📄 Rethinking Music Captioning with Music Metadata LLMS
#音乐理解 #多模态模型 #大语言模型 #数据集
✅ 7.0/10 | 前25% | #音乐理解 | #多模态模型 | #大语言模型 #数据集
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 中
👥 作者与机构
- 第一作者:Irmak Bukey(卡内基梅隆大学,工作在Adobe Research实习期间完成)
- 通讯作者:未说明
- 作者列表:Irmak Bukey(卡内基梅隆大学 / Adobe Research实习)、Zhepei Wang(Adobe Research)、Chris Donahue(卡内基梅隆大学)、Nicholas J. Bryan(Adobe Research)
💡 毒舌点评
亮点在于巧妙地将结构化元数据作为“中间表示”,解耦了音乐理解与文本生成,带来了训练效率和风格灵活性的双重提升,这个思路比端到端黑箱训练更可解释、更可控。短板是实验对比的基线强度存疑(用相同元数据合成的caption训练端到端模型),且严重缺乏开源信息,对于想跟进复现的研究者极不友好。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开权重。
- 数据集:核心训练集为未公开的内部授权数据集。评估使用了公开的MusicCaps和Song Describer数据集。
- Demo:未提及。
- 复现材料:论文未提供完整的训练细节(如优化器、学习率、batch size等)、配置文件或检查点信息。附录说明缺失。
- 引用的开源项目:论文引用了Gemma3-1B-it [29]、DAC [30]、Sentence-BERT [32] 等开源模型/工具,但未说明是否依赖其他未列出的开源代码库。
- 总结:论文中未提及开源计划。
📌 核心摘要
- 问题:训练音乐描述(Music Captioning)模型需要高质量、自然语言的描述数据,这类数据稀缺且获取成本高。相比之下,结构化元数据(如流派、情绪等)更易获得。现有方法常用LLM将元数据合成为描述用于训练,但这会固定风格并混淆事实与表达。
- 方法核心:提出“音乐元数据LLM”两阶段方法。第一阶段:微调一个预训练LLM(Gemma3-1B-it),使其能从音频(和可选的部分元数据)中预测出完整的结构化元数据(JSON格式)。第二阶段:在推理时,使用同一个预训练的文本LLM,通过精心设计的提示,将预测出的元数据转换成自然语言描述。
- 新颖性:与直接训练“音频->描述”的端到端模型不同,本方法引入了结构化元数据作为中间层,实现了理解与生成的解耦。这带来了三个关键优势:(a) 训练更高效(仅需约46%的GPU时间);(b) 可在推理后通过修改提示灵活调整输出描述的风格和细节;(c) 能够执行“元数据填充”任务,即利用音频和部分已知元数据补全缺失字段。
- 主要实验结果:在元数据预测和描述生成任务上,本方法性能与端到端基线相当(表1,表2)。关键优势体现在:(a) 通过优化提示(如加入1-shot样例),描述质量可无须重新训练提升超过20%(表3);(b) 当提供部分元数据时,元数据预测性能平均提升21%,最高达33%(表4)。具体关键数据见下方表格。
- 表1:元数据预测性能(SBERT相似度)
模型 流派 情绪 乐器 关键词 平均 MC描述器 0.556 0.673 0.677 0.614 0.630 SD描述器 0.562 0.687 0.676 0.618 0.636 元数据(本方法) 0.548 0.711 0.675 0.566 0.625 - 表2:描述生成评估(SBERT相似度)
风格 模型 MusicCaps Song Describer 平均 匹配 描述器 0.478 0.468 0.407 匹配 元数据(本方法) 0.443 0.454 0.392 交叉 描述器 0.441 0.469 0.405 交叉 元数据(本方法) 0.439 0.462 0.395 - 表3:不同提示对描述性能的影响(综合平均)
方法 SBERT-Sim BM25 长度 POS 平均 描述器(基线) 0.473 0.141 0.208 0.765 0.396 元数据(本方法) 0.449 0.156 0.185 0.735 0.381 元数据 + 较短提示 0.457 0.132 0.243 0.741 0.393 元数据 + 固定1-shot 0.475 0.125 0.366 0.741 0.426 元数据 + 元数据1-shot 0.483 0.181 0.369 0.733 0.442 - 表4:部分元数据填充性能(SBERT分数,%表示可用字段比例)
模型 % 流派 情绪 乐器 关键词 Gemma3-1b 50% 0.504 0.666 0.657 0.543 Ours 0% 0.548 0.711 0.675 0.566 Ours 25% 0.638 0.743 0.754 0.618 Ours 50% 0.679 0.765 0.780 0.645 Ours 75% 0.715 0.789 0.807 0.671 Ours 100% 0.731 0.798 0.817 0.686
- 表1:元数据预测性能(SBERT相似度)
- 实际意义:提供了一种更灵活、高效且可解释的音乐描述方案。其元数据填充能力对整理大型音乐库、补全不完整标签极具价值;风格后定制能力使其能适应不同应用场景的输出需求。
- 主要局限性:模型训练依赖一个未公开的内部授权音乐数据集,影响了可复现性和外部验证。与基线对比时,由于基线模型使用了同一套元数据合成的训练数据,这可能削弱了方法优越性的证明力度。此外,论文未公开代码、模型或详细超参数,完全不可复现。
🏗️ 模型架构
本文提出的“音乐元数据LLM”采用两阶段解耦架构:
整体输入输出流程:
- 输入:一段10秒的音乐音频(随机截取) + 可选的部分已知元数据(JSON格式)。
- 中间表示:完整的结构化元数据(JSON格式),包含流派、情绪、乐器、关键词等多个字段。
- 输出:一段自然语言的音乐描述文本。
主要组件及数据流:
音频编码器:
- 功能:将原始音频波形转换为离散的音频令牌(tokens)序列。
- 结构与细节:基于DAC(Descript Audio Codec)的神经音频自编码器,但采用了更激进的时域下采样。编码器输出32个通道,帧率为21 Hz,随后通过一个大小为1024的码本进行量化,得到离散的音频令牌。
- 交互:编码器的输出被映射到语言模型(LLM)中预留的文本令牌空间,使LLM能够处理音频输入。
元数据预测模型(核心阶段一):
- 功能:从音频令牌(和可选的部分元数据提示)中预测出完整的、结构化的音乐元数据。
- 结构与基础模型:基于预训练的解码器-only文本大语言模型Gemma3-1B-it。通过两阶段微调适配音频任务。
- 阶段一(多模态适应):在自监督的音频-语言续写任务上进行联合微调,使文本LLM获得理解音频令牌序列的能力,得到一个音频-文本多模态LLM(MLLM)。
- 阶段二(指令微调):在音乐元数据预测任务上进行指令微调。训练数据为(音频, 元数据JSON)对。模型被训练以结构化格式预测元数据字段,同时保持已提供字段不变。这使其能够执行“元数据填充”任务。
- 交互:推理时,输入音频令牌和一个空的或部分填充的元数据字典。模型生成完整的JSON格式元数据。
元数据到描述转换器(核心阶段二):
- 功能:将阶段一预测出的结构化元数据(JSON)转换成流畅、自然的语言描述。
- 结构与基础模型:直接使用原始的预训练文本LLM(Gemma3-1B-it),无需任何额外微调。
- 交互:通过精心设计的文本提示指令,引导LLM基于提供的元数据字段生成描述,并避免“幻觉”(即编造元数据中不存在的信息)。提示工程的灵活性是本方法的关键优势,可以通过调整提示(如添加上下文学习样例)来控制输出描述的风格、详细程度等。
元数据填充模块:
- 功能:利用上述架构完成对不完整元数据的补全。
- 实现:训练时,在元数据JSON中随机屏蔽部分字段;推理时,提供音频和部分已知字段的元数据。模型被训练并用于预测出完整的元数据集合。
架构图说明:
论文中的图1展示了该方法与传统方法的对比。
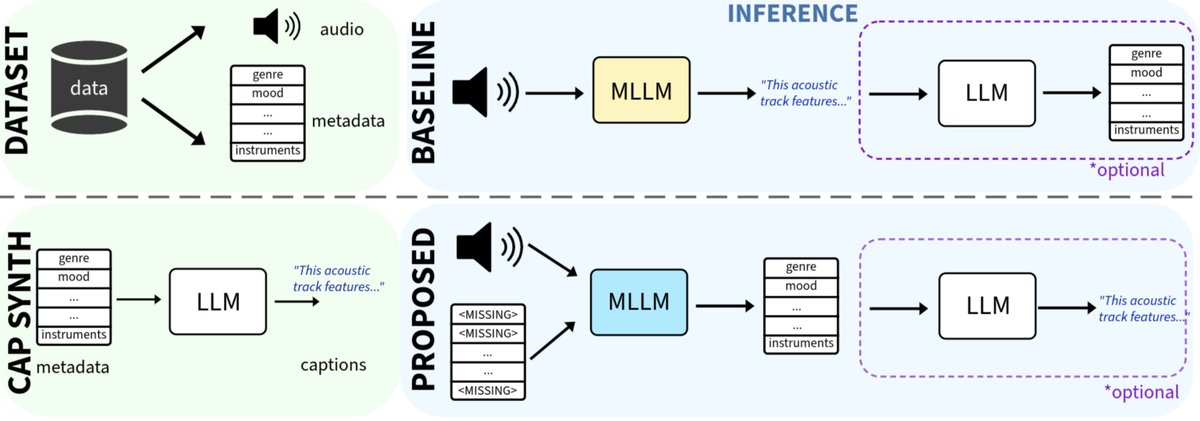
- 右下角:本文提出的“Metadata MLLM”推理流程。输入音频和可选的部分元数据。模型首先输出完整的结构化元数据(可选)。然后,一个文本LLM(可选地)将元数据转换为所需风格的自然语言描述。这体现了两阶段解耦和灵活性。
- 右上角:典型的端到端“Caption MLLM”流程。输入音频,模型直接生成描述。之后可选地用文本LLM从描述中提取元数据。
- 左下角:展示了如何用文本LLM将已有的元数据合成为训练描述数据,这是传统端到端模型常见的训练数据构建方法。
- 左上角:展示了本文方法使用的训练数据格式(音频-元数据对)。
💡 核心创新点
- 解耦音乐理解与文本生成:首次将音乐描述任务明确分解为“音频->结构化元数据”和“元数据->自然语言描述”两个阶段。这打破了传统端到端“黑箱”模型的范式,使中间表示(元数据)可解释、可编辑,实现了训练和推理的灵活性。
- 元数据填充能力:通过训练模型从不完整的元数据中预测完整集合,本方法天然支持“元数据填充”任务。这是端到端描述模型难以实现的,因为它直接针对结构化数据进行操作,对音乐数据库整理等实际应用极具价值。
- 后处理风格定制:由于第二阶段(元数据->描述)是在推理时通过LLM提示实现的,因此可以在不重新训练模型的情况下,通过修改提示(如加入不同风格的示例)来灵活调整输出描述的风格、语气、详细程度等。实验表明,优化提示可使性能显著提升(>20%),而对端到端模型的输出进行后编辑则效果甚微。
- 提升训练效率:由于模型核心是微调一个1B参数的LLM进行相对简单的元数据预测任务(相比于生成复杂的自然语言序列),其训练收敛更快。论文显示,元数据模型仅需约46.3%的GPU时间即可达到与端到端模型相当的性能。
🔬 细节详述
- 训练数据:
- 数据集:一个未公开的内部授权纯器乐(instrumental)音乐数据集。
- 规模:约25,000小时的音乐。
- 标注:包含多个字段的元数据标注,如流派(genre)、情绪(mood)、关键词(keywords)、速度(tempo)、调性(key���、能量(energy)、乐器(instruments)等。
- 数据特点:元数据不完整,有23%的曲目缺失一个或多个字段。
- 预处理:音频从曲目中随机截取10秒的片段作为训练样本。
- 评估数据:
- 元数据预测评估:使用同一内部数据集的5,000首保留子集。
- 描述生成评估:使用公开的MusicCaps数据集(非人声子集,2,185首)和Song Describer数据集(446首)。
- 损失函数:论文未明确提及具体损失函数名称。根据任务性质,元数据预测和文本生成阶段很可能均采用标准的自回归交叉熵损失(预测下一个token)。
- 训练策略:
- 模型基础:Gemma3-1B-it(1B参数的解码器-only文本LLM)。
- 多阶段微调:如上文架构部分所述。
- 训练硬件:4张 NVIDIA A100 GPU。
- 训练步数:使用了早停(early stopping)。元数据模型在161,000步时停止,两个基线描述模型在347,600步时停止。
- 优化器/学习率:论文未说明。
- 关键超参数:
- LLM:Gemma3-1B-it。
- 音频编码器:基于DAC,编码器输出32通道,帧率21 Hz,量化码本大小1024。
- 推理细节:论文未详细说明解码策略(如温度、采样方法、beam size等)。
- 正则化/稳定训练:论文未提及具体的正则化技巧或稳定训练方法。
📊 实验结果
本文在元数据预测和描述生成两大任务上进行了评估,并重点分析了风格灵活性和元数据填充能力。
主要实验结果与对比:
元数据预测性能(表1):
- 在四个语义字段上使用SBERT相似度评估。
- 结论:本方法在平均性能上与基线描述器相当(0.625 vs 0.630/0.636)。在情绪字段上表现最佳(0.711),但在关键词字段上表现较弱(0.566 vs 0.614/0.618)。
模型 流派 情绪 乐器 关键词 平均 MC描述器 0.556 0.673 0.677 0.614 0.630 SD描述器 0.562 0.687 0.676 0.618 0.636 元数据(本方法) 0.548 0.711 0.675 0.566 0.625
描述生成性能(表2):
- 在MusicCaps(MC)和Song Describer(SD)两个数据集上评估,设置“匹配风格”和“交叉风格”两种评估模式。
- 结论:在匹配风格设置下,本方法性能与基线描述器差距不大(平均0.392 vs 0.407)。值得注意的是,“交叉风格”评估显示,用更详细的MusicCaps风格提示来描述Song Describer音频时,性能下降不明显(0.462),反之亦然,说明描述的可迁移性。
风格 模型 MusicCaps Song Describer 平均 匹配 描述器 0.478 0.468 0.407 匹配 元数据(本方法) 0.443 0.454 0.392 交叉 描述器 0.441 0.469 0.405 交叉 元数据(本方法) 0.439 0.462 0.395
风格与提示变体实验(表3):
- 使用四个指标评估:语义相似度(SBERT-Sim)、词汇重叠(BM25)、长度相似度(Length)、句法结构相似度(POS)。
- 核心结论:对本方法的第二阶段提示进行优化(如使用“较短提示”、“固定1-shot样例”、“元数据标签1-shot样例”),可以无须重新训练地显著提升描述的综合质量(平均从0.381提升至0.442,提升约16%)。其中,“元数据1-shot”提示在BM25和长度相似度上表现最佳。
- 对基线描述器的输出进行类似的后编辑提示,效果提升不明显。
方法 SBERT-Sim BM25 长度 POS 平均 描述器(基线) 0.473 0.141 0.208 0.765 0.396 元数据(本方法) 0.449 0.156 0.185 0.735 0.381 元数据 + 较短提示 0.457 0.132 0.243 0.741 0.393 元数据 + 固定1-shot 0.475 0.125 0.366 0.741 0.426 元数据 + 元数据1-shot 0.483 0.181 0.369 0.733 0.442
元数据填充实验(表4):
- 评估当输入部分元数据时,模型补全其他字段的性能(SBERT分数)。
- 结论:提供部分元数据能显著提升预测性能。随着可用字段比例从0%增加到100%,四个字段的性能平均提升21%,最高达33%(乐器字段从0.675提升至0.817)。基线Gemma3-1B模型在50%填充率下的表现远低于本方法在50%时的表现(0.593 vs 0.717平均值),说明专门微调的重要性。
模型 % 流派 情绪 乐器 关键词 Gemma3-1b 50% 0.504 0.666 0.657 0.543 Ours 0% 0.548 0.711 0.675 0.566 Ours 25% 0.638 0.743 0.754 0.618 Ours 50% 0.679 0.765 0.780 0.645 Ours 75% 0.715 0.789 0.807 0.671 Ours 100% 0.731 0.798 0.817 0.686
⚖️ 评分理由
- 学术质量 (5.5/7):创新性良好,提出了一个逻辑清晰、有实际优势的解耦框架。技术路线正确,实验设计涵盖了多个重要维度。主要扣分点在于:1)基线选择可能不够强(同源数据训练),削弱了结论的颠覆性;2)部分关键对比信息(如具体训练时长)未明确量化;3)依赖未公开的内部数据集进行核心实验,外部验证不足。整体证据可信,但说服力有提升空间。
- 选题价值 (1.5/2):音乐描述是一个重要的实用任务。本文的方法不仅提升了任务本身的性能(灵活性和效率),还衍生出“元数据填充”这一高价值的新功能,对音乐信息检索、数据库管理、可控音乐生成均有积极影响。
- 开源与复现加成 (-0.5/1):论文中未提及任何开源计划,包括代码、模型权重、数据集(明确使用未公开的内部数据)。训练细节(优化器、学习率等)也未完整披露。这严重阻碍了研究的可复现性,是一个重大缺陷。