📄 Representation-Diverse Self-Supervision for Cross-Domain Bioacoustic Learning in Low-Resource Settings
#生物声学 #对比学习 #自监督学习 #迁移学习 #低资源
✅ 7.0/10 | 前25% | #生物声学 | #对比学习 | #自监督学习 #迁移学习
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Dimitris N. Makropoulos(HERON - Hellenic Robotics Center of Excellence; 国家技术大学雅典分校电气与计算机工程学院;雅典研究中心机器人研究所;希腊海洋研究中心海洋学研究所)
- 通讯作者:未说明(论文未明确标注)
- 作者列表:Dimitris N. Makropoulos(同上),Christos Garoufis(HERON; 国家技术大学雅典分校; 雅典研究中心),Antigoni Tsiami(雅典研究中心),Panagiotis P. Filntisis(HERON; 雅典研究中心),Petros Maragos(HERON; 国家技术大学雅典分校; 雅典研究中心)
💡 毒舌点评
亮点:其核心想法——让模型学习同一段海豚叫声的两种不同“画像”(频谱图与能量图)之间的联系——非常巧妙,不仅有效利用了信号本身的物理特性,还意外地在完全不同的鸟类叫声识别任务上取得了优异效果,展现了生物声学中“调制模式”跨物种共享的有趣洞察。短板:实验验证的“跨域”跨度仅限于海豚与鸟类,且数据集规模偏小(预训练仅15类海豚),论文未提供代码开源计划或预训练模型,极大地限制了其作为通用生物声学预训练方法的即时可用性和影响力。
🔗 开源详情
- 代码:论文中未提及代码链接或开源计划。
- 模型权重:未提及是否公开预训练或微调后的模型权重。
- 数据集:论文使用了公开数据集(WMMSD, RFCx, BirdCLEF),但未在论文中说明具体获取方式或提供处理后的数据脚本。
- Demo:未提供在线演示。
- 复现材料:提供了较详细的训练超参数(epoch, batch size, 学习率, 优化器)、模型架构选择(ResNet18等)、数据处理流程(重采样率, 窗长, 谱图大小)以及关键算法公式(Gabor滤波, TKEO, InfoNCE loss),为复现提供了必要信息。
- 引用的开源项目:论文引用了SimCLR、COLA等自监督学习方法作为对比基线,但未明确说明其代码依赖。
📌 核心摘要
- 解决的问题:在低资源生物声学领域,跨物种、跨数据集的迁移学习面临挑战,因为不同物种的发声信号虽有共性(如频率调制),但数据分布差异大。传统自监督学习(如SimCLR)依赖数据增强,可能未充分利用信号本身的多种物理表示。
- 方法核心:提出一种“表示多样性”的对比自监督学习框架。在预训练阶段,模型(ResNet18, MobileNetV2, ViT-B/16)学习区分同一段海豚叫声的频谱图和由Teager-Kaiser能量算子(TKEO)派生的能量图。这两种表示分别捕捉信号的功率谱密度和瞬时能量-调制特性。之后,将预训练好的编码器在鸟类叫声数据集上进行微调。
- 与已有方法的新颖之处:不同于SimCLR对同一表示进行随机数据增强,也不同于跨模态学习(如音频-文本),本方法首次利用同一信号的不同物理/数学表示(频谱图 vs. 能量图)构建正样本对进行对比学习。这种跨表示对比迫使模型学习更本质的、跨表示不变的声学特征。
- 主要实验结果:
在RFCx和BirdCLEF两个鸟类叫声数据集上,所有模型架构(ResNet18, MobileNetV2, ViT)均显示,从监督学习到SimCLR,再到对比不同窗口频谱图,最后到对比“频谱图-能量图”,性能持续提升。最佳配置(对比频谱图与离散TKEO能量图)显著优于监督基线和SimCLR。
模型 RFCx (加权F1) BirdCLEF (加权F1) ResNet18 82.38 ± 1.51% (最佳) 73.72 ± 0.40% (最佳) MobileNetV2 77.95 ± 1.12% 67.40 ± 0.68% ViT-B/16 82.10 ± 1.31% 68.12 ± 0.67% 表1:不同模型在最佳配置(对比频谱图与离散TKEO能量图)下的加权F1分数对比(数据来源于论文Table 1) 论文图2展示了虎鲸和旋转海豚的能量图与频谱图对比,直观显示了能量图对调制结构的增强效果。 - 实际意义:为低资源生物声学监测提供了一种有效的预训练策略。通过利用海豚叫声数据(可能相对易获取)预训练,能够提升鸟类(或其他物种)叫声分类的性能,有助于生态保护和生物多样性监测。
- 主要局限性:预训练数据(海豚)和下游任务数据(鸟类)虽然都包含调制成分,但物种差异巨大,框架的泛化能力到更多类群(如昆虫、蛙类)未被验证。数据集规模较小(预训练15类,下游测试集每类50-250样本),在大规模实际场景中的鲁棒性未知。论文未提供代码和预训练模型。
🏗️ 模型架构
本文提出的管道架构分为三个阶段(见论文图3):
 论文图3:所提管道架构概览。I. 数据处理:对同一段海豚叫声信号,分别生成频谱图和能量图。II. 对比学习:两个编码器(共享权重)分别处理频谱图和能量图,通过投影头输出嵌入,然后使用InfoNCE损失最大化正对(同一音频的两种表示)相似度,最小化负对(不同音频的表示)相似度。III. 下游任务:将预训练的编码器(去掉投影头)连接分类头,在鸟类叫声的频谱图上进行端到端微调。
论文图3:所提管道架构概览。I. 数据处理:对同一段海豚叫声信号,分别生成频谱图和能量图。II. 对比学习:两个编码器(共享权重)分别处理频谱图和能量图,通过投影头输出嵌入,然后使用InfoNCE损失最大化正对(同一音频的两种表示)相似度,最小化负对(不同音频的表示)相似度。III. 下游任务:将预训练的编码器(去掉投影头)连接分类头,在鸟类叫声的频谱图上进行端到端微调。
完整流程:
- 输入:一批海豚叫声音频片段。
- 表示生成:
- 频谱图:对原始音频进行短时傅里叶变换(STFT),得到对数幅度谱图(resize至224x224)。
- 能量图:原始音频先通过一个Gabor带通滤波器组(256个滤波器,中心频率间隔172.3 Hz,带宽512 Hz),将信号分解为多个AM-FM子带信号。然后对每个子带信号应用Teager-Kaiser能量算子(TKEO)(离散或正则化版本),得到每个子带的瞬时能量序列。最后,对每个时间帧,取所有子带能量中的最大值,形成最终的能量图(同样是时间-频率表示)。
- 对比学习预训练:
- 编码器:使用在ImageNet上预训练的ResNet18, MobileNetV2或ViT-B/16作为编码器
f。编码器分别处理频谱图s和能量图e,得到特征向量f(s)和f(e)。 - 投影头:在编码器后添加一个由两层线性层+ReLU构成的投影头,将特征映射到低维嵌入空间,用于计算对比损失。
- 损失函数:采用InfoNCE损失(公式6)。对于一个批次中的2N个样本(N个频谱图,N个对应的能量图),损失函数鼓励每个频谱图嵌入与对应能量图嵌入的相似度高,与其他所有嵌入的相似度低。温度参数
τ设为0.1。
- 编码器:使用在ImageNet上预训练的ResNet18, MobileNetV2或ViT-B/16作为编码器
- 下游微调:
- 将预训练的编码器(去掉投影头)与一个新的分类头(线性层)结合。
- 在鸟类叫声的频谱图数据集上,以端到端的方式微调整个网络(包括编码器)。
关键设计选择及动机:
- 双表示对比:核心创新。动机是相信频谱图和能量图从不同角度描述同一声学事件,模型应能学习到对这两种视角都鲁棒的深层特征,这些特征可能更本质地对应于发声源的调制特性,从而利于跨物种迁移。
- Gabor滤波器组+TKEO:用于生成能量图。Gabor滤波器是分析AM-FM信号的经典工具,TKEO能有效追踪信号的瞬时能量,对背景噪声(如船只噪声)不敏感,能突出快速变化的调制事件(如动物叫声)。这提供了与频谱图(基于功率谱)互补的表示。
- 使用预训练权重:编码器初始化使用ImageNet-1K预训练权重,为视觉模型提供了良好的初始特征提取能力,即使任务域从自然图像变为音频谱图。
💡 核心创新点
- 跨表示对比学习框架:首次在生物声学领域提出使用同一音频信号的不同物理表示(频谱图与能量图)构建对比学习的正样本对。这超越了传统基于数据增强(如裁剪、掩码)的自监督范式,引导模型学习跨表示不变的、更具泛化性的声学特征。
- 融合信号处理与深度学习:将经典的信号处理工具(Gabor滤波、TKEO)与现代深度对比学习相结合,用于生成和利用“能量图”这种富含调制信息的表示。这为音频自监督学习引入了基于领域知识的强归纳偏置。
- 跨物种迁移学习的验证:成功证明了在海豚(鲸目动物)叫声上通过对比学习预训练的模型,可以显著提升鸟类叫声分类的性能。这为利用一种丰富但可能不相关的生物声学数据源,来辅助解决另一种低资源生物声学任务提供了可行路径,并暗示了不同物种发声在调制模式上的共通性。
🔬 细节详述
- 训练数据:
- 预训练:Watkins Marine Mammal Sound Database (WMMSD) 的一个平衡子集,包含15个海豚物种,每个物种100-150个wav文件。音频重采样至44.1 kHz。
- 下游微调/评估:
- RFCx:强标签数据集,包含24类鸟类和蛙类叫声,每类50个录音。
- BirdCLEF 2022:弱标签数据集,包含15种鸟类,每种250个录音,每个录音时长均低于10秒。
- 预处理:所有音频均resize为224x224的谱图。频谱图计算使用汉明窗,窗长1024,重叠50%。未提及具体的数据增强策略(除了对比学习框架隐含的跨表示选择)。
- 损失函数:Information Noise-Contrastive Estimation (InfoNCE) 损失(公式6),是InfoNCE loss的一种实现,用于最大化正对相似度、最小化负对相似度。温度参数
τ=0.1。 - 训练策略:
- 对比学习阶段:训练120个epoch,批大小32,使用Adam优化器,初始学习率
10^-3。数据随机打乱,不使用标签。 - 微调阶段:训练100个epoch,使用Adam优化器,初始学习率
10^-3。 - 数据划分:监督学习和下游评估均采用低资源设置:20%训练,80%测试。进行K=10次随机划分,报告均值及95%置信区间。
- 对比学习阶段:训练120个epoch,批大小32,使用Adam优化器,初始学习率
- 关键超参数:
- Gabor滤波器组:256个滤波器,中心频率间隔172.3 Hz,带宽512 Hz。
- 对比学习中的正负对构建方式:同一音频的频谱图(i)与能量图(i+N)为正对。
- ViT-B/16:使用
img_size=224, patch_size=16。
- 训练硬件:论文中未说明使用的GPU型号、数量及训练时长。
- 推理细节:论文中未说明解码策略、温度(除对比损失中的τ)、beam size等。微调后直接用于分类。
- 正则化或稳定训练技巧:论文中未明确说明是否使用Dropout、权重衰减等。对于ViT模型,在对比学习阶段使用了随机裁剪(最高20%面积移除)。
📊 实验结果
主要结果:如论文Table 1所示,在RFCx和BirdCLEF两个数据集上,对比“频谱图-能量图”的配置在所有模型上都取得了最佳或接近最佳的性能,并且显著优于监督基线和SimCLR方法。关键数据已在上文“核心摘要”中用表格呈现。
与最强基线的差距:
- 在RFCx数据集上,最佳模型(ResNet18, 对比频谱图与离散TKEO能量图)的加权F1分数为
82.38%,比监督基线(69.71%)高12.67个百分点,比SimCLR基线(76.49%)高5.89个百分点。 - 在BirdCLEF数据集上,最佳模型(ResNet18, 对比频谱图与正则化TKEO能量图)的加权F1分数为
73.72%,比监督基线(64.80%)高8.92个百分点,比SimCLR基线(67.69%)高6.03个百分点。
关键消融/对比实验: 论文通过对比不同的自监督配置(SimCLR vs. 多窗口对比 vs. 频谱图-能量图对比),形成了清晰的消融链条,证明了“跨表示对比”这一设计的有效性。例如,对于ResNet18在RFCx上:
- (1) 监督:
69.71%w-F1 - (2) SimCLR:
76.49% - (3) 对比不同窗口频谱图 (w-1024 vs w-256):
79.85% - (4b) 对比频谱图与离散TKEO能量图:
82.38%
不同条件下的结果:
- 模型架构:ResNet18和ViT-B/16在最佳配置下性能接近且优于MobileNetV2。ViT在监督设置下表现最差,但通过对比学习获得提升最大,论文归因于其更依赖数据量。
- 能量图类型:离散TKEO与正则化TKEO性能非常接近,互有胜负,表明两种变体均有效。
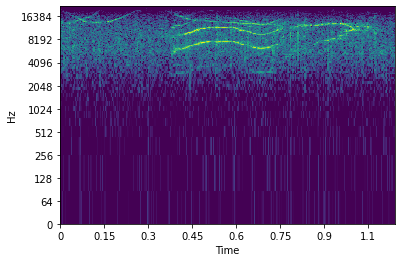
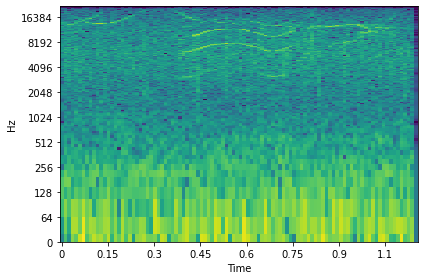
 论文图2:展示了一只虎鲸(上)和一只旋转海豚(下)叫声的离散TKEO能量图(左)与频谱图(右)。能量图清晰突出了叫声中的调制结构,视觉上与频谱图形成互补。
论文图2:展示了一只虎鲸(上)和一只旋转海豚(下)叫声的离散TKEO能量图(左)与频谱图(右)。能量图清晰突出了叫声中的调制结构,视觉上与频谱图形成互补。
其他图表:
 论文图1:能量图生成流程框图。原始信号
论文图1:能量图生成流程框图。原始信号gs通过一组Gabor带通滤波器g1, g2...gk,每个滤波器的输出再经过TKEO(Ψ)算子,最后对每个滤波器通道在时间维度上取最大能量,形成能量图的各行。这相当于一个基于调制能量的注意力机制。
 此图在论文中未在正文中直接引用,但根据描述可能对应其他实验或补充材料。
此图在论文中未在正文中直接引用,但根据描述可能对应其他实验或补充材料。
⚖️ 评分理由
- 学术质量(6.0/7):
- 创新性(高):提出“跨表示对比学习”这一新颖范式,并在生物声学跨域迁移中成功应用,思路清晰且富有启发性。
- 技术正确性(高):方法实现基于坚实的信号处理理论(Gabor分析、TKEO)和成熟的对比学习框架(InfoNCE),技术路线正确。
- 实验充分性(中):在三个不同复杂度的骨干网络、两个下游数据集上进行了系统对比,实验设计合理。但预训练数据集规模小(15类),下游任务仅限鸟类,缺乏更多样化的物种验证。
- 证据可信度(中高):报告了详细的均值和置信区间,实验设置(如低资源数据划分)清晰。但未提供代码和模型,他人无法直接复现验证其结论。
- 选题价值(1.5/2):
- 前沿性(高):将对比学习从数据增强扩展到多物理表示,是音频/语音自监督学习的一个新颖方向。
- 潜在影响(中高):对低资源生物声学监测、生态保护有直接应用价值,并可能启发其他音频领域的迁移学习研究。
- 与音频/语音读者相关性(高):直接涉及音频表示学习、自监督、迁移学习等核心议题,对音频处理研究者有参考价值。
- 开源与复现加成(0.5/1):
- 论文详细描述了方法、关键参数(如滤波器设置、训练epoch、学习率),提供了一定的复现基础。
- 重大缺失:未提供代码仓库、预训练模型权重或数据集获取说明,显著增加了复现难度。因此给予正向但较低的加成。