📄 SAGA-SR: Semantically and Acoustically Guided Audio Super-Resolution
#音频增强 #扩散模型 #流匹配 #生成模型
✅ 7.5/10 | 前25% | #音频增强 | #扩散模型 | #流匹配 #生成模型
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 中
👥 作者与机构
- 第一作者:Jaekwon Im(KAIST 文化技术研究生院)
- 通讯作者:未说明
- 作者列表:Jaekwon Im(KAIST 文化技术研究生院)、Juhan Nam(KAIST 文化技术研究生院)
💡 毒舌点评
这篇论文的亮点在于巧妙地将文本语义信息和频谱滚降这一物理特征结合,作为扩散模型的双重引导,有效解决了通用音频超分辨率中“对齐差”和“高频能量不稳定”这两大痛点。不过,论文在训练硬件、具体模型参数量等复现关键信息上完全缺失,对于想复现其成果的同行来说,这无异于只给了地图却没标比例尺,实用性打了折扣。
🔗 开源详情
- 代码:论文中提供了代码和示例的链接:
http://jakeoneijk.github.io/saga-sr-project。 - 模型权重:论文中未明确提及是否公开预训练模型权重。
- 数据集:论文使用的训练数据集(FreeSound, MedleyDB等)均为公开数据集,但论文未说明具体如何组合和预处理。测试集(VCTK, FMA-small, ESC50)也是公开数据集。
- Demo:项目主页链接可能包含声音示例(论文中提及“Sound examples…are available online”),但论文内未直接给出在线演示链接。
- 复现材料:论文提供了详细的训练超参数(学习率、batch size、优化器、步数、调度器参数等)、数据预处理方法(滤波器类型、截止频率范围)和推理设置(采样步数、引导尺度)。但未提供模型结构细节(如DiT具体配置)、训练硬件信息、检查点文件或完整的训练配置代码。
- 论文中引用的开源项目:依赖预训练的VAE(来自
[12]Stable Audio Open)、Qwen2-Audio(用于音频字幕生成)、T5-base(文本编码器)、librosa(频谱滚降计算)以及参考了AudioSR、FlashSR等工作的代码实现(用于对比)。
📌 核心摘要
- 问题:现有的通用音频超分辨率方法(如AudioSR、FlashSR)在重建高频时,常出现语义不匹配(如生成不自然的齿音)和高频能量分布不一致的问题。
- 方法核心:提出SAGA-SR模型,基于DiT(Diffusion Transformer)架构和流匹配(Flow Matching)目标进行训练。其核心创新在于引入了双重条件引导:(1)由音频生成的文本描述提供的语义嵌入;(2)由输入和目标音频的频谱滚降频率提供的声学嵌入。
- 新颖之处:首次在音频超分辨率任务中系统性地引入了基于文本的语义引导,解决了现有方法生成音频语义失真的问题;同时,引入了频谱滚降这一可量化的声学特征,为模型提供了明确的高频能量分布指导,并允许用户在推理时通过单一标量控制输出音频的高频能量。
- 主要结果:在语音、音乐、音效三个领域的测试中,SAGA-SR在所有客观指标(LSD、FD)和主观评估分数上均优于AudioSR和FlashSR。例如,在主观评估中,SAGA-SR在音效任务上得分3.88,显著高于FlashSR的3.34。消融实验证实了文本嵌入和频谱滚降嵌入的有效性。
- 实际意义:SAGA-SR提供了一个能够处理任意输入采样率(4-32 kHz)并统一上采样到44.1 kHz的通用音频增强工具,其可控的高频能量生成特性使其在音频修复、后期制作等场景中具有应用潜力。
- 主要局限性:模型对于包含多个重叠声源的复杂音频的处理能力有限;后处理中的低频替换操作可能引入频段间的不自然连接。
🏗️ 模型架构
SAGA-SR的整体架构(图1)是一个以条件DiT为核心的生成模型,包含以下流程:
- 输入处理:输入低分辨率音频($x_l$)和目标高分辨率音频($x_h$)。它们首先通过预训练的VAE编码器被压缩成潜在表示 $z_l$ 和 $z_h$。
- 条件提取:
- 文本条件:利用Qwen2-Audio模型从音频(训练时用$x_h$,推理时用$x_l$)生成文本描述$c$,再通过预训练的T5-base编码器提取文本嵌入。
- 声学条件:计算$x_h$和$x_l$的频谱滚降频率($f_h$, $f_l$),归一化到[0,1)后,通过可学习的傅里叶嵌入转换为嵌入向量。
- 核心生成模型(DiT):
- 模型采用DiT架构,以流匹配为目标进行训练。训练时,向量场$u_θ$学习将噪声$z_0$和数据$z_1$之间的线性插值路径$z_t$的速度场$v_t$回归到正确的值。
- 条件注入:
- $z_l$直接与$z_t$在通道维度拼接,作为DiT的输入。
- 文本嵌入$c$和频谱滚降嵌入在序列维度拼接后,通过交叉注意力机制注入DiT。
- 目标频谱滚降嵌入$f_h$与输入频谱滚降嵌入$f_l$在通道维度拼接、投影后,与时间步$t$的正弦嵌入相加,然后前置(prepend) 到DiT输入序列的最前面,为模型提供全局的高/低频能量参考。
- 为了灵活控制条件强度,使用了Classifier-Free Guidance (CFG)。在公式(4)中,$s_a$和$s_t$分别是声学条件和文本条件的引导尺度。
- 输出生成:推理时,从噪声$z_0$出发,通过ODE求解器(如Euler方法)在DiT的引导下迭代去噪,得到估计的高分辨率潜在表示$\hat{z}_h$。
- 后处理:$\hat{z}_h$通过预训练的VAE解码器恢复成音频信号,最后进行低频替换,将输入音频$x_l$的低频部分(截止频率以下)直接复制到输出中,以确保低频信息的绝对一致。
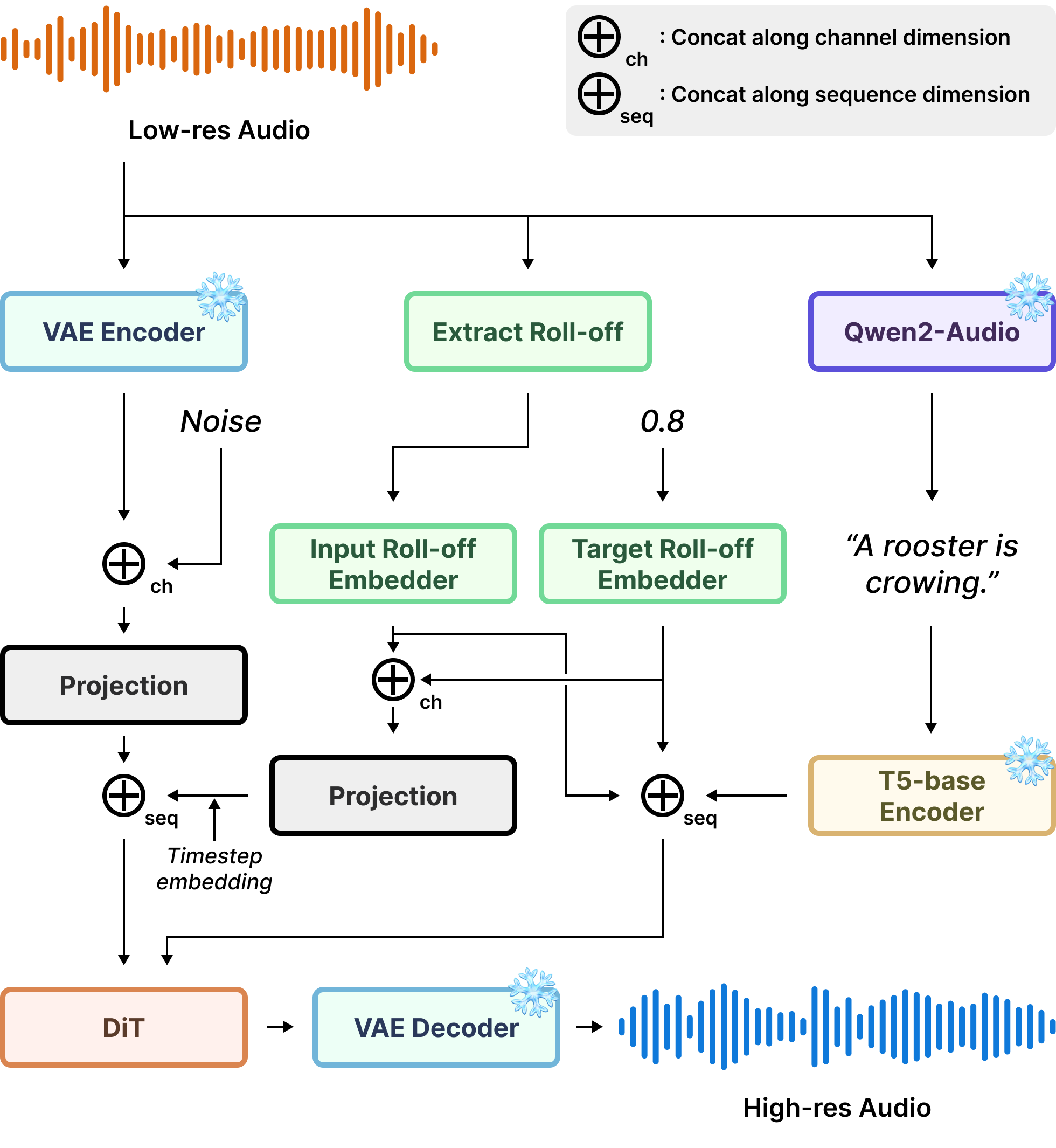 图1展示了SAGA-SR的完整流程:音频对通过VAE编码,文本和频谱滚降特征被提取并注入到DiT中,最终由DiT估计高分辨率潜在表示,再经VAE解码和低频替换后得到输出。
图1展示了SAGA-SR的完整流程:音频对通过VAE编码,文本和频谱滚降特征被提取并注入到DiT中,最终由DiT估计高分辨率潜在表示,再经VAE解码和低频替换后得到输出。
💡 核心创新点
- 基于文本的语义引导:首次在通用音频超分辨率任务中,利用音频-语言模型生成的文本描述作为条件。这弥补了现有方法(如AudioSR)仅基于音频数据训练导致语义对齐不足的缺陷,使模型能生成更符合原始语义的高频内容(如正确的齿音、泛音结构)。
- 基于频谱滚降的声学引导与可控性:引入频谱滚降频率这一明确的声学特征作为条件。它不仅告诉模型输入音频的截止频率,更重要的是指定了目标输出的高频能量分布。这解决了现有方法在不同音频类型上高频重建不一致的问题,并提供了用户可控性——用户可以通过调节一个标量值来控制生成音频的“明亮度”。
- 通用性与鲁棒性:通过结合上述两种引导,SAGA-SR能够处理从4 kHz到32 kHz任意输入采样率的音频,并将其统一上采样到44.1 kHz,在语音、音乐、音效等广泛域上均实现了稳定的高质量重建。
🔬 细节详述
- 训练数据:使用FreeSound, MedleyDB, MUSDB18-HQ, MoisesDB, OpenSLR4语音数据集,总时长约3800小时。所有音频重采样至44.1 kHz,并随机切分为5.94秒片段。通过随机选择滤波器类型(Chebyshev, Butterworth等)、阶数(2-10)和截止频率(2k-16kHz)对高分辨率音频进行低通滤波,模拟低-高分辨率对。
- 损失函数:采用条件流匹配(Conditional Flow Matching)目标。如公式(3)所示,损失为预测速度场$u_θ$与真实速度$v_t = z_1 - z_0$之间的L2距离。
- 训练策略:使用AdamW优化器(β1=0.9, β2=0.999),学习率$1.0 × 10^{-5}$,批次大小256。使用InverseLR调度器(inverse gamma $10^6$, power 0.5, warmup factor 0.99)。共训练26,000步。
- 关键超参数:DiT具体层数、隐藏维度等参数未在论文中明确说明。Classifier-Free Guidance中,声学条件引导尺度$s_a=1.4$,文本条件引导尺度$s_t=1.2$。推理时使用Euler采样器,100步,采用线性-二次$t$调度。
- 训练硬件:未说明。
- 推理细节:推理时从$z_0 \sim N(0,1)$开始。文本嵌入从输入低分辨率音频生成。用户可通过调节目标归一化滚降频率($f_h$)来控制输出高频能量。
- 正则化技巧:在训练时,对条件$z_l$和文本嵌入$c$均应用10%的Dropout率,以支持Classifier-Free Guidance的训练。
📊 实验结果
- 客观评估结果 (Table 1) 论文在语音(VCTK)、音乐(FMA-small)、音效(ESC50)三个测试集上,对4kHz和8kHz截止频率两种情况进行了评估。使用Log-Spectral Distance (LSD,越低越好)和Fréchet Distance (FD,越低越好)指标。
| 任务 | 方法 | 4kHz LSD↓ | 8kHz LSD↓ | 4kHz FD↓ | 8kHz FD↓ |
|---|---|---|---|---|---|
| 语音 | Unprocessed | 2.89 | 2.49 | - | - |
| VAE (recon) | 0.87 | 0.81 | - | - | |
| AudioSR [1] | 1.46 | 1.26 | - | - | |
| FlashSR [4] | 1.47 | 1.15 | - | - | |
| SAGA-SR | 1.28 | 1.07 | - | - | |
| w/o text | 1.32 | 1.11 | - | - | |
| w/o roll-off | 1.57 | 1.43 | - | - | |
| 音乐 | Unprocessed | 3.68 | 2.68 | 138.09 | 106.46 |
| VAE (recon) | 1.13 | 1.06 | 18.92 | 17.30 | |
| AudioSR [1] | 2.09 | 1.88 | 32.52 | 25.93 | |
| FlashSR [4] | 1.76 | 1.69 | 37.79 | 32.08 | |
| SAGA-SR | 1.64 | 1.45 | 23.87 | 20.44 | |
| w/o text | 1.63 | 1.45 | 30.14 | 25.34 | |
| w/o roll-off | 2.16 | 1.78 | 35.99 | 23.5 | |
| 音效 | Unprocessed | 3.30 | 2.39 | 110.25 | 64.08 |
| VAE (recon) | 1.13 | 1.08 | 13.47 | 11.53 | |
| AudioSR [1] | 1.85 | 1.68 | 39.69 | 28.54 | |
| FlashSR [4] | 1.81 | 1.89 | 41.32 | 36.13 | |
| SAGA-SR | 1.65 | 1.43 | 26.32 | 21.86 | |
| w/o text | 1.60 | 1.43 | 29.00 | 23.94 | |
| w/o roll-off | 2.19 | 1.75 | 33.07 | 22.4 |
结论:SAGA-SR在所有任务、所有指标上均取得最优。消融实验表明:去除频谱滚降嵌入(w/o roll-off)导致性能显著下降,尤其在处理不同截止频率时;去除文本嵌入(w/o text)对语音任务影响较大,但对音乐/音效的LSD影响较小,不过会显著降低FD(感知质量)。
- 主观评估结果 (Table 2) 25名参与者对4kHz截止频率的输出进行1-5分评分(5分为最佳)。
| 方法 | 语音 | 音乐 | 音效 |
|---|---|---|---|
| Unprocessed | 1.81 | 1.66 | 1.77 |
| Ground Truth | 4.23 | 3.93 | 4.18 |
| AudioSR [1] | 3.26 | 2.94 | 3.03 |
| FlashSR [4] | 3.45 | 3.46 | 3.34 |
| SAGA-SR | 3.70 | 3.65 | 3.88 |
结论:SAGA-SR在所有类别上均获得最高主观评分,尤其在音效上领先优势明显(3.88 vs 3.34)。
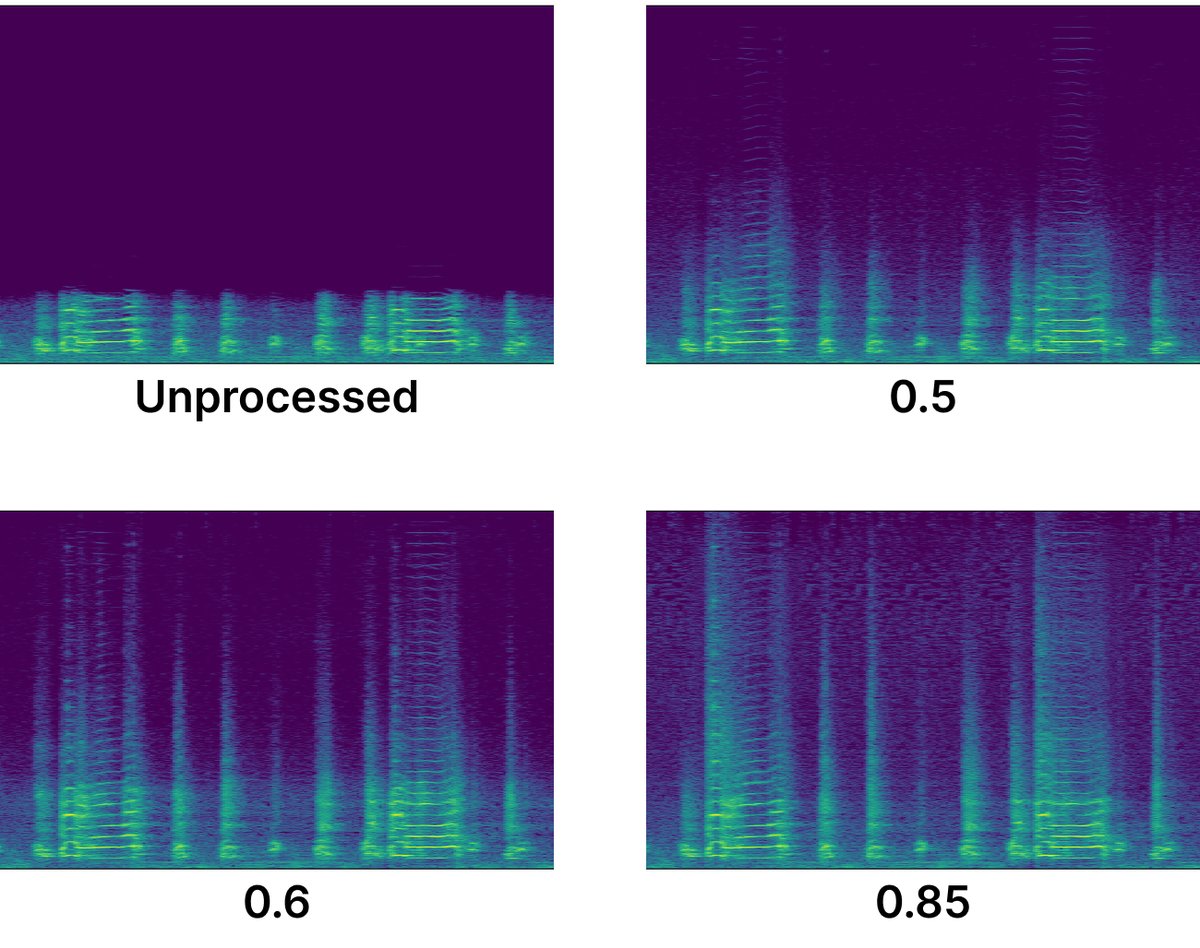 图2显示,AudioSR和FlashSR的输出在高频区域(10kHz以上)能量分布不一致,且AudioSR有明显齿音伪影。SAGA-SR的频谱图与真实值(Ground Truth)更接近,高频结构更清晰、一致。
图2显示,AudioSR和FlashSR的输出在高频区域(10kHz以上)能量分布不一致,且AudioSR有明显齿音伪影。SAGA-SR的频谱图与真实值(Ground Truth)更接近,高频结构更清晰、一致。
 图3展示了通过调节目标归一化滚降频率标量,可以控制生成音频的高频能量强度,从较暗(左)到较亮(右)。
图3展示了通过调节目标归一化滚降频率标量,可以控制生成音频的高频能量强度,从较暗(左)到较亮(右)。
⚖️ 评分理由
- 学术质量:6.0/7。论文针对通用音频SR的明确痛点提出了创新性的双重条件引导方案,技术路线(DiT+Flow Matching+CFG)是当前主流且有效的组合。实验设计合理,在多个数据集和指标上进行了充分对比与消融,结论可信。扣分点在于模型的具体架构参数(如DiT规模)未公开,训练硬件未知,部分细节缺失,影响了完全复现的可行性。
- 选题价值:1.5/2。音频超分辨率是音频处理领域的基础且重要任务,尤其在修复历史录音、改善网络通话质量、增强生成式模型输出等方面有广泛的实际应用。论文追求“通用性”符合现实需求,提出的可控性也增加了实用价值。
- 开源与复现加成:0.5/1。论文提供了项目主页和代码链接(
http://jakeoneijk.github.io/saga-sr-project),这是积极的一面。但未提及模型权重是否开源,也未提供训练数据的具体下载方式或详细的复现脚本,降低了直接复现的便利性。