📄 Reference Microphone Selection for Guided Source Separation Based on The Normalized L-P Norm
#语音增强 #波束成形 #麦克风阵列 #语音识别
✅ 7.0/10 | 前50% | #语音增强 | #波束成形 | #麦克风阵列 #语音识别
学术质量 6.5/7 | 选题价值 1.0/2 | 复现加成 0 | 置信度 中
👥 作者与机构
- 第一作者:Anselm Lohmann (Carl von Ossietzky Universit¨at Oldenburg, Dept. of Medical Physics and Acoustics, Germany)
- 通讯作者:未明确说明(论文提供了第一作者邮箱,但未明确标注通讯作者)
- 作者列表:Anselm Lohmann (Carl von Ossietzky Universit¨at Oldenburg, Germany)、Tomohiro Nakatani (NTT, Inc., Japan)、Rintaro Ikeshita (NTT, Inc., Japan)、Marc Delcroix (NTT, Inc., Japan)、Shoko Araki (NTT, Inc., Japan)、Simon Doclo (Carl von Ossietzky Universit¨at Oldenburg, Germany)
💡 毒舌点评
论文敏锐地抓住了分布式麦克风语音增强中“信噪比最优”与“混响鲁棒性”之间的矛盾,并用一个优雅的数学工具(归一化ℓp范数)提出了解决方案,在CHiME-8这种高难度真实数据集上取得了稳定提升。然而,其方法深度绑定于特定的GSS处理流程,创新的“舞台”相对狭小,更像是对现有系统进行精细调优,而非提出一个可独立复用的新范式。
🔗 开源详情
论文中未提及任何关于代码、模型权重、数据集或在线演示的开源计划。论文中引用的开源项目包括:
- Pyroomacoustics:用于模拟房间脉冲响应和生成模拟数据。
- VERSA:论文中引用的非侵入式语音质量评估工具包。
- Torchaudio-Squim:论文中引用的非侵入式语音质量和可懂度度量工具。 复现材料方面,论文���供了部分关键实验参数(如STFT设置、WPE参数等),但完整的系统实现细节(如GSS、波束成形、后滤波器的具体代码)未提供。
📌 核心摘要
- 问题:在基于分布式麦克风的引导源分离(GSS)语音增强前端中,通常选择估计输出信噪比(SNR)最高的麦克风作为参考。但这种方法忽略了不同麦克风信号在早期-晚期混响比(ELR)上的巨大差异,可能无法选出整体信号质量最佳的参考信号,从而影响下游语音识别(ASR)性能。
- 方法核心:提出两种新的参考麦克风选择方法,均基于归一化ℓp范数。第一种方法仅选择归一化ℓp范数最低的波束成形输出(对应最高的信号稀疏性,通常与高ELR相关)。第二种方法将归一化ℓp范数与SNR结合,通过最小化二者的加权归一化和,同时考虑ELR和SNR。
- 新意:将原本用于WPE解混响的归一化ℓp范数参考麦克风选择准则,创新性地应用于包含解混响和噪声抑制的GSS全流程中。特别是,提出了兼顾ELR和SNR的组合选择策略。
- 主要实验结果:在CHiME-8挑战赛的ASR系统上评估,所提方法在多个数据集(尤其是使用空间分布式麦克风的DiP和Mi6数据集)上降低了宏观平均时间约束最小排列词错率(tcpWER)。例如,在使用估计说话人日志时,组合方法(α=0.5)将宏观平均tcpWER从25.5%(基线SNR方法)降至24.4%。关键结果对比如下表:
方法 CH6 DiP Mi6 NSF 宏观平均tcpWER (%) (a)使用Oracle说话人日志 SNR (基线) 24.3 24.2 14.4 13.5 19.1 归一化ℓp范数 24.6 23.1 13.4 13.5 18.7 组合方法 (α=0.5) 24.2 22.9 12.9 13.5 18.4 (b)使用估计说话人日志 SNR (基线) 37.2 28.1 16.1 20.6 25.5 归一化ℓp范数 37.2 26.9 13.8 20.6 24.6 组合方法 (α=0.5) 37.0 26.7 13.3 20.6 24.4 - 实际意义:为分布式麦克风阵列的远场语音识别系统提供了一种更优的前端参考麦克风选择策略,有助于提升复杂声学环境下的ASR鲁棒性。
- 主要局限性:方法的有效性高度依赖于GSS系统的整体流程。组合策略中的权衡参数α需要通过在验证集上搜索确定。论文未探讨该方法对非GSS前端或其他语音任务的适用性。
🏗️ 模型架构
本文研究对象并非一个端到端神经网络模型,而是一个经典的多阶段语音信号处理流程——基于GSS的语音增强前端。其核心是解决该流程中“参考麦克风选择”这一关键步骤的优化问题。
整体架构流程如下图所示:
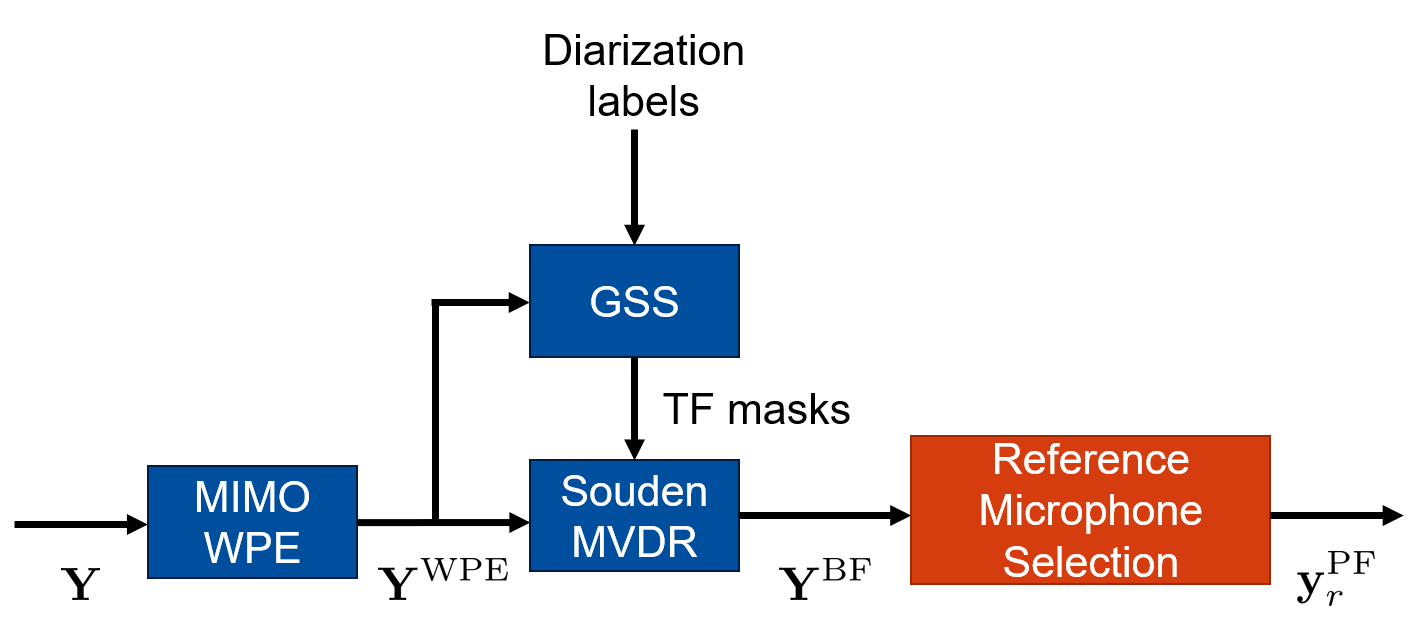
- 输入:M个空间分布式麦克风录制的混合语音信号
Y。 - 第一阶段 - 解混响:使用多输入多输出加权预测误差(MIMO WPE)方法,从混合信号
Y中减去估计的晚期混响分量,输出为Y_WPE。 - 第二阶段 - 噪声抑制:使用Souden最小方差无失真响应(MVDR)波束成形器处理
Y_WPE,输出M路波束成形信号Y_BF。波束成形器的滤波器W由估计的目标语音协方差矩阵R_x和噪声协方差矩阵R_n计算得到,而R_x和R_n则依赖于由引导源分离(GSS)模块计算出的时间-频率掩模μ_x和μ_n。 - 关键创新步骤 - 参考麦克风选择:这是本文的核心改进点。从M路波束成形信号
Y_BF中选择一路作为最终输出。基线方法选择输出SNR最高的路。本文提出的新选择准则包括:- 仅基于归一化ℓp范数:选择
J_{ℓp/ℓ2}(y^BF_m)最小的路,追求信号在时频域的最强稀疏性(对应高ELR)。 - 结合SNR与归一化ℓp范数:选择使
α·J̃_{ℓp/ℓ2}(y^BF_m) + (1-α)·J̃_{NSR}(y^BF_m)最小的路,其中J̃表示跨麦克风的Min-Max归一化值。这旨在同时优化抗噪性和抗混响性。
- 仅基于归一化ℓp范数:选择
- 后处理:对选定的单通道波束成形信号
y^BF_r应用盲分析后滤波器,得到最终增强信号y^PF_r。 - 组件交互:GSS模块利用说话人日志标签,通过复角中心高斯混合模型(cACGMM)估计掩模,指导波束成形器的形成。整个流程是级联的,参考麦克风的选择发生在波束成形之后、后处理之前,其质量直接影响最终输出。
💡 核心创新点
- 将归一化ℓp范数用于GSS全流程的参考麦克风选择:之前的研究将该准则仅用于WPE解混响阶段。本文创新性地将其应用于包含解混响和噪声抑制的GSS整体流程中,直接针对最终增强信号进行选择。
- 提出SNR与归一化ℓp范数的组合选择准则:认识到单一指标(SNR或ℓp范数)的局限性——前者忽略混响,后者在高噪下可能失效。通过简单的加权归一化求和公式,首次提出兼顾输出SNR和信号稀疏性(ELR)的组合选择策略,提供了更全面的优化目标。
- 在CHiME-8挑战赛的复杂真实场景下验证有效性:在业界公认的高难度多说话人远场ASR基准上,通过系统集成实验,定量证明了所提选择方法相比SNR基线能带来稳健的WER降低,特别是在空间分布式麦克风场景下(DiP, Mi6数据集)。
🔬 细节详述
- 训练数据:信号质量评估使用了模拟数据:使用Pyroomacoustics在随机混响时间(200-500 ms)的房间内生成100条混响语音,并添加来自CHiME-6数据集的噪声。ASR评估使用CHiME-8挑战赛的官方开发集和评估集(包含CH6, DiP, Mi6, NSF四个数据集)。
- 损失函数:不适用。本文是信号处理方法,不涉及神经网络训练。
- 训练策略:不适用。
- 关键超参数:
- STFT:采样率16kHz,帧长64ms,帧移16ms,汉宁窗。
- MIMO WPE:稀疏参数
p=0,组矩阵Φ=I,滤波器长度L_g=5,预测延迟τ=2,迭代次数IWPE=3。 - 归一化ℓp范数:
p=0,避免数值问题的小常数ε=10^{-4}。 - GSS:迭代次数
IGSS=5。 - 组合选择策略的权衡参数
α:在CHiME-8开发集上通过网格搜索确定,最终固定为α=0.5。
- 训练硬件:未说明。
- 推理细节:在GSS前端处理流程中,应用所提出的选择准则后,进行后滤波和最终ASR解码。ASR模型为0.6B参数的Conformer-based transducer。
- 正则化或稳定训练技巧:不适用。
📊 实验结果
主要证据来自两部分:模拟数据上的信号质量评估和CHiME-8真实数据上的ASR评估。
- 模拟数据信号质量评估(Table 1)
使用非侵入式指标(DNSMOS, NISQA, SCOREQ, NI-PESQ, NI-STOI)和信号统计量(输出SNR
ôSNR, 输入ELRiELR)进行评估。 (注:原图包含Table 1a和1b)
- 在10 dB输入SNR下:仅使用归一化ℓp范数的方法在所有非侵入式指标上均优于仅使用SNR的基线。组合方法表现介于两者之间,但其选择的麦克风显示出比基线更高的输入ELR(9.56 dB vs 7.79 dB)和相近的输出SNR,体现了对混响的优化。
- 在-10 dB输入SNR下:组合方法在非侵入式指标上略有优势。此时归一化ℓp范数单独使用时性能与基线接近,因为噪声严重影响了信号稀疏性,凸显了结合SNR的必要性。
- 关键结论:输入ELR的趋势与信号质量指标更相关,说明混响对感知质量影响显著;而输出SNR不能完全反映最终信号质量。
- CHiME-8 ASR评估(Table 2 & Fig. 2)
使用宏观平均tcpWER作为主要指标。
- Fig. 2:展示了组合方法中
α参数在开发集上的性能曲线,确定了α=0.5为较优选择。 - Table 2:提供了评估集上的详细WER结果(已在“核心摘要”部分以表格形式列出)。
- 关键结论:
- 对空间分布式麦克风数据集(DiP, Mi6)效果显著:在DiP上,组合方法(估计日志)将tcpWER从28.1%降至26.7%;在Mi6上,从16.1%降至13.3%,降幅明显。
- 对紧密麦克风数据集(NSF)无效:符合预期,因为该场景不存在麦克风间的巨大差异。
- 对复杂房间内分布式阵列(CH6)改进有限:可能由于该数据集本身的复杂性(多个房间)。
- 组合方法一致性优于单一准则:在几乎所有分布式麦克风场景下,组合方法取得了最低的WER。
⚖️ 评分理由
- 学术质量:6.5/7:问题明确,动机合理。将已有工具(ℓp范数)创新性地应用于新场景(GSS全流程),并提出简单有效的组合策略。实验设计全面,从模拟信号质量到真实系统ASR性能,提供了多维度、有说服力的证据。技术实现细节清晰。创新范围较为集中,组合策略较为直接,是主要扣分点。
- 选题价值:1.0/2:解决分布式麦克风ASR系统前端中的一个具体优化问题,具有实际工程价值。对从事相关系统研发的读者有明确参考意义。但问题相对细分,影响范围有限。
- 开源与复现加成:0.0/1:论文未提及任何开源资源。虽然基于公开挑战赛,但完整复现其GSS流程及参数设置仍需额外工作。