📄 Sampling-Rate-Agnostic Speech Super-Resolution Based on Gaussian Process Dynamical Systems with Deep Kernel Learning
#语音增强 #高斯过程 #深度核学习 #鲁棒性
✅ 6.5/10 | 前25% | #语音增强 | #高斯过程 | #深度核学习 #鲁棒性
学术质量 4.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Aditya Arie Nugraha(RIKEN Center for Advanced Intelligence Project (AIP),日本)
- 通讯作者:未说明
- 作者列表:Aditya Arie Nugraha(RIKEN AIP,日本)、Diego Di Carlo(RIKEN AIP,日本)、Yoshiaki Bando(RIKEN AIP,日本)、Mathieu Fontaine(LTCI, T’el’ecom Paris, Institut Polytechnique de Paris,法国;RIKEN AIP,日本)、Kazuyoshi Yoshii(京都大学工学研究科,日本;RIKEN AIP,日本)
💡 毒舌点评
亮点:论文将语音超分辨率问题巧妙地重新定义为基于连续时间随机过程的统计逆问题,提出的GPDS-SR框架在理论上非常优雅,并首次实现了真正的采样率无关性(可输出如13931Hz、19391Hz等非标准采样率)和对缺失样本的鲁棒性。短板:然而,这种理论上的优雅并未完全转化为感知质量上的优势,在核心指标ViSQOL和LSD-LF上,GPDS-SR明显落后于NU-Wave 2和UDM+等扩散/变分模型,且频谱图显示其生成结果存在明显伪影,这削弱了其“更具数学严谨性”方法的实际竞争力。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及。
- 数据集:使用了公开的CSTR VCTK corpus v0.92,但论文中未提供获取方式(通常可公开获取)。
- Demo:提供了一个在线演示页面(https://aanugraha.github.io/demo/gpds-sr)。
- 复现材料:提供了极其详尽的模型配置、训练细节、超参数和数据处理流程描述,足以支持复现。
- 论文中引用的开源项目:提到了用于重采样的
librosa、SoX库,以及作为基线的NU-Wave 2和UDM+的GitHub仓库链接。
📌 核心摘要
- 要解决什么问题:传统的基于深度神经网络的语音超分辨率(SR)方法通常受限于固定的输入或输出采样率,无法处理任意、不规则的采样情况。本文旨在提出一种采样率无关的语音SR方法。
- 方法核心是什么:提出了一种基于高斯过程动力学系统(GPDS)和深度核学习(DKL)的方法(GPDS-SR)。该方法将语音信号视为连续时间域上的随机过程,假设观测到的低采样率语音是某个连续语音信号在离散时间点的采样。通过GPDS建立生成模型,并利用变分推理和神经网络参数化的核函数来近似连续潜在信号的后验分布,从而可以在任意更细的时间网格上预测高采样率语音。
- 与已有方法相比新在哪里:与大多将SR视为离散信号到离散信号映射的DNN方法不同,本文从概率建模角度,将SR视为基于连续随机过程的曲线拟合问题。GPDS-SR能支持任意输入采样率和任意更高的输出采样率(包括非整数倍率),并能处理缺失或不规则样本,这是大多数现有方法不具备的。
- 主要实验结果如何:在VCTK数据集上,以4kHz输入为例,在16kHz标准目标下,GPDS-SR的LSD-HF(高频估计)与扩散模型基线UDM+接近,但ViSQOL(感知质量)和LSD-LF(低频保真)明显较差(例如,4kHz输入到16kHz输出:GPDS-SR ViSQOL ≈ 3.34,UDM+ ≈ 3.8;LSD-LF:GPDS-SR ≈ 0.41,UDM+ ≈ 0.1)。对于19391Hz等非标准输出率,GPDS-SR能生成高于输入奈奎斯特频率的谐波,而基线模型则无法做到。对缺失样本的鲁棒性测试显示,即使随机丢弃10%的样本,高频估计指标(LSD-HF)仅轻微变化。
- 实际意义是什么:该方法为语音处理提供了一种统一的连续时间建模框架,在处理采样率不匹配、数据缺失或不规则采样的实际场景(如老旧录音、网络丢包)中具有潜在应用价值。
- 主要局限性是什么:模型在低频保真度和整体感知质量上显著逊于当前基于扩散模型的SOTA方法,频谱图中存在伪影。其计算复杂度较高,需要分段处理以降低矩阵运算开销。
🏗️ 模型架构
模型整体是一个基于变分自编码器(VAE)思想的生成与推断框架,核心是利用GPDS和DKL在连续时间域进行建模。
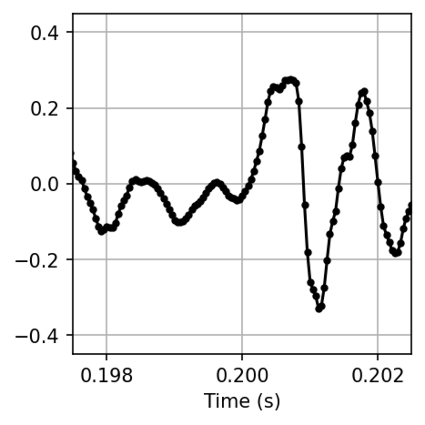 图1:GPDS-SR核心概念图。 展示了模型如何从低采样率输入(4kHz)通过GPDS-SR生成任意高采样率的输出(如13931Hz, 16kHz, 19391Hz),阴影区域表示95%置信区间,体现了模型的采样率无关性和概率预测特性。
图1:GPDS-SR核心概念图。 展示了模型如何从低采样率输入(4kHz)通过GPDS-SR生成任意高采样率的输出(如13931Hz, 16kHz, 19391Hz),阴影区域表示95%置信区间,体现了模型的采样率无关性和概率预测特性。
- 生成模型(Generation Model)
- 输入/输出:输入是连续时间点的潜在信号
z,输出是对应时间点的语音信号s。 - 核心组件:假设
z和s分别服从高斯过程(GP)。具体地:- 潜在过程
p(z|τ):由一个静态的谱混合(SM)核K_z(τ,τ)定义。 - 语音过程
p(s|z,τ):由一个非静态的广义谱混合(GSM)核K_s(ζ,ζ)定义,其中ζ={z,τ}。GSM核的参数(权重、长度尺度、均值)通过一个神经网络解码器(Decoder) 从输入{z, τ}映射得到。
- 潜在过程
- 关键设计:使用神经网络(DKL)来参数化GP的核函数,使得模型能学习复杂的数据依赖的协方差结构,而不仅仅是静态核。
- 推断模型(Inference Model)
- 输入/输出:输入是观测到的低采样率语音
s和时间点τ,输出是潜在信号z的近似后验分布q(z|s,τ)。 - 核心组件:后验分布也建模为一个GP,其均值函数和对角协方差矩阵由一个神经网络编码器(Encoder) 从
{s, τ}映射得到。 - 作用:编码器学习将观测信号映射到一个潜在空间,为后续的GP回归提供基础。
- 超分辨率作为GP回归(Super-Resolution as GP Regression)
- 流程:这是预测阶段的核心。
- 推断潜在信号:从编码器得到的后验分布
q(z|s,τ)中采样或使用均值z_ϕ。 - 预测潜在过程:利用潜在过程GP的预测公式(Eq. 8-11),根据
z_ϕ和新旧时间点{τ, ẽτ},计算出在新时间点ẽτ上的潜在信号ẽz的预测分布。 - 预测语音过程:将预测出的
{ẽz, ẽτ}和观测到的{z_ϕ, τ}一同输入解码器,得到语音过程GP的预测参数(均值、核参数),然后利用语音过程GP的预测公式(Eq. 12-15),计算出高采样率语音信号ẽs在ẽτ上的预测分布。最终输出通常取该分布的均值μ_{ẽs}。
- 推断潜在信号:从编码器得到的后验分布
- 网络架构细节
- 编码器和解码器均采用时间感知的全连接(FC)网络,由多个处理块堆叠而成。
- 每个块包含特征处理器
F(·)、加权平均层G(·)和激活层H(·)。设计上考虑了时间上下文(通过Δ(b)和随机采样邻域索引J_t),并使用了全局层归一化和PReLU激活。 - 训练和推理时,对信号进行分段处理以降低计算复杂度,并使用重叠相加(OLA)法合成最终结果。
💡 核心创新点
- 连续时间域建模:首次将语音超分辨率问题完全建模为对连续时间随机信号的推断问题,而非传统的离散样本到离散样本的映射。这从根本上实现了采样率无关性。
- GPDS作为先验:使用高斯过程动力学系统(GPDS)作为语音信号的生成模型先验,能自然地表征语音信号复杂的非线性时序动态,并为处理缺失/不规则样本提供了概率框架。
- 深度核学习端到端训练:将深度神经网络嵌入GP的核函数(DKL),使得模型的表达能力大大增强,能够从数据中学习复杂的非平稳协方差结构,同时整个模型可以通过变分推理进行端到端优化。
🔬 细节详述
- 训练数据:使用CSTR VCTK corpus v0.92。训练集为100位说话人的40936条语句,但为控制计算成本,GPDS-SR仅随机使用其中8000条进行训练。输入信号通过降采样和切比雪夫I型低通滤波器从48kHz目标信号(16kHz)生成。训练时输入采样率从[2, 16]kHz中随机选取。
- 损失函数:基于证据下界(ELB)最大化,具体损失函数
L包括四部分(Eq. 18):L_{ẽs}:高采样率信号的重构损失(负对数似然)。L_{ω̃}:解码器GSM核权重参数的频率感知L1正则化(Laplace先验),用于抑制高频伪影。L_{s}:低采样率信号的重构损失。L_{KL}:变分后验与先验的KL散度。 其中β是周期性退火系数,用于防止后验坍塌。
- 训练策略:
- 优化器:AdamW,权重衰减1e-2。
- 学习率:初始1e-3,每10个epoch减半。
- 批大小:8。
- 训练轮数:25个epoch。
- 梯度裁剪:基于范数,阈值10。
- KL退火:周期性,周期为5。
- 分段处理:目标信号分段长度
ẽT’=800(50ms @16kHz),输入信号分段长度T’随采样率变化(如8kHz时T’=400)。
- 关键超参数:
- SM和GSM核的混合分量数
Q=8。 - 频率范围:
f_min=20Hz,f_max=8kHz。 - 噪声方差
ϵ=1e-7。 - GSM核L1正则化参数
α=0.5,κ=1e-6。 - 编码器/解码器中每个块的随机采样邻域数
K(b)=5,上下文半宽Δ(b)=5·2^{b-2} ms。 - 网络深度:B=9个块。
- SM和GSM核的混合分量数
- 训练硬件:未说明。
- 推理细节:测试时,从编码器获取潜在信号均值
z_ϕ ← μ_z,并从预测潜在分布中取均值ẽz ← μ_{ẽz}(而非随机采样)。同样使用分段和OLA法进行最终预测。 - 正则化技巧:包括频率感知L1正则化、KL周期退火、对角加载确保协方差矩阵正定(特征值最小1e-7)。
📊 实验结果
主要对比实验(目标16kHz,输入不同采样率):
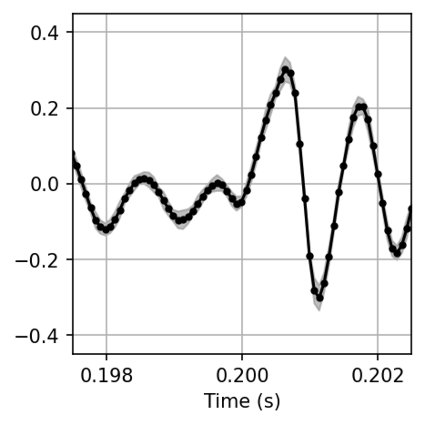 图2(上):目标输出为16kHz时,不同输入采样率下的性能指标(2kHz,4kHz,8kHz)。 可见,在LSD-HF(高频估计)上,GPDS-SR与扩散模型基线UDM+性能接近,但在ViSQOL(感知质量)和LSD-LF(低频保真)上明显落后。
图2(上):目标输出为16kHz时,不同输入采样率下的性能指标(2kHz,4kHz,8kHz)。 可见,在LSD-HF(高频估计)上,GPDS-SR与扩散模型基线UDM+性能接近,但在ViSQOL(感知质量)和LSD-LF(低频保真)上明显落后。
主要对比实验(输入4kHz,目标不同输出采样率):
图2(下):输入为4kHz时,不同输出采样率(13931Hz,16000Hz,19391Hz)下的性能指标。 结果表明,GPDS-SR对任意输出采样率均有效,且在非标准输出率(13931Hz,19391Hz)上具有优势,而基线模型在输出非标准率时性能依赖于后续重采样。
鲁棒性实验(目标16kHz,输入4kHz,含随机丢弃样本):
| 丢弃率 | ViSQOL (↑) | LSD-LF (↓) | LSD-HF (↓) |
|---|---|---|---|
| 0% | 3.340 ± 0.003 | 0.408 ± 0.001 | 2.041 ± 0.002 |
| 5% | 3.194 ± 0.003 | 0.615 ± 0.001 | 2.028 ± 0.002 |
| 10% | 3.039 ± 0.004 | 0.731 ± 0.002 | 2.021 ± 0.002 |
| 表1:GPDS-SR在不同样本丢弃率下的性能。 数据表明,随着输入样本缺失增多,低频保真度(LSD-LF)下降明显,但高频估计能力(LSD-HF)保持相对稳定。 |
频谱图示例(4kHz -> 19391Hz):
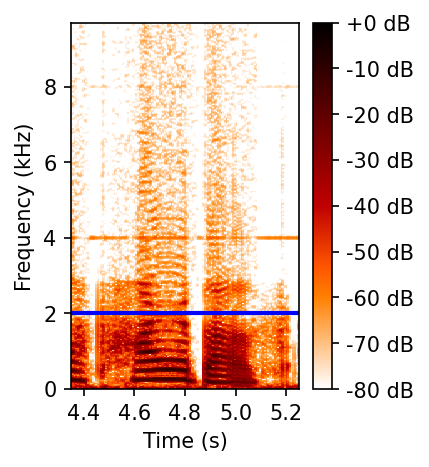 图3:从4kHz到19391Hz的频谱图对比。 (a)参考信号;(b) NU-Wave 2输出在约8kHz以上出现噪声;(c) UDM+输出在8kHz以上无内容;(d) GPDS-SR输出能生成超过输入奈奎斯特频率(蓝线)的高频谐波,但在约4kHz处有伪影,且存在频谱复制。
图3:从4kHz到19391Hz的频谱图对比。 (a)参考信号;(b) NU-Wave 2输出在约8kHz以上出现噪声;(c) UDM+输出在8kHz以上无内容;(d) GPDS-SR输出能生成超过输入奈奎斯特频率(蓝线)的高频谐波,但在约4kHz处有伪影,且存在频谱复制。
⚖️ 评分理由
- 学术质量:4.5/7:论文提出了一个理论上新颖且严谨的概率框架来解决语音SR问题,在建模层面有显著创新。实验设计全面,涵盖了不同输入/输出率、缺失数据等场景,代码和模型细节公开充分。然而,该方法在核心的感知质量指标上明显落后于现有的扩散模型方法,且生成结果存在可观察的伪影,这表明其生成模型部分(GPDS)在捕���真实语音分布上可能存在不足,削弱了整体学术贡献的说服力。
- 选题价值:1.5/2:研究采样率无关的语音处理是一个有价值且具有挑战性的方向,尤其对于处理现实世界中不规则采样或数据缺失的音频信号具有实际意义。该工作为此提供了一种基础性的概率解决方案,具有启发性。但由于性能未达顶尖,其在通用语音增强/超分领域的应用前景目前受限。
- 开源与复现加成:0.5/1:论文提供了极其详细的模型架构、所有超参数、训练策略和正则化技巧的说明,并提供了在线demo,这极大地降低了复现门槛。扣分点在于未承诺开源代码和预训练模型权重,这使得完全复现仍需大量工作。