📄 Real-Time Streaming MEL Vocoding with Generative Flow Matching
#语音合成 #流匹配 #流式处理 #实时处理 #信号处理
✅ 7.5/10 | 前25% | #语音合成 | #流匹配 | #流式处理 #实时处理
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 1 | 置信度 高
👥 作者与机构
- 第一作者:Simon Welker (汉堡大学信息系信号处理组)
- 通讯作者:未说明
- 作者列表:Simon Welker (汉堡大学信息系信号处理组)、Tal Peer (汉堡大学信息系信号处理组)、Timo Gerkmann (汉堡大学信息系信号处理组)
💡 毒舌点评
本文成功地将前沿的生成式流匹配模型“塞”进了实时流式处理的严苛约束里,并拿出了一套从DNN架构到推理缓存的完整解决方案,这工程落地能力值得肯定。然而,其核心贡献在于优化而非范式革命,48ms的总延迟虽比扩散缓冲方案短得多,但对于追求极致低延迟的实时交互(如实时游戏语音)来说,可能仍非最优解。
🔗 开源详情
- 代码:提供代码仓库链接:https://github.com/sp-uhh/melflow。
- 模型权重:论文中明确承诺提供模型检查点(“we provide… the first public code repository and model checkpoint for streamable Mel vocoding”)。
- 数据集:训练数据为公开的EARS-WHAM v2数据集;评估使用了EARS-WHAM v2和LibriTTS的公开测试集。
- Demo:论文中未提及提供在线演示。
- 复现材料:提供了较为详细的训练配置(数据集、优化器、学习率调度、batch size、训练轮数等)。代码仓库本身也是重要的复现材料。
- 论文中引用的开源项目:SpeechBrain (用于提供HiFi-GAN基线), FlowDec (用于流匹配框架), Continual Inference Networks (用于流式推理参考)。
📌 核心摘要
- 要解决什么问题:解决将梅尔频谱图实时流式地转换为高质量波形(即Mel声码)的问题,这是许多文本到语音(TTS)系统的关键环节,尤其适用于需要自然、实时交互的场景。
- 方法核心是什么:结合了基于生成流匹配的先驱工作(DiffPhase)和FreeV中利用梅尔滤波器伪逆算子初始化的思想,提出了MelFlow。核心是设计了一个帧因果(frame-causal)的生成式DNN,并配套一个无需增加额外算法延迟的高效缓存推理方案,实现了流式处理。
- 与已有方法相比新在哪里:据作者所知,这是首次探索基于扩散/流模型的流式Mel声码。与HiFi-GAN等非流式生成模型相比,它实现了实时流式处理能力;与传统的Diffusion Buffer方案相比,它实现了更低的算法延迟(32ms窗+16ms跳=48ms)。其提出的缓存推理方案是实现高效流式扩散/流推理的关键创新。
- 主要实验结果如何:在EARS-WHAM v2和LibriTTS数据集上,MelFlow(N=5步)在PESQ(4.12/3.97)和SI-SDR(-8.8/-14.5)等指标上显著优于16kHz HiFi-GAN(2.99/3.03, -29.9/-25.8)等强基线,同时保持了有竞争力的非侵入式质量指标。其N=25步版本(非流式)进一步提升了性能,接近或超越所有基线。在NVIDIA RTX 4080 Laptop GPU上,处理单帧的时间为 N×2.71ms,N=5时满足16ms帧移的实时要求。
- 实际意义是什么:为构建低延迟、高质量的实时对话式TTS系统提供了一个关键的流式声码器组件。其开源的代码和模型检查点将促进社区在实时生成式语音处理方面的研究与应用。
- 主要局限性是什么:模型参数量较大(27.9M),可能对边缘部署构成挑战;尽管实现了实时流式,但其48ms的总延迟仍然高于一些传统非生成式声码器;在非侵入式指标(如LSD, MCD)上并非最优,表明其在频谱精细结构恢复上可能与特定任务优化的模型有差距。
🏗️ 模型架构
MelFlow的整体流程是一个“生成式增强”过程:
- 输入:一个16kHz语音的梅尔频谱图序列
M|X[t]|。 - 伪逆初始化:首先,对每个时间帧
t的梅尔帧应用梅尔滤波器组M的Moore-Penrose伪逆M†,并取绝对值,得到一个退化的STFT幅度谱估计Y[t] = ||M†M|X[t]|| + 0j(零相位初始化)。这步操作廉价且逐帧进行,是流式的。 - 生成式流匹配增强:将上述估计
Y[t]作为起点,输入到一个帧因果的生成式DNNfθ中。该DNN通过N步(论文默认N=5)流匹配推理(可视为ODE求解),迭代地增强Y[t]序列,最终输出一个更精确的复数STFT系数估计YN[t]。 - 输出:对
YN[t]应用iSTFT,即可得到输出波形。
DNN架构(自定义帧因果DNN):
- 基于NCSN++ U-Net架构改造,专为流式处理设计。
- 核心改动:所有卷积替换为因果卷积(通过零填充实现),确保输出帧
t仅依赖于输入帧t及之前的信息。 - 时间维处理:不沿时间维度进行下/上采样,而是在原本时间下采样的位置使用膨胀率为2的卷积来扩展感受野。
- 归一化:用子带分组BatchNorm(频率4组+原通道分组)替代了非因果的GroupNorm。
- 其他:移除了注意力层;使用加法(而非拼接)进行特征融合;每个级别使用2个ResNet块,共3级下采样。
- 参数量:27.9 M。
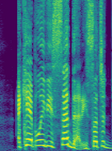
- 推理缓存方案:这是实现高效流式推理的关键。如图1(论文图1)所示,对于因果DNN,每层只需维护一个大小为
(k-1)帧的滚动缓冲区B。当新帧到达时,只需用最新帧和缓冲区计算该层的输出帧。对于需要N次DNN调用的流匹配推理,则维护N组独立的缓冲区集合{B_n,l}。此方案避免了重复计算,且与离线处理结果完全一致,实现了无额外算法延迟的流式推理。
💡 核心创新点
- 首个用于Mel声码的流式生成流模型:将生成式流匹配模型应用于实时、帧级处理的Mel频谱图逆变换任务,填补了该领域的空白,证明了生成模型在此类实时任务中的可行性。
- 无额外延迟的高效缓存推理方案:针对因果DNN和多次调用的流匹配过程,设计了一套缓存机制。它使得流式推理的计算量与离线处理完全相同,并精确实现了由DNN感受野定义的算法延迟(本工作为32ms),没有引入Diffusion Buffer方案中的额外延迟(其最小为340ms)。
- 结合伪逆初始化的生成式Mel声码:借鉴FreeV的思想,利用梅尔伪逆
M†提供一个频谱上粗略但合理的初始化点Y。这不仅将相位恢复问题扩展为更完整的STFT增强问题,还可能引导生成过程更快收敛到合理解,提升了效率与质量。 - 专为流式设计的帧因果DNN:对标准的U-Net(NCSN++)进行了系统性改造,通过因果卷积、时间维度膨胀以及归一化层替换等,构建了一个严格满足流式处理要求、且能有效建模长时依赖的生成网络。
🔬 细节详述
- 训练数据:使用EARS-WHAM v2数据集的干净语音,约87小时,从48kHz下采样到16kHz。
- 损失函数:采用插值流匹配目标(Interpolating Flow Matching Objective),具体损失函数形式未在正文中给出公式,但引用了FlowDec [8]。
- 训练策略:
- 优化器:SOAP优化器。
- 学习率调度:余弦退火调度,从
λ = 5e-4到λ = 1e-6,前1000步线性预热。 - 批大小:12(在4块GPU上)。
- 训练轮数:200 epochs(约140k步)。
- 关键超参数:
- 模型参数量:27.9 M。
- 流匹配噪声水平:
σ_y = 0.25。 - STFT幅度压缩指数:
α = 0.5。 - 流匹配推理步数:默认
N = 5(流式),对比使用N = 25(非流式)。 - 算法延迟:STFT窗长32ms(512点),帧移16ms,故算法延迟32ms,总延迟32ms + 16ms = 48ms。
- 训练硬件:未明确说明GPU型号,仅提及“four GPUs”。
- 推理细节:
- 在NVIDIA RTX 4080 Laptop GPU上测试,单次DNN调用耗时约2.71ms。
- 实现流式处理要求
N * 2.71ms < 16ms(帧移),因此N=5是实时可行的上限。
- 正则化或稳定训练技巧:未提及使用权重指数移动平均(EMA)。
📊 实验结果
主要对比实验结果(表1,论文Table 1):
| 数据集 / 方法 | PESQ↑ | ESTOI↑ | SISDR↑ | DistillMOS↑ | WVMOS↑ | WER↓ | NISQA↑ | LSD↓ | MCD↓ | 流式(S) |
|---|---|---|---|---|---|---|---|---|---|---|
| EARS-WHAM V2 (16 KHZ) | ||||||||||
| M† + RTISI-DM | 2.86 | 0.88 | -29.1 | 2.66 | 2.04 | 7.5% | 2.82 | 0.91 | 2.95 | ✔ |
| HiFi-GAN (SB) | 2.99 | 0.90 | -29.9 | 4.21 | 3.02 | 7.3% | 3.91 | 0.77 | 2.41 | ✖ |
| MelFlow (N=5, ours) | 4.12 | 0.96 | -8.8 | 4.32 | 3.15 | 7.2% | 4.14 | 1.00 | 3.28 | ✔ |
| MelFlow (N=1, ours) | 1.40 | 0.39 | -3.8 | 1.21 | 1.33 | 82.5% | 1.38 | 7.88 | 12.40 | ✔ |
| MelFlow (N=25, ours) | 4.25 | 0.96 | -10.6 | 4.34 | 3.28 | 7.2% | 4.07 | 0.70 | 1.70 | (✖) |
| LIBRITTS (16 KHZ) | ||||||||||
| M† + RTISI-DM | 2.67 | 0.89 | -25.6 | 2.56 | 2.64 | 5.4% | 2.84 | 0.96 | 2.90 | ✔ |
| HiFi-GAN (SB) | 3.03 | 0.92 | -25.8 | 4.02 | 3.86 | 5.1% | 4.06 | 0.87 | 2.09 | ✖ |
| MelFlow (N=5, ours) | 3.97 | 0.95 | -14.5 | 4.08 | 3.67 | 3.5% | 4.32 | 1.12 | 2.90 | ✔ |
关键结论:
- 显著优势:MelFlow (N=5) 在训练集(EARS-WHAM v2)和测试集(LibriTTS)上的PESQ和SI-SDR指标上均大幅优于所有基线,包括非流式的HiFi-GAN,表明其在语音质量和抗噪鲁棒性上具有明显优势。
- 流式能力:MelFlow (N=5) 是唯一在取得顶尖客观质量指标的同时实现流式处理(✔)的方法。
- 多步推理有效性:N=1的MelFlow完全失效,证明了多步生成过程的必要性。N=25的版本进一步提升了质量,尤其在LSD和MCD上表现更佳,展示了该模型架构在计算不受限时的潜力。
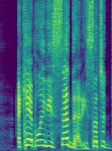
- 频谱恢复能力:从图2(论文Fig. 2)的频谱对比可以看出,MelFlow(尤其是N=25)比HiFi-GAN能更好地恢复语音的高次谐波结构,这可能是其PESQ等指标提升的原因之一。
⚖️ 评分理由
- 学术质量:6.5/7
- 创新性:将流匹配模型应用于实时流式Mel声码,并设计了配套的因果DNN和高效缓存推理方案,组合创新明确且有效。
- 技术正确性:方法推导清晰(如缓存方案),实验设计合理(包含不同步数消融、与多种基线对比),结论有数据支撑。
- 实验充分性:在两个主要数据集上进行了广泛对比,评估指标全面(侵入式、非侵入式、WER)。提供了流式处理的实测延迟数据。
- 证据可信度:实验结果清晰,主要指标提升显著,频谱图示例直观。论文提供了代码和模型权重承诺。
- 选题价值:1.5/2
- 前沿性:实时生成式语音处理是当前热点,本文解决了其中的一个具体但重要的组件问题。
- 潜在影响与应用空间:直接面向低延迟交互式TTS系统的实用需求,具有明确的应用前景。
- 读者相关性:对从事语音合成、音频处理、实时系统开发的学者和工程师有较高参考价值。
- 开源与复现加成:1.0/1
- 论文提供了明确的代码仓库链接(https://github.com/sp-uhh/melflow),并表示将提供模型检查点。
- 训练数据集(EARS-WHAM v2)是公开可用的。
- 核心训练超参数和策略描述详细,复现门槛较低。