📄 SED: Structural Entropy Based Speech Discretization for Discrete Token-Based ASR
#语音识别 #自监督学习 #聚类 #语音大模型 #基准测试
✅ 6.5/10 | 前50% | #语音识别 | #自监督学习 #聚类 | #自监督学习 #聚类
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 中
👥 作者与机构
- 第一作者:Ling Dong (昆明理工大学, 云南人工智能重点实验室)
- 通讯作者:Shengxiang Gao (昆明理工大学, 云南人工智能重点实验室)
- 作者列表:Ling Dong (昆明理工大学, 云南人工智能重点实验室)、Wenjun Wang (昆明理工大学, 云南人工智能重点实验室)、Yan Xiang (昆明理工大学, 云南人工智能重点实验室)、Yantuan Xian (昆明理工大学, 云南人工智能重点实验室)、Shengxiang Gao (昆明理工大学, 云南人工智能重点实验室)
💡 毒舌点评
亮点:将“结构熵”这一图论概念引入语音离散化,动机清晰(自适应确定簇数、显式建模帧间关系),为改进语音token质量提供了一个新颖的理论视角,实验结果也验证了其在WER和聚类纯度上优于K-means。 短板:实验的“深度”不足——仅在LibriSpeech一个数据集上验证,且用于下游LLM(GPT2、Qwen2-0.5B)规模偏小,无法充分展示该方法在大模型时代的真正价值;同时,论文未提供任何代码或模型,对于一篇方法论文来说,严重削弱了其可复现性和社区影响力。
🔗 开源详情
- 代码:论文中未提及任何代码仓库链接或开源计划。
- 模型权重:论文中未提及是否公开SED离散化后的token序列或训练好的ASR模型权重。引用的预训练模型(HuBERT, WavLM, GPT2, Qwen2)本身是公开的。
- 数据集:使用的是公开的LibriSpeech数据集,论文中未提供额外数据的获取方式。
- Demo:论文中未提及提供在线演示。
- 复现材料:论文给出了一些关键的超参数(如下采样因子s=0.001,块长度L=1000,优化器和学习率),但缺少许多完整复现所���的细节(如具体的图构建阈值搜索范围、增量优化中的迭代次数I、训练的具体batch size、日志记录等)。
- 论文中引用的开源项目:HuBERT、WavLM的预训练模型;GPT2和Qwen2的LLM权重;使用了
fairseq或类似框架进行语音特征提取(但未明确说明)。
📌 核心摘要
- 要解决什么问题:如何将连续语音特征离散化为token序列,以适配大语言模型(LLM)的离散输入空间,同时保留足够的声学-语言学信息。现有方法(如K-means)需要预设簇数(码本大小),对多样的语音特征适应性差。
- 方法核心是什么:提出SED方法。首先利用自监督模型(HuBERT/WavLM)提取语音特征;然后将特征建模为图节点,边权基于余弦相似度;最后通过最小化二维结构熵(2D-SE) 对图进行自适应聚类,自动确定最优簇数,得到离散语音token。
- 与已有方法相比新在哪里:1)自动确定簇数,无需人工调参;2)显式建模声学相关性,通过图结构捕捉帧间关系;3)采用增量式2D-SE最小化算法和分块处理策略,以应对长语音序列的计算开销。
- 主要实验结果如何:在LibriSpeech ASR任务上,SED在多个子集上取得了低于K-means的WER。例如,在HuBERT+GPT2模型下,SED的WER(dev-clean: 2.83, dev-other: 5.71)优于K-means(3.05, 6.63)。聚类质量分析显示,SED的聚类纯度(ClsPur: 16.45%)远高于K-means(最高7.00%),音素纯度和PNMI也有提升。下表展示了关键WER对比结果:
| 架构 | 模型 | dev-clean | dev-other | test-clean | test-other |
|---|---|---|---|---|---|
| Decoder-Only, Discretized via K-means | HuBERT-Large + GPT2 | 3.05 | 6.63 | 3.11 | 7.12 |
| WavLM-Large + GPT2 | 3.41 | 7.26 | 3.59 | 7.21 | |
| Decoder-Only, Discretized via SE (ours) | HuBERT-Large + GPT2 | 2.83 | 5.71 | 2.94 | 6.02 |
| WavLM-Large + GPT2 | 3.10 | 6.52 | 3.21 | 6.58 |
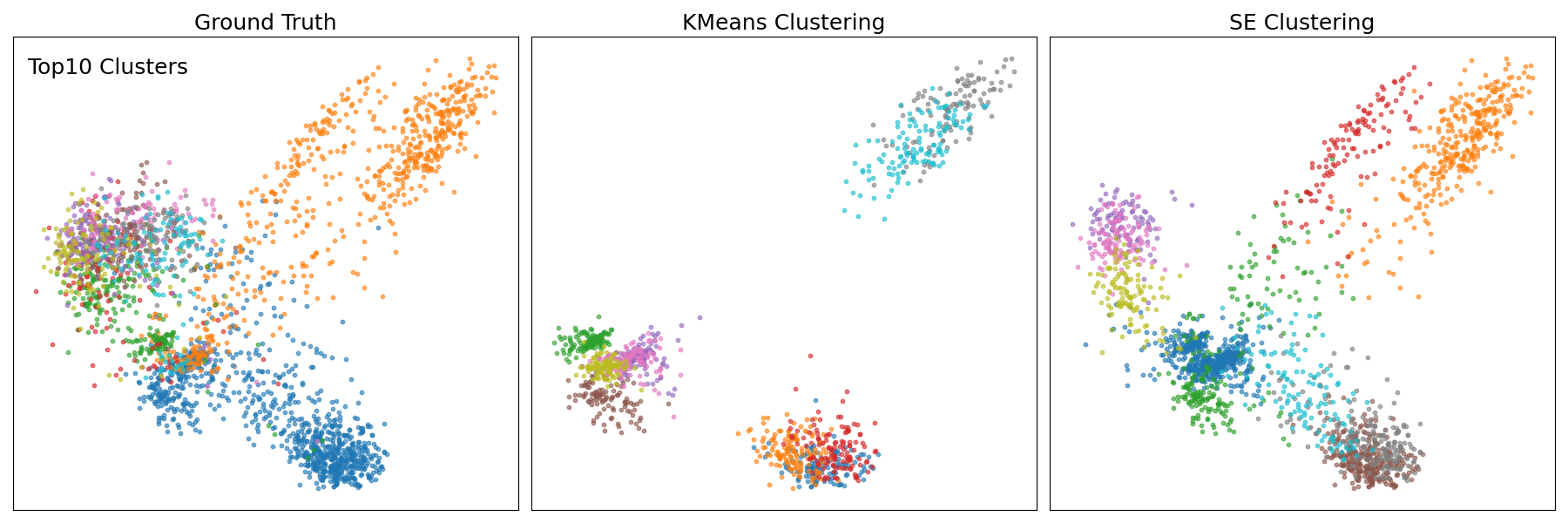 图2:展示了Ground Truth, K-means (K=2000), 和 SE聚类在top-10和top-20簇上的PCA可视化。论文指出,SE聚类比基于质心的K-means更能保持数据的有机结构,并在复杂簇中表现更优。
图2:展示了Ground Truth, K-means (K=2000), 和 SE聚类在top-10和top-20簇上的PCA可视化。论文指出,SE聚类比基于质心的K-means更能保持数据的有机结构,并在复杂簇中表现更优。
- 实际意义是什么:为语音大模型(SpeechLLM)提供了一种更自适应、更鲁棒的语音离散化方案,有望提升下游语音理解任务的性能,尤其是在噪声和复杂声学环境下。
- 主要局限性是什么:1)实验规模有限:仅在LibriSpeech一个基准上进行验证,且下游LLM参数量较小(最大0.5B),结论在更大模型和更多样化数据上的普适性未知;2)计算开销:虽然提出了增量方法,但图构建的O(L²)复杂度在处理超长语音或超大规模数据时仍是挑战;3)对比不充分:未与其他先进的离散化方法(如残差向量量化RVQ、基于Transformer的tokenizer)进行对比。
🏗️ 模型架构
SED的整体流程是一个两阶段管线:语音特征提取与离散化 -> 基于离散token的LLM语音识别。
- 语音特征提取:使用预训练的自监督语音模型(如HuBERT-large, WavLM-Large)作为特征提取器,输入原始语音波形,输出高维特征序列 H = {h1, h2, …, hT} ∈ R^{T×D}。
- 语音离散化(SED核心):
- 图构建:将特征序列H建模为加权无向图G=(V, E, W)。每个特征向量h_i对应一个节点v_i。边权w_ij = CosSim(h_i, h_j),即余弦相似度。通过设置一个自适应阈值(通过最小化一维结构熵确定)来筛选边,形成稀疏图。
- 自适应聚类(2D-SE最小化):这是SED的核心创新。将图的聚类问题转化为最小化二维结构熵(2D-SE)的问题。采用一种增量式博弈框架:每个节点动态决定是留在当前社区、离开还是合并,以最小化其对全局2D-SE的贡献(公式2、3)。这实现了无需预设K值的自适应聚类。
- 扩展性处理:为处理长语音,引入了下采样(采样因子s=0.001)和分块处理(块长度L=1000)策略。对每个语音块依次进行图构建和增量2D-SE最小化,并动态更新分区。
- 离散token-based ASR:将SED生成的离散token序列Z与文本Y一起输入到解码器-only的大语言模型(如GPT2-medium, Qwen2-0.5B)中。LLM的词表被扩展,增加了语音token的嵌入(随机初始化)。模型以自回归方式(next-token-prediction)训练,损失函数为交叉熵损失(公式5)。
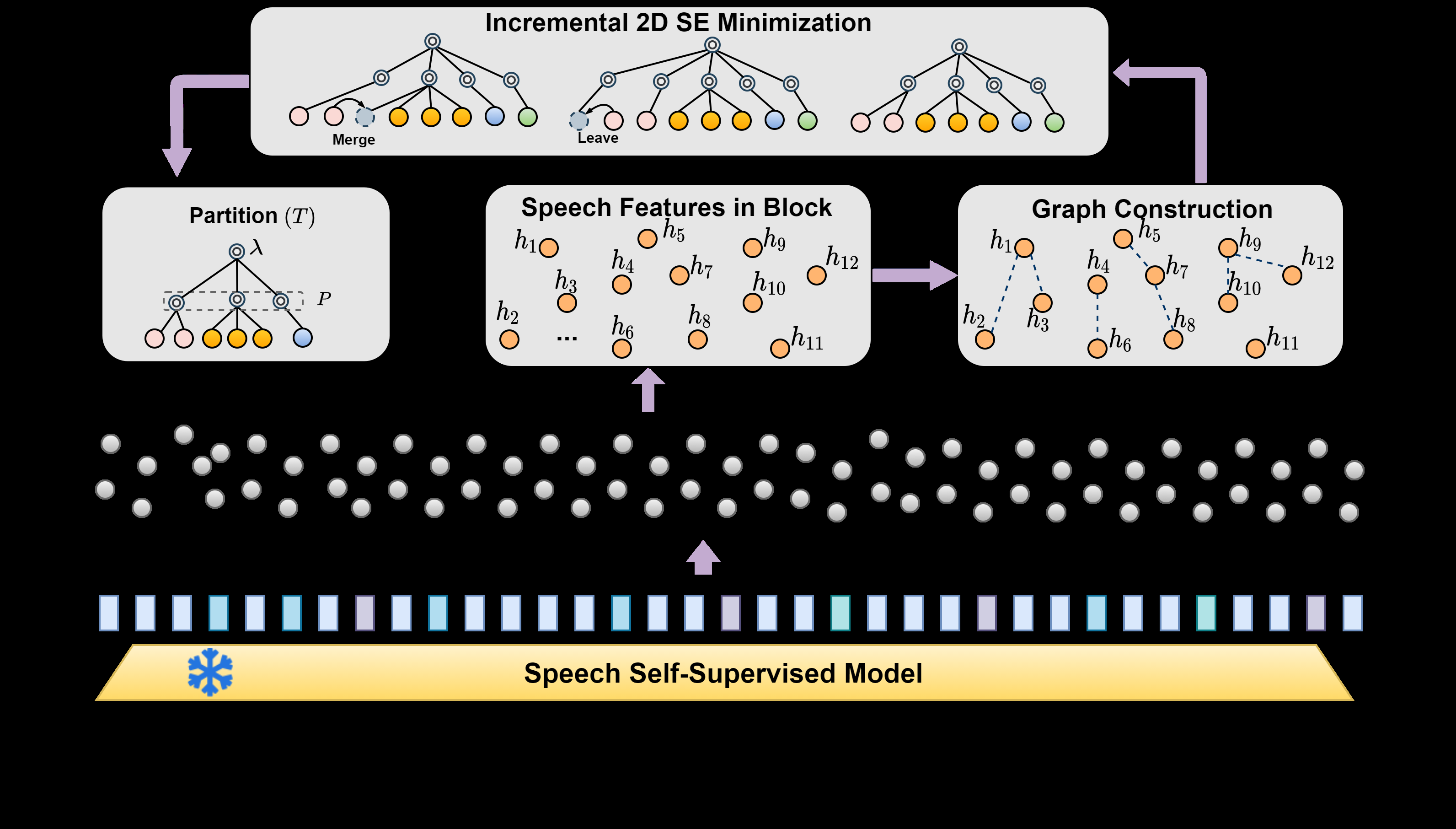 图1:展示了SED方法的框架和工作流程。上层是语音离散化流程:原始语音 -> SSL特征提取 -> 相似度图构建 -> 基于2D-SE最小化的自适应聚类 -> 离散语音token。下层是ASR流程:离散语音token与文本token拼接后输入解码器-only LLM进行自回归训练。
图1:展示了SED方法的框架和工作流程。上层是语音离散化流程:原始语音 -> SSL特征提取 -> 相似度图构建 -> 基于2D-SE最小化的自适应聚类 -> 离散语音token。下层是ASR流程:离散语音token与文本token拼接后输入解码器-only LLM进行自回归训练。
💡 核心创新点
- 基于结构熵的自适应聚类:是什么:利用2D结构熵作为优化目标进行图聚类。之前局限:K-means等方法需要预先指定固定的簇数K,对不同数据和场景适应性差。如何起作用:2D-SE的最小化过程会自然地形成大小、密度不一的社区,从而自动确定簇的数量和结构。收益:实现了语音特征的自适应离散化,无需人工调参,且能更好地保留数据的内在结构(如论文中聚类纯度的大幅提升)。
- 显式建模声学相关性的图表示:是什么:将语音特征序列构建成一个以相似度为权重的图。之前局限:K-means等方法隐式地假设簇为球形,且仅考虑点到质心的距离,忽略了特征间的成对关系。如何起作用:图结构明确编码了每帧语音与其他所有帧的声学亲和度,边权直接反映相关性。收益:聚类过程能更紧密地将声学相似的单元(如同一音素的不同变体)聚合在一起。
- 增量式2D-SE最小化与分块处理:是什么:为解决传统图聚类算法的高计算复杂度,引入基于博弈论的增量更新策略和分块处理机制。之前局限:传统的自底向上合并或层次化最小化方法在处理大规模密集图时计算开销巨大。如何起作用:将聚类过程建模为节点决策的博弈,每个节点基于局部信息(当前分区)做出最优动作(公式3),从而支持流式或分块处理。收益:显著提高了处理长语音序列的效率,使SED在实际ASR任务中可行。
🔬 细节详述
- 训练数据:数据集:LibriSpeech。规模:960小时训练集。预处理:未说明具体预处理步骤(如重采样、归一化)。数据增强:论文中未提及使用数据增强技术。
- 损失函数:使用标准的自回归交叉熵损失(公式5),用于训练LLM根据离散语音token序列生成文本序列。
- 训练策略:优化器:Adam。学习率:3×10⁻⁴。训练轮数:10 epochs。批大小:未说明。硬件:8块NVIDIA A40 GPU。调度策略:未说明是否使用学习率调度(如warmup)。
- 关键超参数:
- SED方法:下采样因子s=0.001;分块长度L=1000;用于聚类的采样帧数约177K。图构建的相似度阈值通过搜索最小化1D-SE自动确定。
- ASR模型:HuBERT-Large和WavLM-Large的隐藏维度均为1024。GPT2-medium:24层,隐藏维度1024,文本词表大小50257。Qwen2-0.5B:24层,隐藏维度896,文本词表大小151643。语音token嵌入随机初始化。
- 训练硬件:8×NVIDIA A40 GPUs。训练总时长未提及。
- 推理细节:解码策略:论文未明确说明ASR推理时使用的解码策略(如beam search大小、温度等)。流式设置:论文未提及任何流式处理相关的设置。
- 正则化或稳定训练技巧:论文未提及使用Dropout、权重衰减等正则化技巧。
📊 实验结果
论文在LibriSpeech数据集上进行了ASR性能评估和离散化质量分析。
- 主要ASR性能对比(WER%)
| 模型架构 | 模型名称 | dev-clean | dev-other | test-clean | test-other |
|---|---|---|---|---|---|
| Encoder-Decoder | Conformer | 3.10 | 8.91 | 3.29 | 8.81 |
| Whisper Large-v2 | 2.22 | 6.07 | 2.37 | 6.08 | |
| Decoder-Only (K-means) | HuBERT-Large + GPT2 | 3.05 | 6.63 | 3.11 | 7.12 |
| WavLM-Large + GPT2 | 3.41 | 7.26 | 3.59 | 7.21 | |
| HuBERT-Large + Qwen2-0.5B | 5.02 | 9.1 | 5.56 | 9.39 | |
| WavLM-Large + Qwen2-0.5B | 4.65 | 8.51 | 5.01 | 8.58 | |
| Decoder-Only (SED, ours) | HuBERT-Large + GPT2 | 2.83 | 5.71 | 2.94 | 6.02 |
| WavLM-Large + GPT2 | 3.10 | 6.52 | 3.21 | 6.58 | |
| HuBERT-Large + Qwen2-0.5B | 3.77 | 6.79 | 3.70 | 7.33 | |
| WavLM-Large + Qwen2-0.5B | 3.71 | 7.36 | 4.09 | 7.26 |
关键结论:在相同的LLM(GPT2)下,SED离散化相比K-means离散化,在所有测试集上均取得了更低的WER。特别是在具有挑战性的dev-other和test-other上,SED的改进更明显(如HuBERT+GPT2在test-other上从7.12降至6.02)。使用Qwen2-0.5B时,SED同样全面优于K-means基线。Whisper Large-v2因其庞大的参数和数据量取得了最佳性能,但SED在较小参数的离散token-based模型中展现出竞争力。
- 离散化质量对比(基于HuBERT特征)
| 方法 | 簇数 (#Clusters) | ClsPur (%) ↑ | PhnPur (%) ↑ | PNMI (%) ↑ | AvgWER (%) ↓ |
|---|---|---|---|---|---|
| K-means | K = 1000 | 7.00 / 6.46 | 70.95 / 67.17 | 73.00 / 67.76 | 10.89 |
| K = 2000 | 4.23 / 3.84 | 74.03 / 69.77 | 76.50 / 71.14 | 4.98 | |
| K = 3000 | 3.20 / 2.92 | 75.55 / 71.25 | 78.25 / 72.96 | 9.07 | |
| SED | P = 3178 | 16.45 / 15.72 | 77.32 / 74.57 | 75.64 / 77.60 | 4.36 |
注:斜杠前后分别对应dev-clean和dev-other集上的结果。 关键结论:SED自动生成了3178个簇。其聚类纯度(ClsPur)远高于任何K-means设置(超过两倍),说明SED产生的簇更紧凑、结构更一致。在音素纯度(PhnPur)和电话归一化互信息(PNMI)上,SED也普遍优于K-means,表明其token与音素对齐更好。SED取得了最低的平均WER(4.36%),且该WER是在无需预设簇数的情况下获得的。
- 可视化分析
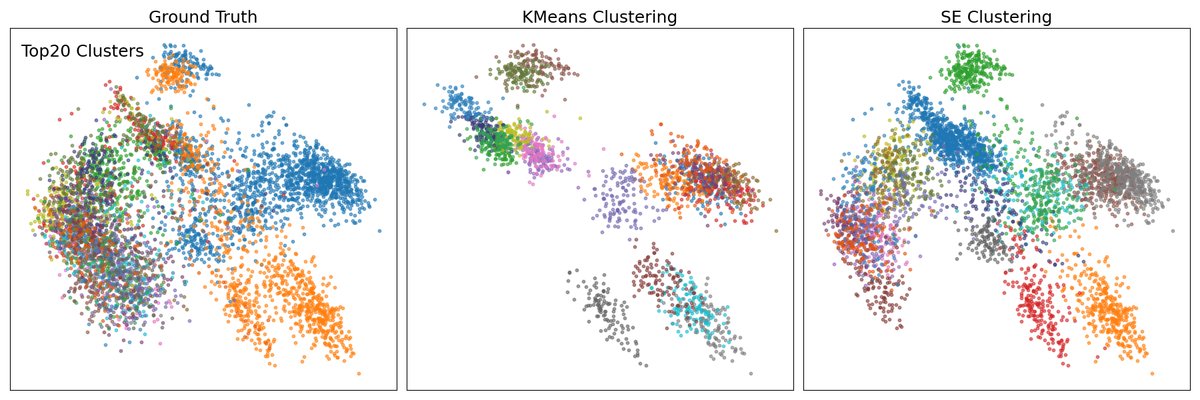 图2:该图对比了真实音素标签、K-means聚类和SED聚类在LibriSpeech dev-clean子集上的PCA可视化。论文分析指出:K-means形成紧凑但可能僵化的簇;SED则能捕捉更有机、灵活的数据结构,在处理复杂簇时保持更好的分离度,更有效地反映了底层数据分布。
图2:该图对比了真实音素标签、K-means聚类和SED聚类在LibriSpeech dev-clean子集上的PCA可视化。论文分析指出:K-means形成紧凑但可能僵化的簇;SED则能捕捉更有机、灵活的数据结构,在处理复杂簇时保持更好的分离度,更有效地反映了底层数据分布。
⚖️ 评分理由
- 学术质量:5.5/7。创新点清晰,理论动机(结构熵)新颖且适配问题。技术实现(图构建、增量优化、分块处理)合理。实验设计了清晰的对比(与不同K值的K-means)和多种评估指标(WER, ClsPur, PhnPur, PNMI),结果具有说服力。但实验的广度和深度有限:仅在单一数据集(LibriSpeech)���验证,下游LLM规模较小,缺少对SED方法自身关键参数(如下采样率、块大小)的消融实验,也未与更新颖的离散化方法(如RVQ、基于Transformer的tokenizer)对比,削弱了结论的普适性。
- 选题价值:1.5/2。语音离散化是当前语音LLM研究的热点和关键瓶颈之一,本文直接针对此问题,提出的自适应、结构感知的方法具有明确的应用价值和前沿性。对语音处理和LLM交叉领域的研究者有较好的参考意义。
- 开源与复现加成:-0.5/1。论文对方法和实验设置描述较为详细,但完全未提供代码、模型权重、预训练特征或具体的复现脚本。对于一篇在顶会上发表的方法论文,这极大地阻碍了社区的验证和后续研究,是显著的减分项。