量化局限性,为后续研究指明了方向。
🔬 细节详述
- 训练数据:
- 数据集名称:VSS-Dataset。
- 来源:歌曲来自MERGE数据集;人声来自GTSinger和SingStyle111数据集。
- 规模:3203个配对样本,按8:2划分为2562个训练集和641个测试集。
- 预处理:对MERGE歌曲使用Demucs模型分离出干声,并进行人工听觉审核以排除有瑕疵的样本。对配对数据进行迭代分析与动态重配,以平衡分数分布。
- 数据增强:论文中未提及使用标准数据增强技术。
- 损失函数:对于监督学习,所有模型均最小化均方误差(MSE)损失,即预测得分与真实标注得分之间的平方差。
- 训练策略:
- 优化器:Adam。
- 学习率:1 × 10⁻⁴。
- Batch Size:因模型而异:MFCC+MLP为64,Spectrogram+ResNet为16,Whisper为1,MERT为4。
- 早停策略:基于验证集上的MAE进行早停。
- Warmup:论文中未提及warmup策略。
- 训练步数/轮数:未明确说明总epoch数或步数。
- 关键超参数:
- MFCC+MLP:20个MFCC系数,三层MLP。
- Spectrogram+ResNet:梅尔谱图mel bands=224,使用ResNet-18(输出512维),下游MLP头为256->1,Dropout率0.5。
- Whisper/MERT:下游Transformer为2层、4头,最后通过平均池化。
- 训练硬件:论文中未说明使用的GPU/TPU型号、数量和训练时长。
- 推理细节:论文中未详细说明推理时的解码策略、温度等,对于回归任务通常直接前向传播并取Sigmoid输出。
- 正则化或稳定训练技巧:在Spectrogram+ResNet的下游MLP中使用了Dropout(率0.5)。其他方法未明确提及。
📊 实验结果
论文在VSS-Dataset测试集(641样本)上进行了实验,评估指标为MAE(↓,越小越好)和Pearson相关系数(↑,越大越好)。
主要基准结果(如上文核心摘要中的表格所示):
- 监督学习:Spectrogram + ResNet显著领先,MAE低至0.1040,Pearson高达0.8913,表明梅尔谱特征结合强大的图像识别骨干网络能极好地捕捉适配性所需的声学直观特征。Whisper基线次之。MERT基线表现最差,可能与其预训练任务(侧重乐器和结构)对人声细微差别关注不足有关。
- 零样本评估:所有MLLMs均表现出一定理解能力,但性能远低于监督学习最优模型。Gemini-2.5-Pro在MAE和Pearson上均为最佳(0.2154, 0.6703)。误差分析(图4)显示,Gemini预测最稳定但略偏保守(误差分布偏负),其他模型预测方差更大。散点图(图5)揭示了所有MLLMs的输出存在量化效应(预测值集中在几个离散水平),这导致即使MAE不高,Pearson相关性也会受损。
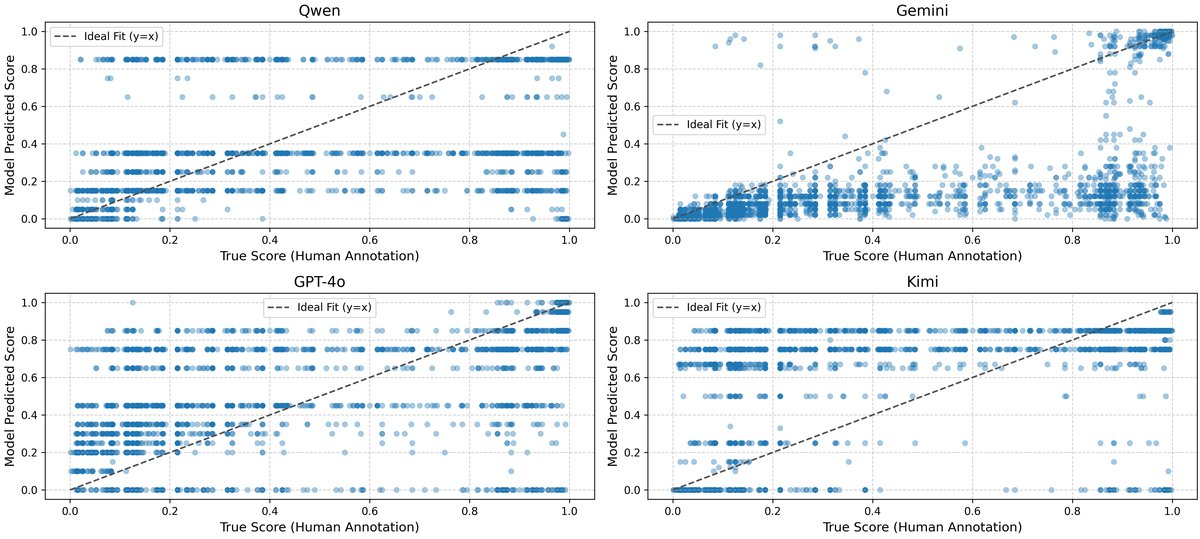 图4:多模态大模型在零样本评估中的误差分布图。横轴为预测值减去真实值(误差),纵轴为核密度估计。可见Gemini-2.5-Pro的误差分布最窄(最稳定),但中位数略低于0;其他模型分布较宽,且Kimi-Audio的分布呈现多峰。
图4:多模态大模型在零样本评估中的误差分布图。横轴为预测值减去真实值(误差),纵轴为核密度估计。可见Gemini-2.5-Pro的误差分布最窄(最稳定),但中位数略低于0;其他模型分布较宽,且Kimi-Audio的分布呈现多峰。
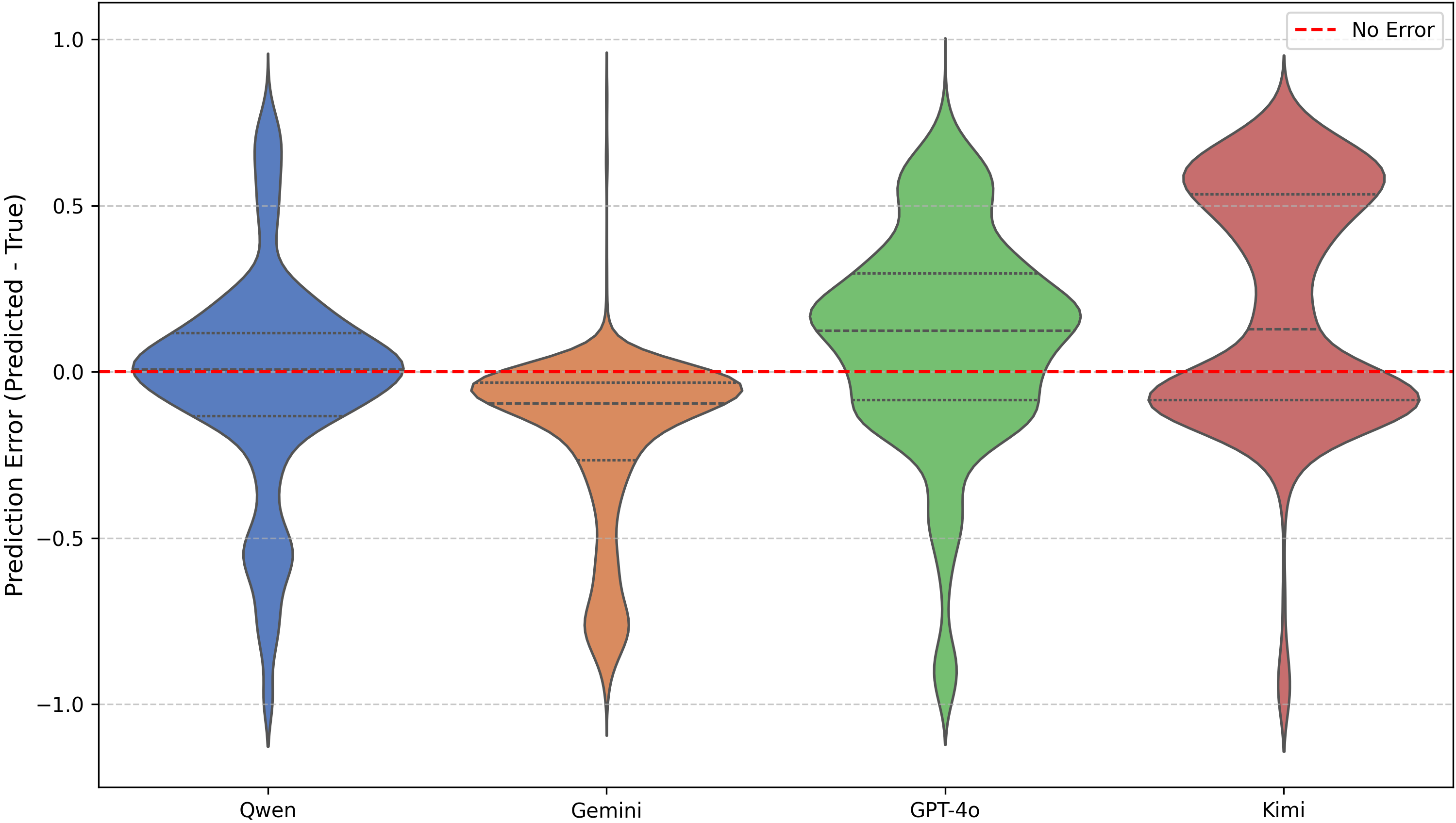 图5:多模态大模型零样本预测的散点图。横轴为真实值,纵轴为预测值。所有模型的预测点都呈现出明显的水平带状分布(量化效应),表明模型倾向于将连续的回归任务粗粒度化为有限的几个离散得分。
图5:多模态大模型零样本预测的散点图。横轴为真实值,纵轴为预测值。所有模型的预测点都呈现出明显的水平带状分布(量化效应),表明模型倾向于将连续的回归任务粗粒度化为有限的几个离散得分。
- 与最强基线的差距:零样本最佳模型Gemini-2.5-Pro(MAE=0.2154)与监督学习最佳Spectrogram+ResNet(MAE=0.1040)相比,MAE高出约107%,Pearson低约25%,差距非常显著,凸显了领域特定监督数据的必要性。
- 消融实验:论文未进行传统意义上的消融实验(如去除某个数据维度或模型组件),但其对比实验本身(不同特征表示、不同预训练模型)起到了类似作用。
⚖️ 评分理由
- 学术质量:5.0/7:论文提出了一个有价值的新任务并构建了质量可靠的数据集,实验设计全面,分析深入。主要不足在于模型创新性不足,本质上是对现有成熟技术(ResNet, Whisper)在新任务上的应用和评估,而非提出为VSSA问题量身定制的新算法或架构。技术实现正确,实验数据清晰,证据链完整。
- 选题价值:1.5/2:选题切中音乐推荐系统从“内容消费”向“内容创作”扩展的实际需求,具有明确的应用场景和潜在商业价值(如K歌应用)。虽然任务相对垂直,但对音频/音乐领域的研究者具有启发意义。
- 开源与复现加成:0.5/1:开源了数据集及其详细的构建方法,为该领域的研究奠定了坚实基础。但未公开基线模型的代码、训练脚本或完整超参数配置,降低了他人直接复现和比较的便利性。