📄 Session-Level Spoken Language Assessment with A Multimodal Foundation Model Via Multi-Target Learning
#语音评估 #语音大模型 #多任务学习 #多模态模型 #端到端
✅ 7.5/10 | 前25% | #语音评估 | #多任务学习 | #语音大模型 #多模态模型
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Hong-Yun Lin
- 通讯作者:未说明
- 作者列表:Hong-Yun Lin, Jhen-Ke Lin, Chung-Chun Wang, Hao-Chien Lu, Berlin Chen(均来自Department of Computer Science and Information Engineering, National Taiwan Normal University)
💡 毒舌点评
亮点:该论文最漂亮的一手是将“评估人类评估过程”这个理念贯彻到底——不是去分数个片段再拼接,而是设计一个能“一口气”看完考生整个作答会话的模型,这从架构层面就对齐了人类考官的认知习惯。短板:虽然方法在特定基准上效果拔群,但这种高度定制化的会话级评估模型,在面对更开放、更多样化的口语任务或语言时,其泛化能力和实际部署的灵活性尚未得到证明,更像一个“专用冠军”而非“通用强者”。
🔗 开源详情
- 代码:论文中未提及代码链接,但声明“实验设置和源代码将在相机版本中公开”。
- 模型权重:论文中提到将基于Phi-4-Multimodal和Whisper-large-v3进行适配,但未提及是否公开自己微调后的权重。承诺公开代码可能包含训练脚本。
- 数据集:使用了公开的Speak & Improve 2025基准数据集,但论文本身未提供数据集下载链接或额外处理说明。
- Demo:论文中未提及在线演示。
- 复现材料:论文详细描述了模型架构、训练策略(优化器、学习率、批大小、轮次等)、关键超参数(模型维度、MLP结构)以及评估指标,为复现提供了充分的信息框架。
- 论文中引用的开源项目:主要依赖Phi-4-Multimodal [14]和Whisper [17]作为基础模型,并使用了LoRA [16]进行高效微调。
📌 核心摘要
- 问题:现有的自动口语语言评估(SLA)系统要么采用易产生误差传播的级联管道,要么使用只能处理短时音频的端到端模型,无法像人类考官那样整合整个测试会话的语篇级证据进行综合评分。
- 方法核心:提出一种基于多模态基础模型(Phi-4-Multimodal)的会话级评估框架。该模型将整个测试会话(包含多个音频响应)格式化为对话序列一次性输入,通过多任务学习(MTL)直接联合预测四个部分的分数和一个总体分数。同时,引入了一个并行的、基于冻结Whisper模型的“声学能力先验”(APP),将其作为前缀令牌注入模型,以显式增强对流利度、停顿等副语言特征的感知。
- 与已有方法相比新在哪里:新在建模范式上:1)实现了真正的会话级、端到端、单次前向传播的评估,避免了分段评估和后期融合带来的误差。2)提出了声学先验注入机制,将外部声学模型的知识作为可学习的先验融入多模态大模型,无需手工特征工程。
- 主要实验结果:在Speak & Improve 2025基准测试中,所提出的Phi-4-MTL-APP模型取得了最优性能,总体RMSE为0.360,皮尔逊相关系数(PCC)为0.827。它超越了当时最强的集成系统(Perezoso, RMSE 0.364)和自己的基线系统(Phi-4-CTG, RMSE 0.412)。消融实验表明,MTL比CTG(RMSE 0.412)误差降低超过12%,而添加APP模块在长语音部分(P3/P4)带来了进一步的稳定提升。
- 实际意义:该研究为计算机辅助语言学习(CALL)提供了一个更准确、更接近人类评估过程、且模型更紧凑(单模型)的自动口语评分方案,有助于降低对人工评分的依赖。
- 主要局限性:1)模型的性能验证局限于特定的Speak & Improve基准测试,其跨任务、跨语言的泛化能力有待进一步研究。2)虽然承诺开源,但论文发表时未提供代码,依赖于特定的商业基础模型(Phi-4)和数据集。
🏗️ 模型架构
该模型采用“单会话输入,多分数输出”的统一架构(如图1b “Unified” 所示),主要由三个组件构成:
- 多模态基础模型骨干(Phi-4-Multimodal):这是核心聚合与推理引擎。它接收一个精心构造的对话序列作为输入。该序列交替包含文本指令(如“Part 1: Interview”)和音频占位符
<|audio_i|>。每个音频占位符对应一段16kHz的原始波形,通过Phi-4内置的语音适配器进行处理。这种设计将语义信息和声学信息置于同一个注意力空间,使模型能够学习跨话语、跨部分的依赖关系。 - 声学能力先验分支(Whisper-based APP):这是一个并行的、用于生成“声学能力先验”的模块。它使用一个冻结的Whisper-large-v3编码器提取最后一个隐藏层状态
H_enc,经过时间维度的平均池化得到向量,然后通过一个两层MLP(Linear → GELU → Dropout → Linear)映射到一个概率向量。最后,通过一个投影层将其转换为一个令牌嵌入e_prior,并前置到多模态主序列的开头。这个APP令牌作为一个可学习的声学特征提示,引导主模型关注副语言特征。 - 预测头:一个简单的多输出线性回归层,连接到主模型最后一个时间步的隐藏状态
h_T上,直接输出五维分数向量(ˆy_P1, ˆy_P3, ˆy_P4, ˆy_P5, ˆy_overall)。
数据流与交互:输入序列(APP令牌 + 对话式音频-文本序列)一次性送入Phi-4骨干。骨干内部的自注意力机制在处理序列时,会同时看到代表整体声学能力的APP令牌、各个部分的文本提示和对应的音频嵌入。这样,模型在生成最终隐藏状态 h_T 时,已经融合了语篇上下文、声学线索和任务指令的所有信息。最后,h_T 通过线性头被解码为所有目标分数。
 图2:会话级多模态评估器的整体架构。清晰展示了左侧的Phi-4多模态骨干处理对话序列,以及右侧并行的Whisper分支生成APP前缀令牌并注入主序列的过程。
图2:会话级多模态评估器的整体架构。清晰展示了左侧的Phi-4多模态骨干处理对话序列,以及右侧并行的Whisper分支生成APP前缀令牌并注入主序列的过程。
💡 核心创新点
- 会话级统一建模与多目标学习:是什么:将整个口语测试会话作为一个完整输入,并使用单一模型同时预测所有部分分数和总体分数。之前局限:先前系统要么对每个音频片段单独评分再融合(如Phi-4-CTG),要么训练多个独立的部分评分器再集成(如Phi-4-STG),这两种方式都割裂了会话内部的语篇联系,且后者需要复杂的多模型管理。如何起作用:通过将多段音频组织成对话序列输入大模型,利用其长上下文和注意力机制直接建模跨话语关系。多任务学习目标迫使模型学习对所有部分都有用的共享表示。收益:实验表明,这种统一建模方式(Phi-4-MTL)比单模型但分段处理的基线(Phi-4-CTG)在总体RMSE上降低了12%以上,尤其在多回答部分(P1, P5)提升显著,更贴合人类评分逻辑。
- 声学能力先验(APP)注入:是什么:从冻结的预训练语音模型(Whisper)中提取声学特征,生成一个“先验”令牌,作为额外提示注入多模态模型。之前局限:直接端到端训练的大模型可能过度关注文本语义,而忽视了对口语评估至关重要的副语言特征(如流利度、犹豫、停顿)。如何起作用:APP模块专门从声学角度对说话能力进行“预评估”,其输出作为一个可学习的向量,为后续的主模型提供了明确的声学质量线索。这相当于为多模态模型配备了一个“声学参考答案”。收益:加入APP后(Phi-4-MTL-APP),模型在长语音部分(P3/P4)的RMSE得到进一步降低,整体性能小幅提升。图3的散点图显示APP预测与最终Phi-4预测高度相关,证明APP起到了有效的校准作用而非引入噪声。
- 参数高效适配(PEFT):是什么:使用LoRA技术对大规模多模态基础模型进行微调。之前局限:全参数微调一个多模态基础模型计算成本高,且可能破坏其预训练知识。如何起作用:冻结原始模型参数,仅在注意力层和MLP层中插入低秩适配器进行训练。收益:使得在长序列、多模态输入上进行高效、可控的微调成为可能,降低了训练门槛。
🔬 细节详述
- 训练数据:使用Speak & Improve 2025语料库,约315小时的L2英语学习者语音。每个测试会话包含四个开放说话部分(P1, P3, P4, P5),每个部分由人类评分员给出一个等级分数(基于CEFR对齐的2.0-5.5分制)。总体标签是这四个部分分数的算术平均。
- 损失函数:采用加权均方误差(Weighted MSE)。公式为:
L = (1 / Σn,k mn,k) * Σn,k mn,k (ˆyn,k - yn,k)²。其中mn,k是掩码(可能用于处理部分缺失的标注),确保所有样本的所有目标在训练中都被平等考虑。 - 训练策略:
- 优化器:AdamW
- 学习率:1e-4,带余弦衰减和100步的warmup。
- 权重衰减:0.01
- 批量大小:1(梯度累积步数为8)
- 训练轮数:3个epoch
- 梯度裁剪:1.0
- 启用FlashAttention以加速长序列处理。
- 关键超参数:
- 主干模型:Phi-4-Multimodal-instruct,支持128k token上下文。
- Whisper编码器:Whisper-large-v3,其最后一层隐藏状态维度
dw为1280。 - APP模块MLP:第一层将维度映射到512,第二层映射到8(输出概率向量维度)。
- 预测头:线性层,输出维度为5。
- 训练硬件:论文中未明确说明GPU/TPU型号、数量及训练时长。
- 推理细节:论文中未详细说明解码策略(如是否为自回归生成),但从预测头设计看,更可能是直接前向传播得到分数向量,因此延迟较低。
- 正则化/稳定训练技巧:使用了LoRA进行参数高效微调,APP模块中使用了Dropout(比率0.1),训练中使用了梯度裁剪。
📊 实验结果
实验在Speak & Improve 2025评估集上进行,主要对比模型在总体和各部分的性能。
表1:S&I评估集上的总体指标
| Arch | Model | RMSE ↓ | PCC | %≤0.5 | %≤1.0 |
|---|---|---|---|---|---|
| Ens | Perezoso | 0.364 | 0.826 | 83.0 | 99.7 |
| Ens | APP (Whisper) | 0.383 | 0.805 | 81.7 | 99.0 |
| Ens | Phi-4-STG | 0.375 | 0.820 | 81.7 | 99.3 |
| Uni | Phi-4-CTG (zero-shot) | 0.783 | 0.516 | 43.2 | 78.1 |
| Uni | Phi-4-CTG | 0.412 | 0.796 | 74.7 | 98.0 |
| Uni | Phi-4-MTL | 0.362 | 0.825 | 85.7 | 99.0 |
| Uni | Phi-4-MTL-APP | 0.360 | 0.827 | 85.7 | 99.0 |
结论:统一模型Phi-4-MTL(RMSE 0.362)在总体RMSE上已超越最强的集成基线Perezoso(0.364)和自身的集成基线Phi-4-STG(0.375)。加入声学先验后,Phi-4-MTL-APP进一步小幅提升至0.360,达到最佳性能。与单模型但非多任务学习的Phi-4-CTG(0.412)相比,相对误差降低超过12%。
表2:S&I评估集上的各部分RMSE
| Model | P1 | P3 | P4 | P5 | Overall |
|---|---|---|---|---|---|
| APP (Whisper) | 0.581 | 0.461 | 0.497 | 0.528 | 0.383 |
| Phi-4-CTG | 0.556 | 0.533 | 0.604 | 0.543 | 0.412 |
| Phi-4-MTL | 0.494 | 0.471 | 0.491 | 0.455 | 0.362 |
| Phi-4-MTL-APP | 0.494 | 0.459 | 0.485 | 0.447 | 0.360 |
结论:Phi-4-MTL在所有部分上都显著优于Phi-4-CTG,尤其是在需要整合多个短回答的P1和P5部分。APP模块在长语音部分(P3, P4)带来了可见的增益(如P4从0.491降至0.485)。
消融与分析:
- MTL vs. CTG:表1和表2证明了会话级多目标学习框架的有效性,它通过跨话语推理显著提升了性能。
- APP的作用:对比Phi-4-MTL和Phi-4-MTL-APP,APP提供了稳定、微小的提升。图3的散点图显示,单独由Whisper预测的总体分数与Phi-4-MTL-APP预测的总体分数有很高的相关性,证明APP作为声学先验与主模型协同工作良好。
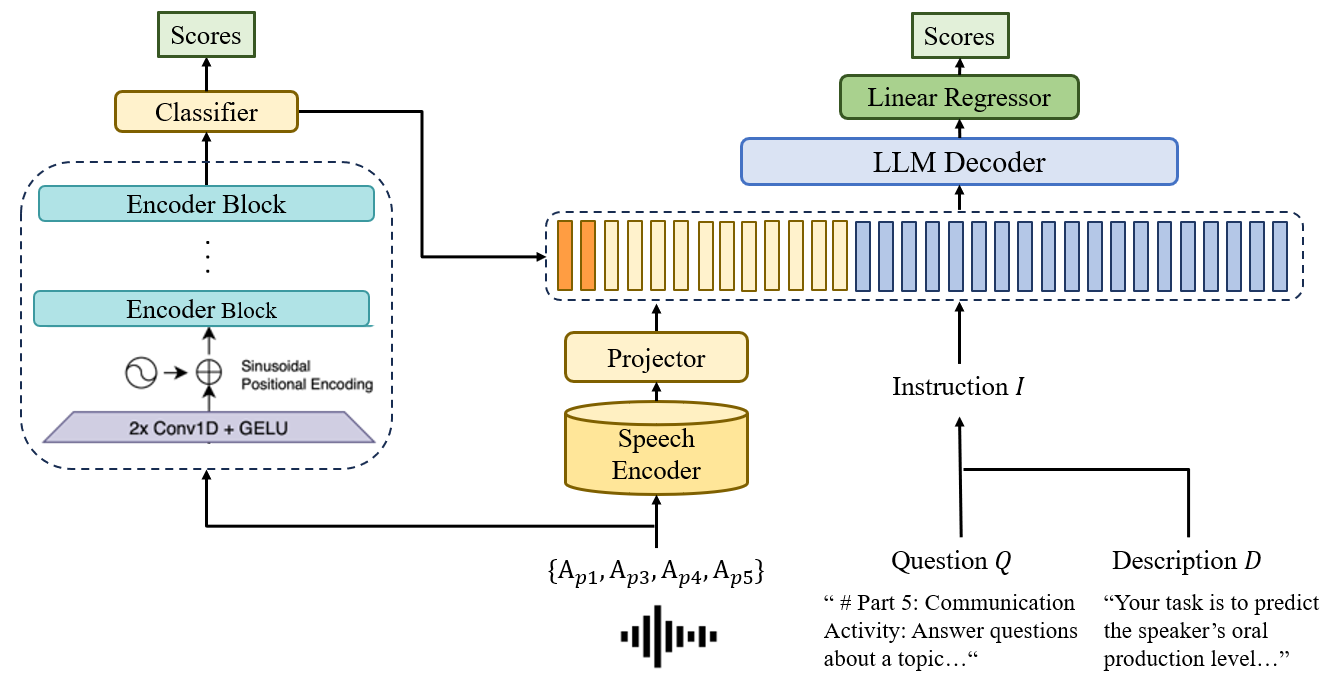 图3:APP (Whisper) 预测值与Phi-4预测值在总体分数上的回归散点图。图中点紧密分布在对角线附近,表明两者预测高度一致,APP有效地提供了声学校准信号。
图3:APP (Whisper) 预测值与Phi-4预测值在总体分数上的回归散点图。图中点紧密分布在对角线附近,表明两者预测高度一致,APP有效地提供了声学校准信号。
⚖️ 评分理由
- 学术质量:6.0/7。创新性体现在提出了一个符合人类评估直觉的、端到端的会话级多模态评估框架,其声学先验注入机制设计巧妙。技术路线正确,实验设计全面,与多个强基线(包括S&I 2025挑战赛顶尖系统)进行了公平对比,并通过详细的消融实验和可视化支持了其主张,证据可信度高。主要扣分点在于:1)模型的核心组件(如Phi-4的语音适配器)细节未深入披露;2)实验局限于单一基准,缺乏跨语言或跨任务的泛化验证。
- 选题价值:1.5/2。选题针对计算机辅助语言学习(CALL)这一明确的应用场景,解决了自动口语评估中的关键痛点(语篇级整合),具有较强的实用价值和产业潜力。该工作处于语��技术与教育科技交叉的前沿,但其受众和应用场景相对垂直,对更广泛的音频/语音社区的影响力可能有限。
- 开源与复现加成:0.5/1。论文明确承诺在相机版本中公开源代码和实验设置,并在文中提供了足够的复现细节(如模型名称、关键超参数、损失函数)。然而,在当前版本中并未提供实际的代码链接或模型权重,因此不能给予满分。如果最终开源完善,此项分数可提升。