📄 RCAL: Reinforced Cross-Modal Alignment for Multimodal Sentiment Analysis with Sparse Visual Frames
#多模态模型 #对比学习 #稀疏输入 #跨模态 #工业应用
🔥 8.5/10 | 前25% | #多模态模型 | #对比学习 | #稀疏输入 #跨模态
学术质量 6.0/7 | 选题价值 1.8/2 | 复现加成 0.8 | 置信度 高
👥 作者与机构
- 第一作者:Xinwei Song(Northeastern University, Khoury College of Computer Science, Portland, ME, United States)
- 通讯作者:未说明
- 作者列表:Xinwei Song(Northeastern University),Xinran Tao(Northeastern University),Jiachuan Wu(Northeastern University),Tala Talaei Khoei(Northeastern University)
💡 毒舌点评
这篇论文的亮点在于其“问题导向”的设计哲学,精准地击中了多模态情感分析从实验室走向真实部署时的核心痛点——视觉信息的稀疏与不稳定,并为此构建了一个闭环的记忆修复系统。然而,其消融实验虽证明了各模块有效性,但未能更深入地揭示在不同稀疏程度(如少于5帧)下各组件贡献度的变化规律,框架的复杂度提升与性能增益之间的权衡关系值得进一步量化。
🔗 开源详情
- 代码:提供了GitHub仓库链接:https://github.com/XinweiSong1018/RCAL。
- 模型权重:论文中未明确提及是否公开预训练或训练好的RCAL模型权重。
- 数据集:使用的是CMU-MOSI, CMU-MOSEI, CH-SIMS等公开数据集,获取方式未在论文中说明。
- Demo:未提及提供在线演示。
- 复现材料:提供了代码,这通常包含了训练脚本、模型定义和部分配置。具体的训练细节(如超参数表)需要阅读代码或附录(论文未提供附录)。
- 论文中引用的开源项目:提到了作为基线对比的多个模型代码库(来自SENA [8]和KuDA [9]平台),以及使用的预训练模型(BERT, ResNet)。
📌 核心摘要
- 问题:现有的多模态情感分析方法大多依赖密集、高质量的视频流,但在远程医疗、驾驶员监控、隐私保护等真实场景中,视觉输入往往极度稀疏(仅5-10帧),导致视觉线索不完整且不稳定,破坏了其在多模态融合中的锚点作用。
- 方法核心:提出RCAL(强化跨模态对齐)框架,以视觉为中心,专门处理极端视觉稀疏下的情感分析。其核心是三个互补组件:(i) 迭代记忆精炼,通过闭环循环从有限帧中逐步重建情感相关线索;(ii) 强化学习门控,自适应地决定何时将对齐后的音频-文本线索注入视觉记忆;(iii) 情感感知对比损失,根据情感相似性结构化视觉嵌入空间。
- 与已有方法相比新在哪:不同于先前假设密集视觉并进行单次前馈融合的方法(如ALMT),RCAL引入了持久的视觉记忆(
hv_hyper),并设计了“更新-反馈”的迭代精炼循环,主动修复缺失的视觉证据。同时,使用离散的强化学习门控(而非软门控)来做出更尖锐的“开/关”决策,以更好地过滤噪声跨模态线索。 - 主要实验结果:RCAL在MOSI、MOSEI和CH-SIMS三个基准数据集上取得了SOTA性能。关键结果如下表所示(指标:MAE↓, Corr↑, Acc-7/5↑)。即使只使用5帧输入,RCAL也超过了使用全帧的多数基线模型;使用全帧输入时性能进一步提升。
数据集 模型 MAE Corr Acc MOSI RCAL (5帧/全帧) 0.665/0.641 0.819/0.848 48.03/52.14 次优基线 (KuDA) 0.705 0.795 47.08 MOSEI RCAL (5帧/全帧) 0.527/0.503 0.753/0.787 54.19/55.26 次优基线 (KuDA) 0.529 0.776 52.89 CH-SIMS RCAL (5帧/全帧) 0.407/0.395 0.604/0.612 45.08/47.92 次优基线 (KuDA) 0.408 0.613 43.54 消融实验表明,记忆精炼模块是性能最关键的贡献者。 - 实际意义:为带宽受限、隐私敏感或实时性要求高的实际情感计算应用(如远程诊疗、司机状态监控)提供了一个高效、鲁棒的实用解决方案,推理延迟低于5毫秒。
- 主要局限性:(1) 框架引入了多个组件和迭代循环,其计算开销和训练复杂度相对于简单融合模型有所增加;(2) 论文主要关注固定稀疏度(如5帧)的性能,对动态变化或极端稀疏(如1-2帧)情况下的自适应能力探讨有限;(3) 视觉记忆的迭代精炼本质上是序列化操作,可能影响并行化效率。
🏗️ 模型架构
RCAL是一个以视觉为中心的多模态情感分析框架,其整体流程如下图所示。
 输入:稀疏的视觉帧(经过采样)、文本序列、音频波形。
输入:稀疏的视觉帧(经过采样)、文本序列、音频波形。
- 模态编码:
- 视觉:使用预训练ResNet提取帧级特征,投影到d维空间,再通过多层Transformer编码器(L层)得到层级视觉表示
h(i)_v。 - 文本:使用BERT编码,得到文本表示
h_l。 - 音频:经过线性投影后,由一个Transformer编码器处理,得到音频表示
h_a。
- 视觉:使用预训练ResNet提取帧级特征,投影到d维空间,再通过多层Transformer编码器(L层)得到层级视觉表示
- 核心模块 - RCAL Block (迭代记忆精炼):
RCAL由L个堆叠的RCAL块组成,每个块包含“记忆更新”和“记忆反馈”两个阶段,如图2所示。
- Stage A: 记忆更新:一个全局的视觉记忆
hv_hyper(初始化为可学习参数或零)通过多头注意力(MHA)整合当前层的视觉表示h(i)_v与文本h_l、音频h_a的信息。同时,一个关键的“强化学习门控”控制是否将“音频-文本交互”h_la注入记忆。更新公式:hv_hyper ← hv_hyper + MHA(h(i)_v, h_a, h_a) + MHA(h(i)_v, h_l, h_l) + h_used,(i)_la。 - Stage B: 记忆反馈:更新后的记忆
hv_hyper被投影并经过一个Transformer层,反馈回视觉流,指导下一层的视觉编码:h(i+1)_v ← h(i+1)_v + Transformer_pred(Proj_fb(hv_hyper))。 这个更新-反馈循环使记忆能迭代地积累跨越帧的、稳定的情感线索。
- Stage A: 记忆更新:一个全局的视觉记忆
- 自适应门控:
在每个RCAL块内,门控机制决定是否注入音频-文本交互信息。它首先计算一个候选音频-文本交互
h(i)_la(通过文本查询音频的交叉注意力)。然后,将h(i)_la的[CLS] token与当前记忆hv_hyper的[CLS] token拼接,投影得到一个标量分数z(i)。通过伯努利采样得到一个二元门g(i),用于决定是否使用h(i)_la(h_used,(i)_la = g(i) * h(i)_la)。门控网络使用策略梯度强化学习训练,奖励信号是下游情感回归的损失改善。 - 输出与损失:
- 最终的视觉记忆
hv_hyper与最后一层的视觉特征h(L)_v通过交叉注意力融合。 - 融合特征送入回归头,预测情感分数,计算MSE损失
L_reg。 - 同时,从记忆
hv_hyper中导出压缩嵌入,计算情感感知的对比损失L_contrast,拉近情感标签相近的样本,推远标签差异大的样本。总损失L = L_reg + λ L_contrast。
- 最终的视觉记忆
💡 核心创新点
- 闭环迭代视觉记忆精炼:针对视觉稀疏问题,提出了一种“更新-反馈”的闭环精炼机制。不同于传统的单次前馈跨模态融合,RCAL维护一个持久的视觉记忆
hv_hyper,在L个块中迭代地吸收多模态线索并反馈引导视觉编码器。这实现了对缺失视觉信息的主动修复和累积,是框架的核心。 - 离散强化学习跨模态门控:在视觉精炼循环中,引入了一个基于强化学习训练的二值门控。它能根据当前状态(视觉记忆与候选跨模态信息)做出“是否融合”的离散决策。这种硬门控相比软门控能更有效地过滤因视觉缺失可能导致的噪声或冲突的跨模态信息,尤其适用于不确定场景。
- 情感感知对比损失:为了稳定稀疏视觉输入下不稳定的嵌入空间,提出了一种以情感标签亲和度为权重的对比损失。它作为正则化器,强制模型在嵌入空间中按情感相似性组织样本,为回归任务提供全局一致性约束,增强了表征的鲁棒性。
- 面向极端稀疏的系统设计:论文的核心价值在于其明确的“为稀疏而设计”的理念。从问题定义、模型组件(如记忆修复、条件融合)到评估设置(重点对比5帧输入),都紧密围绕真实场景中的视觉信息缺失问题展开,具有很强的场景针对性和实用价值。
🔬 细节详述
- 训练数据:使用了三个公开基准数据集:CMU-MOSI(2199段,英文)、CMU-MOSEI(22856段,英文)和CH-SIMS(2281段,中文)。数据预处理未详细说明,但提到了标准的数据集划分。
- 损失函数:总损失为加权和
L = L_reg + λ L_contrast。L_reg是预测分数与真实分数之间的均方误差(MSE)。L_contrast是情感感知的对比损失,其权重λ在消融实验中被设为0.3以达到最佳平衡。 - 训练策略:
- 优化器、学习率、batch size等具体训练策略论文中未说明。
- 训练时,门控网络使用策略梯度算法,以情感回归目标的改善作为奖励信号,并采用移动平均基线来减小方差。
- 训练硬件和时长论文中未提及。
- 关键超参数:
- 视觉编码器:ResNet + L层Transformer。
- 文本编码器:BERT。
- 音频编码器:Transformer。
- 关键的RCAL块数量L,以及嵌入维度d等论文中未明确给出具体数值。
- 帧数:主实验对比了3, 5, 8帧,以及全帧设置。
- 推理细节:论文提到推理延迟低于5毫秒/样本,表明其模型轻量且高效。具体的解码或推理流程未展开。
- 正则化技巧:主要的稳定训练技巧包括:(1) 使用情感感知对比损失作为嵌入空间的正则化;(2) 强化学习门控训练中使用移动平均基线减少方差;(3) 记忆反馈机制本身有助于稳定训练过程。
📊 实验结果
主要基准性能对比 (Table 1):
| 数据集 | 模型 | MAE↓ | Corr↑ | Acc-7↑ / Acc-5↑ |
|---|---|---|---|---|
| MOSI | RCAL (ours, 5f/full) | 0.665/0.641 | 0.819/0.848 | 48.03/52.14 |
| KuDA (prior SOTA) | 0.705 | 0.795 | 47.08 | |
| ALMT | 0.712 | 0.792 | 46.79 | |
| MOSEI | RCAL (ours, 5f/full) | 0.527/0.503 | 0.753/0.787 | 54.19/55.26 |
| KuDA | 0.529 | 0.776 | 52.89 | |
| ALMT | 0.530 | 0.774 | 53.62 | |
| CH-SIMS | RCAL (ours, 5f/full) | 0.407/0.395 | 0.604/0.612 | 45.08/47.92 |
| KuDA | 0.408 | 0.613 | 43.54 | |
| ALMT | 0.408 | 0.594 | 43.11 | |
| 结论:RCAL在5帧输入下,在MOSI和CH-SIMS的多数指标上已超越先前使用全帧的SOTA模型;在MOSEI上,MAE和Acc-7达到最优,Corr略低于KuDA。全帧输入下,RCAL在所有指标上均达到最优。 |
消融实验 (Table 2, MOSI数据集):
| 变体 | MAE↓ | Corr↑ |
|---|---|---|
| Full Model (RL Gate, λ=0.3) | 0.665 | 0.819 |
| w/o Memory Refinement | 0.694 | 0.791 |
| w/o Audio–Text Attention | 0.685 | 0.802 |
| Fixed Gate (=1) | 0.679 | 0.806 |
| Soft Gate (Sigmoid) | 0.688 | 0.814 |
| w/o Contrastive (λ=0.0) | 0.687 | 0.808 |
| Contrastive (λ=1.0) | 0.689 | 0.796 |
| 结论:移除记忆精炼模块性能下降最大,证明了其关键性。RL门控优于固定门和软门。对比损失权重λ=0.3为最佳平衡点。 |
帧数影响 (Table 3, MOSI数据集):
| 帧数 | MAE↓ | Corr↑ |
|---|---|---|
| 0 | 0.773 | 0.751 |
| 3 | 0.724 | 0.782 |
| 5 | 0.665 | 0.819 |
| 8 | 0.659 | 0.823 |
| 结论:性能随帧数增加而提升,但5帧已能取得非常强的结果,展示了框架在极端稀疏下的鲁棒性。 |
可视化分析 (图3, 图4):
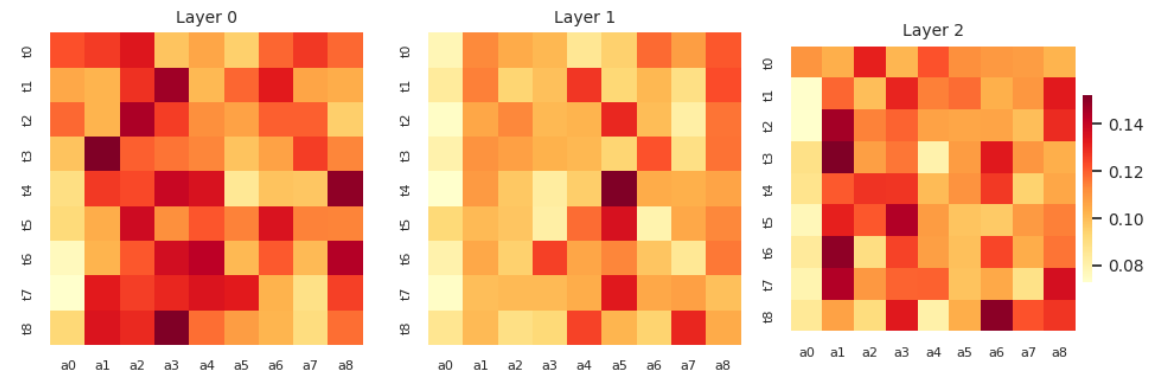 图3展示了门控激活与音频-文本注意力。不同层的门控激活率不同(Layer 0: 0.51, Layer 1: 0.36, Layer 2: 0.71),表明模型能自适应调节不同层级的融合深度。音频-文本注意力在不同层关注不同的模态关系。
图3展示了门控激活与音频-文本注意力。不同层的门控激活率不同(Layer 0: 0.51, Layer 1: 0.36, Layer 2: 0.71),表明模型能自适应调节不同层级的融合深度。音频-文本注意力在不同层关注不同的模态关系。
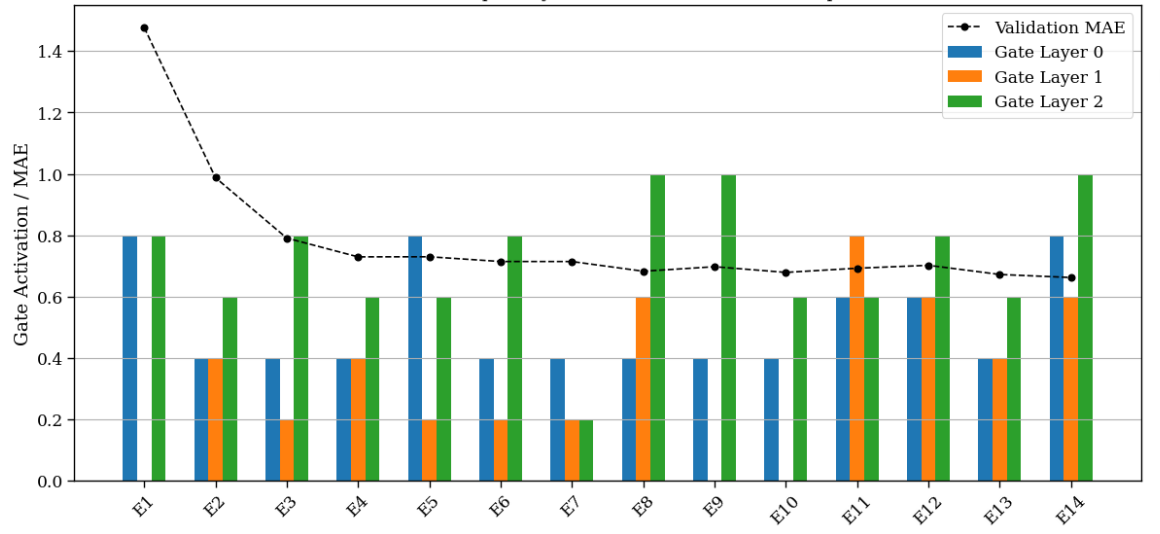 图4展示了对比损失的效果。训练后,类内余弦相似度从0.41提升到0.68,类间相似度从0.32降至0.18,表明嵌入空间按情感得到了更清晰的结构化组织。
图4展示了对比损失的效果。训练后,类内余弦相似度从0.41提升到0.68,类间相似度从0.32降至0.18,表明嵌入空间按情感得到了更清晰的结构化组织。
⚖️ 评分理由
- 学术质量:6.0/7。论文针对一个清晰且重要的实际问题提出了一个设计精巧、组件动机明确的解决方案。创新性体现在模块的组合设计与针对稀疏场景的适配上。实验设计完整,包括主实验、消融实验和可���化分析,结果具有说服力。但整体创新属于系统层面的整合,各单点技术(RL、对比学习、记忆机制)并非首创。部分训练细节缺失,略微影响可复现性评分。
- 选题价值:1.8/2。选题直接切中多模态情感分析从学术走向工业部署的关键瓶颈,具有很高的实用价值和研究前沿性。关注带宽和隐私约束下的实时情感计算,对工业界和学术界的相关读者都有很强吸引力。
- 开源与复现加成:0.8/1。论文提供了可访问的GitHub代码仓库,这是巨大的加分项。公开了所用数据集和模型架构(BERT, ResNet)。然而,模型的具体权重、详细的训练超参数配置需要查阅代码才能完全获取。因此,复现门槛中等,给予较高但非满分的加成。