📄 SightSound-R1: Cross-Modal Reasoning Distillation from Vision to Audio Language Models
#音频问答 #知识蒸馏 #多模态模型 #迁移学习 #音视频
✅ 7.5/10 | 前25% | #音频问答 | #知识蒸馏 | #多模态模型 #迁移学习
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:未说明(论文中作者列表排序未明确指定第一作者)
- 通讯作者:未说明
- 作者列表:Qiaolin Wang(Columbia University, New York, NY, USA)、Xilin Jiang(Columbia University, New York, NY, USA)、Linyang He(Columbia University, New York, NY, USA)、Junkai Wu(University of Washington, Seattle, WA, USA)、Nima Mesgarani(Columbia University, New York, NY, USA)
💡 毒舌点评
亮点在于巧妙地利用“视觉可听”的假设,将强大的视觉语言模型(LVLM)作为“免费的”教师来生成音频推理数据,从而绕过了音频链式思考(CoT)数据稀缺的瓶颈,思路清晰且实用。短板则是这一核心假设存在天然局限,导致生成的推理链可能基于视觉臆测而非真实音频内容(论文中也承认了语音、音乐任务性能下降),且方法的最终效果高度依赖外部强大LVLM和验证模型的能力,并非完全独立。
🔗 开源详情
- 代码:论文中未提及代码链接或开源计划。
- 模型权重:未提及。
- 数据集:使用了公开的AVQA, MMAU, MUSIC-AVQA数据集,并描述了其转换方法(AVQA转音频变体),但未提及是否开源经过其流程生成的CoT数据集DFC。
- Demo:未提及。
- 复现材料:论文详细说明了训练细节、配置(如SFT和GRPO的具体超参数、硬件、批次大小、学习率等)、验证集选择策略。未提供检查点或附录。
- 论文中引用的开源项目:SWIFT框架、LoRA、vLLM。
📌 核心摘要
- 要解决什么问题:大型音频语言模型(LALMs)在复杂音频场景下的推理能力落后于视觉语言模型(LVLMs),主要瓶颈是缺乏大规模、高质量的音频链式思考(CoT)数据来训练逐步推理能力。
- 方法核心是什么:提出SightSound-R1,一个跨模态推理蒸馏框架。核心步骤包括:(i) 利用强大的LVLM(如Qwen2.5-VL-32B)仅从静音视频生成针对音频问题的CoT推理链;(ii) 使用音频验证器(如GPT-4o-audio)过滤掉包含声音幻觉的推理链;(iii) 将验证后的CoT数据用于监督微调(SFT)和基于群体相对策略优化(GRPO)的强化学习,训练LALM学生(如Qwen2-Audio-7B)。
- 与已有方法相比新在哪里:不同于从同模态强模型蒸馏,本文首次系统性地探索从跨模态的视觉教师向音频学生进行推理能力迁移。其创新在于设计了一个自动化的“生成-验证-蒸馏”流水线,无需人工标注CoT数据,即可利用丰富的音视频数据提升LALM的推理能力。
- 主要实验结果如何:在AVQA验证集上,该方法将Qwen2-Audio-7B的准确率从直接推理的67.1%提升至82.7%(测试时蒸馏)和86.5%(SFT)。在未见过的MMAU测试集上,声音子任务达到66.1%,在MUSIC-AVQA测试集上达到59.5%总体准确率,优于多个基线,尤其在时间、比较类推理上表现突出。消融实验证明,音频验证(AGFV)和GRPO优化是性能提升的关键。
- 实际意义是什么:该方法为解决音频领域CoT数据匮乏问题提供了一种可扩展的自动化方案,开辟了利用视觉数据提升音频模型推理能力的新路径,对音视频理解、多模态AI的发展有启发意义。
- 主要局限性是什么:核心假设(视觉能看到所有声音来源)在现实中有缺陷,导致对语音、音乐等缺乏清晰视觉对应物的任务效果不佳(甚至低于基线)。生成的推理链可能存在与音频事实不符的幻觉,尽管有验证,但仍可能误导学生模型。最终性能受限于教师和验证模型本身的能力。
🏗️ 模型架构
SightSound-R1本身是一个框架,而非一个单一模型。其整体架构(流程)如图2所示,包含三个核心组件,组件之间是顺序与交互的数据流关系。
- 教师推理生成器:核心是强大的LVLM教师模型(如Qwen2.5-VL-32B-Instruct)。输入是(静音视频v, 问题q)和音频焦点提示(Paudio)。输出是多个(n个)独立的CoT推理链(R)。通过测试时缩放(TTS)与自一致性筛选:仅保留所有推理链得出唯一一致答案的样本,确保高置信度。这些样本构成初始推理数据集Dreason。
- 音频验证事实检查器:是一个独立的音频检查器C(如GPT-4o-audio)。输入是教师生成的一条推理链r和真实的音频a。它进行二元判断(是/否),验证推理链中关于声音的陈述是否与真实音频相符。通过验证的样本构成事实核查数据集DFC。这一步旨在过滤从静音视频生成的推理链中可能出现的声音幻觉。
- 学生训练模块:LALM学生模型(如Qwen2-Audio-7B-Instruct)在该模块中进行训练。
- 第一阶段(SFT):使用事实核查数据集DFC进行监督微调,学习老师的CoT格式和内容对齐。训练时冻结基础模型参数(θbase),仅微调LoRA参数(θLoRA)。目标函数(公式1)是标准的序列交叉熵损失。
- 第二阶段(GRPO):基于强化学习优化。从当前策略采样G个完整回答(包含CoT),由奖励函数打分。奖励包括准确性奖励(+1,答案与老师标签匹配)和格式奖励(+1,正确使用和
标签)。优化目标(公式2)采用带KL散度约束的裁剪策略目标,鼓励模型在锚定SFT模型的基础上,探索并优化更准确、格式更规范的推理与回答。
架构图:
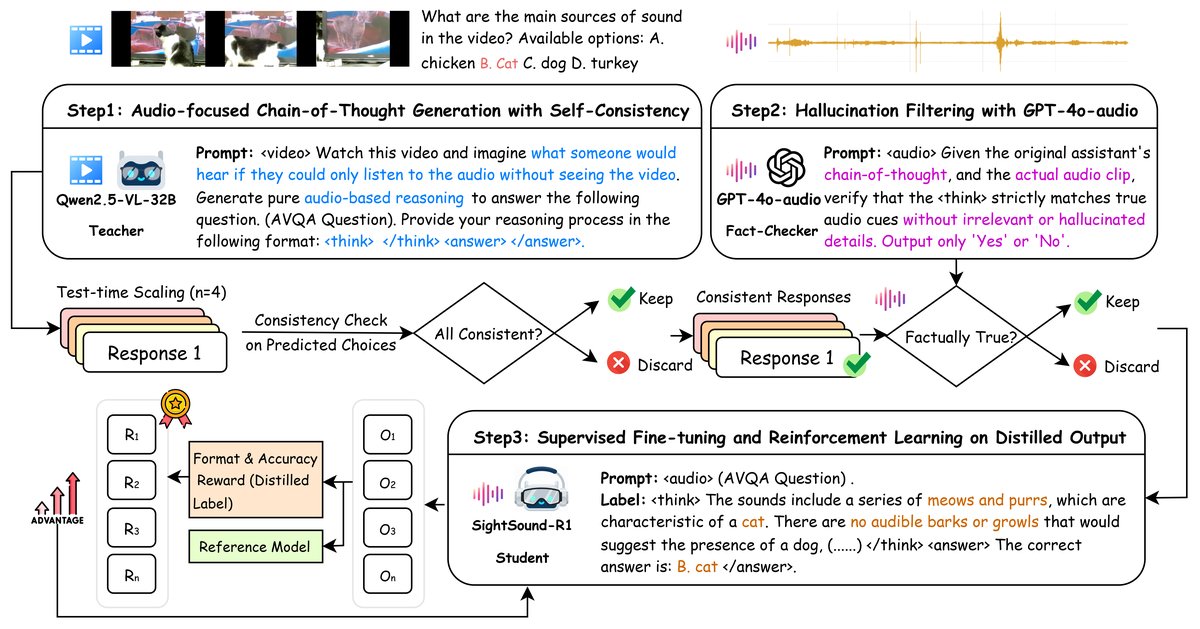 图2详细说明了整个流程:静音视频和问题被输入到“LVLM教师”(Qwen2.5-VL-32B)中,通过测试时采样生成多个“音频焦点CoT”;这些CoT与真实音频一起被送入“GPT-4o-audio事实检查器”进行验证;通过验证的CoT和标签用于两个阶段训练“LALM学生”(Qwen2-Audio-7B):先进行监督微调(SFT),再进行带奖励的强化学习(GRPO)。
图2详细说明了整个流程:静音视频和问题被输入到“LVLM教师”(Qwen2.5-VL-32B)中,通过测试时采样生成多个“音频焦点CoT”;这些CoT与真实音频一起被送入“GPT-4o-audio事实检查器”进行验证;通过验证的CoT和标签用于两个阶段训练“LALM学生”(Qwen2-Audio-7B):先进行监督微调(SFT),再进行带奖励的强化学习(GRPO)。
💡 核心创新点
- 跨模态推理蒸馏范式:提出并验证了从视觉语言模型(LVLM)向音频语言模型(LALM)蒸馏链式思考推理能力的可行性。这突破了传统蒸馏局限于同模态内(强音频模型到弱音频模型)的限制,利用了视觉数据丰富且LVLM推理能力强的优势,为解决音频领域CoT数据稀缺问题提供了全新思路。
- 基于静音视频与自一致性的CoT生成与筛选:创新地利用LVLM处理静音视频来生成音频CoT,有效隔离了视觉信息作为推理线索的纯粹性。结合测试时缩放(TTS) 和自一致性检查,在生成阶段就提升了CoT数据的初始质量和置信度,减少了需要依赖外部验证器的压力。
- 音频验证事实检查(AGFV)流水线:设计了一个模型无关的音频事实验证步骤,用以解决“盲”教师(LVLM)生成推理链可能产生的声音幻觉问题。这保证了蒸馏给学生模型的数据在音频事实上更加可靠,是连接跨模态假设与真实音频世界的桥梁。
🔬 细节详述
- 训练数据:
- 核心训练数据集:AVQA(音视频问答数据集)。论文遵循R1-AQA的方法,将其转换为音频-文本变体:提取音频轨道,并将问题中的“video”替换为“audio”,保留配对的静音视频用于教师推理。
- 评估数据集:AVQA验证集(用于方法开发和初步分析)、MMAU Test-mini(1k个音频问答对,侧重音频理解)、MUSIC-AVQA Test(7k个问答对,来自音乐表演视频,涵盖22种乐器和9种问题类型)。
- 数据预处理/增强:未具体说明。生成CoT时,对同一输入采样n次(具体n值未说明)以实现自一致性检查。
- 损失函数:
- SFT阶段:标准的序列负对数似然损失(公式1),即最大化教师CoT数据的似然概率。
- GRPO阶段:带有KL散度约束的策略梯度目标(公式2)。奖励函数由准确性奖励(+1)和格式奖励(+1)组成,否则为0。奖励值在计算优势时被标准化。
- 训练策略:
- SFT阶段:使用LoRA(rank=8, α=16)微调Qwen2-Audio-7B-Instruct。每个GPU批次大小为8,学习率5e-5,训练2000步。
- GRPO阶段:切换为全参数微调。分配2个GPU用于rollout生成,6个GPU用于策略优化。每个输入提示采样8个补全(G=8),每步生成192个候选响应。每个设备批次大小为4,学习率1e-6,温度1.0,KL系数β=0.04,最多训练1000步。
- 优化器:未具体说明。
- 调度策略:未具体说明。
- 选择策略:在SFT和GRPO阶段,均根据验证集准确率选择最佳检查点。
- 关键超参数:教师模型为Qwen2.5-VL-32B-Instruct;学生模型为Qwen2-Audio-7B-Instruct;事实检查器为GPT-4o-audio。GRPO中的采样数量G=8,裁剪参数ε(epsilon)未给出具体值。
- 训练硬件:单节点8卡NVIDIA A40 GPU。SFT在所有8卡上进行;GRPO使用2卡生成,6卡优化。
- 推理细节:未详细说明最终模型的推理参数(如温度、beam size)。在生成教师CoT和学生探索时使用了采样。
- 正则化/稳定训练技巧:在GRPO中使用了KL散度惩罚(β=0.04)来约束当前策略不偏离参考策略(πref,推测为SFT后的模型)太远。
📊 实验结果
表1:AVQA验证集上的准确率(%)对比
| 模型类别 | 模型名称 | 方法 | 准确率 |
|---|---|---|---|
| 大型音频语言模型 | Qwen2.5-Omni-3B (audio) | 直接推理 | 73.6 |
| Qwen2.5-Omni-7B (audio) | 直接推理 | 74.7 | |
| Qwen2-Audio-7B-Instruct | 直接推理 | 67.1 | |
| Qwen2-Audio-7B-Instruct | Zero-Shot-CoT | 57.7 | |
| Qwen2-Audio-7B-Instruct | 测试时CoT蒸馏 | 82.7 | |
| Qwen2-Audio-7B-Instruct | SFT(使用地面真值标签) | 86.5 | |
| 大型视觉语言模型 | Qwen2.5-Omni-3B (video) | 直接推理 | 86.5 |
| Qwen2.5-Omni-7B (video) | 直接推理 | 87.4 | |
| Qwen2.5-VL-7B-Instruct | 直接推理 | 85.7 | |
| Qwen2.5-VL-32B-Instruct | 直接推理 | 85.8 | |
| Qwen2.5-VL-32B-Instruct | Zero-Shot-CoT | 84.6 | |
| Qwen2.5-VL-32B-Instruct | Zero-Shot-Audio-CoT | 85.5 | |
| 大型音视频语言模型 | Qwen2.5-Omni-3B | 直接推理 | 88.5 |
| Qwen2.5-Omni-7B | 直接推理 | 89.5 |
表1分析:证实了LVLM(尤其是多模态Qwen2.5-Omni)在AVQA任务上显著优于LALM。关键发现是,Qwen2.5-VL-32B生成的“Audio-CoT”用于测试时蒸馏,能将Qwen2-Audio-7B的性能从67.1%大幅提升至82.7%,接近甚至超过了使用地面真值标签的SFT性能(86.5%),证明了跨模态蒸馏的巨大潜力。
表2:MMAU Test-mini和MUSIC-AVQA测试集上的准确率(%)对比
| 模型 | 方法 | MMAU Test-mini | MUSIC-AVQA Test | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 声音 | 语音 | 音乐 | 平均 | 时间 | 比较 | 计数 | 存在 | 平均 | ||
| 基线 | ||||||||||
| Qwen2-Audio-7B-Instruct | 直接推理 | 64.3 | 52.6 | 61.7 | 59.5 | 57.2 | 57.8 | 55.7 | 55.1 | 55.6 |
| Qwen2-Audio-7B-Instruct | SFT(地面真值标签) | 66.7 | 50.8 | 61.1 | 59.5 | 60.4 | 62.7 | 61.1 | 60.7 | 61.1 |
| Qwen2-Audio-7B-Instruct | SFT(蒸馏标签) | 64.3 | 52.3 | 60.5 | 59.0 | 59.5 | 61.4 | 59.1 | 60.2 | 58.8 |
| Qwen2-Audio-7B-Instruct | GRPO(蒸馏标签) | 62.5 | 49.8 | 59.3 | 57.2 | 59.3 | 60.8 | 59.1 | 60.3 | 58.8 |
| Audio-Thinker [22] | SFT(地面真值CoT) | 63.4 | 56.3 | 54.4 | 57.8 | – | – | – | – | – |
| Audio-Thinker [22] | GRPO(地面真值CoT) | 70.3 | 61.6 | 63.2 | 65.0 | – | – | – | – | – |
| 本文方法(蒸馏CoT上SFT/GRPO) | ||||||||||
| Qwen2-Audio-7B-Instruct | SFT | 61.3 | 47.1 | 48.5 | 52.3 | 56.7 | 57.7 | 56.5 | 54.3 | 55.1 |
| Qwen2-Audio-7B-Instruct | AGFV + SFT | 63.1 | 47.7 | 51.5 | 54.1 | 58.2 | 59.4 | 56.9 | 56.5 | 56.5 |
| Qwen2-Audio-7B-Instruct | TTS + AGFV + SFT | 61.6 | 48.3 | 50.6 | 53.5 | 60.6 | 59.0 | 59.1 | 57.5 | 58.2 |
| SightSound-R1 | TTS + AGFV + SFT + GRPO | 66.1 | 49.8 | 52.7 | 56.2 | 62.7 | 63.3 | 60.1 | 59.7 | 59.5 |
表2分析:SightSound-R1在MMAU声音任务上达到66.1%,优于所有仅使用标签或未结合AGFV的CoT方法,但略低于使用地面真值CoT的Audio-Thinker GRPO(70.3%)。在MUSIC-AVQA上,其总体准确率59.5%和多数子类别上表现优异。消融实验显示:单独SFT蒸馏CoT效果不佳(52.3%),加入AGFV后提升(54.1%),再加入TTS和GRPO后性能显著提升(56.2% -> 59.5%)。值得注意的是,本文方法在语音和音乐任务上的表现普遍低于直接推理或SFT基线,验证了跨模态蒸馏的局限性。
图1: pdf-image-page1-idx0 图1直观对比了LALM(Qwen2-Audio-7B)和LVLM(Qwen2.5-VL-32B)在处理同一AVQA问题时的输出。LALM的回答简短、推理不充分;而LVLM生成了详细的、分步骤的音频焦点推理链(即使它无法听到音频),这为蒸馏提供了丰富的监督信号。
⚖️ 评分理由
- 学术质量:6.5/7:论文提出了一种新颖且系统的跨模态推理蒸馏框架(SightSound-R1),解决了音频领域一个真实存在的关键瓶颈(CoT数据稀缺)。技术路线清晰,三步流水线设计合理,实验在多个数据集和基线上进行了充分验证,包括详细的消融研究。主要创新点(跨模态迁移、基于静音视频的生成、AGFV验证)都有效且结果支持论点。扣分点在于:核心假设存在已知局限,且与使用同模态强监督(地面真值CoT)的最强基线(Audio-Thinker GRPO)相比,在部分任务上仍有差距。
- 选题价值:1.5/2:选题非常前沿,直击多模态大模型时代音频推理能力落后的痛点。提出利用视觉数据“免费”提升音频模型能力,思路巧妙且具有启发性。对音频/多模态领域的研究者有较高的参考价值。应用空间集中在提升音频理解模型的复杂推理能力。扣分点是因为该方法的有效性高度依赖特定的音视频配对场景和强大的外部模型,通用性受到一定限制。
- 开源与复现加成:0.5/1:论文详细报告了训练超参数、硬件配置、数据集处理方法(AVQA转音频变体),并在附录中(文中提及但未展示)可能提供更多细节,具有一定的可复现性。使用了开源的SWIFT框架、LoRA、vLLM等工具。然而,未提及是否开源代码、模型权重或经过验证的推理链数据集,这大大增加了完全复现的难度。因此给予部分加分。