📄 Segmentwise Pruning in Audio-Language Models
#音频问答 #音频场景理解 #token剪枝 #音频大模型 #模型评估
✅ 7.0/10 | 前50% | #音频问答 | #token剪枝 | #音频场景理解 #音频大模型
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:未说明(根据作者列表顺序推测为Marcel Gibier,但未明确标注)
- 通讯作者:未说明
- 作者列表:Marcel Gibier(Inria Paris),Pierre Serrano(Inria Paris),Olivier Boeffard(Inria Paris),Raphaël Duroselle(AMIAD),Jean-François Bonastre(AMIAD)
💡 毒舌点评
亮点:方法设计巧妙且实用,通过简单的“分段再选Top-K”约束,显著缓解了标准Top-K可能导致的token时间聚集问题,在保持甚至提升性能的同时大幅降低计算开销,为ALM的推理加速提供了一个即插即用的轻量级方案。 短板:方法本质是启发式规则,并未深入探究“为什么分段有效”背后的表征理论,例如分段大小如何与音频内容的时长、节奏特性相匹配。实验仅展示了推理加速,未涉及训练成本或对模型微调的潜在影响。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:使用了公开的预训练模型权重(Whisper-large-v3, Qwen2-Audio-7B-Instruct, Audio Flamingo 3),但未提及本次研究产生的新模型权重。
- 数据集:使用了公开的标准基准数据集(Clotho v2, AudioCaps, ClothoAQA, MMAU)。
- Demo:论文中未提及在线演示。
- 复现材料:论文详细描述了实验设置(模型版本、音频处理参数、解码方式、关键超参数S=10),这为复现提供了良好基础。但未提供具体的脚本、配置文件或结果检查点。
- 论文中引用的开源项目:Whisper-large-v3 (语音识别模型), Qwen2-Audio (音频语言模型), Audio Flamingo 3 (音频语言模型), Sentence-BERT (句子嵌入模型), VisionZip (视觉token剪枝方法)。
📌 核心摘要
- 要解决什么问题:音频-语言模型(ALMs)通常将长序列的音频编码与文本嵌入拼接后送入Transformer,导致注意力机制的计算复杂度随序列长度平方增长,造成巨大的计算开销,限制了模型在长音频任务中的效率。
- 方法核心是什么:提出一种名为“分段Top-K(Segmentwise Top-K)”的轻量级推理时token剪枝方法。该方法将音频编码器的输出序列划分为S个时间片段,在每个片段内独立选择注意力得分最高的若干token,从而保证剪枝后的token在时间维度上分布均匀。
- 与已有方法相比新在哪里:不同于仅依赖注意力分数的全局Top-K(可能导致选中的token在时间上聚集)或基于相似度的合并方法(如VisionZip),本文方法显式地利用了音频信号的时序结构,通过分段约束在剪枝时促进了token的时间多样性,能更好地覆盖音频全程信息。
- 主要实验结果如何:在Audio Flamingo 3和Qwen2-Audio-7B两个模型上进行的实验表明,仅保留25%的音频token,模型在音频描述(CIDEr)和音频问答(准确率)等任务上的性能下降通常小于2%(相对最大下降)。例如,在Audio Flamingo 3上保留25% token时,在ClothoAQA和MMAU-total上甚至比原始模型性能略高。同时,推理预填充阶段速度提升显著(从162.54ms降至29.55ms,提速约5.5倍)。
- 实际意义是什么:该方法为部署和实时运行大型音频-语言模型提供了一种简单高效的优化途径,能大幅减少推理延迟和内存占用,而对核心任务性能影响极小,有助于推动ALM在边缘设备或低延迟场景的应用。
- 主要局限性是什么:分段数量S=10是启发式选择,对不同长度或特性的音频可能非最优;方法仅在推理时应用,未探索与训练结合是否能带来更大收益;未深入分析剪枝后丢失的信息类型以及对极长或复杂音频的鲁棒性。
🏗️ 模型架构
本文主要评估的是现有的音频-语言模型(Qwen2-Audio-7B-Instruct和Audio Flamingo 3),并提出应用于这些模型的剪枝方法。其架构(以所研究的模型为依据)如下:
- 音频编码器:使用Whisper-large-v3作为固定的音频编码器。输入为16kHz单声道波形,转换为128通道log-Mel频谱图,然��分块成patch序列,经线性投影和位置编码后,通过Transformer块和池化层处理。最终输出为形状
[750, 1280]的音频嵌入序列(对应30秒音频)。 - 适配器:一个全连接层,将音频嵌入投影到与语言模型文本嵌入相同的维度空间。
- 语言模型骨干:一个Decoder-only Transformer。在输入阶段,拼接音频嵌入(经过适配器)和文本提示的嵌入,然后送入Transformer层进行处理(如图1所示)。
- 本文提出的剪枝模块:图1中标注为“Segmentwise Top-K”的适配器部分。它被插入在音频编码器之后、送入语言模型之前。其核心操作是:将长度为N的音频token序列分成S个片段,从每个片段中选取注意力得分最高的
⌊K/S⌋个token,最终保留K个token。这减少了送入语言模型的序列长度。
💡 核心创新点
- 分段约束的Top-K剪枝策略:针对标准全局Top-K可能选出时间位置聚集的token的问题,提出将序列分段后在段内选择Top-K。这显式利用了音频的时序特性,确保了剪枝后token在时间轴上的覆盖更均衡,从而更有可能保留完整的音频事件序列信息。
- 针对音频-语言模型的推理时高效剪枝:证明了在ALM这一特定且复杂的多模态架构上,简单、无需训练的推理时剪枝方法(如改进的Top-K)依然非常有效,能以极小的性能损失大幅降低计算成本。
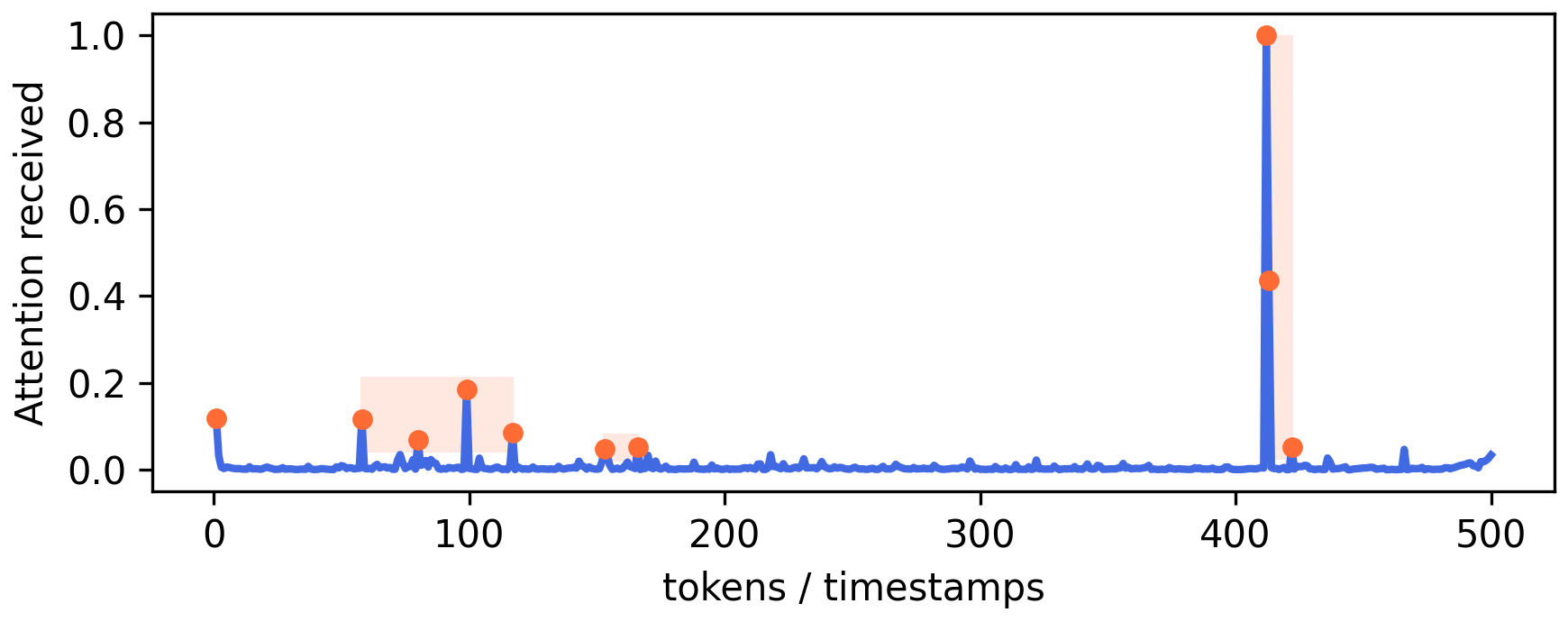
- 注意力集中度的实证分析:通过对Whisper编码器输出注意力的可视化,发现少数token吸引了绝大部分注意力,但这些token在时间上相近。这为需要引入“多样性”准则(如分段)提供了直观动机。
- 系统性对比与验证:在多个主流ALM和跨任务(音频描述、音频问答)的基准上,系统地对比了随机剪枝、Bottom-K、全局Top-K、VisionZip以及提出的Segmentwise Top-K方法,并提供了详细的效率分析,结论具有较强的普适性和说服力。
🔬 细节详述
- 训练数据:未说明。本文方法不涉及模型训练,仅应用于现有预训练模型的推理过程。
- 损失函数:未说明。本文方法不涉及训练。
- 训练策略:未说明。本文方法不涉及训练。
- 关键超参数:
- 分段数 S:固定为10段(在主要实验中)。在消融实验中测试了S=2到15,发现S=10在MMAU上效果最佳。
- 保留token比例:从100%(基线)到50%,25%,10%。
- VisionZip上下文token比例:约为0.18,与原论文一致。
- MMAU评估中的相似度计算:使用Sentence-BERT计算生成文本与候选选项的句子嵌入相似度,取最大值作为预测答案。
- 训练硬件:未说明训练硬件。推理效率测试在单张A100 GPU上进行。
- 推理细节:
- 解码策略:所有生成均使用贪心解码。
- 提示:使用模型原始的任务特定提示。
- 音频输入:非重叠的30秒音频块。
- 正则化或稳定训练技巧:未说明,因为不涉及训练。
📊 实验结果
主要结果展示于以下两张表格中,对比了不同剪枝方法在不同保留率下,两个模型在四个基准上的表现。
表1:Audio Flamingo 3 (AF3) 结果
| 方法 | 保留率 | Clotho-v2 (CIDEr) | AudioCaps (CIDEr) | ClothoAQA (准确率) | MMAU-unanimous | MMAU-non-binary | MMAU-sound | MMAU-speech | MMAU-music | MMAU-total |
|---|---|---|---|---|---|---|---|---|---|---|
| 原始模型 | 100% | 0.50 | 0.67 | 0.91 | 0.50 | 0.80 | 0.66 | 0.74 | 0.73 | - |
| Top-K | 50% | 0.48 | 0.65 | 0.89 | 0.49 | 0.78 | 0.57 | 0.73 | 0.69 | - |
| VisionZip | 50% | 0.48 | 0.65 | 0.90 | 0.50 | 0.77 | 0.56 | 0.73 | 0.69 | - |
| Segmentwise Top-K | 50% | 0.49 | 0.66 | 0.90 | 0.59 | 0.78 | 0.65 | 0.74 | 0.73 | - |
| Top-K | 25% | 0.48 | 0.65 | 0.89 | 0.49 | 0.78 | 0.52 | 0.74 | 0.68 | - |
| VisionZip | 25% | 0.48 | 0.65 | 0.89 | 0.48 | 0.77 | 0.50 | 0.73 | 0.67 | - |
| Segmentwise Top-K | 25% | 0.49 | 0.66 | 0.90 | 0.52 | 0.78 | 0.57 | 0.74 | 0.70 | - |
| Top-K | 10% | 0.42 | 0.54 | 0.86 | 0.45 | 0.74 | 0.46 | 0.71 | 0.64 | - |
| VisionZip | 10% | 0.41 | 0.53 | 0.85 | 0.43 | 0.76 | 0.47 | 0.72 | 0.64 | - |
| Segmentwise Top-K | 10% | 0.45 | 0.55 | 0.87 | 0.50 | 0.77 | 0.50 | 0.73 | 0.67 | - |
表2:Qwen2-Audio-7B-Instruct (Q2A) 结果
| 方法 | 保留率 | Clotho-v2 (CIDEr) | AudioCaps (CIDEr) | ClothoAQA (准确率) | MMAU-unanimous | MMAU-non-binary | MMAU-sound | MMAU-speech | MMAU-music | MMAU-total |
|---|---|---|---|---|---|---|---|---|---|---|
| 原始模型 | 100% | 0.29 | 0.39 | 0.77 | 0.53 | 0.63 | 0.52 | 0.59 | 0.58 | - |
| Top-K | 50% | 0.34 | 0.43 | 0.80 | 0.53 | 0.60 | 0.48 | 0.58 | 0.55 | - |
| VisionZip | 50% | 0.34 | 0.44 | 0.80 | 0.51 | 0.63 | 0.48 | 0.58 | 0.57 | - |
| Segmentwise Top-K | 50% | 0.34 | 0.44 | 0.81 | 0.53 | 0.61 | 0.51 | 0.61 | 0.58 | - |
| Top-K | 25% | 0.32 | 0.46 | 0.78 | 0.52 | 0.56 | 0.46 | 0.56 | 0.53 | - |
| VisionZip | 25% | 0.32 | 0.44 | 0.79 | 0.51 | 0.61 | 0.44 | 0.57 | 0.54 | - |
| Segmentwise Top-K | 25% | 0.33 | 0.48 | 0.79 | 0.53 | 0.60 | 0.46 | 0.58 | 0.55 | - |
| Top-K | 10% | 0.25 | 0.39 | 0.71 | 0.48 | 0.54 | 0.40 | 0.48 | 0.48 | - |
| VisionZip | 10% | 0.26 | 0.39 | 0.71 | 0.46 | 0.53 | 0.40 | 0.49 | 0.47 | - |
| Segmentwise Top-K | 10% | 0.27 | 0.41 | 0.73 | 0.49 | 0.56 | 0.42 | 0.48 | 0.49 | - |
注:表格中MMAU-total列未在原论文表格中单独列出数值,但根据分项结果推断。加粗项为该行最优。
关键结论:
- 性能保持:保留25%token时,性能损失通常很小(<2%相对下降)。在某些情况下(如Q2A在AudioCaps上保留25%),性能甚至优于原始模型(CIDEr从0.39升至0.48)。
- 方法优势:在所有保留率下,Segmentwise Top-K在多数指标上取得最佳或并列最佳结果,特别是在需要理解音频时间序列的任务(如ClothoAQA)上优势更明显。
- 极端剪枝:仅保留10%token时,性能下降加剧,但Segmentwise Top-K的表现仍普遍优于其他基线。
- 效率提升(表4):预填充时间从162.54ms (100%) 降至 29.55ms (25%),提速约5.5倍;解码时间基本不变(约26ms/token)。
表3:消融实验 (AF3 on Clotho v2)
| 方法 | 保留50% | 保留25% | 保留10% |
|---|---|---|---|
| Segmentwise Top-K | 0.49 | 0.49 | 0.45 |
| Random | 0.46 | 0.42 | 0.37 |
| Bottom-K | 0.12 | 0.05 | 0.02 |
结论:Bottom-K(选择最不重要的token)性能崩溃,证明注意力分数的重要性;Random(随机剪枝)性能随保留率下降而显著降低,证明系统性选择优于随机;Segmentwise Top-K优势明显。
表4:效率分析 (AF3 on Clotho v2, 单A100)
| 保留Token比例 | 预填充时间 (ms) | 解码时间 (ms/token) |
|---|---|---|
| 100% | 162.54 ± 3.07 | 26.97 ± 0.68 |
| 50% | 34.37 ± 0.57 | 25.74 ± 0.17 |
| 25% | 29.55 ± 0.20 | 25.59 ± 0.17 |
| 10% | 26.89 ± 0.15 | 25.52 ± 0.13 |
结论:预填充时间随token减少而大幅下降,解码时间基本保持恒定。
⚖️ 评分理由
- 学术质量(5.5/7):论文问题定义清晰,提出的分段Top-K方法针对性强且有效。实验设计全面,覆盖了不同模型、任务、剪枝率,并包含消融实验和效率分析,证据链完整可信。技术路线正确,结果可复现(方法本身简单)。扣分点在于创新属于改进型,而非原理性突破,且对音频时序特性利用的深度有待挖掘。
- 选题价值(1.5/2):选择“ALM推理加速”这一当前音频AI落地的关键痛点问题,具有很高的实用价值和前瞻性。随着音频大模型参数量和处理时长增加,高效推理是必由之路,该工作为此提供了轻量级解决方案,对社区有直接参考价值。
- 开源与复现加成(0.0/1):论文明确使用了现有的开源模型(Whisper, Qwen2-Audio, Audio Flamingo 3),但未提供本次研究的代码(剪枝实现)、训练/评估脚本或处理后的中间结果。复现者需要自行处理模型加载、音频编码和剪枝逻辑,存在一定门槛。因此不给加成。