📄 Reference-Aware SFM Layers for Intrusive Intelligibility Prediction
#语音评估 #语音大模型 #预训练 #模型评估 #多任务学习
✅ 7.5/10 | 前10% | #语音评估 | #语音大模型 | #预训练 #模型评估
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Hanlin Yu(UBC ECE, Canada)
- 通讯作者:Linkai Li(Stanford EE, USA)、Shan X. Wang(Stanford EE, USA)
- 作者列表:Hanlin Yu(UBC ECE, Canada),Haoshuai Zhou(Orka Labs Inc., China),Boxuan Cao(Orka Labs Inc., China),Changgeng Mo(Orka Labs Inc., China),Linkai Li(Stanford EE, USA),Shan X. Wang(Stanford EE, USA)
💡 毒舌点评
亮点:本文在CPC3挑战赛中成功夺冠,证明了系统整合SFM多层特征与显式参考信号对于侵入式可懂度预测任务的有效性,且消融实验设计系统、结论清晰。短板:核心创新点更偏向于对现有组件的精巧组合与工程优化,缺乏在模型原理层面的根本性突破,且论文未开源代码或模型,限制了其作为可复现基准的价值。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及公开的模型权重。
- 数据集:使用公开的CPC3挑战赛数据集,但论文未说明其获取方式。
- Demo:未提及在线演示。
- 复现材料:论文提供了较为详细的模型结构描述、训练参数(优化器、学习率、batch size、epoch数等)和消融实验设置。但完整的代码、配置文件、预训练检查点及详细预处理步骤均未提供。
- 论文中引用的开源项目:论文引用了两个NVIDIA的预训练语音基础模型作为主干:Canary-1B-flash和parakeet-tdt-0.6b-v2。
- 开源计划:论文中未提及开源计划。
📌 核心摘要
- 问题:传统的侵入式语音可懂度预测方法(依赖于干净参考信号)性能上未能稳定超越非侵入式系统,作者认为主要原因是未能充分利用语音基础模型(SFM)强大的内部表征。
- 方法核心:提出一个侵入式预测框架,将双耳助听器信号与干净参考信号分别输入冻结的SFM(Canary-1B-flash和parakeet-tdt-0.6b-v2)提取中深层(10-16层)表征,并通过多尺度卷积神经网络(MSCNN)前端注入细粒度声学特征。之后,通过跨参考注意力、跨耳注意力以及温度控制的“最佳耳”池化机制进行融合与打分。
- 新意:与之前简单使用SFM的CLS token或浅层特征不同,本文系统探索了SFM的多层聚合策略(通过severity token读出)、显式参考条件化以及双耳融合方式,证明了这些设计选择的协同作用。
- 实验结果:在CPC3的开发集和评估集上,模型RMSE分别达到22.36和24.98,排名第一。消融实验证实了使用SFM中深层特征(优于单层)、包含参考信号、使用severity token进行听者条件化以及“最佳耳”池化(优于双耳平均)的有效性。具体实验结果见下表:
方法/变体 开发集 RMSE 评估集 RMSE HASPI 基线 28.00 29.50 本文方法 (CPC3冠军) 22.36 24.98 CPC3 第二名 [9] 21.87 25.31 CPC3 第三名 [9] 22.80 25.54 使用PTA4数值替代severity token 22.29 25.11 使用PTA8数值替代severity token 23.20 25.30 无severity条件(用CLS替代) 23.88 25.69 无参考信号 22.82 25.39 双耳特征平均池化 22.82 25.29 - 实际意义:为构建基于SFM的侵入式可懂度预测器提供了实用的设计指南,推动了助听器语音质量评估技术的发展。
- 主要局限:模型依赖于大型冻结SFM,计算成本可能较高;实验仅在特定挑战赛数据集(CPC3)上进行,泛化性需更多验证;论文未提供开源代码或模型,限制了可复现性。
🏗️ 模型架构
模型整体为一个端到端的预测管道,输入为双耳(左/右)助听器处理后的信号、一个干净的参考信号以及听者的听力损失严重程度标签,输出为0-100的整句可懂度分数。架构主要包含四个阶段,具体流程如下:
特征提取与前端融合 (A: Front End):
- SFM编码器:左、右耳及参考信号分别输入两个冻结的SFM骨干网络(Canary-1B-flash和parakeet-tdt-0.6b-v2)。模型选择这两个SFM的中深层(具体为第10至16层)的隐藏状态输出。对每一层,对时间维度进行×8的平均池化,得到下采样后的SFM令牌序列。
- MSCNN前端:同时,从对数梅尔频谱图构建一个三分支多尺度膨胀1D卷积网络(MSCNN)。该网络使用不同尺度(3/5/9)和膨胀率(1/2/4)的卷积核,在不降低时间分辨率的前提下,扩大时间感受野,生成全速率的帧级声学嵌入。
- SFM-MSCNN融合:通过一个标准的Transformer交叉注意力模块,将下采样后的SFM令牌作为查询(Query),全速率的MSCNN嵌入作为键(Key)和值(Value)。这一步将细粒度的声学特征注入SFM令牌中,增强模型的鲁棒性。此过程在每个选定的SFM层上独立进行,权重在不同流(左/右/参考)和层之间共享。
时间建模与跨参考融合 (Temporal Stage):
- 将融合后的每个SFM层的令牌序列,通过一个深度为1的时间Transformer。这允许模型在单一层级内建模时间上下文依赖关系。
- 在同一阶段,左、右耳的表示通过跨参考注意力与干净参考表示对齐。这使得每个耳的表示能够直接关注到相同时间窗口内的参考线索。
层级建模与跨耳融合 (Layer Stage):
- 将每个SFM层经时间建模后、并经过时间掩码平均得到的单向量表示,按层顺序堆叠成一个序列。
- 该序列输入一个深度为1的层级Transformer,建模不同SFM层之间的互补关系。
- 在此阶段,每个耳再次通过跨耳参考注意力整合来自参考信号的高层先验知识。
- 最后,应用跨耳注意力,允许左右耳信息交换,使模型能够更倚重听力较好的耳朵。
评分与输出 (Best-Ear Scoring):
- 将“严重程度”令牌(severity token)附加在左、右耳分支在经过所有融合操作后的表示位置。将此令牌的输出向量送入一个共享的多层感知机(MLP)头,分别预测左耳和右耳的分数。
- 采用温度控制的对数求和指数(Log-Sum-Exp)池化(即softmax)将双耳分数合并为最终的整句分数,这被称为“最佳耳”池化。该操作是可微的,并能隐式地选择分数更高的耳朵。
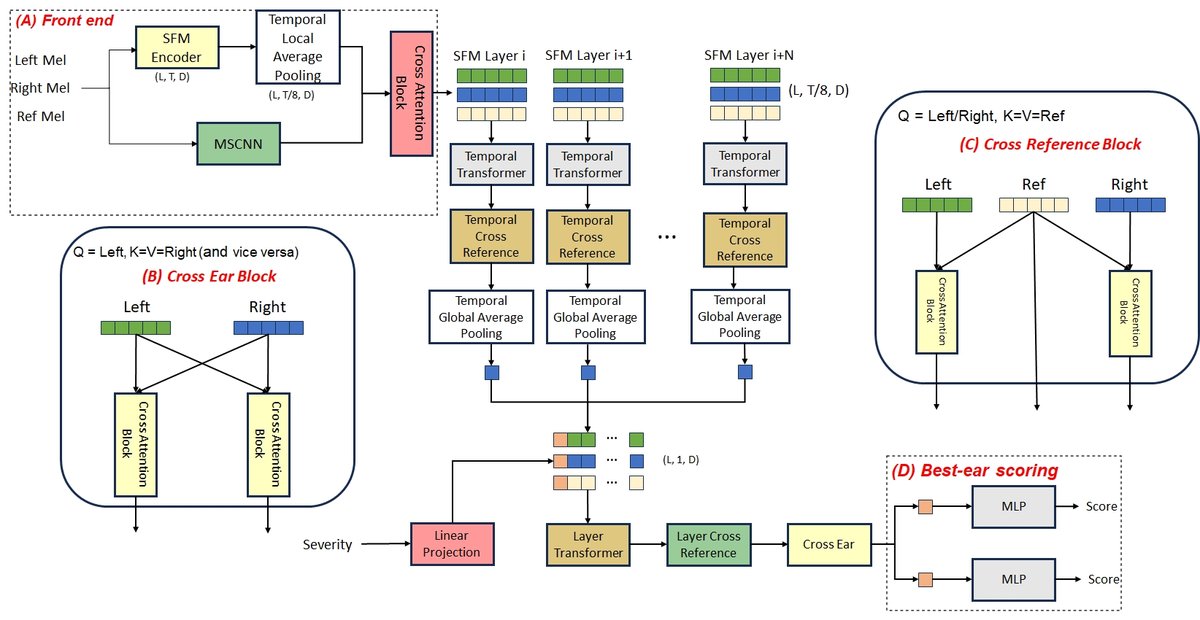 图1展示了该管道:A部分为前端,B部分为跨耳融合,C部分为跨参考融合,D部分为最佳耳评分。它清晰地描绘了SFM与MSCNN的融合、跨参考/跨耳注意力的连接位置以及最终的评分机制。
图1展示了该管道:A部分为前端,B部分为跨耳融合,C部分为跨参考融合,D部分为最佳耳评分。它清晰地描绘了SFM与MSCNN的融合、跨参考/跨耳注意力的连接位置以及最终的评分机制。
💡 核心创新点
- 系统化地在侵入式框架中应用SFM多层表征:不同于以往仅使用SFM的输出层或CLS token,本文系统研究了SFM中深层(10-16层)特征的聚合效果,证明了多层(特别是中深层)聚合能提供更丰富的语言和语音学先验,显著提升预测性能。
- Severity Token条件化读出机制:提出在每个选定的SFM层的令牌序列后附加一个可学习的“严重程度”令牌,并将其在经过所有注意力和融合层后的输出作为该层的最终表示。实验证明,这种方式比简单的均值池化或CLS池化更能有效整合听者特定的听力损失信息,提升模型对不同听者的泛化能力。
- 多阶段的跨参考与跨耳注意力融合:在特征提取、时间建模和层级建模三个阶段都设计了与参考信号或另一耳的交叉注意力机制。这种深度的、多层次的条件化设计,使得模型能够充分、持续地利用干净参考和双耳信息,是性能超越简单基线(如无参考、双耳平均)的关键。
🔬 细节详述
- 训练数据:使用Clarity Prediction Challenge 3 (CPC3) 官方数据集。训练过程采用5折听者级别的交叉验证,每折验证集包含6名听者(2轻度、2中度、2中重度听力损失)。
- 损失函数:未明确提及具体损失函数名称,但指出训练目标是最小化预测分数与真实可懂度分数之间的均方根误差(RMSE)。
- 训练策略:
- 优化器:AdamW,学习率 3 × 10⁻⁵,权重衰减 10⁻²。
- 批次大小:8。
- 训练轮数:9个epoch。
- 使用混合精度训练。
- 最佳耳池化温度参数 β = 6。
- 语音基础模型(SFM)在训练过程中保持冻结。
- 关键超参数:
- 模型主干:NVIDIA Canary-1B-flash(32层,1024维隐藏状态)和parakeet-tdt-0.6b-v2(同架构)。
- 选用的SFM层:第10至16层。
- MSCNN:三分支膨胀1D CNN,卷积核大小3/5/9,膨胀率1/2/4,填充方式为SAME,步长1。
- 交叉注意力模块:标准的Transformer交叉注意力,带残差连接、LayerNorm和门控FFN(SiLU + GLU + dropout)。
- 时间/层级Transformer深度均为1。
- 训练硬件:未提供具体GPU/TPU型号、数量和训练时长信息。
- 推理细节:对于开发集和评估集,运行全部五个折的模型检查点,并对每个句子的预测结果取平均值。
- 正则化技巧:在交叉注意力模块的FFN中使用了dropout。模型主体使用混合精度训练。
📊 实验结果
主要Benchmark结果: 论文在CPC3挑战赛上进行了评估,主要指标是RMSE(越低越好)。最终结果如下表所示:
| 方法/变体 | 开发集 RMSE | 评估集 RMSE |
|---|---|---|
| HASPI 基线 | 28.00 | 29.50 |
| 本文方法 (CPC3冠军) | 22.36 | 24.98 |
| CPC3 第二名 [9] | 21.87 | 25.31 |
| CPC3 第三名 [9] | 22.80 | 25.54 |
关键消融实验及分析:
- 严重程度条件化:
- PTA4数值(替代severity token)表现相当(22.29/25.11)。
- PTA8(扩展频率范围)性能下降(23.20/25.30),说明额外高频信息可能引入噪声。
- 完全移除严重程度信息(用CLS替代)性能下降最明显(23.88/25.69),证实了听者条件化的重要性。
- 参考信号使用:
- 去除参考信号流和所有跨参考模块后,Dev和Eval RMSE均上升(22.82/25.39),表明即使有强SFM,显式参考条件化仍有益。
- 双耳融合策略:
- “最佳耳”池化(默认)优于“双耳特征平均”(22.82 vs. 22.36 on Dev),符合“听力主要由较好耳朵决定”的直觉。
- SFM层选择消融:
- 单层选择(窗口=1):在Canary-1B-flash上,CLS池化(Setup C)在L20达到最佳RMSE 23.99,优于均值池化(Setup B)在L12的24.00。
- 四层块选择(窗口=4):如图3所示,所有方法在层12-15区块表现最佳。此时,本文提出的severity token读出方法(Setup A)在层12-15上达到最佳RMSE 22.89,显著优于CLS(23.70)和均值池化(23.85)。这证实了多层聚合和听者条件化读出的优越性。
- 在Parakeet模型上的验证:类似地,Setup A在层12-15区块上也表现最佳(RMSE 23.02)(图4)。
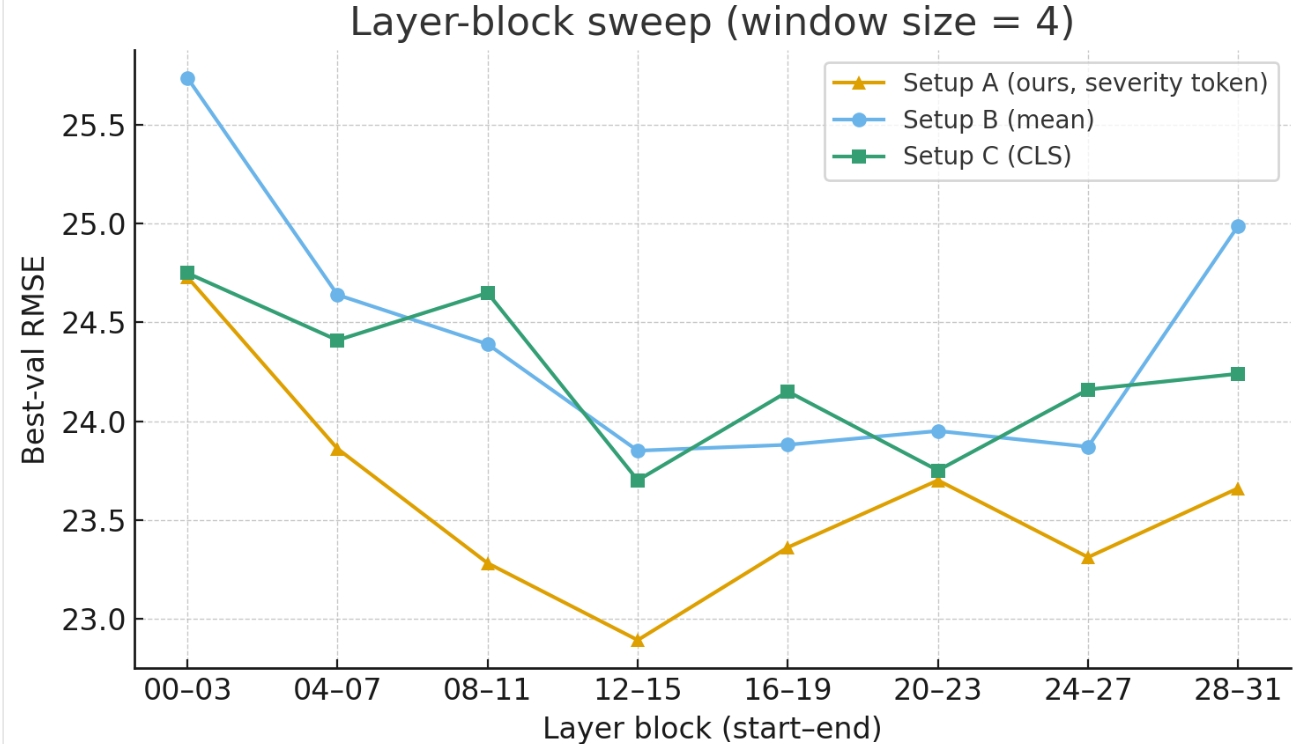 图2显示了在Canary-1B-flash上进行单层扫描(窗口=1)时,Setup C(CLS)在L20和Setup B(均值)在L21获得最低验证集RMSE。
图2显示了在Canary-1B-flash上进行单层扫描(窗口=1)时,Setup C(CLS)在L20和Setup B(均值)在L21获得最低验证集RMSE。
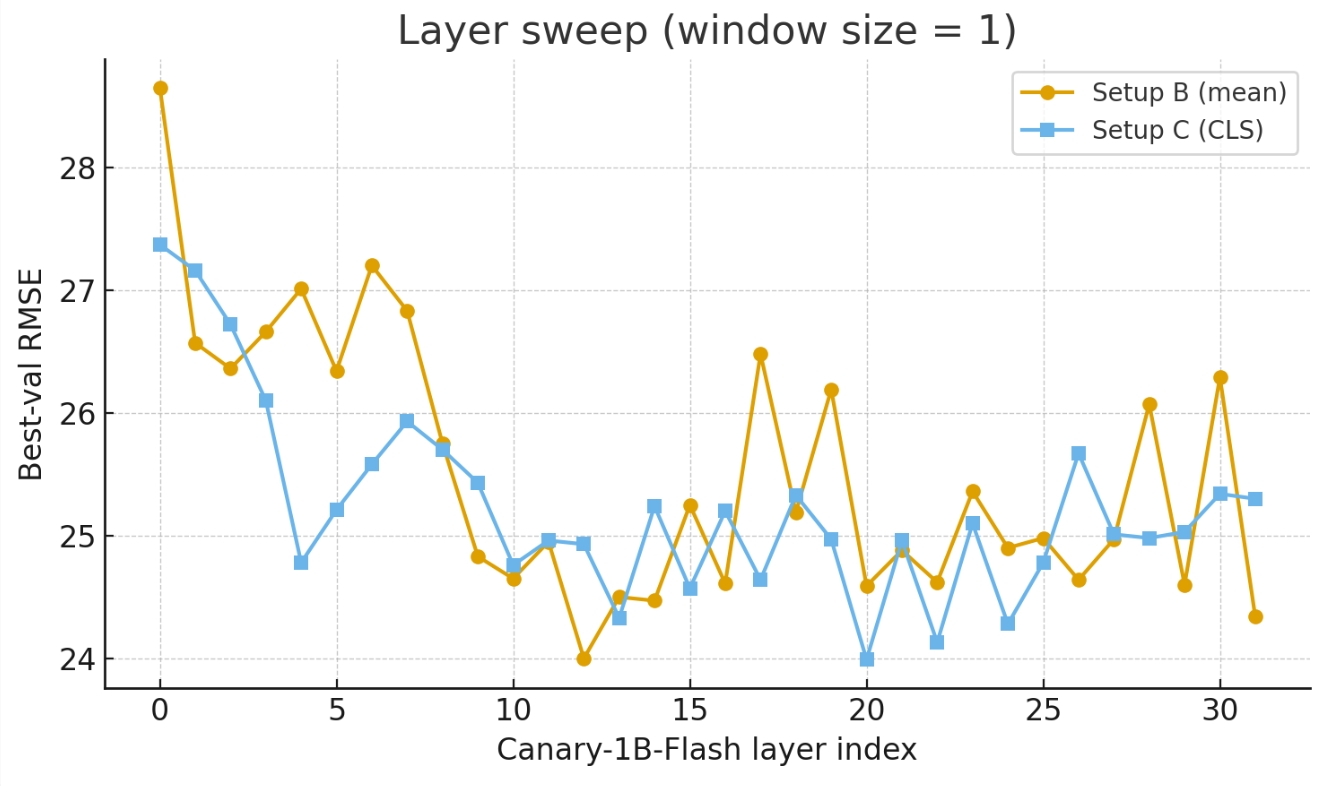 图3比较了在四层窗口下,三种读出方式在Canary-1B-flash上的表现。Setup A(severity token)在层12-15块上取得最佳RMSE。
图3比较了在四层窗口下,三种读出方式在Canary-1B-flash上的表现。Setup A(severity token)在层12-15块上取得最佳RMSE。
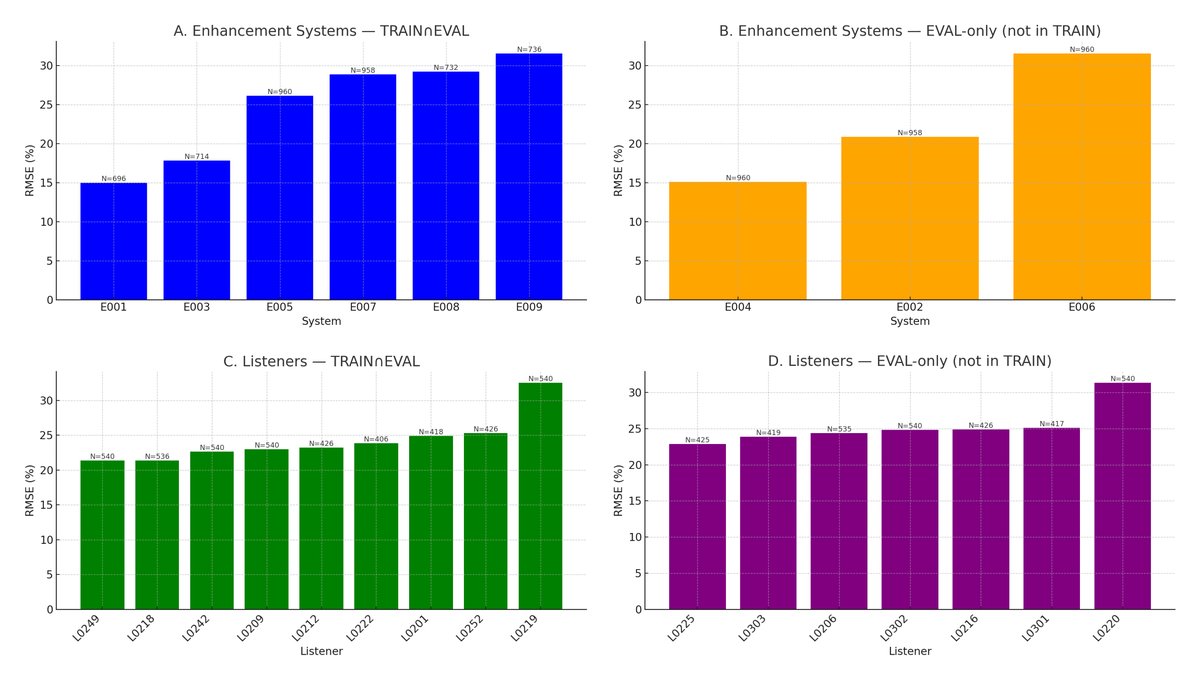 图4显示了在parakeet-tdt-0.6b-v2模型上的层选择,Setup A和均值池化基线都倾向于中深层(12-15),峰值在12-15块(23.02)。
图4显示了在parakeet-tdt-0.6b-v2模型上的层选择,Setup A和均值池化基线都倾向于中深层(12-15),峰值在12-15块(23.02)。
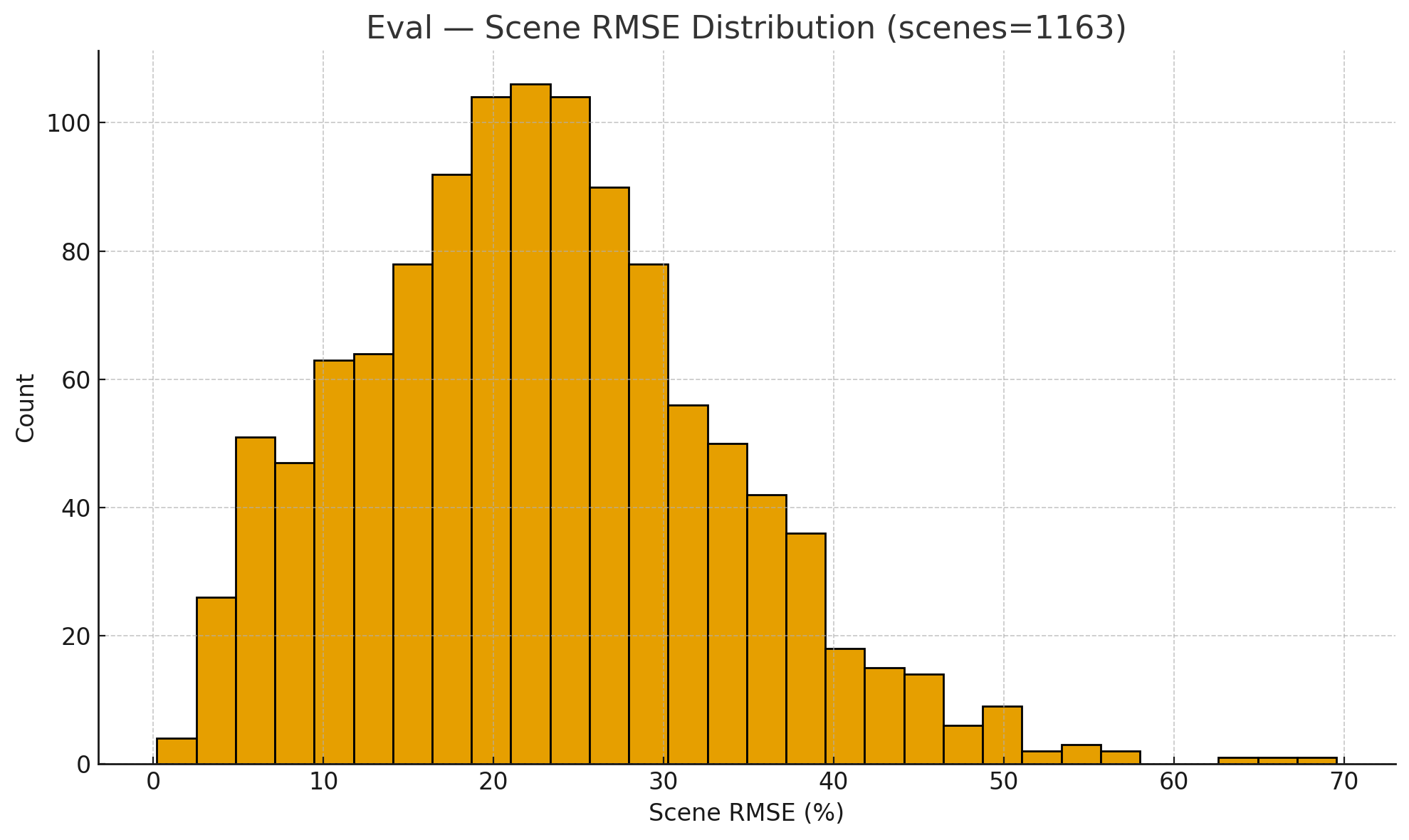 图5对评估集误差进行分层分析。(A)训练集和评估集共有的系统,(B)仅评估集系统,(C)训练集见过的听者,(D)仅评估集听者。观察到模型对训练集见过的听者(C)预测更好。
图5对评估集误差进行分层分析。(A)训练集和评估集共有的系统,(B)仅评估集系统,(C)训练集见过的听者,(D)仅评估集听者。观察到模型对训练集见过的听者(C)预测更好。
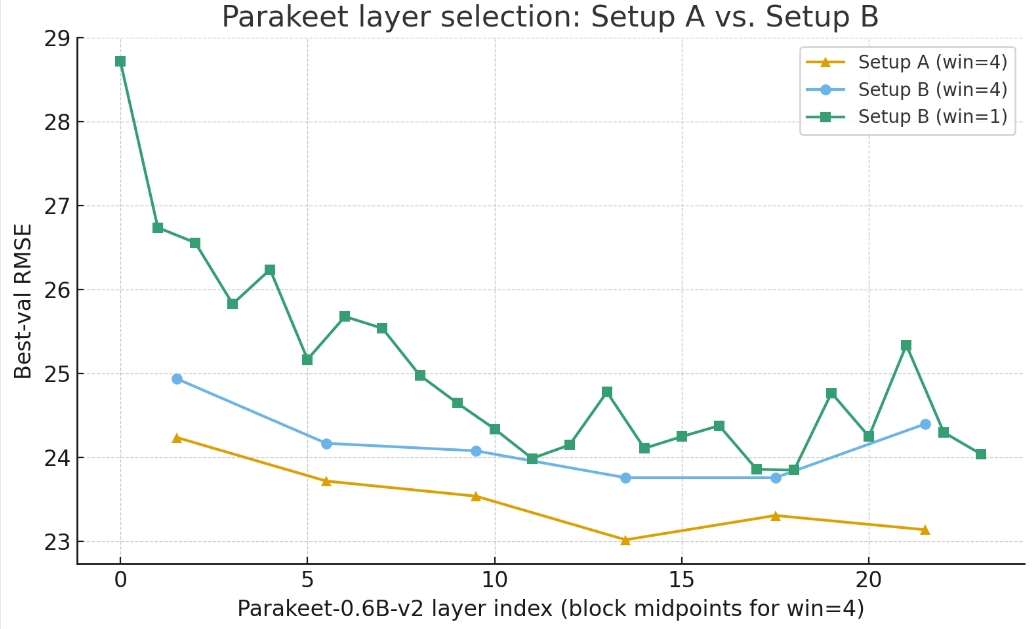 图6展示了1163个评估场景的RMSE分布直方图,呈右偏态。大多数场景RMSE在15-30之间,但有少量(约6%)RMSE超过40的难题场景拉高了整体误差。
图6展示了1163个评估场景的RMSE分布直方图,呈右偏态。大多数场景RMSE在15-30之间,但有少量(约6%)RMSE超过40的难题场景拉高了整体误差。
⚖️ 评分理由
- 学术质量:6.5/7。本文在特定任务上取得了SOTA结果,系统设计和消融研究严谨、深入,清晰地展示了各个组件(SFM多层、参考、听者条件化)的贡献。技术实现正确,实验数据充分可信。创新性主要体现在对现有技术的创造性整合与系统优化上,而非提出全新的模型范式。
- ��题价值:1.5/2。研究聚焦于听力障碍人群的语音评估,是具有明确社会价值和应用前景的垂直领域。模型利用SFM表征进行评估的思路具有可迁移性,对音频质量评估等相关领域有参考价值。
- 开源与复现加成:0.5/1。论文提供了相当丰富的模型架构、训练策略和超参数细节,有利于同行理解方法。但关键的代码、预训练模型权重、完整的数据预处理流程以及训练硬件信息均未公开,这使得独立复现该工作的成本较高,限制了其作为可复现基准的贡献。