📄 RMODGDF: A Robust STFT-Derived Feature for Musical Instrument Recognition
#音乐信息检索 #时频分析 #音频分类 #鲁棒性 #基准测试
✅ 7.0/10 | 前50% | #音乐信息检索 | #时频分析 | #音频分类 #鲁棒性
学术质量 5.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Hao ZHOU(南开大学软件学院)
- 通讯作者:Binhui WANG(南开大学创新与智能设计中心 I²DC, 南开大学软件学院)、Haining ZHANG(南开大学软件学院, 天津市软件体验与人机交互重点实验室)
- 作者列表:Hao ZHOU(南开大学软件学院;天津市软件体验与人机交互重点实验室)、Zhen LI(独立研究者)、Binhui WANG(南开大学软件学院;创新与智能设计中心 I²DC)、Haining ZHANG(南开大学软件学院;天津市软件体验与人机交互重点实验室)
💡 毒舌点评
论文核心亮点在于巧妙地将“对数变换提升梅尔频谱图性能”的思路迁移到相位特征上,提出了RMODGDF,并提供了严谨的统计检验来证明其有效性。然而,其短板在于创新幅度较小,本质上是已有MODGDF的一个简单数学变换(加log),且仅在单一CNN模型上验证,未能探索其与更先进的Transformer模型结合的可能性,也未开源代码,限制了社区的快速验证与应用。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开模型权重。使用的预训练模型(ConvNeXt-V2 Base)权重来自Facebook公开的Hugging Face库。
- 数据集:IRMAS和ChMusic是公开可获取的数据集(论文中提供了引用)。
- Demo:未提供在线演示。
- 复现材料:论文详细给出了STFT参数、特征提取公式、模型架构选择、训练策略(优化器、学习率调度、早停)、数据集划分比例和数据增强方法,这些信息对于复现实验是充分的。但缺少具体的命令行参数、配置文件或检查点信息。
- 论文中引用的开源项目:主要依赖了公开的ConvNeXt-V2预训练模型(来自Facebook)。
📌 核心摘要
- 问题:当前主流音乐乐器识别方法严重依赖幅度谱特征(如Log-Mel频谱图),而丢弃了可能包含时域结构、瞬态和音色关键信息的相位信息。
- 方法核心:提出“反射修正群延迟函数(RMODGDF)”,通过对修正群延迟函数(MODGDF)施加对数变换(
sign(τ) * log(1 + |τ|^α))来压缩动态范围、增强判别性特征,类比于从梅尔频谱图到对数梅尔频谱图的成功演进。 - 与已有方法相比的新颖性:与直接使用原始相位(Cos+Sin分量)或未做对数变换的MODGDF相比,RMODGDF是一种更结构化、更鲁棒的相位信息表示方法。它首次系统地将对数压缩这一关键操作应用于群延迟特征,旨在提升其在分类任务中的判别力。
- 主要实验结果:在IRMAS(西方乐器)和ChMusic(中国民族乐器)两个数据集上,使用ConvNeXt-V2 Base模型进行评估。RMODGDF在所有指标上均优于Log-Mel频谱图基线、原始相位组合及MODGDF。关键数据见下表:
| 特征表示 | IRMAS AUROC (%) | IRMAS 准确率 (%) | ChMusic AUROC (%) | ChMusic 准确率 (%) |
|---|---|---|---|---|
| Log-Mel Spectrogram | 98.717 ± 0.203 | 89.291 ± 0.937 | 99.520 ± 0.320 | 92.271 ± 1.199 |
| MODGDF | 98.674 ± 0.387 | 89.167 ± 1.083 | 99.498 ± 0.308 | 91.449 ± 2.840 |
| RMODGDF (本文) | 99.299 ± 0.157 | 91.496 ± 1.564 | 99.747 ± 0.184 | 93.023 ± 1.526 |

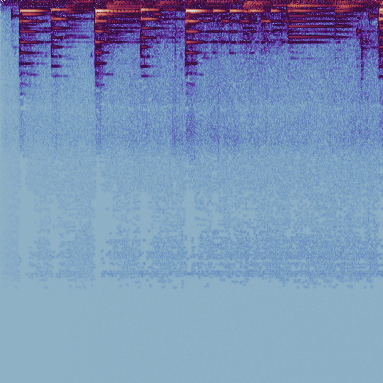 图1和图2(论文中标为Fig. 1与Fig. 2)展示了MODGDF与RMODGDF特征图的视觉对比。RMODGDF的对数变换增强了低能量区域的细节,同时保持了高能量区域的判别性,整体对比度更优。
图1和图2(论文中标为Fig. 1与Fig. 2)展示了MODGDF与RMODGDF特征图的视觉对比。RMODGDF的对数变换增强了低能量区域的细节,同时保持了高能量区域的判别性,整体对比度更优。
- 实际意义:为音频特征表示(尤其是相位信息利用)提供了一个简单、原理清晰且有效的改进方案,对提升MIR相关任务性能有潜在价值。
- 主要局限性:方法创新局限于对已有特征的简单数学变换;评估仅使用单一CNN模型(ConvNeXt-V2),未与更先进的Transformer模型对比;未提供代码,部分统计显著性结果为边际显著(p<0.10)。
🏗️ 模型架构
本文的核心贡献是特征表示(RMODGDF),而非一个新的深度学习模型架构。实验所用的模型架构是现成的ConvNeXt-V2 Base。
- 完整输入输出流程:输入音频波形 → STFT计算得到复数谱 → 提取特定特征(如RMODGDF, 生成为与图像兼容的2D时频表示) → 预训练的ConvNeXt-V2骨干网络处理特征图 → 添加线性分类头 → 输出乐器类别概率。
- 主要组件:
- 特征提取器:根据公式(1)-(4),从STFT中计算出所需的特征。关键组件是MODGDF计算(公式3)和后续的“反射”对数变换(公式4)。
- 分类器:采用ConvNeXt-V2 Base模型,这是一个在ImageNet-22K上预训练的卷积神经网络。为处理单通道或双通道输入特征(如RMODGDF是单通道,Cos+Sin of Phase是双通道),通过零填充扩展通道数以匹配模型预训练时的三通道输入。
- 数据流:原始波形 → STFT → 特征图(RMODGDF)→ ConvNeXt-V2特征提取 → 全局平均池化 → 线性分类层 → 预测。
- 关键设计选择:选择单一、强大的现有分类模型是为了确保性能差异源于输入特征的不同,而非模型架构差异,这是一种标准的消融实验设计。对数变换的应用是核心,旨在模仿Log-Mel频谱图的成功经验,压缩特征动态范围,增强低能量细节的表示。
💡 核心创新点
- 提出RMODGDF特征表示:这是论文最核心的贡献。通过对MODGDF进行对数变换,创建了一个新的、更鲁棒的相位特征表示。
- 局限:RMODGDF直接建立在已有的MODGDF之上,其核心创新是引入了“对数压缩”这一操作,创新幅度有限。
- 作用:压缩群延迟值的动态范围,突出低能量区域的判别性信息,使特征分布更接近对数梅尔频谱图的成功范式。
- 收益:在乐器识别任务中,RMODGDF在AUROC等关键指标上取得了统计显著的提升。
- 系统性地验证并强调相位信息的价值:通过将原始相位(Cos+Sin)、MODGDF和RMODGDF与仅使用幅度的Log-Mel频谱图进行对比,论文实证了相位信息中包含对乐器识别有益的互补线索。
- 局限:此前已有工作(如引用[8][9])探索过相位信息,本文并非首次关注。
- 作用:通过严谨的对比实验,强化了“有效利用相位可以提升性能”这一观点。
- 收益:为MIR领域的特征工程提供了新的研究方向。
- 提出“Reflect”操作解决相位特征表示问题:公式(4)中的
sign(τ) * log(1 + |τ|^α)操作。- 局限:这是一个技术性改进,旨在让对数函数能处理负值并避免零点奇点,非概念性突破。
- 作用:在保留群延迟符号信息(正/负值)的前提下,进行非线性幅度压缩。
- 收益:使得RMODGDF成为一个有效的、可直接输入神经网络的单通道特征图。
🔬 细节详述
- 训练数据:
- 数据集:IRMAS(西方乐器, 11类, 3秒片段, 多声部)和ChMusic(中国传统乐器, 11类, 3秒片段, 单声部)。
- 划分:IRMAS使用70%/10%/20%的训练/验证/测试集;ChMusic使用60%/20%/20%。
- 数据增强:在IRMAS训练集上使用了随机2-mix(两段音频混合)。
- 预处理:STFT和特征提取参数被设置为能生成与384x384输入分辨率兼容的特征图。
- 损失函数:未明确说明,但根据任务性质,应为交叉熵损失(标准分类任务)。
- 训练策略:
- 优化器:AdamW。
- 学习率调度:余弦学习率调度,1个epoch的预热期。
- Batch size:未说明。
- 最大轮数:100 epochs。
- 早停:如果验证损失连续10个epoch不下降,则停止训练,并使用最佳验证损失对应的模型检查点。
- 独立运行:每个设置使用不同的随机种子进行5次独立运行,结果报告均值±标准差,并进行配对t检验。
- 关键超参数:
- MODGDF参数:γ = 0.9, α = 0.4(基于经验设置)。
- 输入分辨率:384 × 384。
- 分类头:线性层,输出神经元数等于数据集中的乐器类别数(IRMAS为11,ChMusic为11)。
- 训练硬件:未说明。
- 推理细节:未说明(推测为标准前向传播)。
- 正则化或稳定训练技巧:早停机制。
📊 实验结果
实验在两个数据集上验证了RMODGDF的有效性,关键结果总结如下:
表1. IRMAS数据集实验结果
| 特征表示 | 准确率(%) | 精确率(%) | 召回率(%) | 宏观F1(%) | AUROC(%) |
|---|---|---|---|---|---|
| Log-Mel Spectrogram (Baseline) | 89.291 ± 0.937 | 89.532 ± 0.943 | 89.291 ± 0.937 | 89.257 ± 1.000 | 98.717 ± 0.203 |
| MODGDF | 89.167 ± 1.083 | 89.152 ± 1.243 | 89.167 ± 1.083 | 89.014 ± 1.195 | 98.674 ± 0.387 |
| Cos + Sin of Phase | 72.393 ± 1.796 | 73.094 ± 1.277 | 72.393 ± 1.796 | 72.263 ± 1.483 | 93.676 ± 0.497 |
| RMODGDF (Proposed) | 91.496 ± 1.564 | 91.588 ± 1.439 | 91.496 ± 1.564 | 91.431 ± 1.505 | 99.299 ± 0.157 |
表2. ChMusic数据集实验结果
| 特征表示 | 准确率(%) | 精确率(%) | 召回率(%) | 宏观F1(%) | AUROC(%) |
|---|---|---|---|---|---|
| Log-Mel Spectrogram (Baseline) | 92.271 ± 1.199 | 92.523 ± 0.454 | 92.271 ± 1.199 | 91.633 ± 0.852 | 99.520 ± 0.320 |
| MODGDF | 91.449 ± 2.840 | 91.588 ± 2.876 | 91.449 ± 2.840 | 90.315 ± 3.404 | 99.498 ± 0.308 |
| Cos + Sin of Phase | 67.607 ± 5.325 | 69.080 ± 3.012 | 67.607 ± 5.325 | 65.564 ± 3.807 | 93.497 ± 1.101 |
| RMODGDF (Proposed) | 93.023 ± 1.526 | 94.069 ± 0.520 | 93.023 ± 1.526 | 92.782 ± 1.065 | 99.747 ± 0.184 |
图1:MODGDF特征图可视化。
图2:RMODGDF特征图可视化。对比图1,RMODGDF的图像动态范围更均衡,低亮度(低能量)区域的细节更清晰,有助于模型学习。
关键结论与消融分析:
- RMODGDF 全面优于基线:在两个数据集的所有评估指标上,RMODGDF均取得最佳结果。在IRMAS的AUROC上,RMODGDF(99.299%)比Log-Mel基线(98.717%)高出0.58个百分点,统计显著(p=0.0069, Cohen’s d=2.29)。
- 对数变换(Reflect操作)有效:RMODGDF与MODGDF的对比构成了对“Reflect”操作的消融研究。结果表明,对数变换带来了显著的性能提升(例如,IRMAS上AUROC提升0.62个百分点, p=0.0103)。
- 原始相位特征效果差:“Cos + Sin of Phase”性能远低于其他所有方法,证明了直接使用原始相位分量效果不佳,需要结构化处理(如MODGDF或RMODGDF)。
- 跨数据集泛化性:RMODGDF在多声部的西方乐器(IRMAS)和单声部的中国传统乐器(ChMusic)上均表现优异,展示了良好的泛化能力。
⚖️ 评分理由
- 学术质量:5.0/7:论文提出了一个清晰、合理的改进(RMODGDF),实验设计严谨(控制变量、统计检验、多数据集验证),结论可信。然而,创新是渐进式的(在MODGDF上加log),技术深度一般,且仅在单一CNN模型上验证,未能探索与更先进架构(如Transformer)的结合。
- 选题价值:1.5/2:音乐乐器识别是MIR中的基础且实用任务。论文聚焦于“如何更好地利用相位信息”这一具体技术点,对相关领域的特征工程有参考价值。但整体话题并非当前最前沿的热点(如生成式AI、多模态大模型)。
- 开源与复现加成:0.5/1:论文详细公开了所有实验设置、数据集信息、模型配置和超参数,使得方法逻辑完全清晰。但没有提供任何代码、模型权重或可直接运行的脚本,大大降低了社区复现和应用的便利性。