📄 SEP-ST: Incorporating Speech Entity Prompt Into Large Language Models for Speech Translation
#语音翻译 #大语言模型 #多任务学习 #命名实体识别 #多语言
✅ 7.5/10 | 前25% | #语音翻译 | #多任务学习 | #大语言模型 #命名实体识别
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 中
👥 作者与机构
- 第一作者:Fei OuYang (昆明理工大学, 云南人工智能重点实验室)
- 通讯作者:Zhengtao Yu (昆明理工大学, 云南人工智能重点实验室)
- 作者列表:Fei OuYang (昆明理工大学, 云南人工智能重点实验室)、Linqin Wang (昆明理工大学, 云南人工智能重点实验室)、Zhengtao Yu (昆明理工大学, 云南人工智能重点实验室)
💡 毒舌点评
亮点在于直击端到端语音翻译中“命名实体”这个老大难问题,提出了一种无需外部知识库、通过联合训练从语音中直接提取实体特征提示LLM的优雅方案,在CoVoST-2和MuST-C上的实体翻译准确率(TSR)提升非常亮眼。短板是方法高度依赖于预训练的NER模型生成训练标签,且消融实验显示一种核心变体(Transformer-based)效果不佳,这使得其“端到端”的纯粹性打了折扣,更像是一个“半端到端”的增强方案。
🔗 开源详情
- 代码:论文中提供代码仓库链接:https://github.com/Crabbit-F/SEP。
- 模型权重:未提及是否公开预训练或训练好的模型权重。
- 数据集:使用公开数据集CoVoST-2和MuST-C,但未提及是否提供自建的SEP提取数据集。
- Demo:未提及。
- 复现材料:提供了基本的训练细节(优化器、学习率、warmup步数、调度策略)和模型架构描述。关键超参数(λ值)、硬件信息、完整的训练配置文件未说明。
- 引用的开源项目:依赖预训练模型:Whisper-large-V3(语音编码器)、Qwen2.5(LLM)、Q-Former(适配器)、roberta-large-ner-english(NER工具)。
📌 核心摘要
- 问题:当前端到端语音翻译模型在翻译命名实体(如人名、地名、机构名)时准确率不足,而依赖级联或外部知识库的方法存在误差传播和泛化性差的问题。
- 方法核心:提出SEP-ST,一个端到端框架。其核心是新增一个“语音实体提示(SEP)提取模块”,直接从语音表征中学习并提取实体相关的嵌入特征。然后将该特征与原始语音特征和文本指令拼接,共同输入大语言模型(LLM)进行翻译,从而引导模型关注并准确翻译实体。
- 创新点:与已有方法相比,该工作是首个提出直接在语音表征层面进行端到端实体特征提取并作为提示整合进LLM的统一框架,摆脱了对外部实体词典或检索模块的依赖。
- 主要实验结果:在CoVoST-2数据集上,平均BLEU从39.1提升至40.6,实体翻译成功率(TSR)从36.4%提升至70.5%。在MuST-C零样本评估中,平均BLEU从16.9提升至20.6。具体对比数据见下表。
方法 CoVoST-2 (En2X) Avg BLEU CoVoST-2 (En2X) Avg TSR MuST-C (zero-shot) Avg BLEU MuST-C (zero-shot) Avg TSR LLM-SRT-7B (基线) 39.1 36.4 16.9 43.2 SEP-ST (CTC-based) 40.6 70.5 20.6 55.0 - 实际意义:提升了语音翻译在真实场景(常包含大量实体)中的可用性和保真度,简化了现有实体翻译增强方案的流程。
- 主要局限性:SEP提取模块的训练依赖于预训练NER模型标注的伪标签;其Transformer变体效果不佳,表明该特征学习方式有待探索;实验仅限于英译德/日/中三种语言方向。
🏗️ 模型架构
整体架构(如图2(a)所示)由四个核心组件顺序连接,输入为语音,输出为翻译文本。
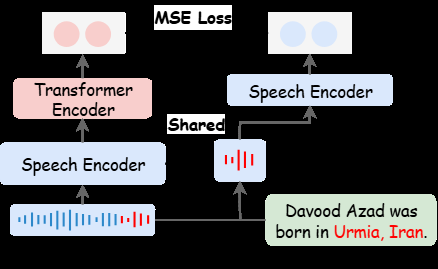
- 语音编码器(Speech Encoder):采用预训练的Whisper-large-V3模型。功能是从原始语音信号中提取全面的帧级声学表示。
- 语音适配器(Speech Adapter):结合预训练的Q-Former和MLP。功能是将语音编码器输出的高维表示压缩并投影到与LLM文本嵌入空间相匹配的维度。
- 语音实体提示提取模块(SEP Extract):这是本文的核心创新模块,有CTC-based(图2(b))和Transformer-based(图2(c))两种实现。功能是并行地从语音编码器的输出中,直接提取与命名实体相关的嵌入特征(SEP embedding)。
- CTC-based SEP Extract (图2(b)):先利用CTC对齐将帧级特征映射到词级token,再通过一个分类头预测每个token是否为实体标签,从而获得词级的实体相关特征。
- Transformer-based SEP Extract (图2(c)):在语音帧特征上叠加一个Transformer编码器,然后通过最小化实体语音段编码与对应位置上下文表示的距离来学习实体特征。
- 大语言模型(LLM):采用预训练的Qwen2.5。功能是接收并处理拼接后的多源嵌入:原始语音特征(经适配器)、SEP实体特征、以及文本指令嵌入。最终自回归地生成目标语言的翻译文本。
数据流:语音→编码器→适配器→(原始语音嵌入)→ 同时送入 LLM & SEP提取模块 → SEP提取模块输出(实体嵌入)→ 与原始语音嵌入、文本嵌入拼接 → LLM → 翻译文本。
💡 核心创新点
- 端到端语音实体特征提取:区别于先识别文本实体再利用的级联方法或依赖外部知识库的检索方法,本文首次提出直接在语音表示空间训练一个专门的模块(SEP Extract)来捕获实体相关的隐含特征,实现了从语音到实体提示的端到端映射。
- 联合训练框架:将SEP提取模块与语音翻译主任务进行联合训练。在第二阶段,冻结语音编码器和适配器,只更新SEP模块参数并通过LoRA微调LLM,通过一个对齐损失(Lalign)显式地让提取的实体特征向LLM的实体token嵌入对齐,有效融合了跨模态信息。
- 无需外部知识库的泛化能力:由于实体特征是直接从输入语音中学习得到的,该方法摆脱了对预定义实体词典或检索模块的依赖。实验结果(尤其是MuST-C零样本评测)证明了其在未见过的数据域上具有更强的泛化能力。
🔬 细节详述
- 训练数据:
- CoVoST-2:用于训练,选择了英→德、英→日、英→中三个方向。
- SEP提取数据集:基于CoVoST-2构建。使用Whisper获得词级时间戳对齐,再用
roberta-large-ner-english对转录文本进行命名实体识别(NER),提取出人名、地名、机构、杂类四类实体对应的语音片段,用于训练SEP提取模块。
- 损失函数:
- CTC-based SEP训练损失(公式6):
L_CTC-Extract = L_ctc + λL_ne。其中L_ctc是CTC对齐损失,L_ne是实体标签分类损失,λ为平衡超参数(具体值未说明)。 - 整体训练损失(公式10):
L_total = λ1L_align + λ2L_st。L_align是SEP嵌入与LLM中实体token嵌入的对齐损失(公式9),L_st是语音翻译损失,λ1和λ2为平衡超参数(具体值未说明)。
- CTC-based SEP训练损失(公式6):
- 训练策略:
- 两阶段训练:第一阶段单独训练SEP提取模块;第二阶段将其整合进完整框架联合训练。
- 优化器:AdamW。
- 学习率:1e-4。
- Warmup步数:1000步。
- 调度策略:线性衰减。
- 并行训练:使用DDP(分布式数据并行)。
- 关键超参数:未详细说明模型具体层数、隐藏维度等。
- 训练硬件:未说明。
- 推理细节:未说明具体的解码策略、beam size、温度等。
- 正则化技巧:未明确提及,但使用了预训练模型和LoRA微调,本身具有正则化效果。
📊 实验结果
主要在CoVoST-2和MuST-C数据集上评估,指标为BLEU(翻译质量)和TSR(术语成功率,衡量实体翻译准确性)。
表1. 主要实验结果对比
| 方法 | 知识库 | CoVoST-2 (En2X) | MuST-C (zero-shot) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| De | Ja | Zh | Avg | De | Ja | Zh | Avg | ||
| BLEU / TSR | BLEU / TSR | BLEU / TSR | BLEU / TSR | BLEU / TSR | BLEU / TSR | BLEU / TSR | BLEU / TSR | ||
| LLM-SRT-7B [6] (基线) | 否 | 28.7 / 43.3 | 41.6 / 35.6 | 47.1 / 30.3 | 39.1 / 36.4 | 18.3 / 49.8 | 11.3 / 41.9 | 21.2 / 38.0 | 16.9 / 43.2 |
| SEP-ST (CTC-based) | 否 | 31.5 / 72.3 | 42.8 / 63.8 | 47.5 / 75.4 | 40.6 / 70.5 | 25.6 / 58.5 | 14.1 / 50.1 | 22.0 / 56.4 | 20.6 / 55.0 |
| SEP-ST (Transformer-based) | 否 | 28.1 / 50.6 | 41.5 / 45.4 | 46.0 / 31.6 | 38.5 / 42.5 | 19.0 / 41.2 | 11.5 / 44.7 | 21.0 / 35.6 | 17.1 / 40.5 |
关键结论:
- 性能提升:提出的SEP-ST (CTC-based)版本在所有测试的语言对和数据集上,BLEU和TSR均显著超越基线LLM-SRT-7B。在CoVoST-2平均BLEU提升1.5点,平均TSR大幅提升34.1个百分点(从36.4%到70.5%)。
- 零样本泛化:在MuST-C零样本测试中,SEP-ST平均BLEU提升3.7点(从16.9到20.6),且TSR也有提升,显示了比依赖外部检索的方法(如RaD)更好的泛化性。
- 消融实验:CTC-based的SEP提取效果远好于Transformer-based的(在CoVoST-2 Avg TSR上70.5% vs 42.5%)。论文分析认为,在相同数据量下,基于CTC的token级序列标注比特征级实体映射更容易学习。
- 案例研究(表2):展示了在英→德、英→日、英→中翻译中,SEP-ST能正确翻译“San Francisco Bay Area”、“Kohoutek”、“Mavis”等实体,而基线模型翻译错误。
图1. 不同方法变体示意图(用于说明问题与本文方法)
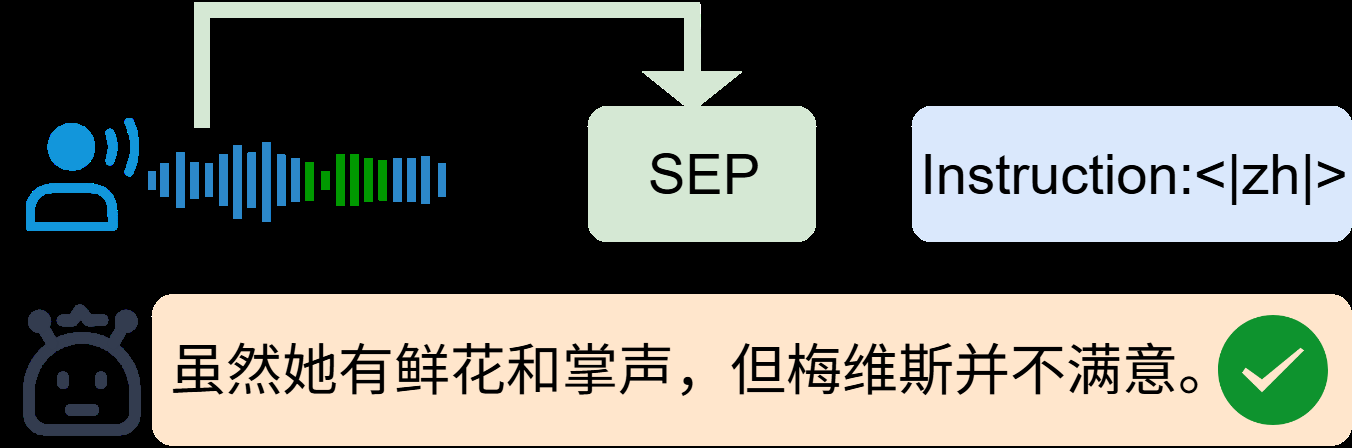 图1展示了传统端到端(a)、基于LLM的级联(b)、知识检索(c)和本文提出的SEP-ST(d)四种方法在处理语音命名实体时的不同路径,直观体现了本文方法(直接从语音提取实体提示)的简化与直接性。
图1展示了传统端到端(a)、基于LLM的级联(b)、知识检索(c)和本文提出的SEP-ST(d)四种方法在处理语音命名实体时的不同路径,直观体现了本文方法(直接从语音提取实体提示)的简化与直接性。
⚖️ 评分理由
- 学术质量:5.5/7。创新性在于将实体特征提取作为提示端到端地融入LLM,解决了实际问题,技术路线合理。实验设计全面,数据充分,结果对比明显。扣分点在于核心思想(提取实体特征作为提示)并非全新,且CTC-based方法的成功部分依赖了现有NER工具生成的伪标签,Transformer-based变体的不佳表现也说明特征学习机制有待深入。
- 选题价值:1.5/2。聚焦于语音翻译中关键的实体翻译瓶颈问题,研究方向实用且具有挑战性。提出的解决方案简洁有效,对提升语音翻译在实际应用中的可靠性有直接价值。
- 开源与复现加成:0.5/1。论文明确承诺开源代码,并提供了GitHub链接。给出了基本的训练超参数和模型组件。但部分关键训练细节(超参数λ值、硬件、推理设置)缺失,复现需要一定实验工作。