📄 Random Matrix-Driven Graph Representation Learning For Bioacoustic Recognition
#生物声学 #图表示学习 #时频分析 #鲁棒性 #数据集
✅ 7.5/10 | 前25% | #生物声学 | #图表示学习 | #时频分析 #鲁棒性
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Biaohang Yuan(西藏大学, 拉萨)
- 通讯作者:Jiangzhao Wang(湖南大学, 长沙)
- 作者列表:Biaohang Yuan(西藏大学), Jiangzhao Wang(湖南大学), YuKai Hao(武汉理工大学), Ruzhen Chen(西藏大学), Yan Zhou(北京理工大学, 珠海)
💡 毒舌点评
这篇论文的亮点在于巧妙地将随机矩阵理论融入图神经网络的构建过程,为处理低资源生物声学信号中的时频特征关联提供了一个有数学理论支撑的新颖视角,特别是通过可学习缩放因子α和超图结构来动态建模复杂谐波关系,立意很高。然而,短板在于其核心方法的“新颖性”更多体现在框架的复杂拼接上,对于随机矩阵理论如何具体且关键地提升了模型性能(而非仅作为理论背书)的阐述略显薄弱,且实验部分对训练细节的吝啬披露,让其宣称的优越性能打了折扣,复现门槛极高。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:提到了Birdsdata和牛蛙叫声数据集名称��来源,但未提供公开下载链接或获取方式说明。
- Demo:未提及。
- 复现材料:论文给出了算法伪代码(Algorithm 3.1)和部分超参数(如τ=0.3),但缺少大量关键训练细节(如网络具体层数、隐藏层维度、优化器参数、学习率等)。
- 论文中引用的开源项目:未明确提及依赖的开源项目。引用的基线方法(如MFTE, GraFPrint, BirdNET, METAAUDIO)本身是开源项目,但本文未说明是否复用了其代码。
📌 核心摘要
- 问题:生态声学监测依赖生物声学识别,但面临训练数据稀缺、类别不平衡以及复杂声景中信号易受干扰等挑战,导致现有模型性能受限。
- 方法核心:提出了随机矩阵驱动的图表示学习框架(RM-GRL)。该框架首先将三通道梅尔频谱图(Log-Mel, Delta, Delta-Delta)视为时频图,并利用随机矩阵理论指导图结构的构建,引入一个可学习的缩放因子α来动态调整跨通道权重。它结合了普通图和超图结构,其中超边连接同一谐波成分内的时频节点。
- 创新点:与传统方法相比,新在:a) 将随机矩阵理论与图表示学习结合,通过低秩投影和JL引理保证特征投影的距离保持性;b) 构建时频超图以显式建模谐波结构;c) 在图卷积网络中引入Lipschitz常数约束和对抗扰动以增强局部判别特征;d) 采用ADD损失函数优化嵌入空间。
- 实验结果:在Birdsdata和牛蛙叫声数据集上进行评估。实验设置了四组不平衡正负样本比例(1:1至1:4)。结果显示,该模型在精确率-召回率曲线(图3)上始终优于MFTE、GraFPrint、BirdNET和METAAUDIO四个基线。在ROC-AUC评估中,对21种生物声音均达到0.8以上(图4)。消融研究表明,随机矩阵驱动投影模块贡献最大(+2.3%),其次是超图构建(+1.5%)。在F1分数对比中,该方法在大多数物种上表现最佳(图5b)。
- 实际意义:该工作为低资源、高噪声环境下的生物声学识别提供了一种新的图神经网络建模范式,有助于提升生态监测的自动化水平。
- 主要局限性:论文未提供代码、模型权重和关键训练超参数(如学习率、批次大小、具体网络层数/维度),可复现性差;对随机矩阵理论在模型中发挥具体作用的理论分析相对表面,更多依赖引理陈述;实验仅在两个自述数据集上进行,缺乏更广泛的验证。
🏗️ 模型架构
RM-GRL框架的整体架构如图1所示,主要包含三个阶段:时频图构建、基于随机矩阵的动态图学习、以及图神经网络编码与分类。
- 输入与特征提取:输入为原始音频,预处理为三通道梅尔频谱图(C=3:Log-Mel, Delta, Delta-Delta),维度为 F(频率点)× T(时间帧)× C。每个时间-频率点被视为图中的一个节点。
- 图构建(图2):
- 节点连接:建立两种连接:a) 时间相邻帧内的相邻梅尔频带节点连接;b) 通过随机矩阵投影计算节点间的自适应邻接矩阵。
- 随机矩阵驱动:使用一个复合随机投影矩阵
R_multi = Π ℓ=1^L R_ℓ。为了高效优化,将其参数化为R = U S V^T,其中U和V是固定的半正交基(初始化时随机),S是可学习的矩阵。该投影通过投影梯度下降(PGD) 进行优化,并引入一个可学习的缩放因子 α ∈ [0, 1] 来平衡随机投影带来的不平衡。 - 注意力与掩码:计算缩放点积注意力分数,并使用余弦相似度阈值 τ=0.3 进行稀疏化,只保留强相关边。同时,应用伯努利随机掩码 M 进行对抗扰动,最终邻接矩阵为
A_final = A_adapt ⊙ M + A_rand ⊙ (1-M)。
- 超图结构:3D特征向量作为超边的属性,连接同一谐波成分内的所有时频节点,以保持谐波结构。
- 图神经网络编码:使用图卷积网络(GNN)处理超图。为稳定训练,约束了图卷积算子的Lipschitz常数。采用最大相对聚合方式(式9)更新节点特征,即拼接中心节点特征与其邻域中差异最大的特征。
- 图级嵌入与分类:通过全局平均池化获得整个图的嵌入向量
g,然后通过一个全连接层和Sigmoid激活函数输出二分类预测。
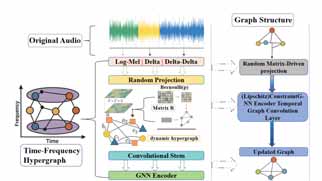 图1:RM-GRL框架概览。展示了从三通道梅尔频谱图输入,到超图构建,再到通过带有Lipschitz约束的GNN编码器进行多尺度特征整合与图精炼的流程。
图1:RM-GRL框架概览。展示了从三通道梅尔频谱图输入,到超图构建,再到通过带有Lipschitz约束的GNN编码器进行多尺度特征整合与图精炼的流程。
 图2:动态图结构构建基础框架。展示了对数梅尔、Delta、Delta-Delta三个通道的特征如何通过随机矩阵投影和自适应可学习缩放,映射到图结构中的空间关系。
图2:动态图结构构建基础框架。展示了对数梅尔、Delta、Delta-Delta三个通道的特征如何通过随机矩阵投影和自适应可学习缩放,映射到图结构中的空间关系。
💡 核心创新点
- 随机矩阵驱动的可学习图参数化:将随机矩阵理论(特别是Johnson-Lindenstrauss引理)融入图神经网络的图构建阶段,通过优化低秩投影矩阵
R来动态学习一个既能保持距离又能适应数据的邻接结构。这是区别于传统k-NN或固定注意力图的核心。 - 时频超图构建:显式地使用超图来建模生物声学信号中的谐波关系,超边连接同一谐波内的所有时频节点,弥补了传统图在捕捉这类非成对、群体性关系上的不足。
- Lipschitz约束与最大相对聚合:在图卷积网络中引入Lipschitz常数限制,并采用最大相对聚合策略,旨在增强模型对局部判别特征的学习能力,同时保证梯度传播的稳定性,尤其是在处理噪声和扰动时。
🔬 细节详述
训练数据:
- 数据集:提及了两个数据集:a) Birdsdata, 由北京人工智能研究院(BAAI)和Birdsdata联盟联合发布;b) 牛蛙叫声数据集, 包含1000个WAV音频样本,来源为康奈尔大学生物声学研究实验室和全球野生动物声音库(如Macaulay Library)。
- 预处理:对每个特征通道独立进行通道均值方差归一化。使用Kronecker积融合降维后的通道特征以保留交互。
- 数据增强:未说明具体增强方法。论文提及使用了来自五种不同环境的噪声数据作为负样本。
- 数据划分:10折分层交叉验证,训练集与测试集比例为8:2,每次训练时从训练集中随机抽取20%作为验证集。
损失函数:
- 名称:Angular Distribution Distance (ADD) Loss(式10)。
- 作用:通过优化嵌入空间的角度分布特性(类内紧凑、类间分散),增强模型对关键声学特征的敏感性,实现更均衡的分类。具体包含正/负样本的均值与标准差项。
训练策略:
- 未说明学习率、优化器、batch size、warmup、总训练轮数等具体信息。
- 优化器:GNN参数Θ通过反向传播更新。随机投影矩阵R通过投影梯度下降(PGD) 更新(式2)。
- 训练流程:每个epoch包含:前向传播(使用当前邻接矩阵)-> 计算ADD Loss -> 反向传播更新GNN参数Θ。邻接矩阵在epoch间用更新的节点特征动态更新。
关键超参数:
- 模型大小、层数、隐藏维度:未说明。
- 图构建超参数:余弦相似度阈值
τ = 0.3, 邻接矩阵稀疏化阈值。 - 随机投影矩阵:采用低秩参数化
R = U S V^T, 但秩r的大小未说明。 - 可学习缩放因子
α:初始化为α0, 优化空间约束于α ∈ [0, 1]。
训练硬件:未说明。
推理细节:对于二分类任务,使用Sigmoid激活输出概率。
正则化与稳定训练技巧:
- Lipschitz常数约束:限制图卷积算子的Lipschitz常数,防止梯度爆炸。
- 随机掩码(Bernoulli):用于对抗训练,增强鲁棒性。
- 正交正则化项
L_ortho(式6):约束投影矩阵的近似正交性,并惩罚α偏离初始值,有助于稳定训练。
📊 实验结果
主要对比实验: 论文在四个不同正负样本比例(1:1, 1:2, 1:3, 1:4)的设置下,对四个基线(MFTE, GraFPrint, BirdNET, METAAUDIO)和本方法进行了对比。
| 实验设置 | 模型/方法 | 数据集/任务 | 指标 | 结果描述 |
|---|---|---|---|---|
| 正负样本比例 | Our Model | Birdsdata/牛蛙数据集 | Precision-Recall曲线 | 在四种比例下,其曲线均包围或优于其他基线,表明在类不平衡下性能更稳健(图3)。 |
| MFTE | 在1:1比例下与本方法性能接近。 | |||
| GraFPrint | ||||
| BirdNET | ||||
| METAAUDIO | ||||
| 综合评估 | Our Model | Birdsdata + 牛蛙数据集 (21类生物声音) | ROC-AUC | 对所有21个任务,ROC-AUC分数均高于0.8(图4)。 |
| 品种级对比 | Our Model | 21个物种 | Accuracy & F1 Score | 在图5a(准确率热图)和图5b(F1分数热图)中,在大多数物种上,本方法的指标(颜色深度)优于或持平于基线,尤其在F1分数上优势更明显。 |
| 消融研究 | 完整模型 | 未说明具体数据集 | 性能增益 | 随机矩阵投影模块贡献 +2.3%;超图构建贡献 +1.5%;Lipschitz约束和ADD损失确保稳定性和判别性。 |
 图3:四个样本比例下的精确率-召回率曲线。展示了本模型(紫色)在不同不平衡程度下均能保持较好的精确率和召回率平衡,优于其他基线。
图3:四个样本比例下的精确率-召回率曲线。展示了本模型(紫色)在不同不平衡程度下均能保持较好的精确率和召回率平衡,优于其他基线。
 图4:21种生物声音的ROC-AUC曲线。展示了本模型在所有类别上都取得了0.8以上的高AUC值,证明了其鲁棒性和有效性。
图4:21种生物声音的ROC-AUC曲线。展示了本模型在所有类别上都取得了0.8以上的高AUC值,证明了其鲁棒性和有效性。
 图5:五种模型在21个物种上的性能热图对比。(a) 准确率对比;(b) F1分数对比。直观显示了本方法在大部分物种识别任务上的优势。
图5:五种模型在21个物种上的性能热图对比。(a) 准确率对比;(b) F1分数对比。直观显示了本方法在大部分物种识别任务上的优势。
⚖️ 评分理由
- 学术质量(6.0/7):创新性在于将随机矩阵理论、超图和图卷积网络进行有针对的整合,以解决生物声学的具体问题,思路清晰且具有理论动机。技术正确性基本成立,但核心理论推导(如式3-7)与最终模型性能的因果链条不够坚实。实验充分,设计了多组不平衡场景对比、ROC-AUC评估和消融研究,结果图表清晰。主要扣分点在于关键实验细节缺失,降低了结论的可验证性和可信度。
- 选题价值(1.5/2):生物声学是具有重要生态和社会价值的交叉前沿领域,数据稀缺是公认难题。本文工作直接针对此痛点,提出的框架具有明确的潜在应用空间(生态监测、物种保护),对音频处理领域研究者也有方法论上的启发。
- 开源与复现加成(0.0/1):论文未提供代码仓库、模型权重、训练配置(学习率、批次大小等)、训练硬件信息,也未提及公开数据集获取方式。仅描述了算法框架,几乎无法复现。