📄 Scaling Multi-Talker ASR with Speaker-Agnostic Activity Streams
#语音识别 #说话人分离 #预训练 #端到端
🔥 8.5/10 | 前25% | #语音识别 | #预训练 | #说话人分离 #端到端
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.8 | 置信度 高
👥 作者与机构
- 第一作者:Xiluo He (约翰斯·霍普金斯大学计算机科学系)
- 通讯作者:Xiluo He (xhe69@jh.edu)
- 作者列表:Xiluo He (约翰斯·霍普金斯大学计算机科学系)、Alexander Polok (布尔诺理工大学信息技术学院)、Jes´us Villalba (约翰斯·霍普金斯大学人类语言技术卓越中心)、Thomas Thebaud (约翰斯·霍普金斯大学人类语言技术卓越中心)、Matthew Maciejewski (约翰斯·霍普金斯大学人类语言技术卓越中心)
💡 毒舌点评
亮点:工程设计巧妙,通过将多说话人活动“压缩”为两个与说话人无关的流,将推理成本从与说话人数成正比降至固定为两次,且性能损失可控,这是非常实用且优雅的解决方案。短板:方法建立在“同时只有两个说话人重叠”这一较强假设上,论文中对超过两人重叠的场景虽有讨论,但应对策略有限,且未与另一主流降本方案(如SOT)进行直接对比,说服力稍有欠缺。
🔗 开源详情
- 代码:论文中提供了代码仓库链接:https://github.com/xiluohe/heat-conditioned-whisper
- 模型权重:论文中未提及是否公开训练好的模型权重。
- 数据集:使用了公开数据集AMI、ICSI、LibriMix。论文未提供数据集本身(因其公开),但说明了数据获取途径和使用方式(如SDM条件)。
- Demo:论文中未提及在线演示。
- 复现��料:提供了训练细节(优化器、学习率、调度策略等)、模型架构描述(基于Whisper-large-v3-turbo)、评估指标定义。这些构成了良好的复现基础。
- 论文中引用的开源项目/模型:
- Whisper:作为基础预训练模型。
- DiCoW:作为直接比较和集成的基础框架。
- Diarizen:在实验中用于获取自动说话人活动掩码。
📌 核心摘要
- 要解决的问题:现有基于说话人活动条件的多说话人ASR系统(如DiCoW)需要为目标说话人逐个运行识别模型,导致推理成本与说话人数量成正比,严重限制了其在实际场景中的应用效率。
- 方法核心:提出一种将说话人特定的活动输出转化为两个说话人无关(Speaker-Agnostic)流的框架。核心是利用HEAT思想,并设计新的启发式分配策略(特别是“说话人连续性”启发式),将多个说话人的语音片段分配到两个固定的流中,使得每个流在时间上不重叠。
- 与已有方法相比新在哪里:不同于传统方法需要为每个说话人运行一次模型,或序列化输出训练(SOT)对标签格式敏感,该方法通过合并活动流,将模型推理次数固定为两次,且对活动标签格式更鲁棒。同时,相比于基于分离的方法,它避免了分离引入的伪影。
- 主要实验结果:在AMI和ICSI会议数据集上,使用“说话人连续性”启发式,基于Oracle活动的tcORC-WER分别为19.71和24.94,接近直接使用说话人活动的性能(17.18和23.84)。在使用自动日志系统(Diarizen)输出时,该方法在AMI和ICSI上分别实现了123%和159%的相对推理速度(RTFx)提升,同时WER仅有小幅上升。在SparseLibriMix数据集上的实验表明,当重叠说话人数超过两人时,性能差距会拉大。
- 实际意义:该方法能大幅降低多说话人ASR系统的部署和计算成本,使其在实时会议转录、在线协作等场景中更具可行性和经济性。
- 主要局限性:性能依赖于“同时重叠说话人不超过两人”的假设,在三人及以上重叠场景下性能会下降。目前输出为说话人无关的转录流,未能同时解决说话人归属问题。
🏗️ 模型架构
本文方法的核心在于对现有活动条件ASR模型(DiCoW)的输入进行改造,其自身并不提出全新的ASR模型架构。
- 整体流程:输入为多说话人音频,外部日志系统提供每个说话人的活动掩码 \(y_{spk} \in [0, 1]^{T \times K}\)。系统首先使用HEAT启发式将这些 \(K\) 个说话人活动合并为两个说话人无关的流活动 \(y_{HEAT} \in [0, 1]^{T \times 2}\)。然后,针对每个流,使用其活动掩码作为条件,运行一个目标说话人ASR模型(DiCoW)进行识别。最终输出两个流的转录文本。
- 核心组件:
- HEAT 流合并模块:此模块是本文的关键创新点。它接收各说话人的活动片段,按照设计的启发式(First-available, Alternating, Recency-continuity, Speaker-continuity)将片段分配到流1或流2。分配的目标是使每个流内部的时间上不重叠,同时保持负载均衡和对话连续性。
- 活动条件 ASR 模型(DiCoW):这是被改造的基座模型。DiCoW本身基于Whisper-large-v3-turbo,在其编码器每层之前引入帧级日志相关变换(FDDT)。FDDT根据活动掩码对隐藏状态进行仿射变换的加权组合。在原DiCoW中,活动掩码是针对每个目标说话人的四类事件(静音、仅目标、仅非目标、重叠)。在本文的HEAT版本中,目标被替换为“流”,活动掩码同样是基于合并后的流活动生成的四类(S, T, N, O)掩码。
- 数据流与设计选择:
- 解耦关键:传统方法为每个说话人运行一次编码器-解码器。本文方法将输入从“\(K\) 个说话人活动”转换为“2个流活动”,使得ASR模型只需运行两次,从而将推理成本与说话人数解耦。
- 启发式设计动机:朴素的First-available启发式会导致两个流的内容高度相似(模型坍塌)。新启发式旨在平衡两个关键点:(1) 负载均衡,防止单一流主导模型训练;(2) 连续性,确保同一段连贯对话的语句不被拆散到不同流中,以便语言模型利用上下文。Speaker-continuity启发式通过优先保持说话人连续性来同时优化这两点。
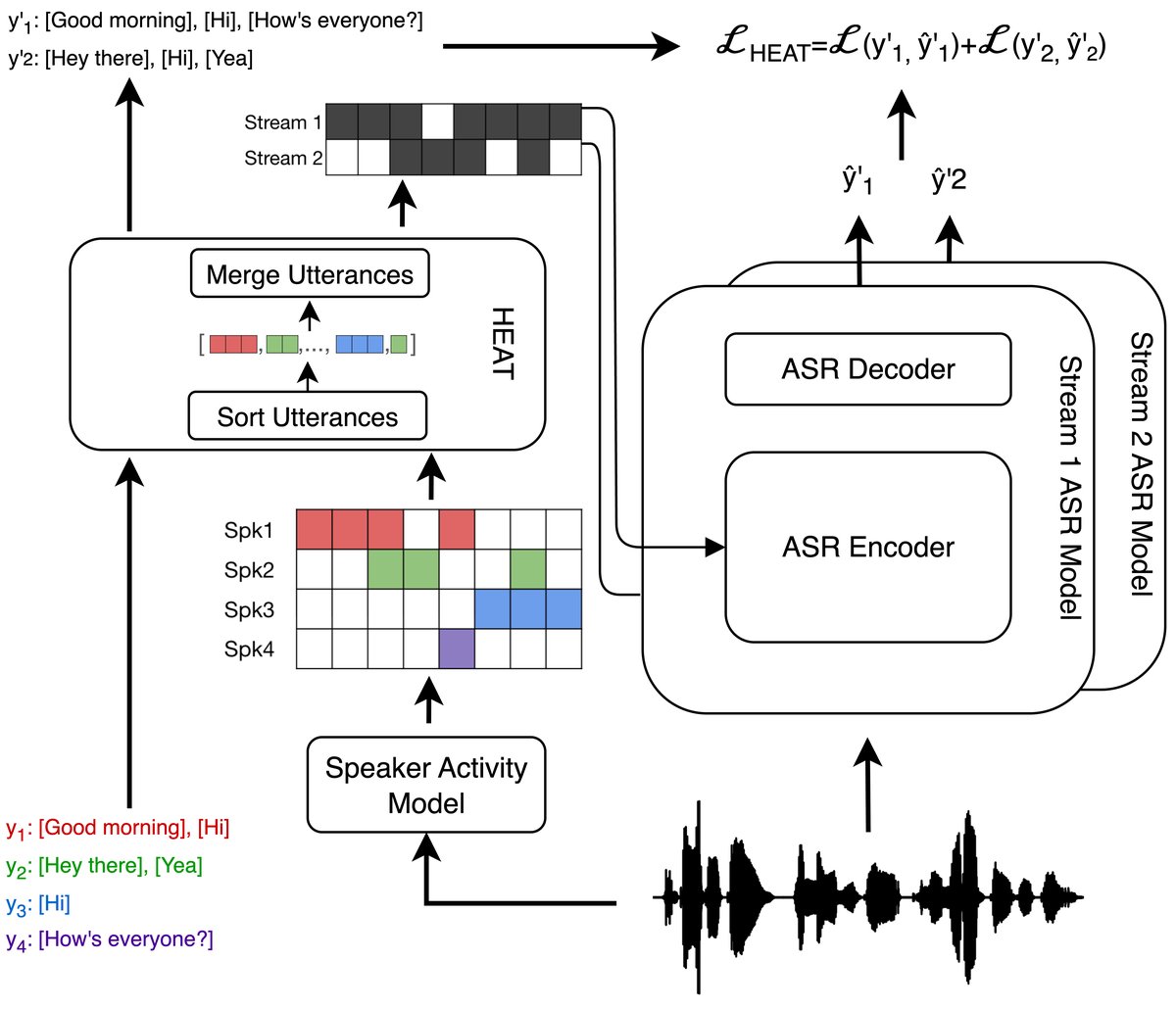 图1说明:此图直观展示了HEAT的工作流程。原始音频包含多个说话人(不同颜色),其活动信号被合并为两个说话人无关的流(Stream 1, Stream 2),每个流内部没有重叠。然后,ASR模型(DiCoW)仅对这两个流分别进行处理,生成最终转录。这清晰地展示了如何将推理成本固定为两次。
图1说明:此图直观展示了HEAT的工作流程。原始音频包含多个说话人(不同颜色),其活动信号被合并为两个说话人无关的流(Stream 1, Stream 2),每个流内部没有重叠。然后,ASR模型(DiCoW)仅对这两个流分别进行处理,生成最终转录。这清晰地展示了如何将推理成本固定为两次。
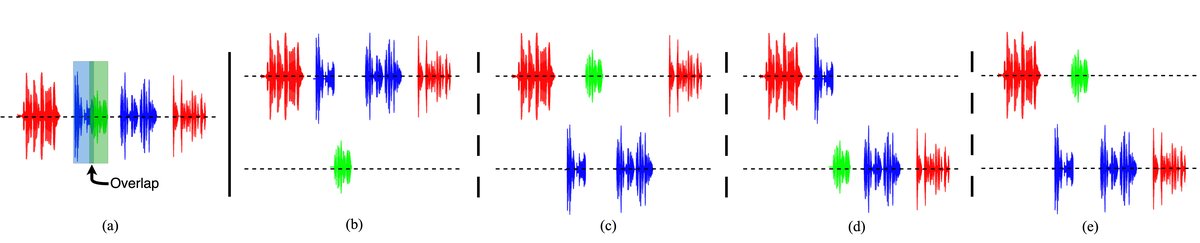 图2说明:此图展示了五句话(三个说话人)在不同HEAT启发式下被分配到两个流(S1, S2)的结果。图中清晰地对比了First-available(可能导致负载不均或不连续)、Alternating(严格交替但不考虑说话人)、Recency-continuity(优先分配给最近使用的流)和Speaker-continuity(优先保持同一说话人)的区别。Speaker-continuity在保持对话连贯性(将说话人A和B的连续话轮放在同一流)和平衡性上表现最好。
图2说明:此图展示了五句话(三个说话人)在不同HEAT启发式下被分配到两个流(S1, S2)的结果。图中清晰地对比了First-available(可能导致负载不均或不连续)、Alternating(严格交替但不考虑说话人)、Recency-continuity(优先分配给最近使用的流)和Speaker-continuity(优先保持同一说话人)的区别。Speaker-continuity在保持对话连贯性(将说话人A和B的连续话轮放在同一流)和平衡性上表现最好。
💡 核心创新点
- 推理成本与说话人数解耦:将多说话人活动压缩为固定两个流,使ASR模型推理次数恒为2次。这是对HEAT思想在活动条件ASR中的创造性应用,直接解决了实际部署中的效率瓶颈。
- 面向对话场景的新型活动流分配启发式:提出了Alternating、Recency-continuity,特别是Speaker-continuity启发式。这些启发式超越了简单的按时间排序,旨在同时维护流的负载均衡与对话/说话人连续性,有效防止了模型坍塌,并提升了识别性能。
- 兼容现有活动条件框架:提出的方法是一个“即插即用”的前端处理模块,能无缝集成到现有的目标说话人ASR系统(如DiCoW)中,无需修改其内部架构,降低了应用门槛。
- 避免分离伪影:与基于语音分离的2流系统相比,本方法直接操作活动掩码,避免了信号分离过程中可能产生的扭曲或伪影,保证了输入给ASR模型的音频质量。
🔬 细节详述
- 训练数据:
- 主要在AMI语料库(约100小时,4-5人会议,SDM条件)上训练。
- 在ICSI语料库(约72小时,3-10人会议,SDM条件)上进行评估。
- 同时使用SparseLibriMix数据集进行可控的重叠比例分析。
- 数据预处理:未详细说明。论文提及使用外部日志系统输出作为活动掩码输入。
- 损失函数:未明确提及新引入的损失。论文指出模型基于DiCoW,DiCoW使用CTC损失(权重0.3)和解码器损失(隐含为交叉熵,带时间戳令牌)进行训练。本文的训练应沿用此设置。
- 训练策略:
- 优化器:AdamW
- 基础学习率:\(2 \times 10^{-6}\)(主体模型),\(2 \times 10^{-4}\)(FDDT引入的参数)
- 权重衰减:\(1 \times 10^{-6}\)
- 学习率调度:线性衰减,2000步预热(warm-up)
- 批大小:自适应批大小(具体未说明)
- 训练轮数:10 epochs
- 关键超参数:
- 骨干模型:Whisper-large-v3-turbo
- 附加组件:一个CTC头,两个卷积层(下采样因子为2)
- CTC损失权重:0.3
- 训练硬件:未说明。
- 推理细节:
- 解码策略:默认使用贪婪解码。报告的部分结果使用束搜索(beam size=5,长度惩罚0.1,CTC权重0.2)。
- 评估指标:tcORC-WER(时间约束最优参考组合词错误率),RTFx(逆实时因子)。
- 正则化/稳定训练技巧:通过设计良好的启发式(如Speaker-continuity)来避免模型坍塌,这本身就是一种重要的训练稳定性技巧。
📊 实验结果
主要对比实验(Oracle活动输入)
| 方法 | AMI-SDM tcORC-WER (↓) | ICSI-SDM tcORC-WER (↓) |
|---|---|---|
| Diarization (直接使用说话人活动) | 17.18 | 23.84 |
| HEAT (First-available) | 32.41 | 40.45 |
| HEAT (Alternating) | 22.20 | 25.47 |
| HEAT (Recency-continuity) | 20.64 | 24.42 |
| HEAT (Speaker-continuity) | 19.71 | 24.94 |
- 结论:朴素的First-available导致性能严重下降(模型坍塌)。Speaker-continuity启发式性能最佳,在AMI上仅比直接使用说话人活动差2.53个点,在ICSI上差1.1个点,验证了方法的有效性。
推理效率对比(使用自动日志系统Diarizen输出)
| 活动掩码来源 | AMI-SDM WER (↓) | AMI-SDM RTFx (↑) | ICSI-SDM WER (↓) | ICSI-SDM RTFx (↑) |
|---|---|---|---|---|
| Speaker (逐个说话人) | 18.34 | 2.05 | 25.55 | 1.50 |
| HEAT (Speaker-continuity) | 18.99 | 4.57 | 26.24 | 3.89 |
- 结论:在使用实际日志系统输出时,HEAT方法的WER仅比说话人条件基线高约0.6-0.7个点,但推理速度(RTFx)提升了123%(AMI)和159%(ICSI),证明了其巨大的效率优势。
重叠说话人数影响分析(SparseLibriMix数据集)
| 重叠说话人数 | 重叠比例 | Speaker基线 WER (↓) | HEAT WER (↓) | 性能差距 |
|---|---|---|---|---|
| 2人 | 0% | 6.56 | 6.34 | HEAT略优 |
| 2人 | 20% | 10.04 | 11.83 | HEAT差1.79 |
| 3人 | 0% | 7.23 | 6.93 | HEAT略优 |
| 3人 | 20% | 30.29 | 33.10 | HEAT差2.81 |
- 结论:在两人重叠且比例不高时,HEAT性能与基线相当甚至略优。随着重叠比例增加,性能差距逐渐扩大。对于三人重叠,即使在低重叠比例下,HEAT的性能下降也比两人重叠时更明显,验证了方法对高重叠人数的局限性。
图2说明:此图虽主要用于说明启发式原理,但也间接展示了不同分配��略可能导致的语音流在时间上的分布差异,这与最终的识别性能(表1)直接相关。
⚖️ 评分理由
- 学术质量:6.0/7:创新点明确且实用(解耦推理成本),技术路线正确(在DiCoW框架上集成HEAT)。实验设计全面,包括不同启发式消融、不同输入源(Oracle vs. 自动)、不同数据集及受控重叠比例分析,结果清晰可信。扣分点在于对核心假设(≤2人重叠)的讨论深度不足,且未与另一重要降本路径(SOT)进行直接比较。
- 选题价值:1.5/2:问题精准(多说话人ASR推理成本瓶颈),解决方案直接有效,具有很高的工程落地价值和市场潜力,与语音技术应用者高度相关。
- 开源与复现加成:0.8/1:提供了明确的代码仓库链接,训练关键超参数、数据集信息、评估指标均已公开,复现门槛较低。扣分点在于未提供训练好的模型权重或完整配置文件。