📄 Robust Online Overdetermined Independent Vector Analysis Based on Bilinear Decomposition
#语音分离 #信号处理 #麦克风阵列 #实时处理
✅ 7.0/10 | 前25% | #语音分离 | #信号处理 | #麦克风阵列 #实时处理
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 高
👥 作者与机构
- 第一作者:Kang Chen(武汉大学电子信息学院)
- 通讯作者:未说明(论文未明确标注通讯作者)
- 作者列表:Kang Chen(武汉大学电子信息学院)、Xianrui Wang(西北工业大学、早稻田大学)、Yichen Yang(西北工业大学、早稻田大学)、Andreas Brendel(弗劳恩霍夫集成电路研究所)、Gongping Huang(武汉大学电子信息学院)、Zbyněk Koldovský(利贝雷茨理工大学)、Jingdong Chen(西北工业大学)、Jacob Benesty(魁北克大学国家高等研究院)、Shoji Makino(早稻田大学)
💡 毒舌点评
亮点:巧妙地将参数量从 O(M) 大幅缩减至 O(M1+M2)(当 M=M1*M2),并通过交替投影保证了收敛,实验结果显示在SIR和SDR上均有显著提升(约10dB),论证完整。短板:论文完全没提供代码,对于一个强调“在线”和“实时”的算法,缺乏可部署的开源实现或详尽的复现指南,大大削弱了其实践参考价值;此外,虽然实验场景有噪声和混响,但仍然是高度受控的合成环境,真实世界复杂声学场景(如强动态混响、运动声源)下的性能未知。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用了公开数据集CMU Arctic,但噪声数据(办公室噪声)和生成RIR的具体参数设置需读者自行实现图像法模型进行复现。
- Demo:未提供在线演示。
- 复现材料:论文给出了算法伪代码(Algorithm 1)和核心公式,并说明了主要实验设置(阵列尺寸、STFT参数、遗忘因子等)。但对于代码实现中可能遇到的数值稳定性细节、矩阵求逆的高效实现等未做说明。
- 引用的开源项目:未明确提及。论文引用了CMU Arctic数据集和图像法生成RIR的工具,但未指向具体开源库。
- 总结:论文中未提及开源计划。复现需要较高的信号处理编程能力和从论文描述中重建实验环境的能力。
📌 核心摘要
- 要解决什么问题:现有过定独立向量分析(OverIVA)在大型麦克风阵列下应用时,由于分离滤波器长度等于麦克风数,导致需要估计的参数数量过多,在线估计精度会下降,影响实时性能。
- 方法核心是什么:提出一种双线性分解策略,将每个长的源分离滤波器分解为两个短子滤波器的Kronecker积(w = w1 ⊗ w2),从而大幅减少待估参数。为解决两个子滤波器强耦合的问题,设计了交替迭代投影算法进行优化更新。
- 与已有方法相比新在哪里:相比于直接优化高维滤波器的传统OverIVA,新方法(BiIVA)在保持甚至利用过定模型优势的同时,通过参数降维提升了在线估计的鲁棒性。相比于确定情形下的AuxIVA,BiIVA能更充分地利用多余麦克风的空间分集。
- 主要实验结果如何:在包含混响、点噪声源和白噪声的仿真环境中(36麦克风,2目标源),BiIVA在收敛后性能显著优于AuxIVA和OverIVA。根据图1,BiIVA的信号干扰比(SIR)提升超过30dB,信号失真比(SDR)提升接近20dB,相比OverIVA(SIR
20dB, SDR10dB)和AuxIVA(SIR14dB, SDR8dB)有明显优势。图2的语谱图显示BiIVA能更有效地抑制干扰并保留目标语音。 - 实际意义是什么:为部署大规模麦克风阵列的实时语音分离系统(如智能会议设备、机器人听觉)提供了一种更鲁棒、高效的算法,提升了在线处理的准确性和可行性。
- 主要局限性是什么:实验仅在合成的静态场景下进行,未验证在真实复杂环境(如声源移动、非平稳强噪声、麦克风阵列几何变化)下的鲁棒性;算法依赖于对两个子滤波器进行交替更新,其计算复杂度和收敛速度是否优于原OverIVA的直接更新未做详细分析和比较;论文未开源代码,难以评估其实际运算效率和易用性。
🏗️ 模型架构
论文的核心是算法架构而非神经网络架构。其整体流程为一个在线盲源分离算法。
- 输入:在时频(STFT)域,每个时间帧j,所有麦克风在所有频率点i的观测信号 x_{i,j} ∈ ℂ^M。
- 核心组件:双线性分离滤波器。对于每个源n和频率点i,原本需要估计一个长度为M的滤波器 w_{n,i,j} ∈ ℂ^M。新方法将其分解为 w_{n,i,j} = w_{n,i,j,1} ⊗ w_{n,i,j,2},其中 w_{n,i,j,1} ∈ ℂ^{M1}, w_{n,i,j,2} ∈ ℂ^{M2},满足 M = M1 * M2。这大大减少了参数量(从M减为M1+M2)。
- 数据流与交互:
- 首先固定子滤波器 w_{n,i,j,2},构造矩阵 Δ_{n,i,j,1} = I_{M1} ⊗ w_{n,i,j,2},然后通过一个类似AuxIVA的更新规则(式(19))优化 w_{n,i,j,1}。
- 然后固定更新后的 w_{n,i,j,1},构造 Δ_{n,i,j,2} = w_{n,i,j,1} ⊗ I_{M2},再更新 w_{n,i,j,2}。
- 交替进行以上两步。每次更新后都进行归一化(式(21)和(25))。
- 噪声处理:源分离矩阵更新后,通过正交约束(式(11))更新噪声分离矩阵 U_j,以确保源子空间与噪声子空间正交。
- 输出:更新后的完整分离矩阵 W_i,j 用于提取源信号估计 y_{i,j} = W_i,j x_{i,j}。
- 关键设计选择与动机:采用Kronecker积进行双线性分解的动机直接源于减少参数数量的需求。交替投影算法的选择是因为两个子滤波器相互耦合,难以联合直接优化。
💡 核心创新点
- 双线性分解(Kronecker积形式)降低参数维度:这是本文最核心的贡献。将长度为M的滤波器分解为长度为M1和M2的两个子滤波器的Kronecker积。局限:传统OverIVA参数量随阵列大小M线性增长,在线更新易过拟合。创新:将参数量从O(M)降至O(M1+M2),当M较大时(如文中M=36, M1=M2=6),参数减少极其显著,提升了在线估计的鲁棒性。收益:在保持过定模型空间增益的同时,大幅降低了模型复杂度,提高了分离性能(SIR/SDR提升约10dB)。
- 交替迭代投影更新策略:针对强耦合的双线性结构设计的优化算法。局限:双线性形式导致目标函数非凸,且两个变量相互依赖。创新:固定一个子滤波器更新另一个,将非凸问题转化为一系列交替的凸子问题求解。收益:保证了算法可实现并收敛,并成功应用于复杂的多源场景(扩展自[25]的单源工作)。
- 将双线性分解思想应用于过定IVA框架:虽然双线性/张量分解在信号处理中已有应用,但将其与结合了正交约束的OverIVA算法结合是新的尝试。这解决了OverIVA在大阵列场景下的痛点。
🔬 细节详述
- 训练数据:CMU Arctic数据集。选取5男5女说话人,每人语音拼接为30秒片段。使用图像法生成房间冲激响应(RIR),模拟约200ms的混响时间(T60)。混响语音以0dB的输入信干比(iSIR)混合。噪声包括:5个随机放置的真实录制办公室噪声(卷积RIR)和多通道白高斯噪声(模拟麦克风缺陷)。通过参数σ_v控制输入信噪比(iSNR)为20dB。
- 损失函数:未直接定义“损失函数”,而是优化一个基于最大似然的辅助目标函数(式(6))。该函数包含加权协方差项和行列式项,旨在最大化源信号的统计独立性并满足空间约束。
- 训练策略:属于在线自适应算法,非深度学习训练。交替投影:对每个源n,依次固定一个子滤波器更新另一个。归一化:每次更新子滤波器后,按式(21)和(25)进行归一化,确保 w^H V w = 1。遗忘因子:用于递归估计加权协方差矩阵V(式(7))和空间协方差矩阵C(式(12))。α取值:BiIVA为0.98, AuxIVA为0.96, OverIVA为0.99(各取最佳性能值)。
- 关键超参数:阵列配置:M=36(6x6矩形平面阵,间距6cm)。分解方式:M1=6, M2=6。STFT设置:1024点Hann窗,75%重叠。初始化:BiIVA中, w_{n,0,1}=e_n, w_{n,0,2}=e_1(单位向量); AuxIVA和OverIVA中,分离矩阵初始化为单位阵。
- 训练硬件:未说明。
- 推理细节:在线处理,逐帧计算。解码策略不适用(直接输出分离后的时频信号)。
- 正则化或稳定训练技巧:子滤波器的归一化是关键的稳定技巧。加权协方差矩阵V的递归更新(式(7))本身也具有平滑和正则化作用。
📊 实验结果
主要实验设置与结果:
- 场景:6x6平面麦克风阵列,2个目标声源,5个噪声源+白噪声。
- 指标:信干比改善(SIR improvement)和信号失真比改善(SDR improvement)。
- 对比方法:AuxIVA, OverIVA, 提出的BiIVA。
- 关键结果(来自图1):
- 收敛速度:OverIVA初始SIR提升最快(5秒内达~20dB), BiIVA稍慢但最终超过。AuxIVA最慢。
- 稳态性能:BiIVA表现最佳, SDR峰值接近20dB, SIR超过30dB。OverIVA的SDR约10dB, SIR约20dB。AuxIVA的SDR约8dB, SIR约14dB。BiIVA相比OverIVA,在SIR和SDR上均有约10dB的优势。
- 定性结果(图2语谱图):清晰展示了AuxIVA干扰抑制不足, OverIVA有轻微失真(白框处),而BiIVA输出最干净,有效保留了目标语音。
- 消融实验:论文未提供针对双线性分解各部分(如M1, M2选择、初始化策略)的消融研究。
- 细分结果:未提供不同信噪比、混响时间下的细分结果。
实验结果表格:论文中未提供数值表格,结果以曲线图(图1)和语谱图(图2)形式呈现。
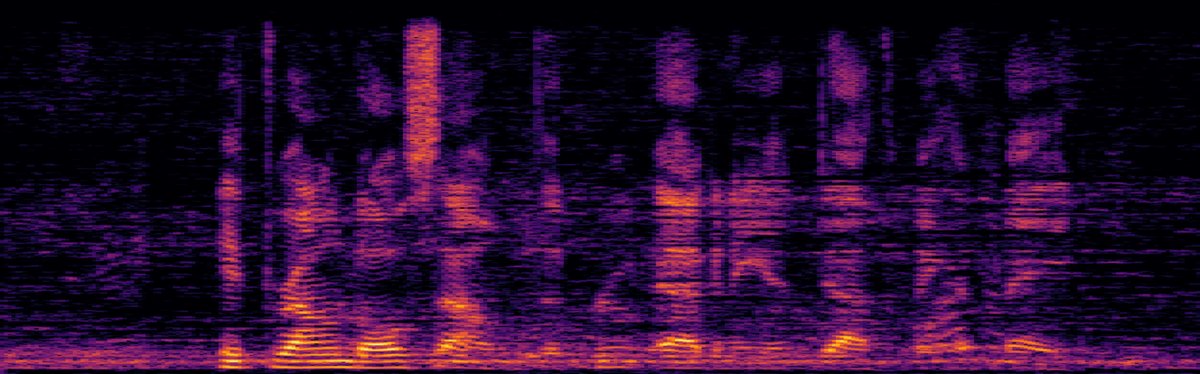 图1显示了三种算法的平均SIR改善(a)和SDR改善(b)随时间变化曲线。BiIVA(绿色)在收敛后性能显著优于OverIVA(红色)和AuxIVA(蓝色)。
图1显示了三种算法的平均SIR改善(a)和SDR改善(b)随时间变化曲线。BiIVA(绿色)在收敛后性能显著优于OverIVA(红色)和AuxIVA(蓝色)。
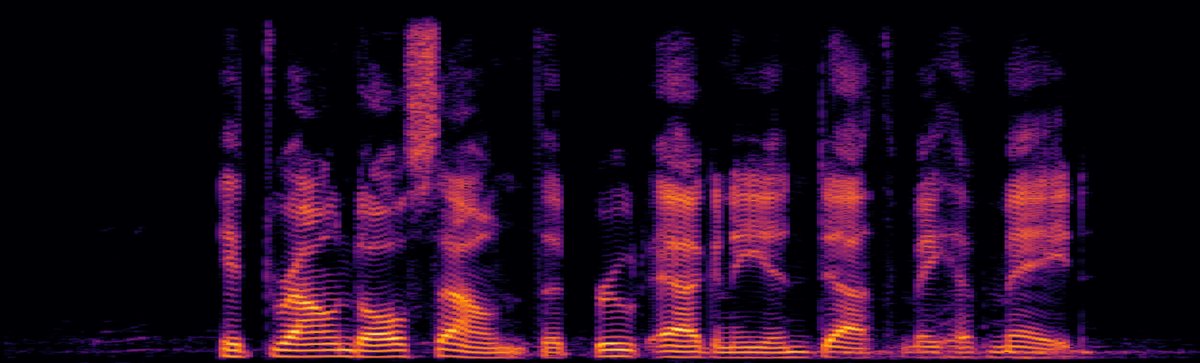 图2展示了原始观测、目标语音以及三种算法分离后信号的语谱图。BiIVA的输出最接近目标,干扰抑制最彻底。
图2展示了原始观测、目标语音以及三种算法分离后信号的语谱图。BiIVA的输出最接近目标,干扰抑制最彻底。
⚖️ 评分理由
- 学术质量:6.0/7。论文创新点明确、技术推导严谨、实验设计合理且结果支撑结论。但创新属于对现有框架的改进而非范式革新,且缺乏对算法计算复杂度的深入分析和与更广泛基线的对比。
- 选题价值:1.5/2。解决了阵列信号处理中一个实际且重要的问题(大型阵列在线BSS),具有明确的工业应用前景。问题虽然不够“热门”,但足够坚实。
- 开源与复现加成:-0.5/1。论文未提供任何代码、模型或可直接复现的详细数据集信息,严重阻碍了结果的验证和方法的实际应用。