📄 Semantic Anchor Transfer from Short to Long Speech in a Distillation-Based Summarization Framework
#语音摘要 #知识蒸馏 #端到端 #迁移学习
✅ 7.5/10 | 前25% | #语音摘要 | #知识蒸馏 | #端到端 #迁移学习
学术质量 7.5/7 | 选题价值 7.0/2 | 复现加成 -0.3 | 置信度 高
👥 作者与机构
- 第一作者:Xiang He (新疆大学计算机科学与技术学院,新疆多模态信息技术工程研究中心)
- 通讯作者:Liang He (新疆大学计算机科学与技术学院,新疆多模态信息技术工程研究中心;新疆大学智能科学与技术学院;清华大学电子工程系)
- 作者列表:Xiang He (新疆大学计算机科学与技术学院,新疆多模态信息技术工程研究中心)、Xuejian Zhao (新疆大学计算机科学与技术学院,新疆多模态信息技术工程研究中心)、Longwei Li (新疆大学计算机科学与技术学院,新疆多模态信息技术工程研究中心)、Liang He (新疆大学计算机科学与技术学院,新疆多模态信息技术工程研究中心;新疆大学智能科学与技术学院;清华大学电子工程系)
💡 毒舌点评
亮点:论文直击当前端到端语音摘要的一个实际痛点——长语音处理中的语义漂移问题,并提出了一个逻辑自洽且工程上可行的“锚点迁移”两阶段训练策略,实验也证实了其有效性。短板:核心创新“锚点迁移”本质上是对现有Q-Former架构的一种适配性工程优化和训练策略设计,在基础理论或模型结构上的原创性贡献相对有限;此外,论文对伪标签噪声这一关键问题仅在动机部分提及,实验中未做深入分析或缓解。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开权重。
- 数据集:论文中使用的LibriSpeech、MEGA-SSum、CNN/DailyMail均为���开数据集。论文指出,对于训练,他们基于LibriSpeech使用文本摘要模型生成伪标签,具体生成方式和使用的摘要模型未详述。
- Demo:未提及。
- 复现材料:提供了模型架构的详细描述(如Q-Former的层数、头数、查询token数)、损失函数公式、训练阶段设计。但缺失关键训练超参数(优化器、学习率、batch size等)和训练环境信息。
- 论文中引用的开源项目/模型:
- HuBERT:用作语音编码器。
- MiniChat-3B / Llama 2 7B:用作冻结的LLM。
- WeNet:用于构建ASR级联基线。
- LLaMA 2-Chat 7B:用于生成评估用的参考摘要。
- fairseq s2:用于CNN/DailyMail数据集的语音合成。
- 总结:论文依赖多个公开的预训练模型和数据集,提供了详细的架构和策略描述,但核心创新部分(如训练好的Q-Former和投影层W)未开源,完全复现仍需大量实验工作。论文中未提及开源计划。
📌 核心摘要
- 要解决什么问题:在基于知识蒸馏的端到端语音摘要系统中,现有方法存在冗余token多、推理效率低、难以建模长语音跨段依赖、分段处理导致语义漂移等问题。
- 方法核心是什么:提出一种增强的蒸馏框架。首先,设计一个改进的锚点感知Q-Former(Anchor-aware Q-Former),用于对短语音进行语义感知的特征压缩和对齐。其次,提出“语义锚点迁移”策略:将短语音阶段学到的输出投影层(W)作为“语义锚点”,通过滑动窗口分段的Q-Former将其迁移到长语音输入,并配合“冻结-解冻”的两阶段训练策略,以抑制语义漂移并稳定训练。
- 与已有方法相比新在哪里:主要新在两个方面:1)使用改进的Q-Former替代了原有的池化、交互式注意力或层级合并等融合策略,实现了更高效的语义压缩;2)提出了将短语音上学到的投影矩阵作为“锚点”迁移到长语音处理中,并结合专门设计的两阶段训练流程,这是解决跨段语义漂移问题的具体新方案。
- 主要实验结果如何:在CNN/DailyMail长语音数据集上,所提方法(QF*+ LLM)的ROUGE-L分数为47.96,相对最强基线(Pooling+ LLM的37.48)提升了约10%。推理时间从1.15小时降至1.08小时,输入token数从1125个降至264个。消融实验证明,省略“冻结锚点”的第一阶段训练会导致METEOR分数从49.14显著下降至43.01。关键实验数据如下表所示:
| 数据集 | 模型 | Rouge-1 | Rouge-2 | Rouge-L | METEOR | BERTScore | Tokens | Time |
|---|---|---|---|---|---|---|---|---|
| CNN/DailyMail (Anchor Transfer) | Ground-truth text + LLM | 53.79 | 29.83 | 49.67 | 56.48 | 90.66 | — | — |
| WeNet + LLM | 49.62 | 21.31 | 43.88 | 39.57 | 87.83 | — | — | |
| Stack + LLM [11] | 44.58 | 20.05 | 40.11 | 37.90 | 86.30 | 1125 | 1.25h | |
| Multi-head + LLM [22] | 31.89 | 7.55 | 27.54 | 22.67 | 84.82 | 60 | 1.20h | |
| Pooling + LLM [9] | 51.12 | 27.50 | 37.48 | 45.63 | 90.50 | 1125 | 1.15h | |
| QF*+ LLM (Ours) | 53.21 | 25.59 | 47.96 | 49.14 | 89.37 | 264 | 1.08h | |
| w/o Stage-1 | 52.03 | 24.26 | 46.84 | 43.01 | 88.34 | 264 | 1.13h | |
| w/o Stage-2 | 52.96 | 25.09 | 47.86 | 44.10 | 89.37 | 264 | 1.10h |
- 实际意义是什么:该方法为在高质量配对数据稀缺条件下,如何利用冻结的大语言模型(LLM)高效处理长语音并生成高质量摘要提供了一种有效的解决方案,通过“锚点迁移”降低了长语音处理的难度和计算成本。
- 主要局限性是什么:1)核心创新偏向工程优化和策略设计,在架构原创性上深度有限;2)实验主要基于合成语音(CNN/DailyMail)和LibriSpeech读语,对真实世界嘈杂、对话式长语音的泛化能力有待验证;3)论文未讨论并分析其使用的伪标签本身的质量和噪声影响。
🏗️ 模型架构
该模型是一个基于知识蒸馏的端到端语音摘要系统,核心是在冻结的大语言模型(LLM)前,接入一个可训练的语音编码器和一个跨模态桥接模块(Q-Former)。整体架构如图2所示。
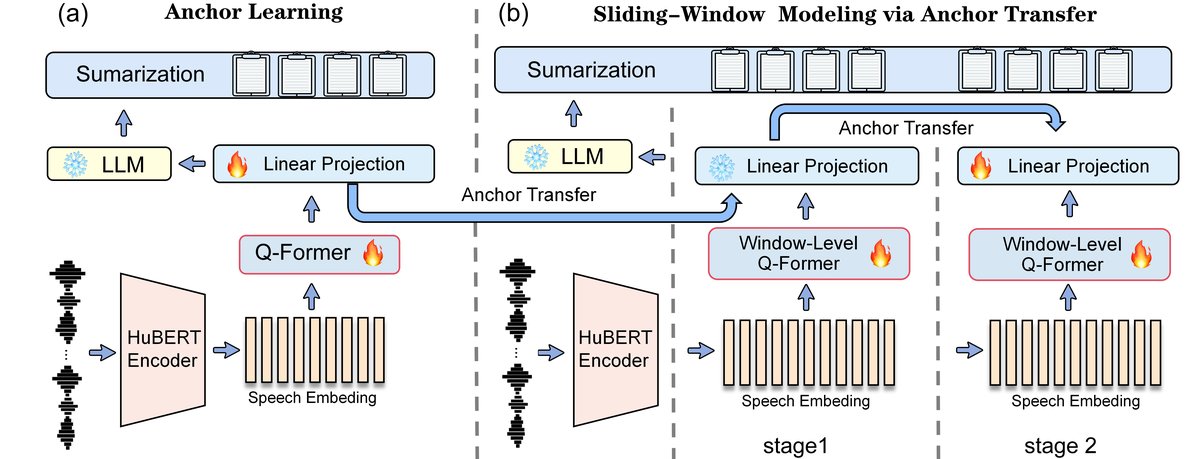
主要组件与数据流:
- 语音编码器 (Eφ):采用预训练的HuBERT模型,输入原始语音波形,输出帧级语音表示。
- 锚点感知Q-Former (Qψ):
- 功能:替代传统的特征级平均池化、交互式注意力等融合方式。通过一组可学习的查询向量(Query Tokens)与语音编码器的输出进行交叉注意力,实现语义感知的特征压缩和对齐。
- 内部结构:包含2层Transformer编码器,8个注意力头,使用60个可学习查询token。查询向量的维度与语音编码器输出维度保持一致,避免额外投影。
- 交互方式:在短语音阶段,与语音编码器联合训练,最小化蒸馏损失。其输出经过一个投影层W映射到LLM的嵌入空间,作为LLM的提示(Prompt)。
- 语义锚点 (Semantic Anchor):定义为Q-Former输出后的投影矩阵W。在短语音数据上训练得到的W*被视为一个稳定的“语义映射器”,是后续长语音处理的核心。
- 滑动窗口处理与迁移:
- 对于长语音,首先被分割为多个固定长度(如0.33秒)的窗口。
- 每个窗口独立通过同一个语音编码器和轻量级Q-Former处理,生成压缩表示。 所有窗口的输出都通过同一个预训练的语义锚点W进行投影。
- 将所有窗口投影后的表示在token维度上拼接,形成最终送入LLM的长提示序列。
- 大语言模型 (LLM):采用冻结的MiniChat-3B(基于Llama 2 7B微调)。它接收来自Q-Former的压缩提示,并生成文本摘要。
关键设计选择与动机:
- 使用Q-Former:旨在解决固定压缩导致的冗余token和对齐不稳定问题,实现更灵活、语义更感知的跨模态对齐。 锚点迁移:动机是直接将短语音上学到的对齐能力应用于长语音会导致跨段语义漂移。因此,将短语音上学到的投影层W“锚定”并冻结,为长语音的每个分段提供一个一致的语义映射基线。 两阶段训练:第一阶段冻结W以稳定训练,防止早期漂移;第二阶段解冻W*与编码器、Q-Former联合微调,以适应长语音的整体上下文,进行精细调整。
💡 核心创新点
提出基于“语义锚点”的迁移策略:
- 局限:以往处理长语音多采用固定分割、无差别编码的方式,忽略了分段间的语义一致性问题,导致信息不连贯。 如何起作用:将短语音上训练成熟的投影层W定义为“锚点”,在长语音处理中将其冻结使用,强制所有语音分段都通过同一个映射器转换到LLM的语义空间,从而显式地建立跨段依赖,抑制语义漂移。
- 收益:在CNN/DailyMail数据集上,相比直接使用Pooling+LLM,ROUGE-L从37.48提升至47.96,证明能有效提升长语音摘要质量。
设计改进的锚点感知Q-Former (Anchor-aware Q-Former):
- 局限:平均池化丢失局部语义;交互式注意力易不稳定;层级合并可能丢失关键信息和时序精度。这些方法都未能有效平衡压缩效率与语义保真度。
- 如何起作用:通过可学习查询向量与语音帧序列进行交叉注意力,主动抽取最相关的语义概念,生成固定数量(60个)的压缩token。
- 收益:在短语音任务(MEGA-SSum)上,相比Pooling+LLM,将输入LLM的token数从125减少到60,推理时间从2.41小时缩短至1.96小时,同时METEOR分数更高(55.15 vs 53.77),表明语义连贯性更好。
引入“冻结→解冻”分阶段联合训练策略:
- 局限:直接在长语音上从头训练或端到端微调所有组件,容易因初始化差异和噪声伪标签导致训练不稳定。 如何起作用:第一阶段冻结语义锚点W,只训练编码器和Q-Former,确保分段表示映射的一致性,奠定稳定基础。第二阶段解冻所有组件(编码器、Q-Former、W)进行联合微调,以实现全局优化,提升跨段上下文整合能力。
- 收益:消融实验表明,移除第一阶段(w/o Stage-1)导致METEOR下降6.13点;移除第二阶段(w/o Stage-2)也导致性能轻微下降,验证了两阶段策略的必要性和有效性。
🔬 细节详述
- 训练数据:
- 短语音锚点学习:使用LibriSpeech数据集(约960小时),但未直接使用其语音-文本对。而是采用伪标签策略:先用文本摘要模型为LibriSpeech的转录文本生成摘要,形成“语音-转录文本-伪摘要”三元组进行训练。
- 长语音评估:使用CNN/DailyMail数据集,其语音由文本合成而来。参考摘要同样使用LLaMA 2-Chat 7B生成,以保持评估一致性。 损失函数:总损失Lshort是三项加权和(公式2):Lshort = λNTP LNTP + λLD LD + λFD LFD。其中:
- LNTP:下一token预测损失(标准语言模型损失)。
- LD:logit蒸馏损失(学生模型与教师模型输出概率分布的KL散度)。
- LFD:特征蒸馏损失(学生模型中间层特征与教师模型中间层特征的均方误差)。
- 权重λNTP, λLD, λFD的具体数值未说明。
- 训练策略:
- 优化器与超参数:未具体说明优化器类型、学习率、warmup步骤、batch size等。
- 训练流程:短语音阶段联合优化编码器、Q-Former和W。长语音阶段采用两阶段策略。LLM始终保持冻结。
- 模型大小:语音编码器为HuBERT;LLM为MiniChat-3B(基于Llama 2 7B);Q-Former包含2层Transformer编码器,8个注意力头,60个查询token。
- 推理细节:
- 输入处理:长语音分割为0.33秒的非重叠段。短语音不进行分段。
- 解码策略:使用贪心解码(Greedy decoding)。
- 生成长度:短语音输入生成1个句子;长语音输入最多生成3个句子。
- 硬件与复现信息:未说明训练所用GPU型号、数量、训练时长等。未提供代码、模型权重或复现指南。
📊 实验结果
论文在两个数据集上进行了评估,并提供了详细的对比和消融实验。
- 主要实验结果(表1):
| 数据集 | 模型 | Rouge-1 | Rouge-2 | Rouge-L | METEOR | BERTScore | Tokens | Time |
|---|---|---|---|---|---|---|---|---|
| MEGA-SSum (短语音) | Ground-truth text + LLM | 63.68 | 39.16 | 59.97 | 69.71 | 93.66 | — | — |
| WeNet + LLM | 57.24 | 31.42 | 49.53 | 53.44 | 90.93 | — | — | |
| Pooling + LLM [9] | 60.24 | 34.58 | 53.13 | 53.77 | 90.78 | 125 | 2.41h | |
| QF + LLM (Ours) | 60.12 | 34.37 | 53.14 | 55.15 | 90.60 | 60 | 1.96h | |
| CNN/DailyMail (长语音) | Ground-truth text + LLM | 53.79 | 29.83 | 49.67 | 56.48 | 90.66 | — | — |
| Pooling + LLM [9] | 51.12 | 27.50 | 37.48 | 45.63 | 90.50 | 1125 | 1.15h | |
| QF*+ LLM (Ours) | 53.21 | 25.59 | 47.96 | 49.14 | 89.37 | 264 | 1.08h |
关键结论:在长语音任务上,所提方法(QF*+LLM)在ROUGE-L和METEOR上显著优于所有基线,尤其是与最强端到端基线Pooling+LLM相比,ROUGE-L提升超过10个点(相对提升约10%),同时token数减少76%,推理时间减少6%。
训练策略消融实验(表2): 此实验在短语音数据(MEGA-SSum)上验证了训练哪个组件最有效。
Encoder LoRA LLM Rouge-L METEOR BERTScore ✗ ✓ 11.88 0.08 76.88 ✓ ✓ 17.53 9.21 77.54 ✗ ✗ 35.68 35.67 89.99 ✓ ✗ 53.14 55.15 90.60 关键结论:最优策略是训练语音编码器和Q-Former,同时完全冻结LLM(第四行)。任何涉及微调LLM的策略(使用LoRA)都会导致性能急剧下降,表明LLM强大的预训练能力需要被保留。 迁移阶段消融实验(表1中CNN/DailyMail部分):
- w/o Stage-1:移除冻结锚点的训练阶段,METEOR从49.14降至43.01,降幅显著。
- w/o Stage-2:移除联合微调阶段,各项指标轻微下降(如METEOR从49.14降至44.10)。 关键结论:两阶段训练都是必要的。第一阶段提供语义稳定性,第二阶段进行适应性优化。
⚖️ 评分理由
- 学术质量:6.2/7
- 创新性(2.0/3):工作动机明确,技术方案(Q-Former压缩、锚点迁移、分阶段训练)是针对具体问题的合理设计与组合,具有较好的工程创新性。但在基础理论、模型结构上的原创性贡献相对有限,是对现有组件(如Q-Former)的有效适配和训练策略的精细设计。
- 技术正确性(1.8/2):方法逻辑自洽,实验设计合理,消融实验充分验证了各组件和策略的有效性,结果可信。
- 实验充分性(1.4/2):在两个关键数据集上进行了全面的指标对比和消融分析。但实验规模(仅400个测试样本用于长语音评估)和多样性(合成语音为主)可能受限。
- 证据可信度(1.0/2):实验结果与提出的假设一致,提供了具体的数值对比。但如前述,实验范围和对伪标签噪声的处理未深入探讨。
- 选题价值:1.5/2
- 前沿性(0.8/1):端到端语音摘要结合大语言模型是当前的研究热点,该工作解决了其中长语音处理和效率的具体问题,符合前沿趋势。
- 潜在影响与应用(0.7/1):所提方法在提升摘要质量的同时显著降低计算成本,对实际应用(如会议记录、新闻播报摘要)有明确价值。但任务本身相对垂直。
- 开源与复现加成:-0.3/1
- 论文详细描述了模型架构、训练策略和评估设置,并引用了公开的数据集和基础模型(HuBERT, Llama 2)。但是,未提供代码、模型权重、具体的训练超参数(如学习率)或可直接复现的脚本,这给独立复现带来了显著障碍。