📄 S-PRESSO: Ultra Low Bitrate Sound Effect Compression with Diffusion Autoencoders and Offline Quantization
#音频生成 #扩散模型 #量化 #模型比较
✅ 7.5/10 | 前25% | #音频生成 | #扩散模型 | #量化 #模型比较
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Zineb Lahrichi(Sony AI, LTCI, T´el´ecom Paris, Institut Polytechnique de Paris)
- 通讯作者:未说明
- 作者列表:Zineb Lahrichi(Sony AI, LTCI, T´el´ecom Paris, Institut Polytechnique de Paris)、Ga¨etan Hadjeres(Sony AI)、Ga¨el Richard(LTCI, T´el´ecom Paris, Institut Polytechnique de Paris)、Geoffroy Peeters(LTCI, T´el´ecom Paris, Institut Polytechnique de Paris)
💡 毒舌点评
S-PRESSO巧妙地将扩散先验与离线量化结合,在0.096kbps下实现了惊人的音效重建质量,超越了现有连续和离散方法。但其创新本质是工程优化而非理论突破,且当前版本仅限于5秒音效、推理缓慢,离实用还有距离。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及。
- 数据集:训练数据为“内部音效数据集”,未公开。评估数据集部分公开(Freesound, BBC Sound Effects)。
- Demo:提供在线音频样例网站:https://zineblahrichi.github.io/s-presso/
- 复现材料:论文给出了训练框架的概述、部分超参数(如学习率、批大小、GPU型号)和量化器配置,但缺少完整的训练脚本、配置文件和预训练模型检查点。
- 论文中引用的开源项目:引用了Qinco2[18](量化器)、LoRA[12]、Vocos[13](AudioAE基础)、Stable Audio Open[21]、Music2Latent[22]、SemantiCodec[6]等作为基线或组件来源。
📌 核心摘要
- 问题:现有神经音频压缩模型在追求高压缩率时,通常会在极低比特率下产生明显的可听伪影(如金属音、机器人音),且多局限于低分辨率音频。
- 方法核心:提出S-PRESSO,一个三步训练的扩散自编码器:1) 训练一个连续扩散自编码器,利用预训练的扩散Transformer(DiT)作为解码器;2) 对学习到的连续表示进行离线神经量化(Qinco2);3) 微调扩散解码器以补偿量化引入的失真。
- 新颖之处:与现有方法相比,S-PRESSO首次在48kHz高分辨率音效上实现了超低比特率压缩(最低0.096 kbps),并通过将帧率降至1Hz(750倍压缩),重点利用生成先验来保持声学相似性而非波形保真度。
- 主要实验结果:
- 连续压缩对比 (Table 1):在相似压缩率下,S-PRESSO在所有指标上均优于基线Stable Audio Open和Music2Latent。例如,在R=68 (11Hz)时,S-PRESSO的FADCLAP为0.050,而Music2Latent为0.168;其CLAPaudio相似度为0.76,高于Music2Latent的0.69。
- 离散压缩对比 (Table 2):在低比特率(~1.3 kbps)和超低比特率(~0.3 kbps)下,S-PRESSO均大幅超越SemantiCodec。例如在0.3 kbps时,S-PRESSO的FAD为0.64,SemantiCodec为1.23;CLAPaudio相似度为0.71,高于后者的0.48。
- 主观评估 (Fig. 3):在
1.35 kbps和0.3 kbps的MUSHRA测试中,S-PRESSO在音质和相似度评分上均显著高于SemantiCodec和低通锚点。 - 消融研究 (Fig. 4):第三步微调(finetune)对所有比特率配置都有持续提升;在固定帧率下,更多码本带来更好性能;在固定比特率下,更高帧率性能更优。
- 实际意义:该工作展示了生成式模型在音频压缩领域的巨大潜力,尤其是在带宽受限但需要高感知质量的动态环境(如游戏)中,可以实现以声学相似性换取极低存储/传输开销。
- 主要局限性:模型当前仅针对约5秒的音效片段进行训练和评估,其对更长、更复杂的音频(如音乐、语音)的处理能力未验证;扩散模型解码过程较慢,不适合实时应用;与所有生成式方法一样,其重建结果存在随机性,可能无法满足对波形精确一致性的要求。
🏗️ 模型架构
S-PRESSO是一个端到端的音频压缩-解压框架,其核心是利用预训练的生成模型作为解码器。整体流程分为三个阶段,如图1所示。
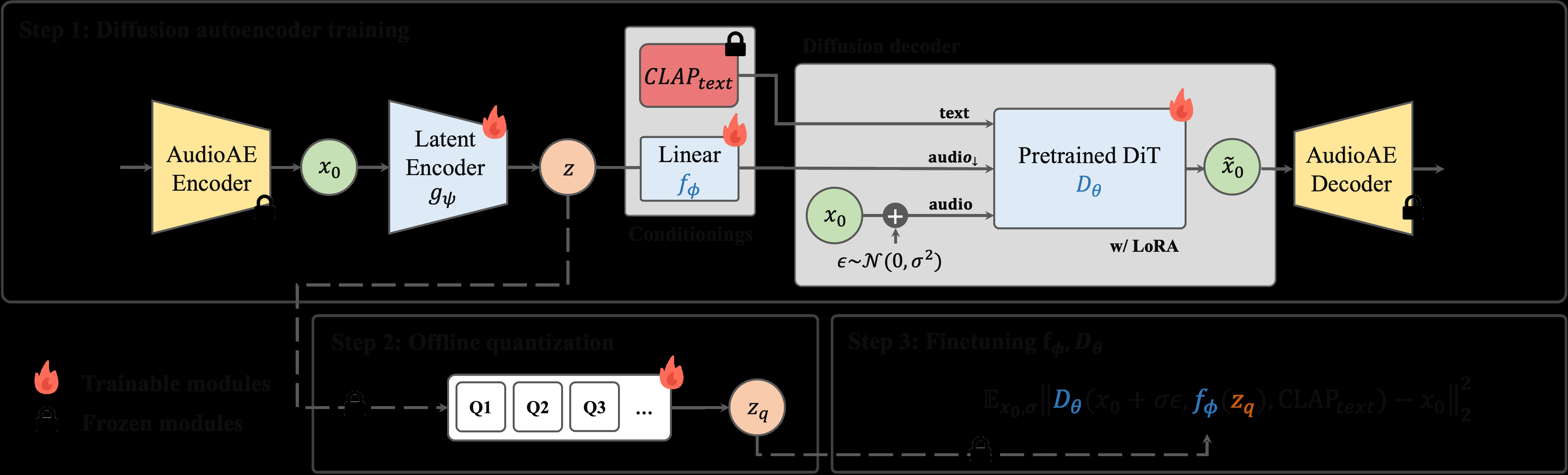 图1 说明:该图清晰地展示了三步训练流程。Step 1是扩散自编码器训练,原始音频经一个低压缩率的AudioAE编码为
图1 说明:该图清晰地展示了三步训练流程。Step 1是扩散自编码器训练,原始音频经一个低压缩率的AudioAE编码为x0,再由潜在编码器gψ压缩为z,z经线性层fϕ上采样后作为条件,输入到预训练的扩散Transformer(DiT)解码器Dθ中,Dθ被训练从加噪的x0中重建出干净的x0。Step 2是对z进行离线量化得到zq。Step 3是用zq替换z,微调Dθ和fϕ。
- Audio Autoencoder (AudioAE):一个基于GAN的低压缩率自编码器,用于将原始48kHz波形转换为更紧凑、信息更丰富的潜在表示
x0。其解码器基于Vocos[13],直接预测STFT复数系数,以减少上采样伪影。其作用是为后续的高压缩提供一个高质量的潜在表示空间。 - 潜在编码器 (Latent Encoder,
gψ):如图2(a)所示,这是一个深度可变的Transformer编码器。它沿时间和频率轴对x0进行下采样,时间压缩因子t根据目标帧率调整(帧率=100/t Hz)。它使用RoPE位置编码,并通过平均池化实现时间下采样,输出压缩后的潜在表示z。
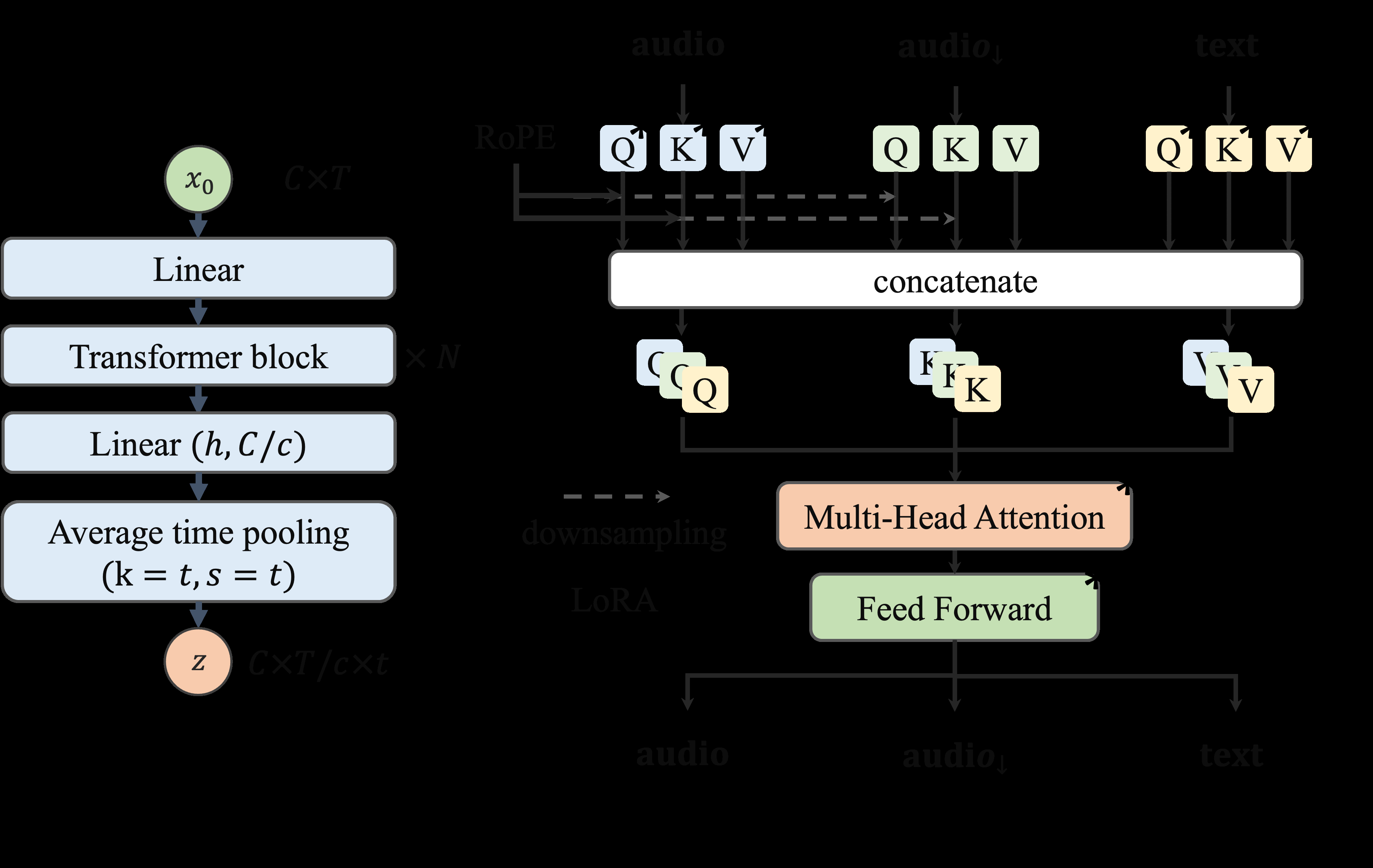 图2(a)说明:展示了潜在编码器的结构:输入
图2(a)说明:展示了潜在编码器的结构:输入x0经过多个Transformer块(使用RoPE),然后通过线性层和平均池化层实现时间下采样,得到z。
图2(b)说明:展示了扩散解码器中的条件注入机制。压缩后的音频条件audio↓(来自fϕ(z))被视为第三种模态,通过专门的Q、K、V层注入到DiT中,并与原始音频模态共享降采样的RoPE位置编码以保持对齐。
- 扩散解码器 (Diffusion Decoder,
Dθ):一个预训练的文本到音频的Diffusion Transformer (DiT),基于EDM2[19]参数化。它由12个Transformer块组成(前6个多模态,后6个仅音频)。在训练中,其权重被LoRA适配器[12]微调,以适应新的音频条件audio↓。 - 线性投影层 (
fϕ):一个简单的线性层,用于将潜在编码器输出的z重新投影到与DiT原始音频模态兼容的维度,作为解码器的条件输入。 - 离线神经量化器:采用Qinco2[18],它是一种改进的残差向量量化(RVQ),使用神经网络生成自适应质心。它在步骤2中对冻结的
z进行训练,生成离散表示zq。
💡 核心创新点
- 三步训练流程:结合了连续扩散自编码器训练、离线神经量化和解码器微调。这允许模型先学习一个强大的连续表示,再通过量化获得紧凑的离散表示,最后微调解码器以适应量化误差,平滑了从连续到离散的过渡。
- 将预训练扩散模型用作压缩解码器:利用大型文本到音频扩散模型(DiT)强大的生成先验,使其在仅接收极低帧率(如1Hz)条件时,仍能生成语义连贯、音质逼真的音频。这颠覆了传统编解码器追求逐帧波形精确重建的范式。
- 实现1Hz帧率下的高质量音效压缩:通过极强的时间下采样(t=100),将48kHz音频压缩到仅每秒一个潜在向量,在0.096 kbps的极低比特率下,仍能维持较高的声学相似度(CLAPaudio=0.67),证明了生成先验在信息恢复上的强大能力。
- 针对48kHz高分辨率音效:将超低比特率生成式压缩的应用范围从语音、窄带音频扩展到高采样率(48kHz)的音效领域,填补了相关空白。
🔬 细节详述
- 训练数据:使用了四个内部音效数据集,总计约5000小时,采样率48kHz,片段剪辑为5秒。涵盖Foley音、环境声、音乐片段和背景语音。评估使用了Freesound Effects、BBC Sound Effects和一个内部工作室级数据集,每个数据集随机采样500个5秒片段。
- 损失函数:论文未详细说明AudioAE和DiT预训练的损失函数。在扩散自编码器训练中,解码器
Dθ的训练目标是根据条件audio↓和噪声级别,从带噪的x0中重建出干净的x0,这由扩散模型的训练目标(如EDM2的v-prediction)隐式定义。微调阶段未提及额外损失。 - 训练策略:
- AudioAE:遵循文献[4]的设置,包括判别器、损失函数和优化参数。
- DiT:采用EDM2策略,使用AdamW优化器,学习率为1e-4。文本条件(用于预训练)通过CLAP编码器提供。
- 潜在编码器与微调:同样使用AdamW优化器,学习率1e-4。训练使用4块A100 GPU,批大小32。在扩散解码器微调时,对文本嵌入应用了0.8的强dropout,以迫使模型依赖音频条件。在最后量化微调阶段,为稳定训练,会以10%的概率保留原始连续表示
z。
- 关键超参数:
- AudioAE潜在维度C=128,STFT的nfft=960,hop_size=480(约100帧/秒)。
- 频率压缩因子c=2(
z的维度为64)。 - 时间压缩因子t根据目标帧率设置:t=4 (25Hz), t=9 (11Hz), t=20 (5Hz), t=100 (1Hz)。
- 潜在编码器深度随帧率降低而增加:25Hz用6个块,11Hz用10个,5Hz和1Hz用12个。
- 量化器Qinco2:码本大小K=10bit或12bit;码本数量M=10(对应K=10)或M=8(对应K=12),以保持总词汇量在约100 bits左右。批大小8000向量帧。
- 训练硬件:4块NVIDIA A100 GPU。
- 推理细节:使用Heun求解器[19],采样步数为64步,采用EDM2默认参数。
- 正则化或稳定训练技巧:在量化微调阶段,以10%的概率混合使用连续表示
z和量化表示zq,以缓解分布突变。对文本条件施加强dropout。
📊 实验结果
论文主要在两个设置下进行对比:连续压缩和离散压缩。
表1:连续压缩性能对比(S-PRESSO vs. 连续基线)
| 方法 | 变体 | D | 帧率 | R (压缩率) | FAD ↓ | FADCLAP ↓ | KADCLAP ↓ | CLAPaudio ↑ | Si-SDR ↑ |
|---|---|---|---|---|---|---|---|---|---|
| AudioAE | – | 128 | 100 Hz | 4 | 0.008 | 0.008 | 0.15 | 0.90 | 22.3 |
| StableAudio Open | – | 64 | 21.5 Hz | 32 | 0.78 | 0.066 | 1.25 | 0.78 | 0.48 |
| S-PRESSO | t=4 | 64 | 25 Hz | 30 | 0.48 | 0.038 | 0.57 | 0.76 | 3.21 |
| Music2Latent | – | 64 | 11 Hz | 64 | 1.28 | 0.168 | 3.29 | 0.69 | -10.5 |
| S-PRESSO | t=9 | 64 | 11 Hz | 68 | 0.59 | 0.050 | 0.77 | 0.76 | -2.40 |
| S-PRESSO | t=20 | 64 | 5 Hz | 150 | 0.76 | 0.059 | 0.92 | 0.71 | -8.80 |
| S-PRESSO | t=100 | 64 | 1 Hz | 750 | 0.64 | 0.059 | 0.89 | 0.73 | -27.7 |
结论:在相似的压缩率R下(如R~60-70),S-PRESSO(t=9)的FADCLAP (0.050) 远优于Music2Latent (0.168) 和 StableAudio Open (0.066),同时保持了更高的CLAP相似度。即使在R=750的极端压缩下,FAD和CLAP相似度仍保持在可接受范围。
表2:离散压缩性能对比(S-PRESSO vs. 离散基线)
| 方法 | kbps | 帧率 | M | FAD ↓ | FADCLAP ↓ | KADCLAP ↓ | CLAPaudio ↑ | Si-SDR ↑ |
|---|---|---|---|---|---|---|---|---|
| 低比特率 | ||||||||
| DAC | 1.7 | 86 Hz | 2 | 3.24 | 0.108 | 1.71 | 0.63 | -4.11 |
| SemantiCodec | 1.4 | 100 Hz | 1 | 1.79 | 0.136 | 4.93 | 0.60 | -31.8 |
| S-PRESSO | 1.32 | 11 Hz | 12 | 0.55 | 0.048 | 0.728 | 0.73 | -4.48 |
| 超低比特率 | ||||||||
| SemantiCodec | 0.3125 | 25 Hz | 1 | 1.23 | 0.271 | 2.70 | 0.48 | -34.5 |
| S-PRESSO | 0.3 | 1 Hz | 25 | 0.64 | 0.052 | 0.78 | 0.71 | -27.8 |
| S-PRESSO | 0.096 | 1 Hz | 8 | 0.68 | 0.060 | 0.89 | 0.67 | -30.4 |
结论:在低比特率下,S-PRESSO的FADCLAP (0.048) 比SemantiCodec (0.136) 好一个数量级。在超低比特率0.3kbps下,S-PRESSO在几乎所有指标上都优于SemantiCodec,尤其在感知质量(FADCLAP)和相似度(CLAPaudio)上优势明显。
图3:MUSHRA主观评测结果
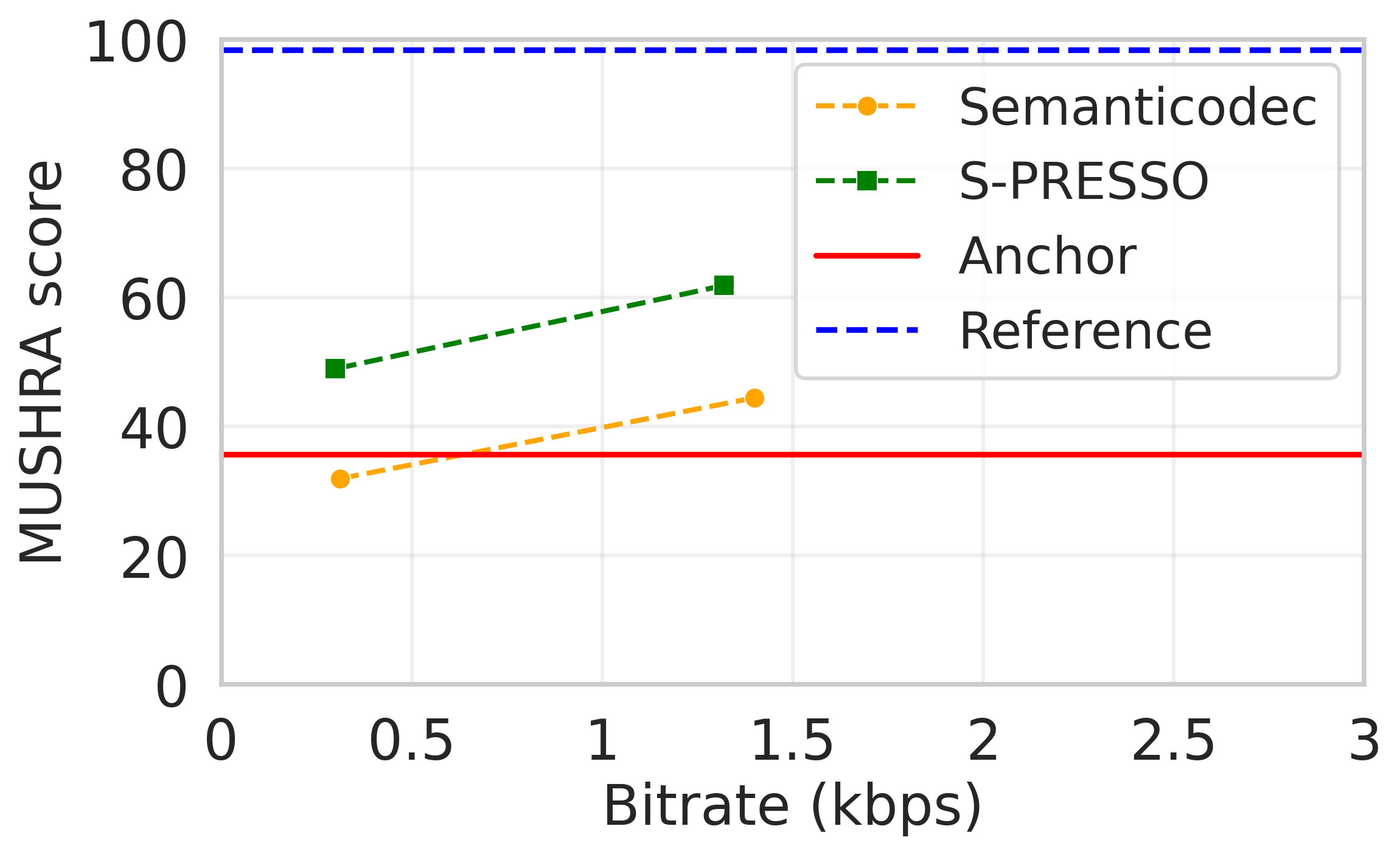 图3 说明:在约1.35 kbps和约0.3 kbps两个比特率下,S-PRESSO的“质量”和“相似度”得分均显著高于SemantiCodec和低通锚点,证实了其在主观感知上的优势。但两者均未达到参考音频(ref)的水平。
图3 说明:在约1.35 kbps和约0.3 kbps两个比特率下,S-PRESSO的“质量”和“相似度”得分均显著高于SemantiCodec和低通锚点,证实了其在主观感知上的优势。但两者均未达到参考音频(ref)的水平。
图4:不同比特率/帧率配置下的性能变化
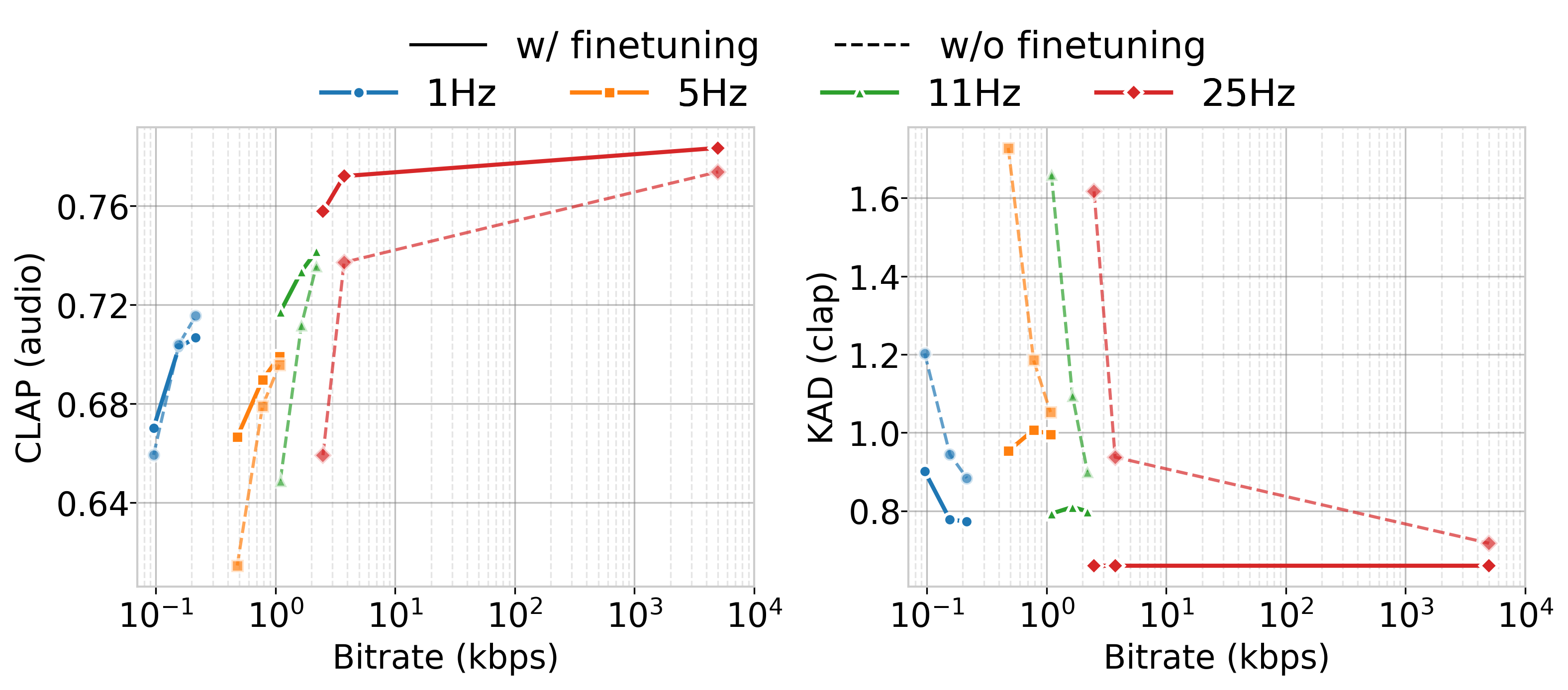 图4 说明:该图显示,对于固定的帧率(如1Hz),增加码本数量(从8到25)能提升性能(FADCLAP降低,CLAPaudio升高)。对于固定的比特率,更高的帧率(如11Hz vs 1Hz)带来更好的性能。同时,比较微调(ft)与未微调的结果,显示微调步骤在所有配置下都带来了性能提升。
图4 说明:该图显示,对于固定的帧率(如1Hz),增加码本数量(从8到25)能提升性能(FADCLAP降低,CLAPaudio升高)。对于固定的比特率,更高的帧率(如11Hz vs 1Hz)带来更好的性能。同时,比较微调(ft)与未微调的结果,显示微调步骤在所有配置下都带来了性能提升。
⚖️ 评分理由
- 学术质量:5.5/7 - 论文技术路线清晰,将扩散先验、潜在压缩和离线量化有机结合,形成一个有效的三步框架。实验对比充分,包含了多个代表性基线、全面的客观指标和主观MUSHRA测试,并提供了有价值的消融实验。主要不足在于创新更多是方法上的巧妙组合与优化,而非提出全新的理论或架构,且对生成过程的可控性与一致性讨论不足。
- 选题价值:1.5/2 - 超低比特率音频压缩是解决网络传输和存储瓶颈的关键技术,具有明确的应用前景。论文将研究拓展到高分辨率音效领域,并强调“声学相似性”而非“波形保真”,符合特定应用场景(如游戏)的需求,思路新颖。但应用场景聚焦于短时音效,对于更通用的音频压缩任务(如长时音乐、语音通话)的影响有待进一步证明。
- 开源与复现加成:0.5/1 - 论文公开了示例音频网站,增加了可信度和透明度。然而,未提供代码、模型权重、训练数据或详细的超参数配置文件,使得完全复现存在较大障碍,这削弱了工作的可扩展性和影响力。