📄 Refgen: Reference-Guided Synthetic Data Generation for Anomalous Sound Detection
#音频事件检测 #流匹配 #数据增强 #工业应用
✅ 7.5/10 | 前25% | #音频事件检测 | #流匹配 | #数据增强 #工业应用
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Wenrui Liang(清华大学电子工程系)
- 通讯作者:Wei-Qiang Zhang(清华大学电子工程系)
- 作者列表:Wenrui Liang(清华大学电子工程系)、Yihong Qiu(华北电力大学经济与管理学院)、Anbai Jiang(清华大学电子工程系)、Bing Han(上海交通大学计算机科学与工程系)、Tianyu Liu(清华大学电子工程系)、Xinhu Zheng(上海交通大学计算机科学与工程系)、Pingyi Fan(清华大学电子工程系)、Cheng Lu(上海交通大学计算机科学与工程系)、Jia Liu(清华大学电子工程系,Huakong AI Plus)、Wei-Qiang Zhang(清华大学电子工程系)
💡 毒舌点评
亮点:该工作将“参考音频”作为声学锚点引入生成式数据增强是一个巧妙且有效的创新,显著优于纯文本驱动的生成方法,实验结果令人信服。短板:论文的亮点高度依赖于所用TangoFlux生成模型的性能天花板,而ASD检测器本身只是采用了现有的BEATs+ArcFace框架,未能展现出更前沿的检测算法探索;同时,生成过程的计算开销(多步ODE求解)可能限制其实际应用效率,但论文未对此进行讨论。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开微调后的TangoFlux或过滤分类器的权重。
- 数据集:使用公开的DCASE 2023 Task 2数据集,论文中未说明是否公开其处理后的数据或生成的合成数据。
- Demo:未提及。
- 复现材料:论文给出了一些训练细节(如GPU型号、epoch数、音频参数),但缺失生成模型的关键超参数(如学习率、
Steptotal)和过滤器训练的完整细节。 - 论文中引用的开源项目:TangoFlux [18]、BEATs [4]、LoRA [6]、ArcFace [26]、SpecAug [27]。
- 总体开源计划:论文中未提及开源计划。
📌 核心摘要
- 问题:工业异常声音检测面临严重的领域偏移问题,尤其是目标域训练数据稀缺时,模型泛化能力下降。
- 方法核心:提出RefGEN框架,核心是参考引导生成和语义一致性过滤。它利用参考音频在潜在空间中作为“声学锚点”,通过控制噪声注入进行受控插值生成,再利用一个BEATs分类器过滤掉语义不匹配的生成样本。
- 创新:首次将参考音频引入ASD的数据生成增强中,克服了纯文本描述无法捕捉细粒度声学特征的局限;同时引入了显式的质量控制机制(过滤器)确保生成数据的标签保真度。
- 主要实验结果:在DCASE 2023 ASD数据集上,RefGEN的平均谐波平均数(hmean)达到72.12%,超越了当时报告的所有基线方法,包括多个挑战赛顶级方案。消融研究证实了参考引导生成(+0.57%)和过滤机制(+0.44%)各自的贡献。频谱图对比显示,参考引导生成比纯文本生成更好地保留了原始音频的频谱结构。
| 模型 | 开发集 hmean | 评估集 hmean | 全集 hmean |
|---|---|---|---|
| Baseline (真实数据) | 67.30 ± 0.88 | 75.38 ± 1.11 | 71.11 ± 0.89 |
| +Ref-GEN | 67.39 ± 0.91 | 76.55 ± 0.78 | 71.68 ± 0.71 |
| +Filter (完整RefGEN) | 68.61 ± 1.01 | 76.03 ± 0.47 | 72.12 ± 0.43 |
| MSN [33] (强基线) | 70.43 | - | 69.53 |
| RefGEN (Best) | 75.33 | - | 72.68 |
- 实际意义:为解决工业场景中标注数据稀缺和领域偏移问题提供了一种有效的生成式数据增强方案,提升了异常检测模型的鲁棒性和泛化能力。
- 主要局限性:生成样本的多样性仍然受限于参考音频库;过滤器的性能依赖于其在原始数据上训练的属性分类器;生成过程的计算成本可能较高。论文未探讨生成音频对最终ASD模型性能的“量-质”权衡关系。
🏗️ 模型架构
RefGEN是一个四阶段框架,整体架构如图1所示。
- (A) 微调TangoFlux:以预训练的文本到音频(TTA)模型TangoFlux为基础。TangoFlux由6个MMDiT块和18个DiT块组成,运行在VAE编码的潜在空间中。微调时冻结VAE参数,仅优化扩散Transformer组件。输入是基于模板自动生成的音频-文本对,用于将模型适配到工业音频领域。
- (B) 参考引导生成:这是核心创新。给定参考音频
a_ref,先用冻结的VAE编码器得到潜在表示x_ref。生成时,不在潜在空间从纯噪声开始,而是从一个由参考潜在表示和高斯噪声线性插值得到的初始状态x_t_start开始,其中t_start = 1 - α,α是噪声控制系数。然后,使用学到的速度场G_θ通过欧拉方法从t_start积分到1,解码得到合成音频a_gen。这使得生成既能锚定于参考音频的真实特征,又能引入可控的变异性。 - (C) 数据过滤:使用一个在原始DCASE数据集上微调好的BEATs属性分类器
f_ϕ对每个生成样本进行预测。只保留预测属性与生成时使用的条件标签一致的样本(I(a_i, c_i)=1),形成过滤后的合成数据集D_filtered。 - (D) ASD系统:将原始真实数据
D_original与过滤后的合成数据D_filtered合并,用于训练最终的ASD模型。该模型使用BEATs初始化的ViT主干,采用FMQAP进行特征融合,并用ArcFace损失进行微调。推理时,分别为源域和目标域建立KNN检测器,取最小归一化余弦距离作为异常分数。
💡 核心创新点
- 参考引导的声学锚点生成:首次将参考音频在潜在空间的编码作为生成过程的起点和引导信号。相比纯文本提示,这能更精确地捕获目标域的细粒度声学特征,生成更逼真且与上下文相关的样本。实验证明,这比从纯噪声生成(α=1.0)性能提升显著。
- 可控的保真度-多样性权衡:通过插值系数
α和相应的积分步数K,可以精细地控制生成样本相对于参考音频的保真度与引入的随机多样性。实验证明,一个较小的α(如0.1)能取得最佳平衡。 - 语义一致性过滤机制:引入了一个独立的BEATs分类器作为质量过滤器,主动丢弃生成过程中语义不匹配的失败样本。这解决了生成模型可能输出“看似合理但标签错误”样本的问题,确保了增强数据的质量和标签可靠性,提升了最终模型的性能。
🔬 细节详述
- 训练数据:DCASE 2023 Task 2数据集,包含14类机器声音。每类训练集包含990个源域正常音频和10个目标域正常音频。文本描述使用模板自动生成。
- 损失函数:生成模型训练采用流匹配目标(论文未给出具体公式)。ASD模型训练使用ArcFace损失,通过属性分类代理任务学习判别性嵌入。
- 训练策略:TangoFlux微调:4块RTX 3090 GPU,每设备batch size为3,训练80个epoch。ASD模型:单块RTX 3090 GPU,进行5次独立运行取平均。
- 关键超参数:TangoFlux:MMDiT块数6,DiT块数18。ASD模型:ViT主干12层,90M参数,输出256维嵌入。音频处理:25ms窗长,10ms hop,128个Mel滤波器。SpecAug掩码大小80。
- 训练硬件:生成模型微调使用4x RTX 3090,ASD训练使用1x RTX 3090。
- 推理细节:ASD推理时,KNN检测器k=1。生成模型推理时,积分步数
K = α * Steptotal(Steptotal未说明具体值)。 - 正则化或稳定训练技巧:对ASD模型输入应用SpecAug数据增强。
📊 实验结果
主实验:在DCASE 2023数据集上与多个SOTA方法对比,RefGEN在总体谐波平均数(hmean)上达到新高。详细对比见下表。
| 模型 | 开发集 hmean | 评估集 hmean | 全集 hmean |
|---|---|---|---|
| No.1 [28] | 66.97 | - | 67.54 |
| No.2 [29] | 66.39 | - | 66.88 |
| FeatEx [30] | - | - | 67.73 |
| Wilkinghoff [10] | - | - | 68.00 |
| Han et al. [31] | 73.70 | - | 68.65 |
| AnoPatch [3] | 74.23 | - | 68.87 |
| FTE-Net [32] | 71.27 | - | 69.09 |
| MSN [33] | 70.43 | - | 69.53 |
| RefGEN (Avg.) | 76.03 ± 0.47 | - | 72.12 ± 0.43 |
| RefGEN (Best) | 75.33 | - | 72.68 |
消融研究:验证了每个组件的有效性。从基线(71.11%)到加入Ref-GEN(71.68%),再到加入过滤器(72.12%),性能逐步提升。
插值系数α的影响:α=0.1时性能最佳(72.12%)。α=0.0(纯参考)和α=1.0(纯文本)性能均下降,证明了受控插值的必要性。
频谱图对比(见图2):直观展示了参考引导生成(中间行)比纯文本生成(底行)能更好地保留原始音频(顶行)的频谱时频结构和关键特征。
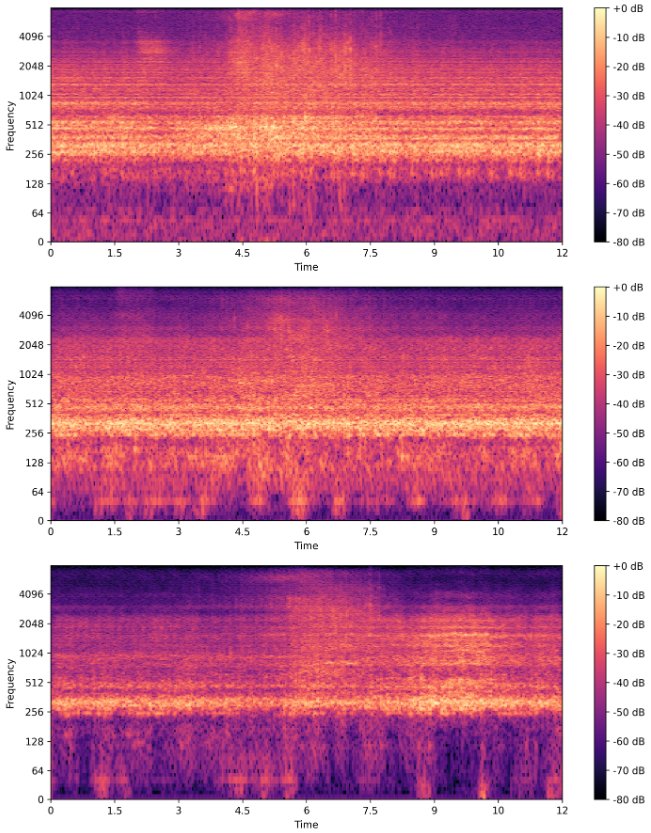 图2:从左到右分别为Valve和ToyTrain类型。每行从上到下:真实音频、参考引导生成、参考引导生成(α=0.1)、参考自由生成(α=1.0)。 结论:参考引导生成能有效平衡保真度和多样性,生成数据的频谱结构更接近真实分布。
图2:从左到右分别为Valve和ToyTrain类型。每行从上到下:真实音频、参考引导生成、参考引导生成(α=0.1)、参考自由生成(α=1.0)。 结论:参考引导生成能有效平衡保真度和多样性,生成数据的频谱结构更接近真实分布。
⚖️ 评分理由
- 学术质量:6.0/7:论文核心创新(参考引导生成)清晰、新颖且有效,技术实现路径严谨。实验设计完整,包含全面的对比和消融分析,数据可信。主要不足在于对生成模型内部机制(如TangoFlux的容量、流匹配的具体实现)探讨较浅,且ASD检测部分属于较强基线的组合,非本文原创。
- 选题价值:1.5/2:针对工业ASD领域的实际痛点(领域偏移、数据稀缺),提出生成式解决方案,具有明确的应用前景和工程价值。对音频生成领域的应用拓展也有参考意义。
- 开源与复现加成:0.0/1:论文未提供代码、模型或详细的训练配置(如
Steptotal值、完整超参数列表),使得生成部分的完全复现存在困难。这限制了工作的可复现性和影响力。