📄 SAASDNet: An EEG-Based Streaming Auditory Attention Switch Decoding Network for Self-Initiated Attention Switching in Mixed Speech
#脑机接口 #端到端 #流式处理 #数据集 #预训练
🔥 8.0/10 | 前25% | #脑机接口 | #端到端 | #流式处理 #数据集
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.3 | 置信度 高
👥 作者与机构
- 第一作者:Yuting Ding(南方科技大学电子与电气工程系)
- 通讯作者:Fei Chen(南方科技大学电子与电气工程系)
- 作者列表:Yuting Ding(南方科技大学电子与电气工程系),Siyu Yu(南方科技大学电子与电气工程系),Ximin Chen(南方科技大学电子与电气工程系),Xuefei Wang(南方科技大学电子与电气工程系),Yueting Ban(南方科技大学电子与电气工程系),Fei Chen(南方科技大学电子与电气工程系)
💡 毒舌点评
亮点:论文抓住了一个非常实际且尚未被充分建模的痛点——在无提示线索、无空间分离的混合语音中进行自发起的注意力切换解码,其构建的MS-AASD数据集和提出的流式解码框架(SAASDNet)为这个更具生态效度的场景提供了首个系统性基准。短板:SAASDNet的架构(多尺度卷积+Transformer+门控循环)在脑电信号建模中已属常见组合,其核心创新点“稳定性感知门控”依赖的“置信度”和“波动性”指标设计相对启发式,缺乏更深入的理论或神经机制支撑,模型整体的“新颖性”相较于其“工程整合性”稍弱。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开的模型权重。
- 数据集:公开。MS-AASD数据集可通过Zenodo链接(https://doi.org/10.5281/zenodo.17149387)获取。
- Demo:未提及在线演示。
- 复现材料:论文提供了详尽的训练细节(三阶段协议、优化器、学习率、批大小、TBPTT参数、损失函数公式等)和评估设置,为复现提供了良好的文本基础。
- 论文中引用的开源项目:
- wav2vec 2.0:用于语音特征提取。
- AISHELL:作为语音材料来源。
- E-Prime 3.0:用于实验刺激控制。
- AdamW:优化器。
📌 核心摘要
- 问题:现有的EEG听觉注意力切换解码(AASD)范式大多依赖外部提示线索(如蜂鸣声)和空间化音频,无法捕捉自然状态下由听者自发发起的注意力切换,且可能引入非听觉伪迹。
- 方法核心:提出一个新的混合语音AASD数据集(MS-AASD)和一个端到端的流式解码网络SAASDNet。SAASDNet包含三个核心组件:多频带多分辨率聚合EEG编码器(MMAEnc)、简单的语音编码器,以及流式稳定性感知门控(StreamSAG)单元。
- 创新点:1)新范式与新数据集:首次构建支持自发起切换、无空间线索的混合语音EEG数据集MS-AASD。2)针对性架构设计:MMAEnc通过多尺度时域卷积和自适应频带聚合来应对EEG的非平稳性;StreamSAG单元利用说话人分类的置信度和短期波动性作为稳定性分数,自适应地加权历史信息,避免显式的切换点检测。
- 主要实验结果:在MS-AASD数据集上,使用wav2vec 2.0特征和1秒决策窗口时,SAASDNet的流式解码准确率达到83.6%,非流式准确率为79.9%。相比多种先进基线(DARNet, ListenNet等)和其自身的非流式版本(AASDNet)均有显著提升。消融实验证明了StreamSAG单元(特别是其中的置信度和波动性成分)、多分辨率卷积(GMR)和自适应频带聚合(MBA)的贡献。关键对比数据如下:
| 模型 | 决策窗口长度 | |||||
|---|---|---|---|---|---|---|
| 0.5 s | 1 s | 2 s | ||||
| Mel | W2V | Mel | W2V | Mel | W2V | |
| DARNet | 70.3 | 74.1 | 71.5 | 76.8 | 72.0 | 77.9 |
| ListenNet | 71.4 | 74.0 | 71.8 | 76.4 | 72.7 | 76.9 |
| ResCNN | 71.8 | 76.2 | 72.1 | 77.2 | 73.7 | 78.0 |
| TransCNN | 72.3 | 77.5 | 73.8 | 78.4 | 74.4 | 79.7 |
| AASDNet (ours) | 72.9 | 78.4 | 74.3 | 79.9 | 76.7 | 81.1 |
| SAASDNet (ours) | 75.8 | 81.5 | 78.2 | 83.6 | 80.1 | 84.5 |
- 实际意义:这项工作为开发更自然、更鲁棒的下一代神经调控助听器提供了关键的数据基础和算法参考,展示了在复杂真实场景中利用EEG解码动态注意力的可行性。
- 主要局限性:数据集规模较小(13名被试),且均为母语中文,模型的泛化能力有待验证。模型虽然有效,但其组件的神经科学可解释性可以进一步深化。
🏗️ 模型架构
SAASDNet是一个为流式EEG听觉注意力切换解码设计的端到端网络,整体架构如图1所示。其核心流程如下:
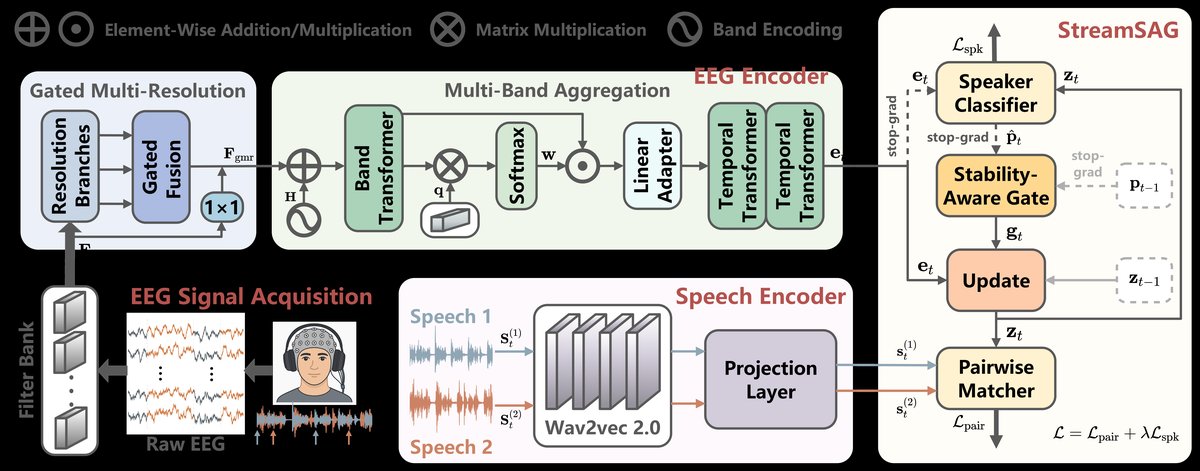
- 输入:在每个决策窗口t,输入是多频带EEG数据
E_t ∈ R^{N×C×T}(N个子频带,C个通道,T个时间步)和两个语音流S_t^{(1)},S_t^{(2)}的语音特征。 - EEG编码器 (MMAEnc):
- 多频带多分辨率聚合 (MMA):首先,对每个子频带分别通过门控多分辨率 (GMR) 模块。该模块使用三个不同核大小和扩张率((3,1), (7,2), (15,4))的深度可分离时域卷积分支来捕捉不同时间尺度的动态,然后通过一个可学习的门控机制(由Softmax产生)融合这些分支,并加入残差连接。
- 自适应频带聚合 (MBA):将所有频带的GMR特征堆叠后,加入可学习的频带编码,并通过一个频带维度上的Transformer来建模频带间的依赖关系。然后,利用一个可学习的查询向量
q为每个频带和时间步计算注意力权重,对频带进行加权融合。最后,通过一个时间维度上的Transformer捕捉长程时间依赖,输出EEG表征e_t ∈ R^{D×T}。
- 语音编码器:两个语音流分别通过预训练的wav2vec 2.0模型(提取第14层特征)和一个1x1卷积投影层,得到语音表征
s_t^{(1)},s_t^{(2)}。 - 流式稳定性感知门控 (StreamSAG) 单元:这是处理序列依赖的关键。它维护一个历史状态
z_{t-1}和对应的说话人概率p_{t-1}。- 首先,用当前EEG表征
e_t通过说话人分类头得到当前说话人概率p_t。 - 然后,计算两个稳定性指标:置信度
c_t(当前说话人概率的最大值)和波动性v_t(当前概率向量p_t与历史p_{t-1}的L1距离)。 - 基于
[c_t, v_t]通过一个带sigmoid的线性层生成门控值g_t,其偏置β被初始化为使σ(β)=0.7,确保在初始无历史信息时门控值较高,倾向于使用当前输入。 - 最后,通过
z_t = g_t ⊙ e_t + (1 - g_t) ⊙ z_{t-1}更新状态。这个状态z_t既用于下一步的门控计算,也用于最终的EEG-语音相似度匹配(使用皮尔逊相关系数ρ)和说话人分类预测注意力目标。
- 首先,用当前EEG表征
- 损失函数:训练损失由配对损失(
L_pair,比较当前EEG状态与两个语音流的相似度)和说话人分类损失(L_spk)加权组成:L = L_pair + λ L_spk。
关键设计动机:
- MMAEnc:旨在增强对EEG信号非平稳性和频带特异性的建模能力。多分辨率捕捉快慢动态,自适应聚合则自动聚焦于信息最丰富的频带。
- StreamSAG:避免显式检测切换点(这在稀疏、滞后标签下很困难),而是利用简单的、与任务相关的信号(说话人分类的置信度和稳定性)来平滑地融合历史信息,在“保持稳定”与“响应切换”之间取得平衡。
💡 核心创新点
- 面向自发起切换的无提示线索混合语音数据集 (MS-AASD):这是该领域首个摒弃外部线索和空间线索,要求模型完全依赖语音内容和说话人特征进行解码的数据集,更贴近真实听觉场景。
- 流式稳定性感知门控 (StreamSAG) 机制:提出了一种新颖的、基于任务相关信号(置信度与波动性)的自适应状态更新机制,用于处理流式EEG解码中的历史依赖问题,解决了因标签稀疏滞后导致的转换窗口难以解码的挑战。
- 多频带多分辨率聚合EEG编码器 (MMAEnc):将多频带分析、多尺度时域卷积和自适应注意力融合相结合,形成了一个针对EEG动态特性优化的、鲁棒的特征提取器。
- 完整的流式训练与评估框架:提出了从编码器预训练、流式骨架预训练到端到端微调的多阶段训练协议,并明确了流式在线评估的流程,为该任务建立了标准的实验范式。
🔬 细节详述
- 训练数据:
- 数据集:MS-AASD,13名听力正常的中国成年被试。
- 预处理:EEG重参考至M1/M2平均;带通滤波提取5个子频带(δ, θ, α, β, 低γ);降采样至128Hz;通道级z-score归一化。语音特征使用预训练wav2vec 2.0(第14层)特征,经PCA降至64维,与EEG在128Hz下对齐。
- 数据增强:论文中未提及具体的数据增强方法。
- 损失函数:总损失
L = L_pair + λ L_spk。L_pair:交叉熵损失,目标为分类当前EEG状态与两个语音流中哪一个的皮尔逊相关性更高。L_spk:交叉熵损失,目标为当前EEG状态对应的说话人ID。λ:权重系数,在第一阶段和第二阶段为0.5。
- 训练策略:
- 三阶段训练:1)编码器预训练(端到端);2)流式骨架预训练(冻结编码器,仅训练StreamSAG,使用TBPTT);3)流式联合微调(端到端)。
- 优化器:AdamW。
- 关键超参数(第一阶段):学习率
1e-3,批大小128,训练30轮。 - 关键超参数(第二阶段):学习率
1e-3,梯度裁剪5,Reduce-on-Plateau调度器(因子0.5,耐心2,最小学习率1e-5),早停耐心10。TBPTT设置:并行流B=48,展开步数K=8,前W=2步为预热不计算损失。 - 关键超参数(第三阶段):学习率
1e-4,早停耐心10。
- 关键超参数(模型):EEG编码器中,GMR模块输出维度D=64,BandTF和TempTF使用4头注意力。说话人分类头隐藏层大小为64,输出2类。
- 训练硬件:论文中未说明训练所使用的GPU型号、数量及训练时长。
- 推理细节:流式推理时,按决策窗口顺序输入,状态
z_t和p_t逐步传递。在线评估与流式训练协议一致。 - 正则化技巧:第二阶段训练使用了梯度裁剪;第三阶段使用了早停。
📊 实验结果
主要对比实验(见核心摘要中的表格)。SAASDNet在所有设置下均取得了最佳性能。例如,在1秒窗口下,使用W2V特征时,SAASDNet(83.6%)相比非流式版本AASDNet(79.9%)提升了3.7个百分点,相比最强基线TransCNN(78.4%)提升了5.2个百分点。
消融实验结果(使用W2V特征)如下表所示:
| 模型变体 | 决策窗口长度 | ||
|---|---|---|---|
| 0.5 s | 1 s | 2 s | |
| – w/o SAG (使用隐式门控) | 77.6 | 78.4 | 79.8 |
| – w/o Conf (移除置信度) | 80.3 | 82.1 | 83.2 |
| – w/o Vol (移除波动性) | 79.7 | 81.8 | 82.6 |
| – w/o GMR (使用单分支卷积) | 79.6 | 82.2 | 82.7 |
| – w/o MBA (均匀平均频带) | 80.1 | 81.7 | 82.3 |
| SAASDNet (完整模型) | 81.5 | 83.6 | 84.5 |
关键结论:移除稳定性感知门控(w/o SAG)导致性能大幅下降(-5.2% @1s),证明了其核心作用。在门控内部,移除置信度(w/o Conf)或波动性(w/o Vol)分别带来-1.5%和-1.8%的性能下降,表明两者互补。MMAEnc中的多分辨率卷积(w/o GMR)和自适应频带聚合(w/o MBA)也分别贡献了显著的性能提升。
论文中未提供不同语言、不同场景下的细分结果。
⚖️ 评分理由
学术质量:6.0/7
- 创新性:提出了新颖的任务范式(自发起、无线索)和相应的数据集、模型。StreamSAG机制的设计具有一定巧思。
- 技术正确性:方法描述清晰,模型架构设计合理,训练流程(多阶段、TBPTT)符合处理序列数据的最佳实践。
- 实验充分性:实验设计全面,包含了与多种先进基线的对比、不同决策窗口长度的评估、不同语音特征(Mel vs. W2V)的对比以及详细的消融研究,有力地支持了所提方法的有效性。
- 证据可信度:实验结果以表格形式清晰呈现,数值差异显著,消融分析逻辑自洽。
- 扣分原因:模型架构(特别是MBA中的Transformer部分���的动机和细节解释可以更深入。缺乏对结果的更深层神经机制或EEG信号层面的可视化分析。
选题价值:1.5/2
- 前沿性:直接针对EEG听觉注意力解码领域从静态、受控向动态、自然场景演进的核心挑战。
- 潜在影响:为开发更智能、更适应真实环境的助听设备提供了关键技术组件,具有明确的应用前景。
- 读者相关性:对于从事脑机接口、神经工程、智能听觉辅助设备研究的读者有较高价值。
- 扣分原因:作为基础研究,距离大规模实际应用仍有距离,且EEG采集的侵入性和成本限制了其普及速度。
开源与复现加成:0.3/1
- 数据集公开:明确提供了MS-AASD数据集的Zenodo链接,这是重要的贡献。
- 复现细节:提供了详细的实验设置、训练三阶段策略、关键超参数和评估协议。
- 缺失部分:未提供代码仓库链接、模型权重或预训练模型,这显著限制了复现的便利性和研究的可扩展性。因此加成有限。