📄 SA-SSL-MOS: Self-Supervised Learning MOS Prediction with Spectral Augmentation for Generalized Multi-Rate Speech Assessment
#语音质量评估 #自监督学习 #数据增强 #多语言 #开源工具
✅ 7.0/10 | 前50% | #语音质量评估 | #自监督学习 | #数据增强 #多语言
学术质量 4.2/7 | 选题价值 1.5/2 | 复现加成 0.3 | 置信度 中
👥 作者与机构
- 第一作者:Fengyuan Cao(KTH Royal Institute of Technology, Stockholm, Sweden)
- 通讯作者:未说明
- 作者列表:Fengyuan Cao(KTH皇家理工学院),Xinyu Liang(KTH皇家理工学院),Fredrik Cumlin(KTH皇家理工学院),Victor Ungureanu(Google LLC),Chandan K. A. Reddy(Google LLC),Christian Sch¨uldt(Google LLC),Saikat Chatterjee(KTH皇家理工学院)
💡 毒舌点评
亮点:论文巧妙地设计了一个并行架构,将受限于16kHz的SSL特征与可处理48kHz的谱图特征相结合,直面并试图解决多速率语音评估中的高频信息丢失问题,两阶段训练策略在有限数据下提升了泛化能力。短板:所提方法在部分外部数据集(如腾讯中文数据集)上的性能反而低于仅使用SSL的基线模型,这表明其“谱图增强”分支可能引入了与语言或域不匹配的偏差,削弱了论文核心论点的一致性,且未与更前沿的多速率评估方法进行对比。
🔗 开源详情
- 代码:提供代码仓库链接:https://github.com/Dear-xxf/SA_SSL_MOS
- 模型权重:论文中未提及公开的模型权重文件。
- 数据集:训练所用的NISQA和AudioMOS数据集均为公开数据集,论文中引用了其来源。评估使用的外部数据集(Tencent, TCD-VoIP等)也多为公开数据集,但论文未提供获取方式的具体说明。
- Demo:论文中未提及在线演示。
- 复现材料:论文给出了关键的模型架构、超参数(学习率、批大小、优化器、损失函数)和训练流程。但未提供具体的检查点、配置文件或环境依赖列表。
- 论文中引用的开源项目/模型:主要依赖于预训练的SSL模型Wav2vec2-XLSR-2B(引用[7]),以及DNSMOS Pro(引用[16])的架构作为SPM设计的参考。实现代码基于PyTorch(脚注中提到了torchaudio)。
- 总结:论文提供了核心代码,具备基本的复现基础,但缺乏模型权重和更完备的复现材料,因此开源程度为中等。
📌 核心摘要
- 问题:现有基于自监督学习(SSL)的语音质量评估(SQA)模型主要在16kHz语音上预训练,无法利用高采样率(24-48kHz)语音中的高频信息,导致对多速率语音的评估性能不佳。同时,公开的多速率MOS标注数据集规模较小,模型易过拟合且泛化能力弱。
- 方法核心:提出SA-SSL-MOS,一个并行的双分支架构。一个分支将音频下采样至16kHz,使用Wav2vec2-XLSR-2B的第9层特征;另一个分支将音频上采样至48kHz,提取对数谱图特征并由CNN处理。两个分支的特征拼接后预测MOS的均值和方差。此外,采用两阶段训练:先在大规模48kHz单速率数据集(NISQA)上预训练,再在少量多速率数据集(AudioMOS)上微调。
- 创新点:与已有SSL-Layer-MOS相比,新在通过并行谱图分支显式补充高频特征;并引入了针对多速率SQA的预训练-微调训练范式。
- 主要实验结果:
- 在AudioMOS测试集上,两阶段训练的SA-SSL-MOS取得了最佳的UTT SRCC(0.750)和UTT LCC(0.848)。
- 在泛化能力测试(表3)中,两阶段训练大幅提升了模型在多个外部数据集(如NISQA-Talk, TCD-VoIP)上的相关系数。但在Tencent w/o R(中文)数据集上,SA-SSL-MOS的MSE(1.192)高于基线(0.751),LCC(0.877)低于基线(0.917)。
| 模型 | 训练数据 | 测试集 (Tencent w/o R) | MSE ↓ | LCC ↑ | SRCC ↑ | | :--- | :--- | :--- | :--- | :--- | :--- | | baseline | AudioMOS train | Tencent w/o R | 1.002±0.054 | 0.691±0.023 | 0.687±0.024 | | SA-SSL-MOS (Ours) | AudioMOS train | Tencent w/o R | 1.097±0.057 | 0.669±0.035 | 0.666±0.033 | | baseline | NISQA+AudioMOS train | Tencent w/o R | 0.751±0.043 | 0.917±0.009 | 0.901±0.006 | | SA-SSL-MOS (Ours) | NISQA+AudioMOS train | Tencent w/o R | 1.192±0.124 | 0.877±0.024 | 0.891±0.010 | - 实际意义:为处理不同采样率的语音质量评估提供了一种可扩展的框架,特别是在标注数据有限时,通过预训练提升泛化能力,对VoIP、高清通话等应用有潜在价值。
- 主要局限性:1) 谱图增强分支在跨语言(如中文)场景下可能产生负面迁移,导致性能下降。2) 高频信息提升评估准确性的核心论点在部分实验中(如腾讯数据集)未得到支持。3) 未与当前多速率SQA领域的其他SOTA方法进行对比。
🏗️ 模型架构
SA-SSL-MOS采用并行的双分支架构处理输入语音音频 x,并预测其MOS分数 y。
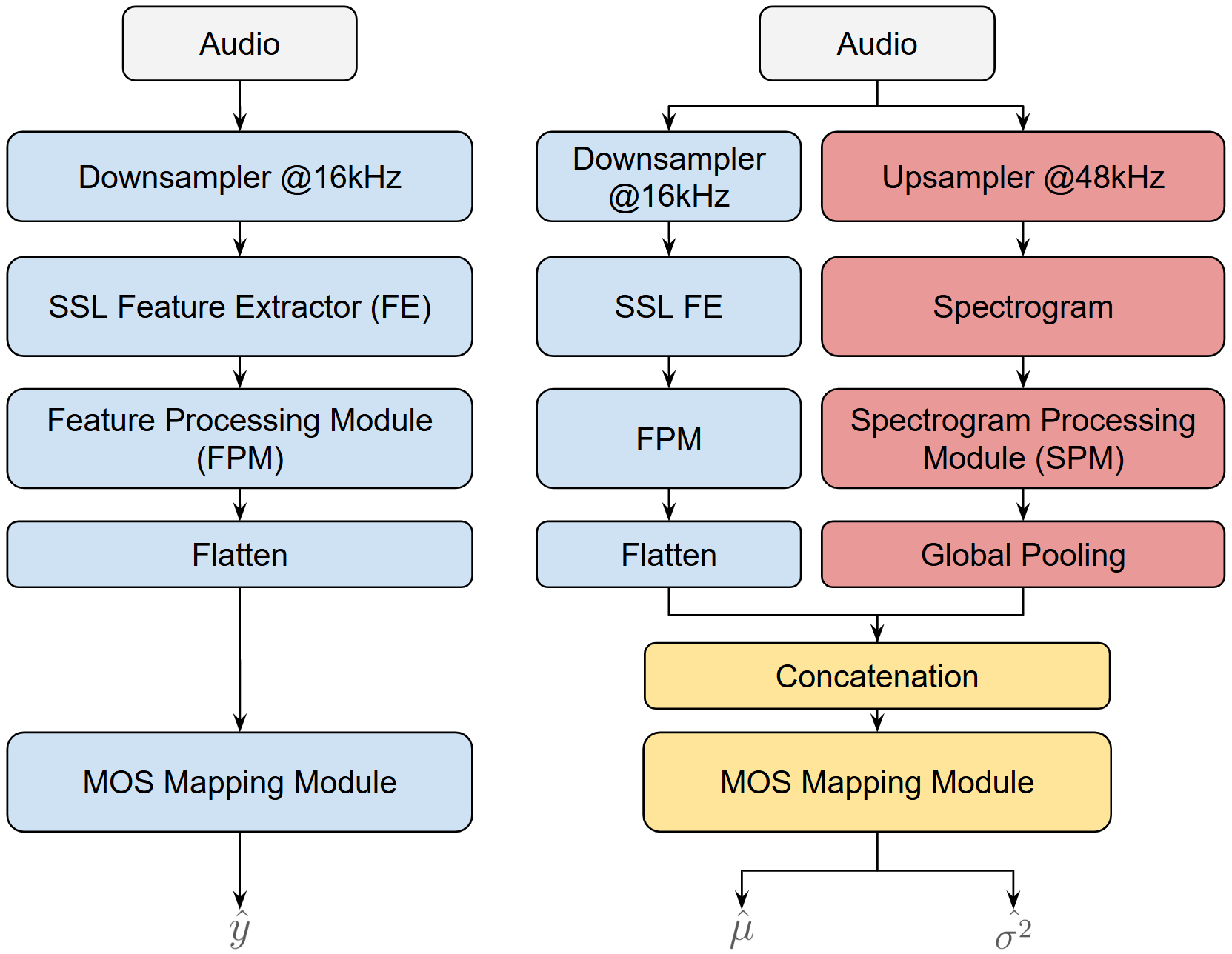 图1:SSL-Layer-MOS(左)与SA-SSL-MOS(右)架构对比。SA-SSL-MOS新增了处理48kHz上采样音频的频谱处理模块(SPM)分支。
图1:SSL-Layer-MOS(左)与SA-SSL-MOS(右)架构对比。SA-SSL-MOS新增了处理48kHz上采样音频的频谱处理模块(SPM)分支。
输入:原始语音信号。输出:MOS预测均值 û 和方差 σ̂²。
主要组件与数据流:
- SSL分支:与基线相同。输入音频被下采样至16kHz,并填充/裁剪至固定长度10秒。通过预训练的Wav2vec2-XLSR-2B模型,提取其第9个Transformer层的输出作为特征表示。该特征经过特征处理模块(FPM),FPM由三个1D卷积层构成,用于进一步处理SSL特征。
- 谱图分支(创新点):输入音频被上采样至48kHz,同样填充/裁剪至10秒。通过短时傅里叶变换(STFT)(窗长320,帧移160,FFT大小320)计算频谱,并取幅度谱后进行对数变换,生成对数谱图。该谱图送入频谱处理模块(SPM),SPM基于DNSMOS Pro的编码器架构,使用2D卷积层进行处理。处理后的特征通过全局池化层,生成固定维度的向量。
- 特征融合与预测:将FPM输出的SSL特征向量与SPM输出的谱图特征向量进行拼接,得到一个640维的联合特征向量。该向量被送入MOS映射模块,该模块包含三个全连接层,并最终通过两个独立的线性层分别映射为预测的均值
û和方差σ̂²。 - 训练目标:模型参数通过最小化高斯负对数似然(GNLL)损失函数来优化。该损失函数建模MOS的后验分布为高斯分布,同时优化点估计精度并提供不确定性估计。
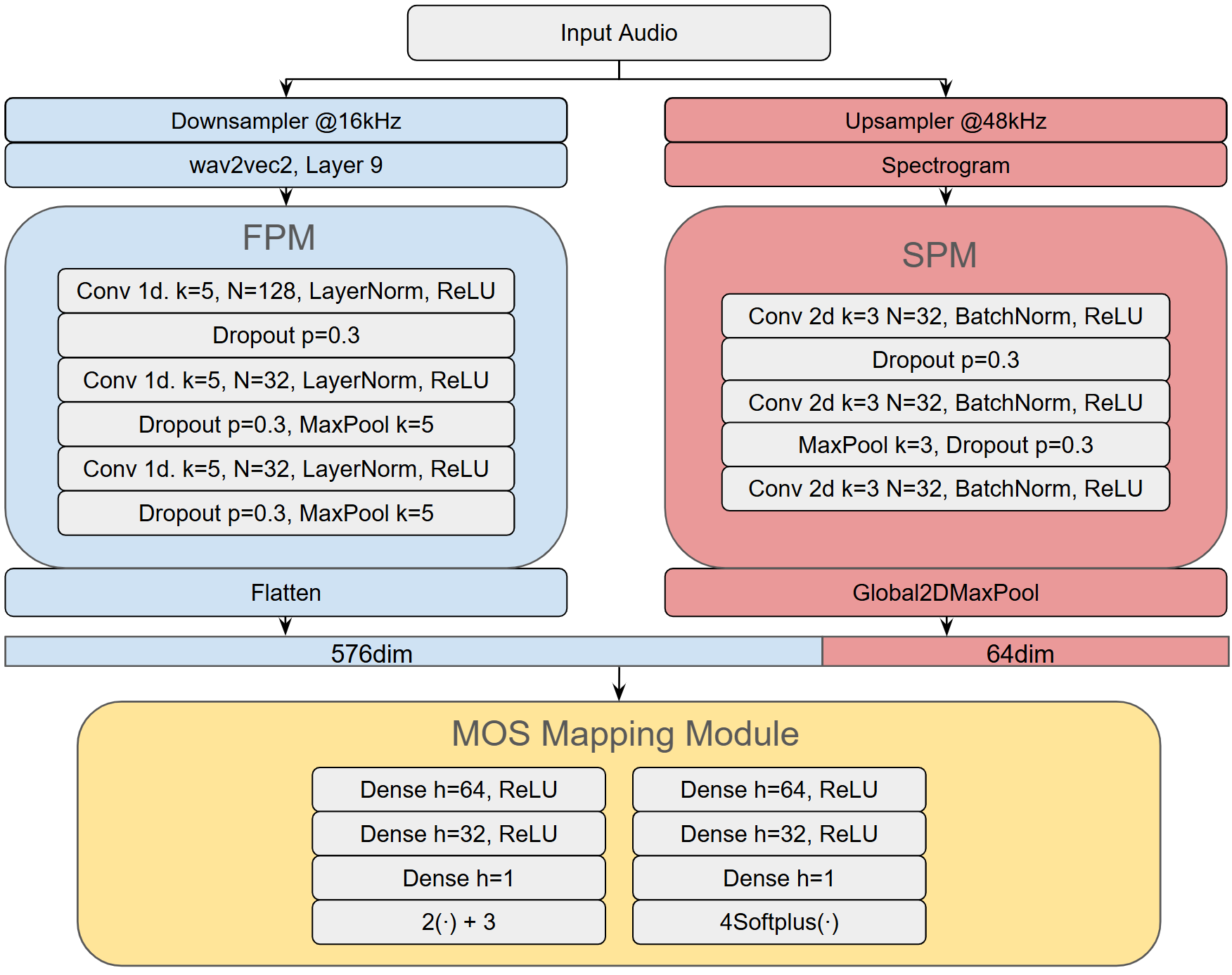 图2:SA-SSL-MOS的详细分层架构图,清晰展示了SSL分支(左侧蓝色流程)和谱图分支(右侧橙色流程)的具体模块构成及拼接预测过程。
图2:SA-SSL-MOS的详细分层架构图,清晰展示了SSL分支(左侧蓝色流程)和谱图分支(右侧橙色流程)的具体模块构成及拼接预测过程。
关键设计选择:
- 选择Wav2vec2第9层:依据先前研究([5]),早期层的SSL特征对MOS预测更有效且推理成本更低。
- 独立映射头:为
û和σ̂²设计独立的输出头,旨在更好地建模后验分布的参数,而非像DNSMOS Pro那样共享部分结构。 - 并行分支:核心动机是弥补SSL模型在16kHz上预训练导致的高频信息缺失。谱图分支直接处理全带宽(48kHz)信号的频谱,旨在捕获高频细节。
💡 核心创新点
- 频谱增强的并行SSL架构:针对SSL模型丢弃高频信息的问题,提出在标准的SSL特征提取路径旁,并行增加一个处理48kHz谱图的卷积神经网络分支。该设计使模型能够同时利用SSL学到的高层语义/声学特征和直接从高分辨率频谱中提取的高频细节特征,丰富了输入表示。
- 针对多速率SQA的两阶段训练策略:为解决多速率标注数据稀缺的问题,设计了“大规模单速率预训练 + 小规模多速率微调”的训练范式。预训练阶段(在NISQA数据集)使模型(尤其是谱图分支)学习通用的语音质量表征,微调阶段(在AudioMOS数据集)则让模型适应多速率评估任务和特定的评分尺度,防止过拟合,显著提升了模型在多个外部测试集上的泛化能力。
- 将高频信息利用与有限数据训练结合:不仅提出了利用高频信息的新架构,还通过实验验证了在数据受限时,两阶段训练策略对于充分发挥该架构优势、提升泛化性能的必要性。这是对问题(高频信息缺失+数据稀缺)和解决方案(架构增强+训练策略)的完整闭环设计。
🔬 细节详述
- 训练数据:
- 预训练数据:NISQA TRAIN(SIM+LIVE),共约11,020个样本,采样率48kHz,英语。验证集为NISQA VAL(约2,700样本)。
- 微调/直接训练数据:AudioMOS 2025 Track3训练集,划分为320个训练样本和80个验证样本,包含16/24/48kHz多速率语音,英语。测试集为400个样本。
- 数据增强:论文中未提及使用额外的数据增强技术(如噪声添加、速度扰动等)。输入音频处理主要通过重复填充或裁剪至固定长度10秒。
- 损失函数:高斯负对数似然(GNLL)损失。公式为
L_GNLL = Σ [ (1/2) * (log(σ̂²) + (y - û)² / σ̂²) ]。它将MOS预测建模为回归高斯分布的问题,同时优化预测均值和方差,比单纯的MSE损失更符合主观评分的不确定性特性。 - 训练策略:
- 两阶段策略:第一阶段在NISQA TRAIN上预训练30个epoch;第二阶段在AudioMOS train上微调3个epoch。
- 对比设置:(1) 仅在AudioMOS train上训练30个epoch;(2) 仅在NISQA TRAIN上训练30个epoch。
- 超参数:优化器Adam(lr=1e-4,β1=0.9, β2=0.999,无权重衰减);学习率调度器ExponentialLR(gamma=0.9999);批大小64。所有实验保持超参数一致。基线模型也使用GNLL损失。
- 实验重复:两阶段策略进行5轮实验,每轮含两次微调;单数据集训练设置进行10次独立运行。
- 关键超参数:
- SSL模型:Wav2vec2-XLSR-2B,使用第9层输出。
- SSL输入:下采样至16kHz,固定10秒。
- 谱图输入:上采样至48kHz,固定10秒。STFT参数:窗长=320,帧移=160,FFT大小=320。
- 模型输出维度:SSL分支与谱图分支特征拼接后为640维。
- 预测头:独立的三层全连接层,输出维度为1(用于
û和σ̂²)。
- 训练硬件:论文中未提及具体的GPU/TPU型号、数量或训练时长。
- 推理细节:推理时使用预测的均值
û作为MOS的点估计。论文中未提及解码策略、温度或流式处理等,因为这是回归任务而非生成任务。 - 正则化/稳定训练技巧:未明确提及除两阶段训练外的其他正则化技巧(如Dropout)。训练稳定性可能部分依赖于预训练提供的良好初始化和较小的学习率调度。
📊 实验结果
论文在AudioMOS测试集上评估了模型性能,并在6个外部数据集上测试了泛化能力。评估指标包括MSE(越低越好)、LCC和SRCC(越高越好)。
表2:AudioMOS测试集上的结果
| 模型 | 训练数据 | UTT MSE ↓ | UTT LCC ↑ | UTT SRCC ↑ | SYS MSE ↓ | SYS LCC ↑ | SYS SRCC ↑ |
|---|---|---|---|---|---|---|---|
| baseline [5] | AudioMOS train | 0.282 ± 0.017 | 0.830 ± 0.012 | 0.678 ± 0.020 | 0.138 ± 0.012 | 0.961 ± 0.006 | 0.852 ± 0.035 |
| baseline [5] | NISQA | 0.835 ± 0.071 | 0.798 ± 0.014 | 0.712 ± 0.033 | 0.641 ± 0.057 | 0.920 ± 0.008 | 0.781 ± 0.042 |
| baseline [5] | NISQA+AudioMOS train | 0.465 ± 0.066 | 0.819 ± 0.016 | 0.731 ± 0.023 | 0.385 ± 0.079 | 0.936 ± 0.007 | 0.845 ± 0.015 |
| SA-SSL-MOS (Ours) | AudioMOS train | 0.375 ± 0.035 | 0.830 ± 0.006 | 0.679 ± 0.015 | 0.286 ± 0.060 | 0.953 ± 0.014 | 0.826 ± 0.084 |
| SA-SSL-MOS (Ours) | NISQA | 0.555 ± 0.070 | 0.789 ± 0.011 | 0.721 ± 0.024 | 0.424 ± 0.059 | 0.911 ± 0.005 | 0.754 ± 0.022 |
| SA-SSL-MOS (Ours) | NISQA+AudioMOS train | 0.377 ± 0.082 | 0.848 ± 0.008 | 0.750 ± 0.018 | 0.323 ± 0.104 | 0.943 ± 0.005 | 0.856 ± 0.025 |
关键发现:
- 仅使用有限AudioMOS数据训练时,基线和SA-SSL-MOS表现相近,SA-SSL-MOS的MSE略高,可能是由于谱图分支需要更多数据。
- 仅使用NISQA训练时,两者相关性指标较好,但MSE较高,源于数据分布不对齐。
- 两阶段训练(NISQA+AudioMOS)显著提升了SA-SSL-MOS的性能,在UTT LCC/SRCC上达到最佳,并缓解了MSE问题。这验证了预训练策略的有效性。
表3:泛化能力测试结果(UTT级别) 由于篇幅,这里仅展示关键部分对比(聚焦于TCD-VoIP和Tencent w/o R两个数据集,以显示差异性):
| test data | train data | model | MSE ↓ | LCC ↑ | SRCC ↑ |
|---|---|---|---|---|---|
| Tencent w/o R | AudioMOS train | baseline | 1.002±0.054 | 0.691±0.023 | 0.687±0.024 |
| Tencent w/o R | AudioMOS train | SA-SSL-MOS | 1.097±0.057 | 0.669±0.035 | 0.666±0.033 |
| Tencent w/o R | NISQA+AudioMOS train | baseline | 0.751±0.043 | 0.917±0.009 | 0.901±0.006 |
| Tencent w/o R | NISQA+AudioMOS train | SA-SSL-MOS | 1.192±0.124 | 0.877±0.024 | 0.891±0.010 |
| TCD-VoIP | NISQA+AudioMOS train | baseline | 0.615±0.061 | 0.844±0.025 | 0.836±0.030 |
| TCD-VoIP | NISQA+AudioMOS train | SA-SSL-MOS | 0.590±0.092 | 0.860±0.022 | 0.847±0.029 |
关键发现:
- 两阶段训练大幅提升了所有模型在外部数据集上的泛化能力(比较“AudioMOS train”与“NISQA+AudioMOS train”行)。
- 在NISQA测试集(多语言、单速率48kHz)和TCD-VoIP上,SA-SSL-MOS(两阶段训练)一致地优于基线,表明高频谱图特征在这些高保真语音评估中发挥了作用。
- 在腾讯中文数据集(24kHz)上,情况相反:SA-SSL-MOS的MSE显著高于基线,LCC和SRCC略低于基线。论文作者将此归因于语言分布不匹配:SSL骨干网络预训练数据包含中文,而SA-SSL-MOS的SPM分支在NISQA(纯英语)上预训练,导致对中文语音的负迁移。这是一个重要的发现,揭示了当前方法在跨语言场景下的局限性。
⚖️ 评分理由
- 学术质量:4.2/7。论文结构完整,提出了针对具体问题的解决方案(并行分支+两阶段训练),实验设计合理,包含充分的对比消融和泛化测试。主要扣分点在于:1) 创新性属于增量式改进,未提出革命性新概念;2) 核心论点(高频信息提升评估准确性)在部分关键实验(中文数据集)中未被证实,甚至出现性能倒退,削弱了论证的严密性;3) 未与当前多速率语音评估领域的其他最先进工作进行对比,难以准确定位其水平。
- 选题价值:1.5/2。多速率语音质量评估是实际存在的工业界和学术界问题,论文直接针对该问题的痛点(数据少、模型带宽受限)。选题具有明确的应用导向和一定的前沿性,但相比音频生成、大模型等热门方向,其影响力和受众面可能相对有限。
- 开源与复现加成:0.3/1。积极提供了代码仓库链接,对复现有重要帮助。但未提供预训练模型权重、完整的复现脚本、或训练好的最终模型。训练数据集(NISQA, AudioMOS)是公开可获取的,但论文未详细说明如何获取和处理。超参数和架构细节描述较为清晰。