📄 Semantic-Guided Pseudo-Feature Attention Network for Audio-Visual Zero-Shot Learning
#音频分类 #零样本学习 #多模态模型 #对比学习 #音视频
✅ 7.0/10 | 前25% | #音频分类 #零样本学习 | #多模态模型 #对比学习 | #音频分类 #零样本学习
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 中
👥 作者与机构
- 第一作者:Siteng Ma(苏州大学)
- 通讯作者:Wenrui Li(哈尔滨工业大学)
- 作者列表:Siteng Ma(苏州大学)、Wenrui Li(哈尔滨工业大学)、Haocheng Tang(北京大学)、Yeyu Chai(哈尔滨工业大学)、Jisheng Chu(哈尔滨工业大学)、Xingtao Wang(哈尔滨工业大学)
💡 毒舌点评
本文的亮点在于将自适应模态加权、语义引导的变分生成与语义对齐的对比学习巧妙融合,形成了一个逻辑自洽的统一框架来解决GZSL中的核心矛盾,并在两个基准数据集上取得了SOTA。然而,其短板在于对SVG模块中具体网络结构的描述较为简略,且未提供任何开源代码或详细的超参数搜索过程,使得完全复现该工作的细节变得困难。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用了ActivityNet, VGGSound, UCF等公开基准数据集,但论文中未提供具体获取方式。
- Demo:未提及。
- 复现材料:论文中提及了部分超参数(损失函数权重λ1-λ5),但缺乏训练细节(如学习率、batch size、优化器、训练轮数)、模型具体配置(如编码器/解码器结构、隐藏维度)以及预训练骨干网络信息。
- 论文中引用的开源项目:论文引用了多个相关工作,但未明确说明其SGPAN实现依赖了哪些具体的开源代码库或工具。
- 总结:论文中未提及开源计划。
📌 核心摘要
这篇论文旨在解决音频-视觉广义零样本学习(GZSL)中因模态竞争和类间分布重叠导致的对可见类过度偏置问题。核心方法是提出一个名为SGPAN的多模态框架,它集成了三个关键组件:1)自适应模态重加权(AMR),动态调整音频和视觉分支的损失权重以平衡学习;2)语义引导变分生成(SVG),利用文本语义条件化的VAE生成伪特征,以扩大类内覆盖并缓解类别混淆;3)语义对齐对比损失(SACL),在投影空间中对齐跨模态特征并扩大类间距。与已有方法相比,新在将特征生成、动态模态平衡与对比学习在同一个端到端框架内协同优化。实验表明,SGPAN在UCF-GZSL和VGGSound-GZSL数据集上的调和平均精度(HM)上取得了当时最优的结果。该工作的实际意义在于为开放世界下的多模态视频理解提供了一个更鲁棒的零样本识别方案。主要局限性包括模型性能对语义标签的质量以及batch统计量的依赖。
🏗️ 模型架构
模型的整体架构如图1所示。SGPAN是一个基于交叉注意力的多模态框架,其输入是来自预训练骨干网络的音频和视觉特征。
- 输入与跨模态特征融合:音频特征 x_a 和视觉特征 x_v 分别经过编码器得到初始嵌入 ϕ_a 和 ϕ_v。随后,这些嵌入通过一个基于Transformer的交叉注意力模块进行交互,捕捉互补信息,得到注意力输出 ϕ_att^a 和 ϕ_att^v。原始嵌入与注意力输出通过残差连接相加,并投影到共享语义空间,得到最终的模态表征 θ_a 和 θ_v。推理时,通过最近邻搜索将表征与类语义嵌入匹配进行预测。
- 语义引导变分生成(SVG):该模块旨在为每个类生成伪特征。对于类嵌入 w,首先通过一个投影层得到 ˆw,然后经过语义引导门控注意力模块(SGAM)进行精炼得到 ˜w。接着,对于每个模态(音频/视觉),一个条件VAE将 ˜w 映射为潜在分布 (μ_m, log σ²_m),并采样得到潜在变量 z_m。解码器 D_m 将 z_m 解码为伪特征 ˆx_m。引入受控噪声 δ 以增加生成多样性。
- 损失函数集成:模型的总损失由四部分组成:跨注意力损失 l_cr、自适应模态重加权损失 l_AMR、语义对齐对比损失 l_s 和生成损失 l_g。这些损失共同优化整个框架。
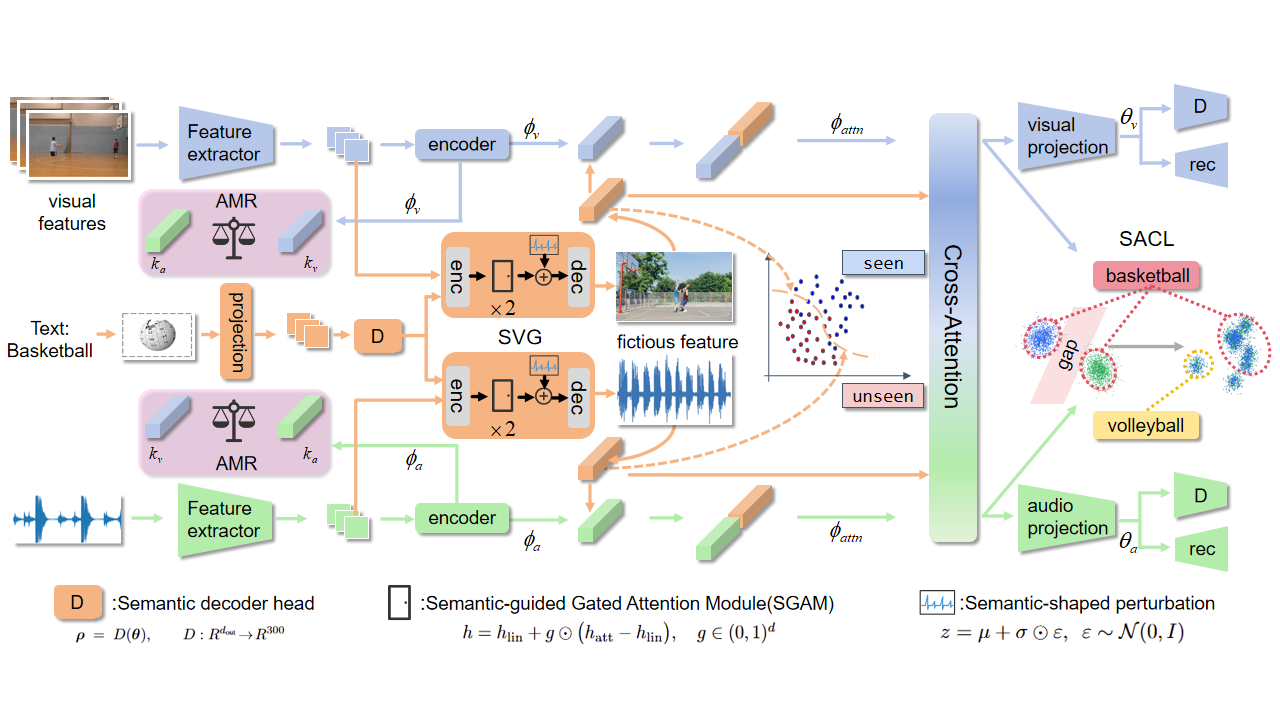 图1:SGPAN的整体结构图。展示了从输入特征提取、跨模态注意力融合、到三个核心模块(AMR、SVG、SACL)的集成,以及最终的预测过程。
图1:SGPAN的整体结构图。展示了从输入特征提取、跨模态注意力融合、到三个核心模块(AMR、SVG、SACL)的集成,以及最终的预测过程。
💡 核心创新点
- 自适应模态重加权(AMR):
- 是什么:一种动态调整音频和视觉模态分类损失权重的机制。权重根据每个batch中各模态的分类准确率自动计算,对较弱的模态赋予更高的权重。
- 之前方法的局限:先前的重加权方法要么基于固定的超参数,要么基于整体性能,缺乏对训练过程中动态变化的适应性,难以有效平衡模态竞争。
- 如何起作用:通过计算批次准确率比 r_m,并映射为有界权重 λ_m = 1 + (β-1) tanh(α(r_m-1)),其中 α 控制敏感度,β 控制最大缩放。这促使模型在训练中更关注当前较弱的模态。
- 收益:消融实验显示,移除AMR后,在VGGSound和ActivityNet数据集上HM分别下降了3.37%和6.14%,证明其对平衡学习至关重要。
- 语义引导变分生成(SVG):
- 是什么:一个文本条件化的VAE生成器,使用SGAM将语义信息注入生成过程,为每个类合成伪音频和视觉特征。
- 之前方法的局限:传统GAN或VAE生成的特征可能缺乏语义区分性,且在可见类和未见类之间容易产生混淆。
- 如何起作用:SVG利用类语义嵌入作为条件,通过SGAM增强语义指导性,生成的伪特征用于扩展训练时的类内分布,使类边界更清晰。
- 收益:生成损失 l_g 直接优化生成特征的质量,消融实验表明,移除SVG或其子组件(SGAM、zaug)会导致性能显著下降,证实其有助于减少类间混淆。
- 语义对齐对比损失(SACL):
- 是什么:一个在投影空间中进行的对比学习损失,旨在拉近同类样本(包括不同模态和生成的增强样本)并推远异类样本。
- 之前方法的局限:简单的跨模态对齐或对比损失可能无法充分放大可见类与未见类之间的间隔,也难以防止VAE的后验坍塌。
- 如何起作用:SACL将视觉、音频特征以及通过统计增强得到的特征 z_aug 堆叠,计算温度缩放的余弦相似度,并使用InfoNCE风格的损失进行优化。
- 收益:在UCF数据集上,移除SACL导致HM下降了6.61%,ZSL精度更是大幅下降。图2的t-SNE可视化显示,SGPAN学习到的特征聚类更紧凑、分离度更好,尤其是未见类。
🔬 细节详述
- 训练数据:
- 数据集:ActivityNet-GZSL, VGGSound-GZSL, UCF-GZSL。
- 来源:标准的音视频分类基准数据集。
- 规模:论文未提供具体样本数量。
- 预处理:使用预训练骨干网络提取音频和视觉特征(论文未指明具体骨干网络)。
- 数据增强:SVG模块通过添加受控噪声 δ 进行特征增强;SACL使用基于批次统计的 z_aug 进行增强。
- 损失函数:
- 跨注意力损失 (l_cr):组合了三元组对齐损失 l_t、复合重建损失 l_c(包含MSE重建损失和辅助三元组损失)、以及投影一致性正则化项 l_r。
- 自适应模态重加权损失 (l_AMR): l_AMR = λ_a l_a^cls + λ_v l_v^cls,其中 λ_m 根据批次准确率 s_m 和性能比率 r_m 动态计算。
- 语义对齐对比损失 (l_s):基于InfoNCE,操作于堆叠的特征 U = [z_v; z_a; z_aug],使用温度缩放的余弦相似度。
- 生成损失 (l_g): l_g = λ4 l_pseudo + λ5 l_KL,其中 l_pseudo 是生成特征的L1范数,l_KL 是VAE的KL散度。
- 总损失: L_SGPAN = λ1l_cr + λ2l_AMR + λ3*l_s + l_g。论文中使用的固定超参数为:λ1=1, λ2=0.5, λ3=0.1, λ4=0.5, λ5=0.2。
- 训练策略:
- 学习率:未说明。
- Warmup:未说明。
- Batch size:未说明。
- 优化器:未说明。
- 训练步数/轮数:未说明。
- 调度策略:未说明。
- 关键超参数:
- 模型大小、层数、隐藏维度:未说明。
- AMR模块参数:α 控制敏感度,β 控制最大缩放,具体值未说明。
- VAE相关参数:λ (控制噪声δ的方差) 未说明。
- 对比学习温度 τ:未说明。
- 训练硬件:未说明。
- 推理细节:通过最近邻搜索,即最小化投影特征 θ_v 与类语义嵌入 θ’_w 之间的L2距离进行分类。
- 正则化或稳定训练技巧:使用了VAE的KL散度作为正则化项;SACL本身也可视为一种正则化,防止特征坍塌。
📊 实验结果
论文在三个标准音频-视觉GZSL基准数据集上进行了评估,主要结果如表1所示。核心评价指标是可见类准确率(Seen)、未见类准确率(Unseen)以及二者的调和平均(HM = 2SU/(S+U)),同时报告了标准ZSL设置下的准确率。
表1:SGPAN与最先进音频-视觉(G)ZSL基线方法在三个基准数据集上的性能对比
| 模型 | VGGSound-GZSL | UCF-GZSL | ActivityNet-GZSL | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Seen | Unseen | HM | ZSL | Seen | Unseen | HM | ZSL | Seen | Unseen | HM | ZSL | |
| AVGZSLNet | 18.05 | 3.48 | 5.83 | 5.28 | 52.52 | 10.90 | 18.05 | 13.65 | 8.93 | 5.04 | 6.44 | 5.40 |
| AVCA | 14.90 | 4.00 | 6.31 | 6.00 | 51.53 | 18.43 | 27.15 | 20.01 | 24.86 | 8.02 | 12.13 | 9.13 |
| AVMST | 14.14 | 5.28 | 7.68 | 6.61 | 44.08 | 22.63 | 29.91 | 28.19 | 17.75 | 9.90 | 12.71 | 10.37 |
| Hyperalignment | 13.22 | 5.01 | 7.27 | 6.14 | 57.28 | 17.83 | 27.19 | 19.02 | 23.50 | 8.47 | 12.46 | 9.83 |
| ACFS | 15.20 | 5.13 | 7.67 | 6.20 | 54.87 | 16.49 | 25.36 | 22.37 | 29.00 | 9.13 | 13.89 | 11.18 |
| TSART | 10.45 | 4.33 | 5.16 | 4.03 | 20.96 | 21.27 | 21.11 | 22.86 | 8.99 | 7.41 | 8.12 | 7.65 |
| MSTR | 13.70 | 5.48 | 7.83 | 6.83 | 86.32 | 19.97 | 32.43 | 23.57 | 22.92 | 9.28 | 13.21 | 9.65 |
| SGPAN | 18.03 | 5.68 | 8.64 | 6.87 | 64.84 | 21.71 | 32.52 | 25.16 | 21.83 | 7.60 | 11.28 | 7.90 |
关键结论:
- 整体SOTA:SGPAN在VGGSound-GZSL和UCF-GZSL数据集上取得了最高的调和平均精度(HM),分别为8.64%和32.52%,超越了包括MSTR在内的所有对比方法。
- 与最强基线对比:在UCF-GZSL上,SGPAN的HM(32.52%)略高于MSTR(32.43%),但ZSL精度(25.16%)显著高于MSTR(23.57%),表明其在标准ZSL设置下优势更明显。
- 权衡可见/未见类:SGPAN在保持较高未见类精度的同时,有效提升了可见类精度(如UCF中Seen为64.84%),实现了更好的平衡。
- ActivityNet数据集:SGPAN在该数据集上的表现(HM 11.28%)并非最优(低于MSTR的13.21%和ACFS的13.89%),可能表明其在更复杂的长视频或场景上的适应性有待加强。
消融实验(表2): 移除任何一个核心组件都会导致性能下降,验证了各模块的必要性。
- 在UCF数据集上,移除SACL对HM影响最大(从32.52%降至25.91%),移除SVG次之(降至26.61%)。
- 在VGGSound和ActivityNet数据集上,移除AMR造成的HM损失最大,分别为3.37%(8.64% → 5.27%)和6.14%(11.28% → 5.14%),突出了自适应模态平衡的重要性。
特征可视化(图2): 论文提供了在UCF数据集上的t-SNE可视化对比。与AVCA(b)相比,SGPAN(a)学习到的特征表示中,未见类(不同颜色点)的聚类更紧凑、分离度更好,且同一类的音频-视频特征在空间中更接近,直观地验证了SVG和SACL在缓解类间混淆和增强跨模态对齐方面的效果。
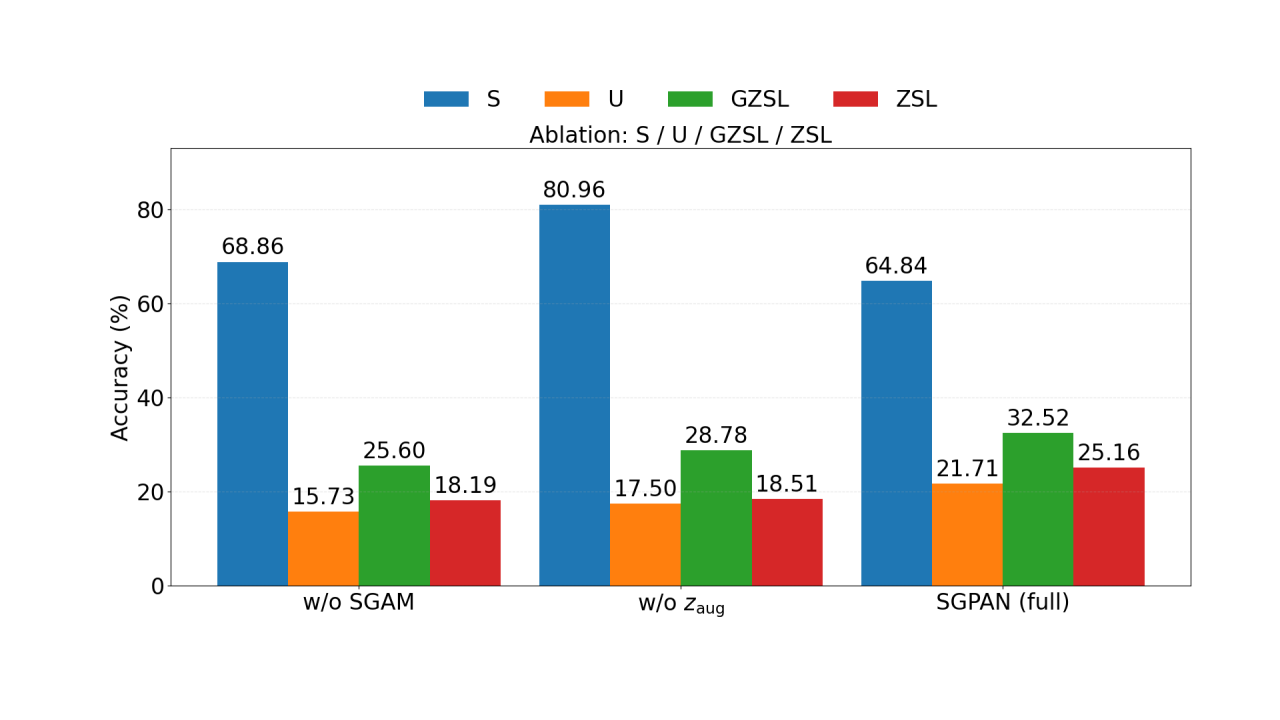 图2:在UCF数据集上的t-SNE可视化。 (a) SGPAN 的表示显示更清晰的类间分离和更紧密的类内聚类。 (b) AVCA 的表示显示出拉长的结构���未见类之间的混合。
图2:在UCF数据集上的t-SNE可视化。 (a) SGPAN 的表示显示更清晰的类间分离和更紧密的类内聚类。 (b) AVCA 的表示显示出拉长的结构���未见类之间的混合。
组件消融(图3): 针对SVG模块的进一步消融显示,移除SGAM(语义引导门控注意力)或zaug(统计增强)都会导致UCF数据集上的HM显著下降(从32.52%分别降至25.60%和28.78%),表明语义引导和特征增强对生成判别性伪特征至关重要。
 图3:关于SGAM和zaug组件的消融研究。移除任一组件都会导致性能下降,证实了SVG模块内部设计的有效性。
图3:关于SGAM和zaug组件的消融研究。移除任一组件都会导致性能下降,证实了SVG模块内部设计的有效性。
⚖️ 评分理由
- 学术质量:6.0/7 - 本文针对音频-视觉GZSL中的多模态平衡和类别偏差两个核心挑战,提出了一个设计巧妙、组件互补的统一框架(SGPAN)。AMR、SVG和SACL三个模块各有明确的技术动机,且相互协同。实验部分在三个标准基准上进行了全面的对比和充分的消融分析,结果具有说服力,证明了方法的有效性。扣分点在于对SVG内部具体网络架构(如SGAM)的描述不够详细,部分超参数未给出,影响了技术细节的完整性。
- 选题价值:1.5/2 - 音频-视觉零样本学习是多媒体理解领域的前沿且具有挑战性的问题,直接应用于开放世界下的视频分类,具有明确的实际应用潜力(如监控、人机交互)。研究与音视频处理、多模态学习高度相关,对本领域读者有参考价值。选题价值较高,但非极为宽泛或影响巨大的方向。
- 开源与复现加成:-0.5/1 - 论文中未提及任何开源代码、预训练模型权重或详细的复现指南(如训练脚本、配置文件)。虽然论文描述了方法框架和主要超参数,但缺乏关键实现细节(如骨干网络选择、学习率、优化器、具体网络维度),这使得独立复现实验变得困难。因此,给予负向加成。