📄 Retrieval-Based Speculative Decoding For Autoregressive Speech Synthesis
#语音合成 #检索式推测解码 #自回归模型 #推理加速 #免训练
✅ 7.0/10 | 前50% | #语音合成 | #检索式推测解码 | #自回归模型 #推理加速
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Alan Chi-Man Lee(香港中文大学)
- 通讯作者:未说明
- 作者列表:Alan Chi-Man Lee(香港中文大学)、Wing-Sun Cheng(RISKSIS)、Calvin Chun-Kit Chan(香港中文大学)
💡 毒舌点评
亮点:论文提出的“检索+过滤接受”框架是一个思路清晰、工程实用性强的解决方案,成功将NLP领域的推测解码思路迁移到语音合成,并针对语音token的模糊性进行了有效适配,在强模型上验证了近30%的无损加速。短板:论文更像一个优秀的工程报告,理论创新有限;关键的实验对比缺失了直接竞争的相关工作(如[8][9]),说服力打了折扣;更重要的是,完全没有开源计划,对于一篇强调“即插即用”的方法论文来说,这几乎是致命缺陷。
🔗 开源详情
论文中未提及任何开源计划。代码、模型权重、数据集(除使用公开LibriTTS外)、Demo或详细复现指南均未提供。论文中引用的开源项目包括CosyVoice 2 [4]、LibriTTS [11]、ERes2Net [12] 和 UTMOS [13]。
📌 核心摘要
- 要解决什么问题:自回归语音合成(TTS)模型质量高但推理速度慢,因为其逐token生成的顺序性造成了严重的计算瓶颈。
- 方法核心是什么:提出一种免训练的“检索式推测解码”框架。它不使用一个小型的参数草稿模型,而是从一个预计算的语音token序列数据store中,根据当前上下文检索出候选续写序列(草稿)。然后,通过树注意力机制在目标模型中并行验证这些草稿,并采用一种结合概率匹配与重复感知的“过滤接受”逻辑来选择最终输出。
- 与已有方法相比新在哪里:与参数草稿模型(如Medusa)相比,它是免训练且即插即用的。与通用的检索推测解码(如REST)相比,它是首次应用于语音合成,并专门设计了处理语音token模糊性的接受策略。与此前的语音推测解码工作相比,它采用非参数检索而非参数草稿,并提出了更稳健的接受机制。
- 主要实验结果:在CosyVoice 2模型上,使用通用数据store可实现约19%的单token生成时间(TPT)缩减;使用针对特定说话人的数据store,可实现高达30%的TPT缩减,同时语音质量(SIM, MOS)、内容准确率(WER)与原始模型持平。关键消融实验数据如下表所示:
| 方法(c: 候选数,τ: 容忍度) | SIM ↑ | WER ↓ | MOS ↑ | LM-RTF ↓ | TPT ↓ |
|---|---|---|---|---|---|
| 基线 (原始 CosyVoice 2) | 78.87 | 3.34 | 4.37 | 0.2034 | 6.30 |
| 本文 (c=16, τ=512, 通用) | 78.74 | 3.39 | 4.38 | 0.1692 | 5.13 |
| 本文 (c=16, τ=512, 说话人特定) | 79.15 | 3.37 | 4.41 | 0.1488 | 4.41 |
- 实际意义是什么:提供了一种无需修改模型、无需额外训练的加速方案,可直接应用于现有自回归TTS系统,对降低实时语音合成服务的延迟和成本有直接帮助。
- 主要局限性是什么:方法的加速效果高度依赖于数据store的覆盖度和匹配度(说话人特定场景效果更好);论文未与最新的语音推测解码工作进行直接对比;缺乏开源代码与模型,限制了实际复现与应用。
🏗️ 模型架构
本文并非提出一个新的生成模型,而是提出了一个加速现有自回归TTS模型推理的推测解码框架。其整体架构与流程如下:
主要组件及数据流:
- 数据store (Datastore):离线构建。使用目标TTS模型本身,在大量音频-文本对上生成语音token序列,并将其索引为“上下文-续写”对。这构成了检索的候选库。
- 上下文检索与Trie构建:在线阶段。给定当前已生成的token序列(上下文),在数据store中进行贪心精确后缀匹配,检索出所有匹配的候选续写序列。这些候选序列被组织成一个Trie树,树中每个节点根据其出现频率加权,并剪枝保留top-c条最常见前缀路径作为最终草稿。
- 并行验证:通过树注意力机制,将整个候选Trie展平为一个序列,用特殊的注意力掩码(
Mtree)确保每个节点只能关注其Trie中的祖先节点和原始上下文。目标TTS模型进行一次前向传播,同时计算出Trie中所有节点位置的logits,即模型对每个位置下一个token的概率分布。 - 过滤接受逻辑:对每个候选路径,逐token检查:
- 概率匹配:从模型当前输出的logits中进行top-p采样,生成一个验证集。候选token若在该验证集中则通过。
- 重复感知:检查候选token是否在最近的窗口(大小为w)内出现过于频繁(超过阈值 τr)。 同时满足两个条件的token才会被接受。框架选择接受长度最长的路径作为最终输出。
关键设计选择:
- 使用Trie而非列表:高效地组织和修剪大量候选序列,避免冗余。
- 树注意力:实现了一次前向传播验证多个序列的核心加速。
- 过滤接受:结合概率匹配和重复惩罚,平衡了语音的合理模糊性与生成的稳定性。
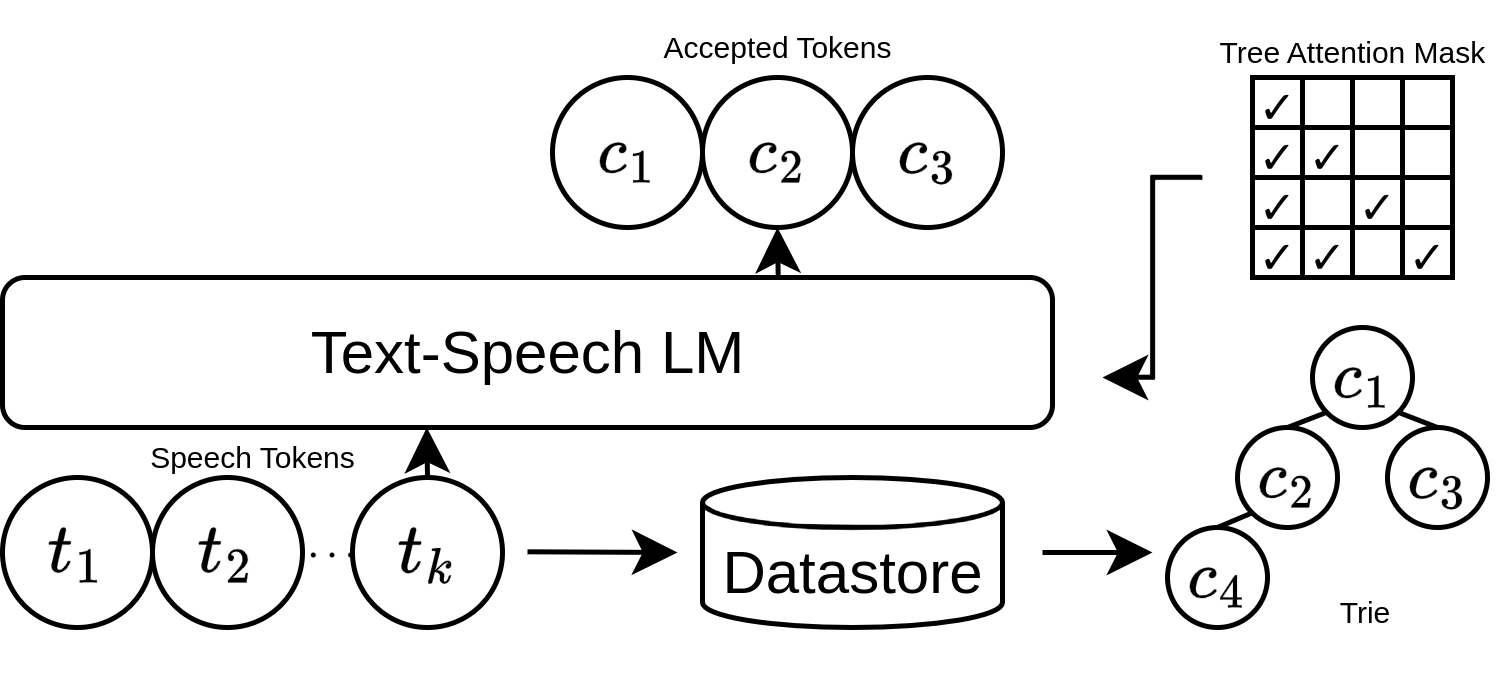 图1展示了框架概览:当前生成的上下文被用于查询语音token数据store。检索出的序列构成一个候选Trie,然后通过树注意力被目标LLM并行验证。
图1展示了框架概览:当前生成的上下文被用于查询语音token数据store。检索出的序列构成一个候选Trie,然后通过树注意力被目标LLM并行验证。
💡 核心创新点
- 首次将检索式推测解码应用于自回归语音合成:将NLP领域(如REST)的免训练加速思路迁移至语音领域,为TTS推理加速提供了一种新的、无需修改模型的“插件式”方案。
- 针对语音特性的过滤接受机制:这是方法的核心适应性创新。传统的“一对一”匹配对语音token过于严格,因为声学上的相似性。本文的多样本概率匹配(通过τ=512采样形成验证集)承认了语音生成的合理多样性,而重复感知则专门抑制了自回归模型常见的重复性伪影,确保了输出质量。
- 说话人特定数据store的有效性:验证了在工业部署常见场景(固定说话人)下,构建专属数据store能极大提升草稿准确性,从而将加速效果从
19%提升至30%,具有很强的实用指导意义。
🔬 细节详述
- 训练数据:论文未说明数据store构建所用文本语料的具体规模、来源和预处理细节,仅提及使用了LibriTTS的“train-clean-100”子集。
- 损失函数:本文方法免训练,不涉及损失函数设计。
- 训练策略:免训练。
- 关键超参数:
- 目标模型:CosyVoice 2(24层Transformer LM)。
- 数据store剪枝:候选路径数
c(实验值为8, 16, 32)。 - 过滤接受参数:容忍度采样数
τ(实验值为2, 16, 128, 512),nucleus采样p=0.8,重复检查窗口w=10,重复阈值τr=0.1。
- 训练硬件:未说明(论文仅提及实验在单张NVIDIA RTX 4090 GPU上进行)。
- 推理细节:
- 检索策略:贪心精确后缀匹配,最大匹配长度
nmax未具体说明,但会递减直到找到匹配。 - 树注意力:将Trie展平并构造专用掩码。
- 解码策略:论文未明确说明目标模型本身的采样策略(如温度、top-k),仅描述了过滤接受阶段的参数。
- 检索策略:贪心精确后缀匹配,最大匹配长度
- 正则化或稳定训练技巧:不适用。
📊 实验结果
主要实验在CosyVoice 2模型和LibriTTS数据集上进行,评估了速度与质量。
候选数(c)消融实验(τ固定为512): 如“核心摘要”中的表格所示,当
c=8或16时,TPT从基线的6.30ms降至5.13ms(约19%加速),且质量指标(SIM, WER, MOS)与基线持平。当c=32时,加速效果消失(TPT=6.21ms),因为验证更大Trie的开销超过了收益。容忍度(τ)消融实验(c固定为16): 论文未提供此实验的表格,但文字描述关键结果:
τ=2(极严格):接受率低,推理反而比基线慢(LM-RTF=0.2372 > 0.2034)。τ=512(宽松):达到最佳加速(LM-RTF降至0.1692),同时质量稳定。证明了宽容的接受机制对语音合成至关重要。
说话人特定数据store实验: 如“核心摘要”中的表格所示,使用针对每个测试说话人构建的专属数据store,取得了最佳结果:TPT降至4.41ms(比基线快30%),且所有质量指标均优于或等于基线。
关键结论:
- 框架能有效加速推理,且在合适超参数下无质量损失。
- 加速效果高度依赖于草稿的准确度(
c需适中)和接受策略的宽容度(τ需足够大)。 - 数据store与目标说话人的匹配度(说话人特定)是进一步提升加速效果的关键。
⚖️ 评分理由
- 学术质量:5.5/7。创新是将检索式推测解码成功应用于语音合成并进行了针对性设计(过滤接受),技术路线清晰且有效。实验设计合理,消融研究充分。但创新高度依赖既有框架的迁移,且缺少与最前沿相关工作的直接对比,理论贡献有限。
- 选题价值:1.5/2。解决的是语音合成落地中的关键痛点——推理延迟。提出的免训练方案对产业界具有明确吸引力,尤其在固定说话人场景下潜力显著。对语音合成领域的研究者和工程师有较高参考价值。
- 开源与复现加成:0/1。论文完全未提及开源代码、模型权重或详细的复现材料,这是一个重大缺陷,严重影响其可复现性和实际影响力。