📄 Scaling Spoken Language Models with Syllabic Speech Tokenization
#语音大模型 #语音理解 #分词技术 #自监督学习 #模型比较
✅ 7.0/10 | 前25% | #语音理解 | #分词技术 | #语音大模型 #自监督学习
学术质量 5.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Nicholas Lee (UC Berkeley)
- 通讯作者:未明确说明(论文中未指定)
- 作者列表:Nicholas Lee (UC Berkeley)、Cheol Jun Cho (UC Berkeley)、Alan W. Black (CMU)、Gopala K. Anumanchipalli (UC Berkeley)
💡 毒舌点评
亮点:这篇论文做了一件扎实且重要的事——系统性地证明了“把语音序列砍短”(音节分词)是训练更高效语音大模型的一条靠谱捷径,用5倍的计算节省换取了相当甚至更好的性能。短板:研究止步于“对比观察”,缺乏对“为何音节分词有效”的深层机制剖析(例如,这种离散化如何保留了关键的韵律或语义信息?),且未提供代码,使得“可复现”的承诺打了折扣。
🔗 开源详情
- 代码:论文中未提及代码链接或开源计划。
- 模型权重:未提及公开任何预训练模型或分词器权重。
- 数据集:使用的是公开数据集(LibriSpeech, LibriLight, LibriTTS, EXPRESSO),论文未提供新的数据集。
- Demo:未提及。
- 复现材料:论文详细描述了基于Slamkit框架的实验设置、模型架构、数据处理和超参数,为复现提供了路线图。
- 依赖的开源项目/模型:明确使用了Slamkit [1]、Sylber [8]、Hubert [5]、WavLM [6]、OPT [18]、Qwen2.5 [19]、SpeechBrain [17]、Whisper [23]、Llama-3.2 [24] 以及Conditional Flow-Matching [14]。
📌 核心摘要
- 问题:当前主流的语音语言模型(SLM)使用高帧率(25-75 Hz)的语音令牌,导致序列过长,使得基于Transformer的模型在自注意力机制下面临二次复杂度的计算瓶颈,严重限制了模型在长上下文数据上的扩展和推理速度。
- 方法核心:采用基于自监督学习模型“Sylber”生成的音节级语音分词(约4.27 Hz),替代传统的帧级分词(如Hubert,约50 Hz),将语音序列长度压缩约5倍。
- 创新点:首次系统性研究音节分词在语音语言建模中的扩展性。在固定计算预算下,对比了不同数据规模和词汇表大小的Sylber分词与Hubert分词SLM的性能。
- 主要实验结果:在多个口语理解基准测试(sBLIMP, sSC, tSC)和生成困惑度(GenPPL)上,Sylber模型用约1/5的训练数据(令牌量)即可匹配或超越使用全量数据的Hubert模型。具体而言,在完整数据集(LibriSpeech+LibriLight+STS)上,Sylber-20k模型在sBLIMP上得分60.57(Qwen-0.5B),高于Hubert的56.95;训练时间从8.5小时降至3小时(8xA100-80GB),FLOPs减少超过5倍。关键结果对比如下表:
| 模型(Qwen2.5-0.5B) | 训练数据集 | 令牌量 | sBLIMP ↑ | sSC ↑ | tSC ↑ | GenPPL ↓ |
|---|---|---|---|---|---|---|
| Hubert (km500) | 全量 | 6.04B | 56.95 | 57.30 | 79.64 | 85.90 |
| Sylber (km20k) | 全量 | 1.24B | 60.57 | 58.90 | 80.17 | 183.08 |
| Sylber (km5k) | 全量 | 1.24B | 60.54 | 57.67 | 79.58 | 168.81 |
- 实际意义:为构建高效、可扩展的长上下文语音语言模型指明了一条有前景的道路,通过更粗粒度、更可解释的语音表示(音节),大幅降低训练和推理成本。
- 主要局限性:研究局限于特定的Sylber分词方法和k-means聚类;未深入探讨不同分词策略(如基于语言学的分词)的影响;生成任务(GenPPL)的评分上,Sylber模型目前仍劣于Hubert模型,表明音节分词在语音生成建模上可能仍有挑战。
🏗️ 模型架构
论文未提出全新的端到端模型架构,而是研究将音节级分词作为输入表示对现有SLM架构的影响。其核心系统流程如下:
编码与分词阶段:
- 输入:原始语音波形。
- SSL编码器:使用预训练的Sylber模型(基于[8])。该模型本身是一个自监督语音模型,其设计能自然地从数据中分割并提取与音节相关的高级特征,输出分辨率为4.27 Hz的“音节级”表示。
- 离散化:对Sylber提取的嵌入向量应用k-means聚类,生成离散的音节令牌(论文测试了词汇表大小为5k, 10k, 20k, 40k)。对于基线Hubert分词器,使用了500个聚类的词汇表并进行了去重,最终采样率为25 Hz。
语言建模阶段:
- 模型:采用标准的Transformer解码器架构(如OPT-125M, Qwen2.5-0.5B),使用TWIST式初始化(利用预训练的文本LLM权重)。
- 输入:离散的语音令牌序列。
- 任务:自回归地预测下一个令牌。训练目标为标准的下一令牌预测交叉熵损失。
声码器解码阶段(用于评估GenPPL):
- 输入:语言模型生成的语音令牌序列。
- 时长与静音预测:训练了一个条件流匹配(CFM)模型,用于预测每个音节令牌的时长以及其前的静音时长(因为Sylber单元移除了音节间的静音)。
- 声学特征生成:将带有时间信息的令牌和说话人嵌入(来自WavLM-base-plus的L0层)输入另一个CFM模型,生成梅尔频谱图。
- 波形合成:使用SpeechBrain的现成声码器将梅尔频谱图转换为16kHz音频。
架构关键点:核心创新在于输入端,用更低频率、更高语义级别的令牌(Sylber)替代了传统高频率的帧级令牌(Hubert)。语言模型本身的主体架构并未改变。这种分词方式的差异是导致整个系统效率提升的根本原因。
💡 核心创新点
- 引入并系统评估音节级分词用于SLM:这是论文最核心的贡献。首次将Sylber这种产生粗粒度(~4 Hz)音节表示的SSL模型,系统性地应用于构建和评估语音语言模型,并与其原始的细粒度对应物(Hubert)进行全面对比。
- 验证了音节分词在SLM扩展性上的巨大潜力:通过严格的控制变量实验(相同基础模型、相同数据集、不同分词方式与数据规模),定量证明了音节分词可以用约1/5的计算资源(训练令牌数、FLOPs、时间)达到或超越传统帧级分词模型的性能。这为解决SLM的长序列计算瓶颈提供了实证支持。
- 探索了分词词汇表大小的影响:对Sylber分词器尝试了不同的k-means聚类数量(5k-40k),发现20k左右的词汇表大小在多个任务上表现相对稳定且优异,为实际应用提供了参数选择参考。
🔬 细节详述
- 训练数据:
- 数据集:使用三个数据集逐级混合,以研究数据规模效应:1) LibriSpeech(约1k小时),2) LibriSpeech + LibriLight(大规模无监督ASR数据),3) LibriSpeech + LibriLight + Spoken TinyStories (STS)(有声故事数据)。
- 规模:所有模型均训练1个epoch。总令牌数差异巨大:Hubert分词约6.04B个令牌,Sylber分词约1.24B个令牌(见Table 1)。
- 损失函数:标准的自回归语言建模损失(交叉熵损失)。
- 训练策略:遵循Slamkit框架[1]的配置。使用TWIST式初始化,即用预训练的文本LLM(OPT-125M, Qwen2.5-0.5B)的权重初始化语音语言模型。优化器、学习率等超参数沿用[1]的设置。
- 关键超参数:基础模型规模:125M和500M参数。Sylber分词器词汇表大小:5000, 10000, 20000, 40000。Hubert分词器词汇表大小:500(去重后有效采样率减半)。
- 训练硬件:8xA100-80GB NVIDIA DGX系统。训练时间对比:完整数据集下,Hubert模型需8.5小时,Sylber (km20k) 模型仅需3小时。
- 推理细节:评估GenPPL时,提供前3秒音频作为提示,生成后续令牌。为了公平比较,Hubert模型最大生成长度设为150,Sylber模型设为30(因Sylber令牌代表更长时间)。
- 正则化/技巧:论文未特别提及额外的正则化技巧,主要依赖框架和预训练初始化的稳定性。
📊 实验结果
论文主要评估了四个指标,并在两种基础模型上报告了结果。
主要基准与结果(Qwen2.5-0.5B模型,完整数据集 LibriSpeech+LibriLight+STS):
| 分词方式 (词汇表大小) | 令牌总量 | sBLIMP ↑ | sSC ↑ | tSC ↑ | GenPPL ↓ |
|---|---|---|---|---|---|
| Hubert (km500) | 6.04B | 56.95 | 57.30 | 79.64 | 85.90 |
| Sylber (km5k) | 1.24B | 60.54 | 57.67 | 79.58 | 168.81 |
| Sylber (km10k) | 1.24B | 60.80 | 57.51 | 78.41 | 177.69 |
| Sylber (km20k) | 1.24B | 60.57 | 58.90 | 80.17 | 183.08 |
| Sylber (km40k) | 1.24B | 60.83 | 57.30 | 78.46 | 187.17 |
关键发现:
- 效率与性能:Sylber分词器以约1/5的训练数据量(1.24B vs 6.04B),在sBLIMP(语法理解)、sSC和tSC(故事理解) 任务上持续优于Hubert分词器,性能增益显著(例如sBLIMP提升约3.6个点)。这直接支持了音节分词在语言理解任务上的优越性。
- 生成质量(GenPPL):在生成困惑度上,Hubert分词器(85.90)显著优于所有Sylber分词器(最低为168.81)。这表明更细粒度的帧级表示可能保留了更多生成连续语音所需的声学细节,而粗粒度的音节分词在生成保真度上存在挑战。
- 数据扩展性:如Fig. 2所示,随着训练数据增加,Sylber模型的性能提升曲线(尤其在sBLIMP和GenPPL上)通常比Hubert模型更陡峭,暗示其可能具有更好的数据利用效率。
- 词汇表大小影响:词汇表大小(5k-40k)对最终性能的影响相对有限,但20k在多数任务上表现均衡。
实验结果图表:
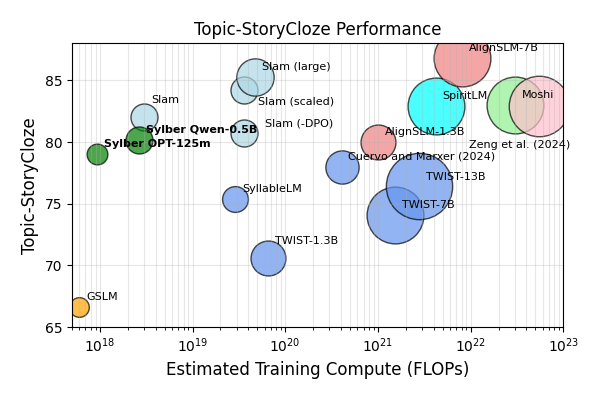 (图注:此图改编自[1],展示了不同SLM在Topic Story-Cloze (tSC) 任务上性能随训练计算量变化的曲线。深绿色线条代表本文的Sylber模型,显示其在较低计算量下达到了具有竞争力的性能。)
(图注:此图改编自[1],展示了不同SLM在Topic Story-Cloze (tSC) 任务上性能随训练计算量变化的曲线。深绿色线条代表本文的Sylber模型,显示其在较低计算量下达到了具有竞争力的性能。)
(图注:此图展示了Hubert和不同词汇表大小的Sylber分词器在四个评估指标(sBLIMP, sSC, tSC, GenPPL)和两种模型尺寸(Qwen2.5-0.5B, OPT-125M)下的性能随训练令牌数增加的变化趋势。清晰显示了Sylber模型在理解任务上的优势以及在生成任务上的劣势。)
⚖️ 评分理由
- 学术质量:5.0/7:论文进行了一项设计良好、控制变量的系统性实验研究。其价值在于为语音大模型的分词策略选择提供了清晰的实证证据和量化比较。创新性属于方法组合与深度评估,而非提出全新的模型范式。实验充分,结论可信。
- 选题价值:1.5/2:选题直击语音大模型发展中的计算效率瓶颈,音节分词是一种符合直觉且高效的解决方案,对推动实用化、长上下文语音模型有明确意义。
- 开源与复现加成:0.5/1:论文提供了详尽的实验设置说明和结果,具备良好的可复现性基础。但因未明确承诺开源代码与模型权重,复现仍需研究者自行搭建环境与实现细节,故给予部分加分。