📄 Reliable AI via Age-Balanced Validation: Fair Model Selection for Parkinson’s Detection from Voice
#语音生物标志物 #模型评估 #数据集 #跨模态 #音频分类
✅ 7.5/10 | 前25% | #语音生物标志物 | #模型评估 | #数据集 #跨模态
学术质量 5.5/7 | 选题价值 1.8/2 | 复现加成 0.3 | 置信度 高
👥 作者与机构
- 第一作者:Niloofar Momeni(Centre for Mathematical Sciences, Mathematical Statistics, Lund University, Sweden)
- 通讯作者:未说明
- 作者列表:Niloofar Momeni(Centre for Mathematical Sciences, Mathematical Statistics, Lund University, Sweden)、Susanna Whitling(Department of Logopedics, Phoniatrics, and Audiology, Faculty of Medicine, Lund University, Sweden)、Andreas Jakobsson(Centre for Mathematical Sciences, Mathematical Statistics, Lund University, Sweden)
💡 毒舌点评
这篇论文的亮点在于其“简单而有效”:用一个精心设计的年龄平衡验证集,就能显著改善跨数据集、跨语言模型的泛化性能,并且推理时完全不需要敏感的人口统计学信息,这在临床场景下极具吸引力。但短板也很明显:除了提出验证集构建流程,论文对“为何年龄平衡验证集能有效”的机理分析较浅,且新构建的VD数据集规模较小(113人),其作为外部验证基准的普适性有待更广泛数据的检验。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及公开训练好的模型权重。
- 数据集:mPower数据集为公开数据集。VD数据集不公开,论文明确指出“Regrettably, the VD dataset is not publicly available due to privacy agreements and institutional data-sharing restrictions.”。
- Demo:未提及在线演示。
- 复现材料:提供了特征提取方法(OpenSMILE的eGeMAPS特征集、DistilHuBERT预处理)、模型架构描述、超参数调优范围(网格搜索参数)和训练硬件环境。但具体的训练脚本、配置文件和最终模型检查点未提供。
- 论文中引用的开源项目:
- 模型/框架:DistilHuBERT [16], TabNet [18], XGBoost [19], scikit-learn [20]。
- 工具库:OpenSMILE [17], Hugging Face Transformers [22]。
- 总结:论文中未提及完整的开源计划。核心的外部验证数据集不公开,代码也未开源,这限制了社区对其方法进行独立验证和扩展。
📌 核心摘要
- 问题:基于语音的帕金森病检测模型常因训练数据中年龄分布不平衡(如健康对照组偏年轻,患者组偏年长)而学习到年龄偏差,导致模型在真实世界或外部数据集上泛化能力差,即模型实质上是在“检测年龄”而非“检测疾病”。
- 方法核心:提出一种在模型选择阶段使用的“年龄平衡验证集”构建策略。即在划分训练/验证集时,确保验证集中健康对照组和患者组的年龄分布相似(例如,通过优先选取年长的健康人进入验证集),以此来选择对年龄偏差更鲁棒的模型超参数和架构。
- 创新点:与之前需要在推理时使用人口统计元数据(如分组缩放)来校正偏差的方法不同,该策略完全在训练/验证阶段完成,无需在测试阶段获取敏感的年龄信息,更适用于隐私保护要求高的临床部署。该策略具有模型无关性,在Transformer、深度学习和传统机器学习模型上均有效。
- 主要实验结果:在内部(mPower数据集)和外部(新构建的瑞典语VD数据集)测试集上,使用年龄平衡验证集选出的模型性能均优于使用随机验证集选出的模型。关键结果如下表所示,尤其在外部VD数据集上提升显著:
| 数据库 | 测试集 | 模型 | 随机验证集调优 (Acc.) | 年龄平衡验证集调优 (Acc.) | 性能提升 |
|---|---|---|---|---|---|
| mPower | 内部测试 | DistillHuBERT | 88.6% | 89.4% | +0.8% |
| XGBoost | 74.1% | 78.8% | +4.7% | ||
| TabNet | 70.2% | 73.4% | +3.2% | ||
| VD | 外部测试 | DistillHuBERT | 61.6% | 70.2% | +8.6% |
| XGBoost | 53.4% | 59.3% | +5.9% | ||
| TabNet | 50.2% | 66.4% | +16.2% |
论文图2直观展示了各模型在不同验证集策略下,在内部验证集、内部测试集和外部VD测试集上的性能对比,清晰表明年龄平衡策略对外部泛化性的显著改善。 5. 实际意义:为构建公平、可靠、可泛化的医疗AI系统提供了一种简单且可操作的评估框架,有助于减少因数据偏差导致的误诊,提高模型在不同人群和语言环境中的适用性。 6. 主要局限性:1) 仅针对年龄偏差,未涉及性别、语言等其他潜在偏差源;2) 用于外部验证的VD数据集规模较小(113名被试),其结论的普适性需进一步验证;3) 策略本身依赖对年龄分布的先验控制或近似,若数据中年龄信息缺失则无法实施。
🏗️ 模型架构
本论文并未提出一种全新的端到端检测模型,而是评估了一种模型选择与评估框架的通用性。该框架应用于三种代表性的模型架构:
- DistilHuBERT:一个轻量化的自监督语音Transformer模型。架构上,它使用冻结的预训练DistilHuBERT骨干网络作为特征提取器,将原始音频波形编码为上下文相关的语音嵌入。随后,对这些嵌入进行平均池化,再通过一个简单的分类头(全连接层)进行帕金森病/健康对照的二分类。其核心是利用自监督预训练学到的通用语音表示。
- TabNet:一种专为表格数据设计的深度学习模型,采用注意力机制进行特征选择。它接收手工提取的声学特征(如eGeMAPS特征集)作为输入。TabNet通过其稀疏注意力掩码和顺序决策步骤,动态地关注输入特征中最具判别力的部分进行分类。其可解释性是其亮点。
- XGBoost:一种经典的梯度提升决策树算法。同样以手工提取的eGeMAPS声学特征作为输入。它通过迭代地构建多个弱学习器(决策树)来组合成一个强分类器,以其高效性、正则化和良好的性能著称。
整体数据流与交互:论文的流程如图1所示。首先从原始语音录音中提取特征:要么使用DistilHuBERT直接编码,要么使用OpenSMILE工具箱提取88维的eGeMAPS静态声学特征(供TabNet和XGBoost使用)。然后,这些特征被用于训练对应的模型。模型的选择(如超参数调优)是在年龄平衡验证集上完成的,而非传统的随机验证集。最终,选中的模型在独立的内部测试集和全新的外部VD测试集上进行评估。
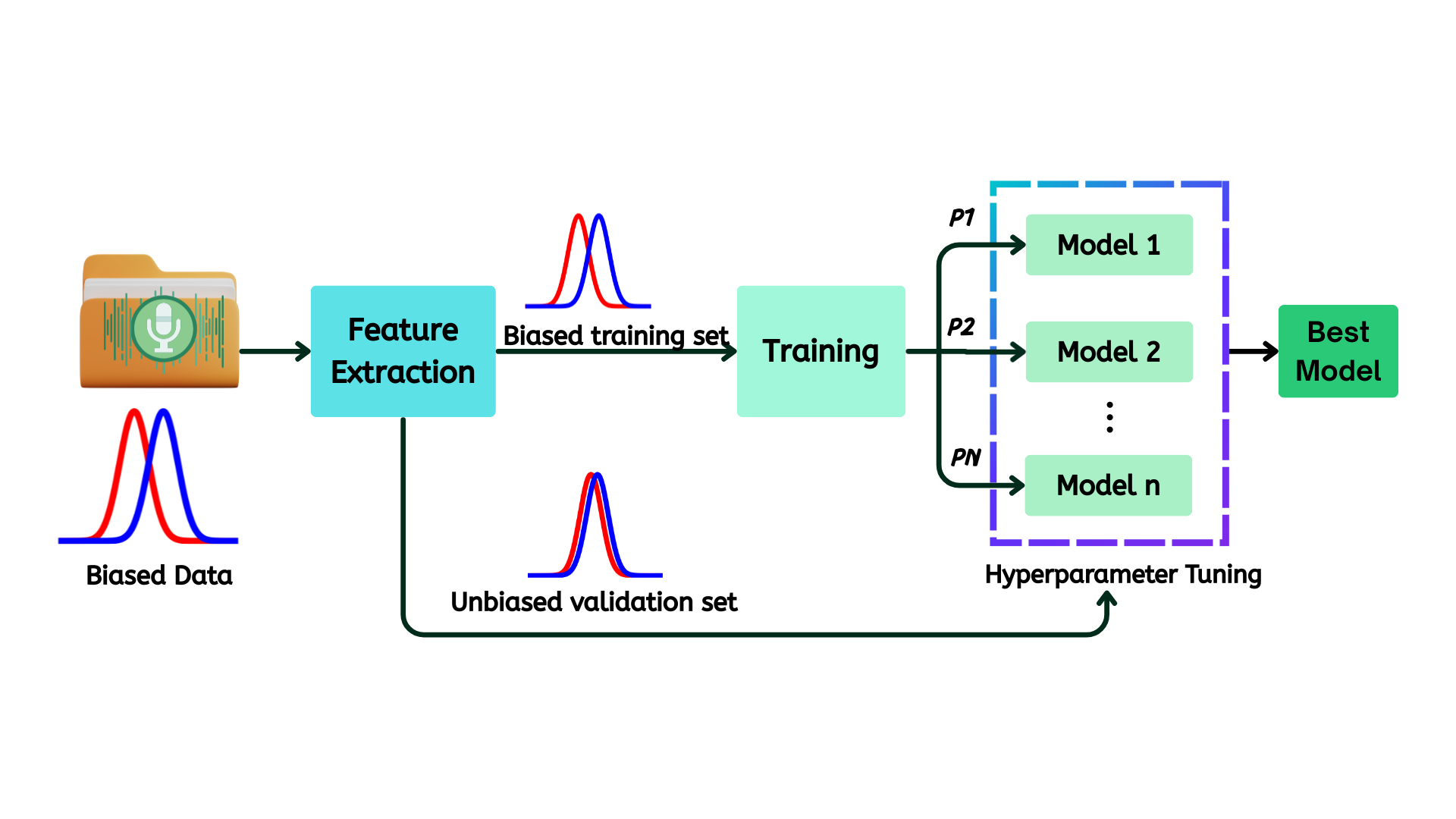 图1 是整个模型选择流程的示意图,清晰地展示了从特征提取、构建年龄平衡验证集、超参数调优到模型选择,最终在多个测试集上评估的完整闭环。
图1 是整个模型选择流程的示意图,清晰地展示了从特征提取、构建年龄平衡验证集、超参数调优到模型选择,最终在多个测试集上评估的完整闭环。
💡 核心创新点
- 提出年龄平衡验证集策略:核心创新是设计了一种在模型选择阶段构建验证集的方法,确保验证集中健康对照组和患者组的年龄分布相似。这从评估源头上抑制了模型选择过程对年龄偏差的偏好。
- 无需推理时人口统计元数据:与先前依赖在测试时使用年龄、性别等元数据进行校正的方法不同,该策略将“公平性”内化到了模型选择过程中。一旦模型选出,推理时仅需语音输入,更符合隐私保护和实际部署需求。
- 模型无关的有效性:在三种架构迥异的模型(Transformer、深度学习、传统机器学习)上均验证了该策略的有效性,证明了其作为通用评估协议的潜力。
- 强调外部验证的必要性并新建数据集:论文通过实验证明,传统的随机划分验证集会掩盖模型的年龄偏差,这种偏差在内部测试集上可能不明显,但在人口分布不同的外部数据集上会暴露。为此,作者专门构建了一个语言(瑞典语)和人口学特征与主数据集(英语)不同的Voice Diagnostics (VD) 数据集作为严格的外部验证基准。
🔬 细节详述
- 训练数据:
- 主要数据集:mPower数据集。包含968名PD患者和3972名健康对照(HC),约6.5万条语音录音。录音来自iPhone应用,任务为发元音/a/约10秒。年龄分布不平衡:HC平均42岁,PD平均63岁。
- 外部测试数据集:Voice Diagnostics (VD) 数据集。包含113名被试(73 HC, 40 PD),2833条语音样本。年龄分布相对平衡:HC平均68岁,PD平均66岁。语言为瑞典语,通过专用手机应用录制。
- 损失函数:论文中未明确说明使用何种损失函数(如交叉熵损失),仅提及优化目标为验证集上的平衡准确率 (Balanced Accuracy)。
- 训练策略:
- 数据划分为训练(80%)、验证(20%)、测试(5%)。VD数据集全量作为外部测试集。
- 对于DistilHuBERT和TabNet,使用基于验证集平衡准确率的早停法。
- 对于XGBoost,使用网格搜索对最大树深度和树的数量进行调优。
- DistilHuBERT训练20个epoch,优化器为Adam,学习率5e-5。
- 关键超参数:未提供模型具体的层数、隐藏维度等详细结构参数。仅提到TabNet和XGBoost使用88维的eGeMAPS特征;DistilHuBERT输入为16kHz重采样的音频,处理为10秒(不足零填充,超长则截断)。
- 训练硬件:NVIDIA GeForce RTX 4080 GPU (16GB VRAM),32GB RAM,Intel CPU,Python 3.10。
- 推理细节:论文未详细描述推理流程,应为标准的单样本前向传播。
- 正则化技巧:未明确说明,仅提到XGBoost和DistilHuBERT模型本身具有正则化特性。
📊 实验结果
论文的核心实验对比了两种验证集构建策略(随机划分 vs. 年龄平衡划分)对最终模型性能的影响。评估指标包括准确率(Acc.)、加权F1分数(F1)、加权召回率(Rec.)和加权精确率(Prec.)。
主要对比表格(直接引用并转录自Table 1):
| Database | Test | Model | Tuned on Random Validation Set | Tuned on age-balanced Validation Set | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Acc. | F1 | Rec. | Prec. | Acc. | F1 | Rec. | Prec. | |||
| mPower | Validation | DistillHuBert | 72.5 | 72.8 | 72.5 | 73.6 | 63.8 | 67.6 | 63.8 | 76.7 |
| XGBoost | 71.7 | 71.7 | 71.7 | 71.8 | 65.5 | 68.9 | 65.5 | 75.7 | ||
| TabNet | 70.5 | 70.7 | 70.5 | 70.9 | 68.5 | 71.5 | 68.5 | 77.7 | ||
| Unseen Test | DistillHuBert | 88.6 | 88.6 | 88.6 | 88.6 | 89.4 | 89.4 | 89.4 | 89.4 | |
| XGBoost | 74.1 | 74.4 | 74.1 | 74.7 | 78.8 | 79.2 | 78.8 | 80.9 | ||
| TabNet | 70.2 | 70.5 | 70.2 | 71.1 | 73.4 | 74.1 | 73.4 | 77.5 | ||
| VD | External Unseen Test | DistillHuBert | 61.6 | 66.0 | 61.6 | 77.6 | 70.2 | 72.5 | 70.2 | 76.2 |
| XGBoost | 53.4 | 58.6 | 54.2 | 81.0 | 59.3 | 63.8 | 59.3 | 78.7 | ||
| TabNet | 50.2 | 54.6 | 50.2 | 79.3 | 66.4 | 70.0 | 66.4 | 79.8 |
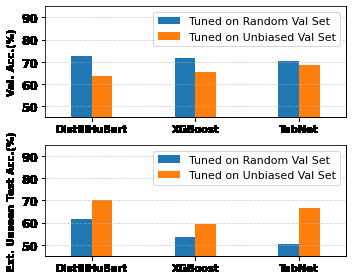 图2 是对表格核心结果的可视化总结,横轴为不同模型在三种数据/验证设置下的表现,纵轴为准确率。蓝色柱子代表使用年龄平衡验证集调优的模型性能,橙色代表随机验证集。图表清晰地显示:在外部VD测试集上,蓝色柱子显著高于橙色柱子,证明了年龄平衡验证策略带来的巨大性能提升;而在内部验证集上,橙色柱子反而更高,这说明了随机验证集会导致过拟合的乐观评估。
图2 是对表格核心结果的可视化总结,横轴为不同模型在三种数据/验证设置下的表现,纵轴为准确率。蓝色柱子代表使用年龄平衡验证集调优的模型性能,橙色代表随机验证集。图表清晰地显示:在外部VD测试集上,蓝色柱子显著高于橙色柱子,证明了年龄平衡验证策略带来的巨大性能提升;而在内部验证集上,橙色柱子反而更高,这说明了随机验证集会导致过拟合的乐观评估。
关键发现与消融:
- 内部验证集悖论:使用年龄平衡验证集选出的模型,在内部mPower验证集上的性能反而低于随机验证集选出的模型。论文解释这是因为随机验证集可能偶然保持了与训练集相似的年龄偏差,从而过拟合。
- 内部测试集表现:在内部未见测试集上,年龄平衡策略选出的模型性能持平或略优。
- 外部数据集核心证据:在VD外部��试集上,所有模型使用年龄平衡策略均获得显著提升。其中TabNet提升最大(+16.2%),DistilHuBERT也提升了8.6%。这直接证明了传统验证方法会掩盖偏差,而新策略能选出泛化性更强的模型。
- 模型比较:Transformer模型(DistilHuBERT)在所有设置下普遍表现最好,表明预训练语音表示的优势。
⚖️ 评分理由
- 学术质量:5.5/7:论文逻辑严谨,从问题定义、方法提出到实验验证形成了一个完整的故事。技术实现正确,实验设计合理(包括内部验证、内部测试、外部测试三级评估,并对比了不同模型)。核心创新点清晰且有实际价值。主要扣分点在于创新深度有限,本质上是将“公平性”考量引入到标准的机器学习流程中,而非提出新的算法或模型。
- 选题价值:1.8/2:选题非常及时且重要。随着AI在医疗领域的应用,数据偏差和模型公平性成为关键挑战。本文直接针对语音生物标志物检测中的年龄偏差问题,并给出了可操作的解决方案,对研究者和临床开发者均有很高的参考价值。
- 开源与复现加成:0.3/1:论文详细描述了实验设置、特征提取工具(eGeMAPS, DistilHuBERT)、模型选择策略和超参数调优范围,对复现有一定指导。但关键的新数据集VD因隐私原因不公开,且代码未提供,使得完全复现其核心结果(年龄平衡验证集策略的效果)变得困难,因此加分有限。