📄 Residual Tokens Enhance Masked Autoencoders for Speech Modeling
#语音合成 #掩码自编码器 #自监督学习 #语音增强
✅ 7.0/10 | 前50% | #语音合成 | #掩码自编码器 | #自监督学习 #语音增强
学术质量 5.5/7 | 选题价值 1.0/2 | 复现加成 0.5 | 置信度 中
👥 作者与机构
- 第一作者:Samir Sadok(Inria at Univ. Grenoble Alpes, CNRS, LJK, France)
- 通讯作者:未说明(论文中未明确标注通讯作者)
- 作者列表:Samir Sadok(Inria at Univ. Grenoble Alpes, CNRS, LJK, France)、Stéphane Lathuilière(Inria at Univ. Grenoble Alpes, CNRS, LJK, France)、Xavier Alameda-Pineda(Inria at Univ. Grenoble Alpes, CNRS, LJK, France)
💡 毒舌点评
这篇论文提出了一个思路清晰、逻辑自洽的改进(用残差令牌捕获“边角料”信息),并通过在语音去噪任务上的初步应用证明了其有效性,这是其主要亮点。然而,其学术贡献更像在一个已有框架(AnCoGen)上做了一个精致的“补丁”,缺乏颠覆性的架构创新或在大规模基准上的压倒性优势,说服力和影响力因而受限。
🔗 开源详情
- 代码:论文中提供了代码和音频示例的在线仓库链接:
https://samsad35.github.io/site-residual。 - 模型权重:论文中未提及是否公开模型权重。
- 数据集:实验使用了公开数据集LibriSpeech [24]、EmoV-DB [25]、LibriMix [37]和PTDB [34],但论文本身未发布新的数据集。
- Demo:在线链接提供了音频示例(属于Demo的一部分)。
- 复现材料:论文提供了实验设置(数据集、属性提取方法、模型架构参数、训练轮数、硬件)和部分超参数(如τ=0.5)。但未提供完整的训练脚本、配置文件、损失函数权重细节或预训练检查点。
- 论文中引用的开源项目:CREPE [27](音高提取)、ECAPA-TDNN [28](说话人编码器)、HiFi-GAN [22](声码器)、CLUB [36](互信息估计)、SQUIM [31](评估工具)。
- 复现材料评价:提供了中等程度的复现信息,有代码示例和基本设置,但缺少一键复现的完整包。
📌 核心摘要
- 要解决什么问题:现有的语音建模方法主要依赖于显式定义的属性(如音高、内容、说话人身份),但这些无法完全捕捉自然语音的丰富性,遗漏了音色细微变化、噪声、情感、发音细节等“残差”信息。
- 方法核心是什么:提出RT-MAE,在掩码自编码器(MAE)框架中引入一组可训练的连续“残差令牌”(R)。这些令牌通过交叉注意力机制从梅尔频谱图中聚合信息,专门用于编码显式属性(A)未能解释的部分。同时,采用基于dropout的正则化策略,防止模型过度依赖残差令牌,确保生成过程保持可控性。
- 与已有方法相比新在哪里:不同于以往依赖复杂解耦损失或多任务学习来分离残差因素的方法,RT-MAE将残差信息表示为MAE中的离散令牌,提供了一种更灵活、更易于集成的表示方式。它明确将残差建模与掩码预测范式结合,并设计了控制信息流的正则化机制。
- 主要实验结果如何:
- 在语音合成任务上,RT-MAE在LibriSpeech和EmoV-DB数据集上相比基线AnCoGen,在各项指标(STOI, N-MOS, SBS, COS)上均有提升。例如,在LibriSpeech上,N-MOS从4.04提升至4.32,说话人相似度(COS)从0.81提升至0.86。
- 消融实验证实,当推理时同时使用属性和残差令牌(✓/✓)时效果最佳;仅使用残差令牌(✗/✓)时性能大幅下降,但保留了较高的说话人相似度,表明其编码了互补信息。
- 论文将该框架扩展到语音去噪:引入一个额外的、专门建模噪声的残差令牌Rnoise,在推理时将其关闭即可实现去噪。在LibriMix测试集上,其N-MOS(4.25)和SIG(4.23)指标优于对比的AnCoGen和DCCRNet等方法。
- 论文未提供与更多语音合成或增强领域SOTA方法的全面对比。
- 实际意义是什么:该工作为语音建模提供了一个简单有效的框架,用于捕获和控制那些难以显式定义的语音特征。在语音合成中,它能提升自然度和保真度;在语音增强中,它通过将噪声建模为一种可关闭的残差,实现了可控的降噪,展示了实际应用潜力。
- 主要局限性是什么:1) 与AnCoGen的改进相对渐进,未证明在更广泛或更标准的基准上的普适性优势;2) 对残差令牌具体编码了何种信息的分析和可视化不足;3) 语音去噪实验中,对比的方法和场景有限,其竞争力有待在更多挑战性条件下验证。
🏗️ 模型架构
RT-MAE构建在AnCoGen的掩码自编码器(MAE)框架之上,其整体架构如图1所示。核心流程如下:
- 输入:语音信号的梅尔频谱图
X和一组显式属性A(音高、响度、说话人嵌入、内容PPGs)。 - 离散化:梅尔频谱图
X和显式属性A被量化为离散令牌序列。残差令牌R则保持为连续向量。 - 掩码与嵌入:训练时,上述三类令牌(离散的X令牌、离散的A令牌、连续的R令牌)被随机部分掩码。可见的离散令牌通过可训练的码本嵌入为连续向量。
- 序列拼接与编码:将三种嵌入(X的嵌入、A的嵌入、R令牌)拼接成一个序列,送入由6层Transformer组成的编码器进行处理。残差令牌
R的生成方式(2.2节):引入一组固定的、可训练的查询向量Q(N=25个,维度d=512)。这些Q通过与梅尔频谱图X的嵌入进行交叉注意力(Q作为查询,X的嵌入提供键K和值V),聚合得到残差令牌R。这类似于Perceiver架构,将变长的梅尔频谱图信息压缩到固定数量的令牌中。 - 解码与预测:在编码器输出序列的相应掩码位置插入掩码令牌,然后通过6层Transformer解码器,预测原始被掩码的令牌(X、A或R的离散化目标)。
- 训练目标:最小化预测令牌与真实令牌之间的交叉熵损失。
- 推理:
- 分析:从输入梅尔频谱图预测其显式属性
A。 - 生成:从显式属性
A和残差令牌R出发,重建梅尔频谱图X,再通过HiFi-GAN声码器生成波形。正则化(2.3节):训练时,以概率τ(τ=0.5)丢弃整个残差令牌序列,迫使模型在缺失残差令牌时也能仅靠属性进行合理重建,从而控制信息流并保持可控性。 - 去噪:推理时,在重建流程中关闭一个额外的、专门建模噪声的残差令牌
Rnoise。
- 分析:从输入梅尔频谱图预测其显式属性
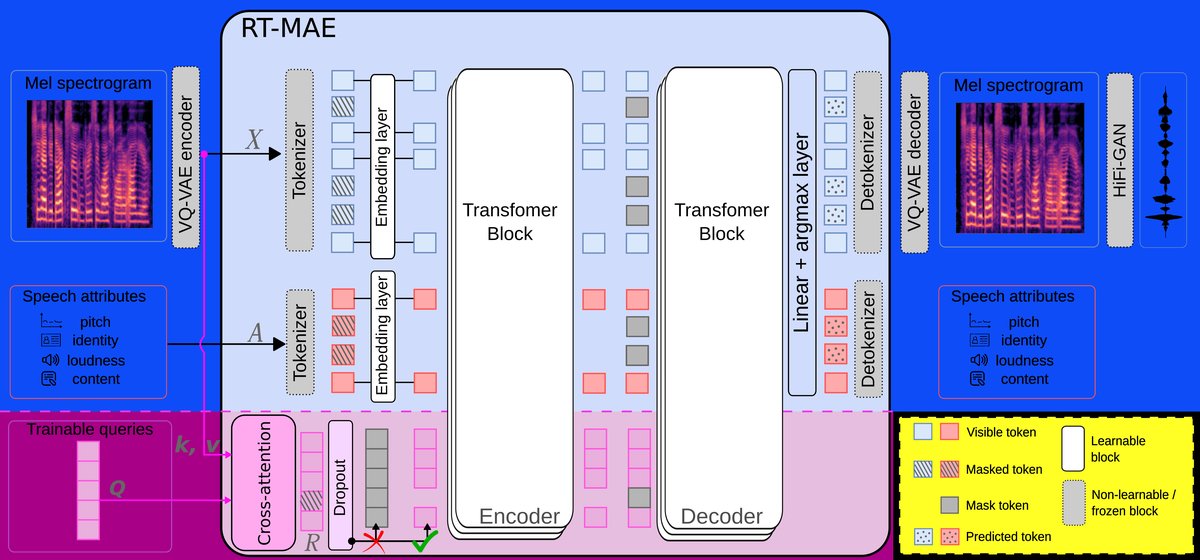 图1展示了RT-MAE的整体架构。顶部(蓝色)展示了传统的MAE范式,仅联合建模语音和显式属性。底部(紫色)展示了本文的核心创新:引入可训练的查询令牌(即残差令牌),通过与梅尔频谱图的交叉注意力,捕获显式属性未能解释的残差因子。
图1展示了RT-MAE的整体架构。顶部(蓝色)展示了传统的MAE范式,仅联合建模语音和显式属性。底部(紫色)展示了本文的核心创新:引入可训练的查询令牌(即残差令牌),通过与梅尔频谱图的交叉注意力,捕获显式属性未能解释的残差因子。
💡 核心创新点
- 引入连续残差令牌显式编码语音残差:在MAE框架中,明确设计了一组可训练的连续令牌(R),用于建模显式属性(A)未捕获的语音信息(如情感、微细韵律、噪声)。这解决了以往模型将残差信息作为数据集偏置隐式吸收、导致可控性差和泛化能力弱的问题。
- 设计基于交叉注意力的残差信息提取机制:借鉴Perceiver思想,使用一组固定的可训练查询向量(Q)与梅尔频谱图进行交叉注意力,以固定数量的令牌紧凑地表示整个频谱图的残差信息。这比标准自注意力(需每个帧一个令牌)计算效率更高,且提供了一个信息瓶颈。
- 提出残差令牌的Dropout正则化策略:训练时随机丢弃整个残差令牌序列,迫使模型学习有效利用显式属性进行重建,防止模型过度依赖残差令牌而变得不可控、不可解释。这确保了生成语音时结构化属性(A)的主导地位。
- 将框架扩展至可控语音去噪:将噪声视为一种特定的残差信息,通过引入一个专用的残差令牌(Rnoise)并训练其与原有残差(R)解耦,在推理时通过“关闭”Rnoise实现降噪,同时保留其他语音特征。这展示了该框架在任务扩展上的灵活性。
🔬 细节详述
- 训练数据:
- 数据集:LibriSpeech 360 Clean [24]。
- 规模:未提供具体小时数。
- 预处理:提取四种属性:音高(CREPE [27])、响度(RMSE)、说话人身份(预训练说话人编码器ECAPA-TDNN [28])、内容(强制对齐模型生成的音素后验图PPGs [29])。
- 数据增强:论文未提及。
- 损失函数:
- 主要损失:预测令牌与真实令牌之间的交叉熵损失(用于离散化的梅尔频谱图、属性和残差令牌)。
- 去噪任务额外损失:使用CLUB估计器[36]最小化残差令牌
R和噪声残差令牌Rnoise之间的互信息,以促进两者解耦。
- 训练策略:
- 优化器:AdamW。
- Batch size:128。
- 训练轮数:400 epochs。
- 学习率及调度策略:未说明。
- Warmup:未说明。
- 关键超参数:
- 模型大小:基础模型参数量约28.9M(见表1)。
- Transformer结构:编码器和解码器均为6层。每层包含多头自注意力、前馈网络和层归一化。
- 残差令牌数量:N = 25。
- 残差令牌维度:d = 512(与Transformer内部表示维度相同)。
- 正则化阈值:τ = 0.5(残差令牌丢弃概率)。
- 训练硬件:
- 4块NVIDIA A100 GPU。
- 训练总时长:未说明。
- 推理细节:
- 生成流程:从
A和R重建梅尔频谱图,然后通过预训练的HiFi-GAN [22]声码器生成波形。 - 解码策略:未提及,应为标准解码(非自回归)。
- 生成流程:从
- 正则化技巧:除Dropout正则化外,未提及其他稳定训练技巧。
📊 实验结果
论文报告了在三个主要任务上的实验结果。
- 语音分析与合成(表1) 比较了在LibriSpeech和EmoV-DB测试集上,从属性重建语音的质量。
| 模型 | 参数量(M) | LibriSpeech Test | EmoV-DB | ||||||
|---|---|---|---|---|---|---|---|---|---|
| STOI ↑ | N-MOS ↑ | SBS ↑ | COS ↑ | STOI ↑ | N-MOS ↑ | Acc. ↑ | COS ↑ | ||
| GT MS | - | 0.93 | 4.44 | - | 0.96 | 0.93 | 4.40 | 99.30 | 0.94 |
| AnCoGen [12] | 27.7 | 0.77 | 4.04 | 0.83 | 0.81 | 0.70 | 4.23 | 96.79 | 0.80 |
| RT-MAE (Ours) | 28.9 | 0.82 | 4.32 | 0.86 | 0.92 | 0.76 | 4.31 | 98.65 | 0.88 |
| 表1显示,RT-MAE在两个数据集上所有指标均优于AnCoGen。在LibriSpeech上,N-MOS提升0.28,说话人相似度(COS)提升0.11;在更具表现力的EmoV-DB上,情感分类准确率(Acc.)提升1.86%。 |
- 消融实验:残差令牌的作用(表2) 通过控制推理时是否使用属性(A)和/或残差令牌(R),分析其互补性。
| Attributes (A) | Residual tokens (R) | STOI ↑ | N-MOS ↑ | SBS ↑ | COS ↑ |
|---|---|---|---|---|---|
| ✗ | ✗ | 0.27 | 2.32 | 0.44 | 0.50 |
| ✓ | ✗ | 0.76 | 4.03 | 0.83 | 0.81 |
| ✗ | ✓ | 0.50 | 3.04 | 0.56 | 0.72 |
| ✓ | ✓ | 0.82 | 4.32 | 0.86 | 0.92 |
| 表2表明,仅使用残差令牌(第三行)仍能获得0.72的说话人相似度,但内容和质量大幅下降。同时使用两者(第四行)效果最佳,证明残差令牌提供了互补信息。 |
- 残差令牌正则化效果(图2描述) 论文描述图2显示,当丢弃阈值τ=0(残差令牌始终可用)时,模型过度依赖R,丧失可控性。τ在0.5左右时,模型能平衡利用A和R,各项指标最优。τ>0.8时,R几乎被忽略,性能退化。
图2] 注:原论文图2(Figure 2)展示了丢弃阈值τ对合成质量的影响。由于用户提供的图片列表中未包含此图的URL,无法贴图。但根据文字描述,该图是分析τ值对各项指标影响的重要证据。
- 语音去噪结果(表4) 在LibriMix测试集上,比较了不同方法的语音增强性能。
| 模型 | N-MOS ↑ | SIG ↑ | BAK ↑ | OVRL ↑ | COS ↑ |
|---|---|---|---|---|---|
| Noisy | 2.62 | 3.97 | 2.52 | 2.97 | - |
| DCCRNet [40] | 4.15 | 4.08 | 4.26 | 3.73 | 0.89 |
| Conv-TasNet [41] | 4.12 | 4.18 | 4.30 | 3.78 | 0.91 |
| AnCoGen [12] | 4.24 | 4.21 | 4.32 | 3.81 | 0.73 |
| RT-MAE (Ours) | 4.25 | 4.23 | 4.29 | 3.80 | 0.86 |
| 表4显示,RT-MAE在N-MOS和SIG指标上取得最优,整体质量OVRL与AnCoGen持平,说话人相似度COS(0.86)显著优于AnCoGen(0.73),接近专用增强模型Conv-TasNet。 |
- 保持可控性(表3) 在PTDB数据集上进行音高操纵实验,表明添加残差令牌不影响控制精度。
| +0 % | +10 % | +20 % | |||||||
|---|---|---|---|---|---|---|---|---|---|
| R | AAE ↓ | N-MOS ↑ | SBS ↑ | AAE ↓ | N-MOS ↑ | SBS ↑ | AAE ↓ | N-MOS ↑ | SBS ↑ |
| ✗ | 4.8 | 4.08 | 0.83 | 5.7 | 4.10 | 0.82 | 5.9 | 4.07 | 0.80 |
| ✓ | 4.8 | 4.33 | 0.86 | 5.7 | 4.30 | 0.86 | 5.9 | 4.20 | 0.84 |
| 表3显示,无论是否使用残差令牌(R),音高操纵的绝对平均误差(AAE)不变,证明控制精度得以保持。同时使用R能一致提升自然度(N-MOS)和语义一致性(SBS)。 |
⚖️ 评分理由
- 学术质量(5.5/7):论文提出了一个清晰且有逻辑的改进点(残差令牌),技术实现(交叉注意力、Dropout正则化)正确,并通过充分的消融实验和多任务(合成、去噪)验证了其有效性。主要扣分在于:1) 创新性属于在已有框架(AnCoGen)上的增强,而非开创性架构;2) 实验对比基线较单一,缺乏与当前语音合成或增强领域顶尖方法的全面比较;3) 对残差令牌所学内容的可解释性分析不足。
- 选题价值(1.0/2):研究如何捕捉和控制语音中的隐式、残差信息,是一个实际且有价值的方向,对于提升语音合成的自然度和实现可控语音增强有直接意义。但该选题在语音领域并非最前沿热点,影响力中等。
- 开源与复现加成(+0.5/1):论文明确提供了代码和音频示例的在线仓库链接,这为复现提供了重要基础。但未提供完整的训练脚本、模型权重或详细的超参数配置指南,因此复现门槛仍然存在,加成有限。