📄 Respire-Mamba C-UNet: Consistency-Trained Autoencoder for High-Fidelity Respiratory Sound Compression
#音频压缩 #一致性训练 #状态空间模型 #远程医疗
✅ 7.0/10 | 前25% | #音频压缩 | #一致性训练 | #状态空间模型 #远程医疗
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Rishabh(德里大学计算机科学系)
- 通讯作者:未说明
- 作者列表:Rishabh(德里大学计算机科学系)、Yogendra Meena(德里理工大学应用数学系)、Dhirendra Kumar(贾瓦哈拉尔·尼赫鲁大学计算机与系统科学学院)、Kuldeep Singh(德里大学计算机科学系)、Nidhi(J.C. Bose科学技术大学 YMCA)
💡 毒舌点评
论文成功地将多个前沿技术(SincConv、U-Net金字塔、Mamba、一致性模型)缝合在一起,在呼吸音压缩任务上取得了令人印象深刻的保真度(CC=1.0000),这是其显著亮点。然而,其核心短板在于压缩比(CR=3.91)相对温和,且论文主要贡献更偏向于“工程整合”而非“理论突破”,此外,关键的消融实验(如表1)中“去掉方差缩放/频率门控”性能反而略好于完整模型,这略显反常,论文未给出充分解释。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用公开的SPRSound系列数据集,但论文未说明具体获取方式。
- Demo:未提供在线演示。
- 复现材料:论文给出了模型架构的文字描述和部分关键参数(如SincConv参数、幂律参数),但缺乏训练细节(优化器、学习率、batch size等),不足以支持完整复现。
- 论文中引用的开源项目:引用了Mamba-SSM([15])作为实现依赖。
📌 核心摘要
- 要解决的问题:慢性呼吸疾病诊断中,数字听诊器录音的高效压缩与高保真重建,以支持可扩展的远程医疗。
- 方法核心:提出Respire-Mamba C-UNet,一个统一的自编码器框架。它结合生理感知的SincConv前端进行特征提取,金字塔UNet进行多尺度编码,以及一个由时间Mamba瓶颈增强的一致性训练UNet进行单步解码重建。
- 与已有方法相比新在哪里:不同于先前工作孤立处理前端、编码、解码,或追求极端压缩比,本文首次将SincConv的生理感知前端、金字塔多尺度表示、Mamba的高效长程建模与一致性训练的单步重建能力整合,共同优化以获得临床级保真度。
- 主要实验结果:在SPRSound 2024基准测试上,模型实现了PRD=0.85%, CC=1.0000, CR=3.91,显著优于现有自编码器和压缩感知基线。消融研究证实了各组件的互补增益。关键对比如下表所示:
方法 PRD (%) CC CR 压缩感知 [10] 50.1 0.8630 3.5 VAE+Transformer [11] 20.5 0.9800 256 卷积自编码器 [9] 22.3 0.9720 222.1 生成式VAE [9] 7.60 0.9757 42.67 压缩感知 [9] 5.30 0.9311 4 本文方法 0.85 1.0000 3.91 - 实际意义:为医疗远程听诊提供了一种高质量、低延迟(单次前向传播)的音频压缩解决方案,有助于推动远程呼吸诊断的普及。
- 主要局限性:压缩比相对较低,未在更广泛的音频或疾病类型数据集上验证;消融实验中个别结果的解读需要更多分析;未提供代码与模型以支持复现。
🏗️ 模型架构
整体架构是一个端到端的自编码器,包含前端、编码器、瓶颈和解码器。
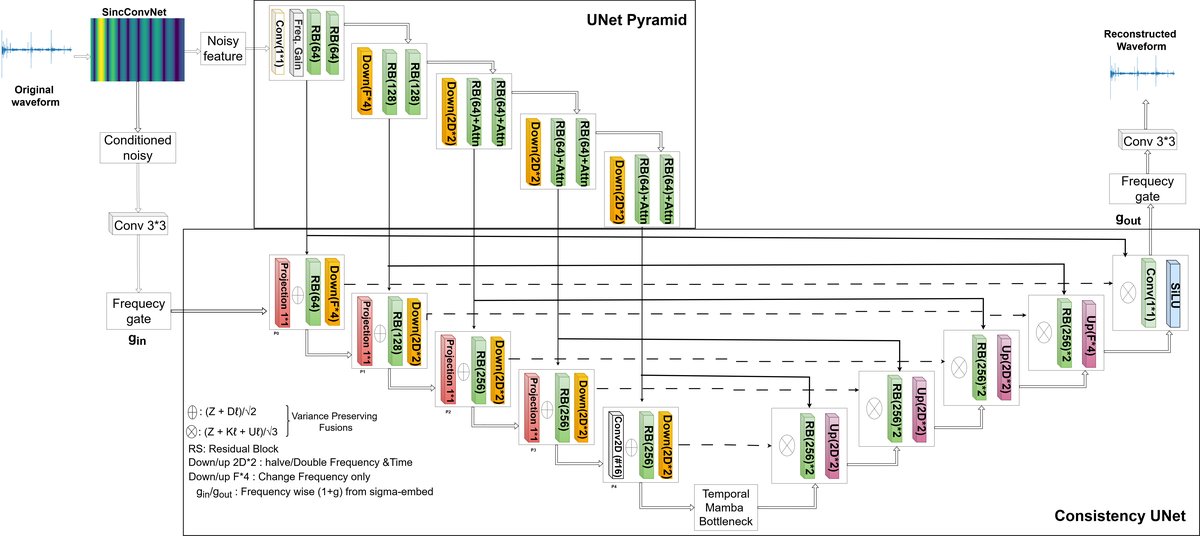
- 音频预处理:原始波形重采样至16kHz,裁剪/填充至固定2秒窗口,进行峰值归一化。
- 特征提取前端 (SincFrontend):
- SincConv:应用一组可学习的带通滤波器(参数化为低/高截止频率)对原始波形进行卷积,输出为频率-时间表示(F=128频段)。这模拟了耳听的生理感知特性。 特征稳定化与缩放:对幅度进行稳定化,使用InstanceNorm进行归一化,然后通过幂律(Power-Law)压缩(x = β (z)^α, α=0.65, β=0.34)增强特征鲁棒性。
- 编码器 (UNetPyramid):
- 接收前端特征(或训练时加入噪声的特征),通过3x3卷积提升通道数。
- 应用可学习的频带增益(Γ)进行初始调制。 包含5个层级,每个层级有2个残差块。通道数随层级增加([1,2,4,4,4]64)。
- 下采样方式交替进行:仅频率下采样或时间-频率联合下采样,构建多尺度金字塔表示。
- 顶层(ℓ≥2)使用自注意力。
- 每个层级的输出作为金字塔特征 Pℓ 传递给解码器。
- 解码器与瓶颈 (ConsistencyUNet with Temporal Mamba):
- 噪声条件注入:训练时向输入特征添加高斯噪声 σε,得到 ˜x。噪声级别 σ 被编码为嵌入向量 e,用于条件化残差块和生成频带门控 (g_in, g_out)。
- 下采样路径:在每一层,当前特征流 Z 与编码器对应的金字塔特征 Pℓ 融合(通过1x1卷积对齐通道,然后方差保持平均 (Z+Dℓ)/√2),再通过条件化残差块处理。
- 时间Mamba瓶颈:在最粗糙尺度,将特征图 Z (C×F×T) 重塑为序列 S (T×D_m),输入多层Mamba状态空间模型进行处理,捕获长程时间依赖。结果以残差方式(因子0.5)加回。
- 上采样路径:镜像编码器。在每个层级ℓ,当前特征Z与两个来源融合:解码器自身跳层特征 Kℓ 和来自编码器金字塔的反转尺度特征 Uℓ = Proj1x1(P_{4-ℓ}),融合方式为 (Z+Kℓ+Uℓ)/√3,再通过条件化残差块。
- 输出门控与头网络:最终特征经过GroupNorm、SiLU激活,由频带门控 (1+g_out) 调制,再通过3x3卷积映射为单通道输出。
- 一致性训练目标: 训练目标是让模型在一次前向传播中直接预测一个混合了干净信号和噪声的目标:y = cskip(σ) x + cout(σ) * ε。 模型输出 ŷ = fθ(cin(σ) ˜x, σ),损失函数为 MSE(ŷ, y)。这使得在推理时,可以直接从带噪输入(或实际数据作为“无噪”输入)一步生成重建。
💡 核心创新点
- 生理感知的前端与幂律缩放:使用可学习的SincConv替代传统Mel频谱,直接从波形中提取具有生理意义的频带特征,并结合幂律压缩,提升了特征表达对呼吸音的适配性。此前方法多用通用音频前端或传统特征。
- 金字塔UNet与跨尺度融合:设计了一个单独的编码器UNet金字塔来提供多尺度特征,并与解码器UNet在不同尺度进行多次融合。这比单一尺度编码器更能捕获从粗到细的呼吸音结构。
- 一致性训练的Mamba-UNet单步解码器:将一致性模型(Consistency Model)引入音频压缩,将解码过程转化为单步去噪/重建问题,避免了自回归解码的延迟。同时,在瓶颈处嵌入Mamba模块,以线性复杂度高效建模长程时间依赖,补充了卷积在感受野上的局限。
- 噪声条件化与频域门控机制:训练中引入的噪声级别σ不仅用于一致性目标,还通过嵌入向量控制解码器各层的残差块,并生成频带相关的门控信号(g_in, g_out),使模型能根据噪声水平进行自适应的频域去噪。
🔬 细节详述
- 训练数据:SPRSound和SPRSound 2023挑战赛数据集组合,共2660/664条录音(387名参与者),用于训练/验证。
- 评估数据:SPRSound 2024挑战赛数据集,1704条录音(324名参与者)。
- 损失函数:一致性模型的均方误差损失:L = E[ || ŷ - (cskip(σ)x + cout(σ)ε) ||² ]。
- 训练策略:未明确说明学习率、优化器、batch size、训练步数/轮数。
- 关键超参数:
- 采样率:16 kHz,输入窗口:2秒。
- SincConv:滤波器数F=128,核长度251,步长512。
- 幂律缩放参数:α=0.65, β=0.34。
- 时间轴裁剪后长度:T=60帧。
- UNetPyramid:基础宽度64,通道倍增[1,2,4,4,4],5个层级。
- Mamba瓶颈:处理序列长度T=60,输入维度D_m = C·F。
- 训练硬件:未说明。
- 推理细节:单次前向传播,无需迭代。输出为固定维度的潜在表示(如表2所示,FP32下每2秒音频占32768字节)。
- 其他技巧:实例归一化(InstanceNorm)、方差保持缩放(在融合操作中使用1/√n)、学习的频带增益和门控。
📊 实验结果
主要基准为SPRSound 2024挑战赛测试集。关键结果总结如下:
表1. 在SPRSound数据集上的消融研究
| 组件 | 变体 | PRD (%) | CC | CR |
|---|---|---|---|---|
| 前端 | 本文: SincConv+PL+Mamba | 0.85 | 1.0000 | 3.91 |
| SincConv (无PL) | 2.04 | 0.9998 | 3.91 | |
| Mel前端 | 3.70 | 0.9998 | 3.91 | |
| 架构 | 无Mamba (保留金字塔) | 1.00 | 1.0000 | 3.91 |
| 单UNet-无Mamba | 2.25 | 0.9998 | — | |
| 单UNet-有Mamba | 1.82 | 0.9998 | — | |
| 频率调制 | 无方差缩放 | 1.35 | 1.0000 | 3.91 |
| 无门控 | 1.25 | 0.9999 | 3.91 | |
| 两者皆无 | 1.14 | 1.0000 | 3.91 |
表2. 存储与比特率分析(2秒音频)
| 表示 | 存储 (字节) | 比特率 (kbps) | CR |
|---|---|---|---|
| PCM16波形 (原始) | 64,000 | 256.0 | 1.00 |
| 潜在表示 (FP32) | 32,768 | 131.1 | 1.95 |
| 潜在表示 (FP16) | 16,384 | 65.5 | 3.91 |
表3. 与最新方法的性能比较
| 参考 | 方法 | PRD (%) | CC | CR |
|---|---|---|---|---|
| [10] | 压缩感知 | 50.1 | 0.8630 | 3.5 |
| [11] | VAE + 非均匀量化 + Transformer | 20.5 | 0.9800 | 256 |
| [9] | 卷积自编码器 | 22.3 | 0.9720 | 222.1 |
| [9] | 生成式VAE | 7.60 | 0.9757 | 42.67 |
| [9] | 压缩感知 | 5.30 | 0.9311 | 4 |
| 本文 | SincConv + PyramidUNet + Mamba | 0.85 | 1.0000 | 3.91 |
关键结论:
- 本文方法在保真度(PRD和CC)上显著优于所有对比基线,实现了近乎完美的相关性(CC=1.0000)。
- 压缩比(CR=3.91)属于中等水平,远低于一些追求极致压缩的方法(如CR>200),但获得了极低的失真。论文论证了这是医疗应用更优的权衡。
- 消融研究表明:
- SincConv+幂律缩放对保真度贡献最大。
- 金字塔UNet架构比单UNet性能提升显著(PRD从2.25%降至1.00%)。
- Mamba瓶颈带来进一步增益(PRD从1.00%降至0.85%)。
- 频率调制技术(方差缩放、门控)单独使用均能提升性能,但有趣的是同时去掉两者(PRD=1.14%)比单独去掉一个性能更好,论文未对此进行解释。
⚖️ 评分理由
- 学术质量(6.5/7):论文技术方案完整,创新点清晰(前端+多尺度+一致性+Mamba的组合),实验设置合理,有全面的消融研究和与SOTA的定量对比,证据充分。扣分点在于创新属于优化组合而非根本性突破,且个别消融实验结果(如频率调制部分)存在需要进一步解释的疑点。
- 选题价值(1.5/2):选题瞄准远程医疗的具体需求,解决数据存储/传输与保真度的矛盾,具有现实意义。分数略低于满分是因为任务本身较为垂直和特定。
- 开源与复现加成(0.0/1):论文未提供任何开源信息(代码、模型、训练细节),严重影响可复现性,因此没有加成。