📄 Sequence-Level Unsupervised Training in Speech Recognition: A Theoretical Study
#语音识别 #无监督学习 #低资源
✅ 6.5/10 | 前50% | #语音识别 | #无监督学习 | #低资源
学术质量 4.0/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 中
👥 作者与机构
- 第一作者:Zijian Yang(RWTH Aachen University, Human Language Technology and Pattern Recognition组)
- 通讯作者:未说明
- 作者列表:Zijian Yang(RWTH Aachen University), Jörg Barkoczi(RWTH Aachen University), Ralf Schlüter(RWTH Aachen University, AppTek GmbH), Hermann Ney(RWTH Aachen University, AppTek GmbH)
💡 毒舌点评
论文构建了一个从分类误差界到训练损失的严谨理论链条,逻辑自洽且推导细致。但讽刺的是,作为一篇标题和摘要都直指“语音识别”的论文,它竟然没有展示任何真实语音识别任务(如音素、单词或句子识别)的实验结果,让漂亮的理论悬在空中,无法证明其对实际性能的提升作用。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:未提及公开新数据集。论文中使用了LibriSpeech的转录文本进行理论条件验证,但未提供具体使用方式。
- Demo:未提及。
- 复现材料:论文中未提供任何训练细节、配置、检查点或附录说明,无法复现其理论工作或应用实验。
- 论文中引用的开源项目:论文引用了多个工作(如CTC[8], LF-MMI[13]),但未明确说明其理论框架的实现依赖于哪些具体的开源工具或模型。
- 总体:论文中未提及任何开源计划。
📌 核心摘要
本文针对无监督语音识别中训练目标与分类错误率关系不清的问题,从分类误差界出发,建立了一个理论框架。论文提出了结构约束和语言模型矩阵全列秩两个充分必要条件,证明了在这两个条件下,无监督训练是可行的。基于此,推导了一个将不可直接计算的分类误差失配(Δq)与可通过无配对数据估计的边缘分布KL散度联系起来的理论界。受该界启发,论文提出了一个单阶段的序列级交叉熵损失函数,使得统计模型(如HMM或端到端模型)可以直接在无配对数据上进行训练。主要实验结果仅为针对理论界的仿真验证(图1),展示了在合成数据上界的有效性,但未提供任何真实语音识别数据集上的性能数值。该工作的实际意义在于为无监督语音识别的损失函数设计提供了坚实的理论依据。主要局限性是缺少在任何真实语音识别任务上的实验评估,无法验证其理论损失在实际中的效果。
🏗️ 模型架构
论文中未提供具体的模型架构。本文是一篇理论研究,其核心贡献是推导了一个通用的训练准则(损失函数),而非提出一个特定的神经网络模型。该损失函数可以应用于多种统计模型,如HMM-GMM、端到端CTC模型等。论文中描述的数据流如下:
- 输入:无标签语音序列 x₁ᴺ。
- 模型:学习一个条件分布 q(x|c),并结合一个预训练或可估计的语言模型 p_LM(c₁ᴺ)(对应 pr(c₁ᴺ))。
- 输出/损失:通过动态规划或搜索近似计算边缘似然 log q(x₁ᴺ) = log ∑_{c₁ᴺ} p_LM(c₁ᴺ) q(x₁ᴺ|c₁ᴺ),并最大化其对训练数据的期望,即最小化序列级交叉熵损失 L(θ)。
- 组件交互:该框架不规定具体架构,但要求模型能参数化 q(x|c)。对于判别式模型 q(c|x),可通过贝叶斯公式转换。
💡 核心创新点
- 提出无监督语音识别的两个充分必要条件:
- 是什么:“结构约束”(真分布与模型分布具有相同的逐位置因式分解形式)和“全列秩条件”(语言模型矩阵 P_C 列满秩,确保标签可区分)。
- 局限:之前工作(如基于GAN的)的理论分析集中在全局收敛性,未明确建立训练损失与分类误差的直接关系,也未明确这些可解性条件。
- 如何起作用:这两个条件共同保证了从边缘分布 pr(x₁ᴺ) 和 q(x₁ᴺ) 的差异可以反推出条件分布 q(x|c) 的误差是有界的,从而使无监督学习成为可能。
- 收益:为无监督语音识别划定了理论可行的边界,解释了为何某些方法(如使用特定映射)能成功。
- 推导序列级分类误差界(定理1):
- 是什么:建立了 D_q(联合分布ℓ1距离的上界)与 Σ|pr(x₁ᴺ)-q(x₁ᴺ)|(边缘分布ℓ1距离)之间的定量关系。
- 局限:之前理论框架未建立训练目标(如GAN的minimax loss)与最终序列分类错误率的明确数学联系。
- 如何起作用:通过两个引理,将条件分布的误差与边缘分布误差通过矩阵 P⁺_C 联系起来。
- 收益:将难以直接优化的分类误差失配 Δq,转化为可以通过无配对数据估算的边缘分布差异,为设计损失函数提供了直接依据。
- 推导并提出单阶段序列级交叉熵损失:
- 是什么:基于上述理论界和 Pinsker 不等式,推导出最小化边缘分布KL散度 D_KL(pr(x₁ᴺ) || q(x₁ᴺ)) 等价于最小化分类误差失配 Δq,并据此提出训练准则。
- 局限:现有两阶段方法(先无监督映射,再半监督微调)流程复杂,且映射步骤与统计模型训练目标割裂。
- 如何起作用:该损失允许直接在无配对语音数据上,通过最大化边缘似然来端到端优化统计模型,无需中间映射步骤。
- 收益:提供了首个理论上可证明与分类错误率挂钩的、适用于统计模型的单阶段无监督训练准则,简化了流程。
🔬 细节详述
- 训练数据:
- 数据集名称与规模:论文未提供用于训练或评估的具体无监督语音数据集信息。
- 预处理与数据增强:未说明。
- 注:在验证全列秩条件时,使用了 LibriSpeech 的转录文本计算 P_C 的最小奇异值。
- 损失函数:
- 名称:序列级交叉熵损失 L(θ) = - (1/S) ∑{s=1}^S log q_θ(x{s,1}^N)。
- 作用:最小化模型预测的边缘分布 q(x₁ᴺ) 与真实边缘分布 pr(x₁ᴺ) 之间的KL散度,从而间接最小化分类误差。
- 公式解释:q_θ(x_{s,1}^N) = ∑{c₁ᴺ} p_LM(c₁ᴺ) q_θ(x{s,1}^N | c₁ᴺ)。它衡量了模型对观测到的语音序列的生成概率。
- 权重:未说明(理论公式中无额外权重)。
- 训练策略:
- 学习率、warmup、batch size、优化器、训练步数/轮数、调度策略:论文中未提及任何具体训练细节。
- 关键超参数:
- 模型大小、层数、隐藏维度、码本大小等:论文中未提及。理论分析中涉及的关键参数是语言模型矩阵 P_C 的维度(N×|C|)及其伪逆的ℓ1范数。
- 训练硬件:
- GPU/TPU型号、数量、训练时长:论文中未提及。
- 推理细节:
- 解码策略、温度、beam size、流式设置:论文中未提及。论文提到对于全上下文LM,可以通过搜索获得假设空间。
- 正则化或稳定训练技巧:论文中未提及。
📊 实验结果
论文没有进行任何真实语音识别任务的实验。其“实验”仅限于理论界的数值仿真。
主要Benchmark与结果:
- 论文未报告在任何标准语音识别数据集(如 LibriSpeech, TIMIT)上的音素错误率(PER)或词错误率(WER)。
与SOTA对比:论文未提供任何对比。
关键消融实验:无。
仿真结果(图1):
- 图表:提供了论文中的图片。
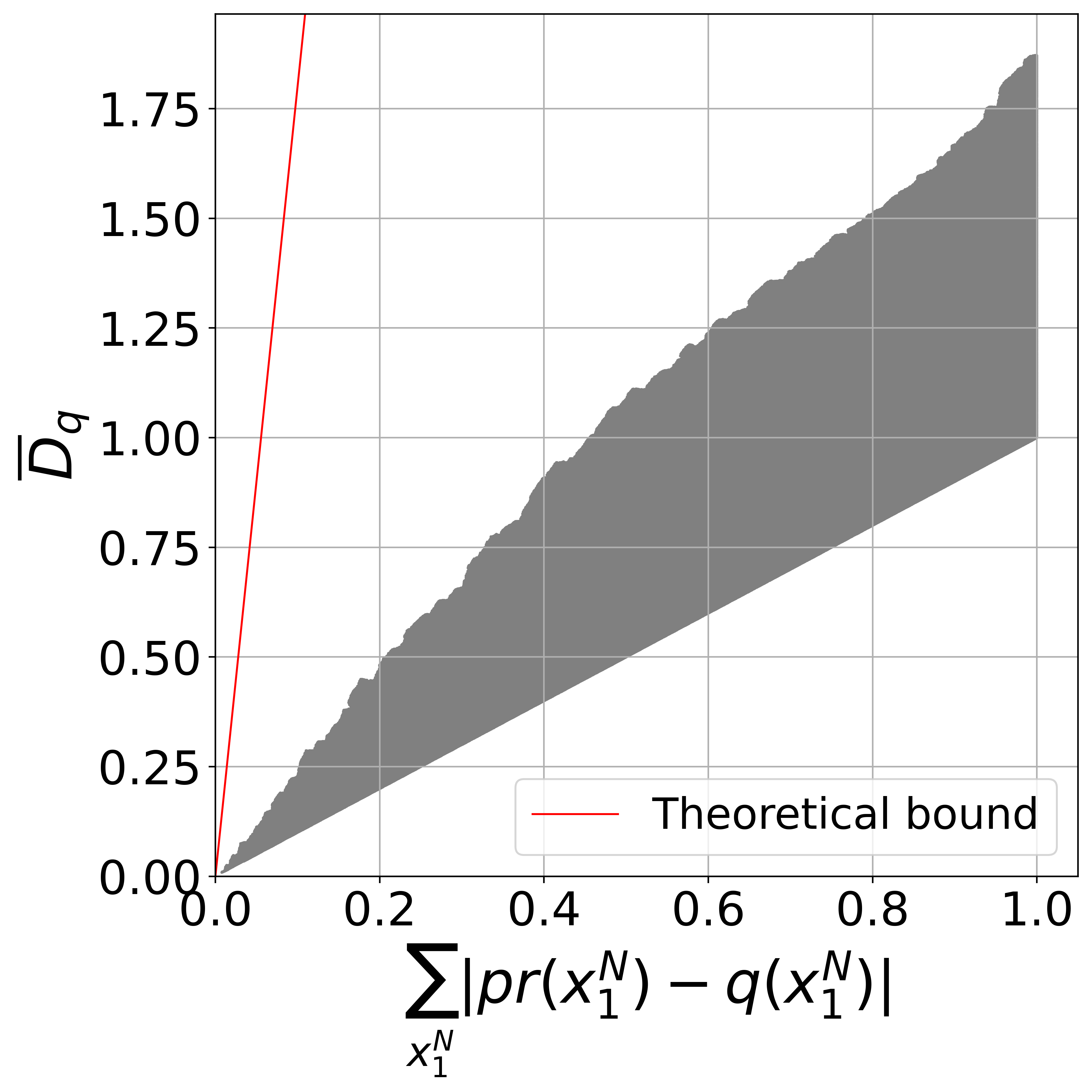
- 描述:该图验证了定理1中的不等式。横坐标是 Σ_{x₁ᴺ}|pr(x₁ᴺ)-q(x₁ᴺ)|(边缘分布差异),纵坐标是 D_q(联合分布差异的上界)。灰色点代表随机生成的分布对(pr, q)。图线表明 D_q 确实被横坐标的值所界定,从而验证了理论界的正确性。但这是在合成数据(|X|=4, |C|=3, N=3)上的验证,与真实语音识别任务无关。
⚖️ 评分理由
- 学术质量:4.0/7 - 创新性:提出了一个新颖且逻辑严谨的理论框架,为无监督语音识别损失函数的设计提供了理论依据,是重要的理论贡献。技术正确性:数学推导过程清晰、正确,仿真验证了理论界的有效性。实验充分性:严重不足。这是本文最大的缺陷。作为一篇关于“语音识别”的论文,没有在任何真实的语音识别数据集上评估其提出的损失函数是否能降低识别错误率,使得理论的价值无法得到实践检验。证据可信度:理论部分可信,但整体论文因缺乏应用层面证据而说服力打折。
- 选题价值:1.5/2 - 前沿性:无监督语音识别是活跃的研究领域,理论研究是其健康发展的基础。潜在影响:如果后续实验证实有效,该理论可指导设计更优的无监督训练方法。实际应用空间:理论本身不直接应用,但为实际应用提供指导。读者相关性:对关注语音识别基础理论、无监督学习机制的学者和研究人员具有高相关性。
- 开源与复现加成:-0.5/1 - 论文完全未提供代码、预训练模型、训练配置或任何复现所需的信息。读者无法根据本文重现其理论分析或(更重要的是)验证其损失函数在实际任务中的效果。