📄 Quantifying Speaker Embedding Phonological Rule Interactions in Accented Speech Synthesis
#语音合成 #数据增强 #语音转换 #低资源
✅ 7.0/10 | 前25% | #语音合成 | #数据增强 | #语音转换 #低资源
学术质量 5.5/7 | 选题价值 1.0/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Thanathai Lertpetchpun (Signal Analysis and Interpretation Lab, University of Southern California)
- 通讯作者:未说明
- 作者列表:Thanathai Lertpetchpun(USC SAIL实验室),Yoonjeong Lee(USC SAIL实验室),Thanapat Trachu(USC计算机科学系),Jihwan Lee(USC SAIL实验室),Tiantian Feng(USC SAIL实验室),Dani Byrd(USC语言学系),Shrikanth Narayanan(USC SAIL实验室、USC计算机科学系、USC语言学系)
💡 毒舌点评
亮点在于将语言学理论中“口音”的模糊概念,拆解为可量化、可操作的音韵规则,并提出了PSR这一新颖的交互度量工具。短板在于创新主要体现在评估方法论和实验分析上,对语音生成模型本身的改进有限,且评估结果严重依赖外部的音素识别模型,可能存在噪声。
🔗 开源详情
- 代码:提供了GitHub仓库链接(https://github.com/linguistylee/KAtDial),用于实现论文中定义的音韵规则。
- 模型权重:论文中未提供作者自己训练的模型权重。实验使用的是公开的预训练模型“Kokoro-82M”。
- 数据集:实验使用的文本来自公开数据集“LibriTTS-R”。说话人嵌入来自“Kokoro-82M”模型。
- Demo:提供了在线语音样本演示页面(https://sav-eng.github.io/icassp_samples.html)。
- 复现材料:提供了代码实现规则。训练细节、模型配置等未提供,因为论文主要使用预训练模型进行合成与分析。
- 论文中引用的开源项目:Misaki G2P, Kokoro TTS, Vox-Profile, Wav2Vec2Phoneme, UTMOS。
📌 核心摘要
- 问题:当前TTS系统通过说话人嵌入控制口音,但该嵌入混合了音色、情感等无关信息,导致口音控制不透明且难以精细调整。
- 方法核心:以美式和英式英语为例,引入基于语言学的音韵规则(闪音、卷舌性、元音对应)作为显式探针。提出“音素移位率(PSR)”指标,用于量化说话人嵌入在多大程度上保留或覆盖这些规则驱动的音素转换。
- 创新点:1)提出PSR指标,直接衡量规则与嵌入的交互强度;2)系统性地分析了显式语言规则与数据驱动嵌入在口音合成中的相互作用。
- 实验结果:
- 主要实验结果见下表1,显示结合规则能提升口音强度且不损害自然度,PSR值降低表明规则被更好保留。
- 表2展示了不同条件下需二次应用规则的次数(N2),证明规则应用能减少“口音回退”。
- 表3显示了不同说话人嵌入与规则结合的效果,PSR普遍下降15%左右。
- 图2的核密度估计图显示,应用规则后,每个语句中被规则改变的音素数量分布向更小值偏移。
| 条件 | UTMOS (↑) | 声音概率 NA (↓) | 声音概率 B (↑) | 声音相似度 NA (↓) | 声音相似度 B (↑) | PSR (↓) |
|---|---|---|---|---|---|---|
| 美式嵌入,无规则 | 4.43 | 86.5 | 3.79 | 0.85 | -0.05 | 0.856 |
| 美式嵌入,全规则 | 4.42 | 58.8 | 17.3 | 0.74 | 0.21 | 0.827 |
| 英式嵌入,无规则 | 3.74 | 17.6 | 67.8 | 0.33 | 0.67 | 0.775 |
| 英式嵌入,全规则 | 3.72 | 5.3 | 78.4 | 0.03 | 0.85 | 0.628 |
表1:不同规则配置下的实验结果(引自论文Table 1)
| 条件 | 闪音 (N2, 千次) | 卷舌性 (N2, 千次) | 元音 (N2, 千次) | 全规则 (N2, 千次) |
|---|---|---|---|---|
| 美式嵌入 (N1) | 12.8 | 83.5 | 125.1 | 221.4 |
| 美式嵌入 (N2) | 25.3 | 57.9 | 106.3 | 189.5 |
| 英式嵌入,无规则 (N2) | 12.3 | 57.4 | 101.7 | 171.5 |
| 英式嵌入,有规则 (N2) | 6.7 | 53.7 | 78.5 | 139.0 |
表2:规则应用前后期望替换次数(N1)与实际观测次数(N2)对比(引自论文Table 2)
| 说话人 | 声音概率 NA (↓) | 声音概率 B (↑) | PSR (↓) | PSR变化 |
|---|---|---|---|---|
| Fable | 17.6 | 67.8 | 0.775 | |
| Fable-R (有规则) | 5.7 | 78.4 | 0.628 | -14.7% |
| Daniel | 4.7 | 89.8 | 0.706 | |
| Daniel-R (有规则) | 1.5 | 93.2 | 0.543 | -16.3% |
表3:不同说话人嵌入与规则结合的效果(引自论文Table 3,仅展示部分数据)
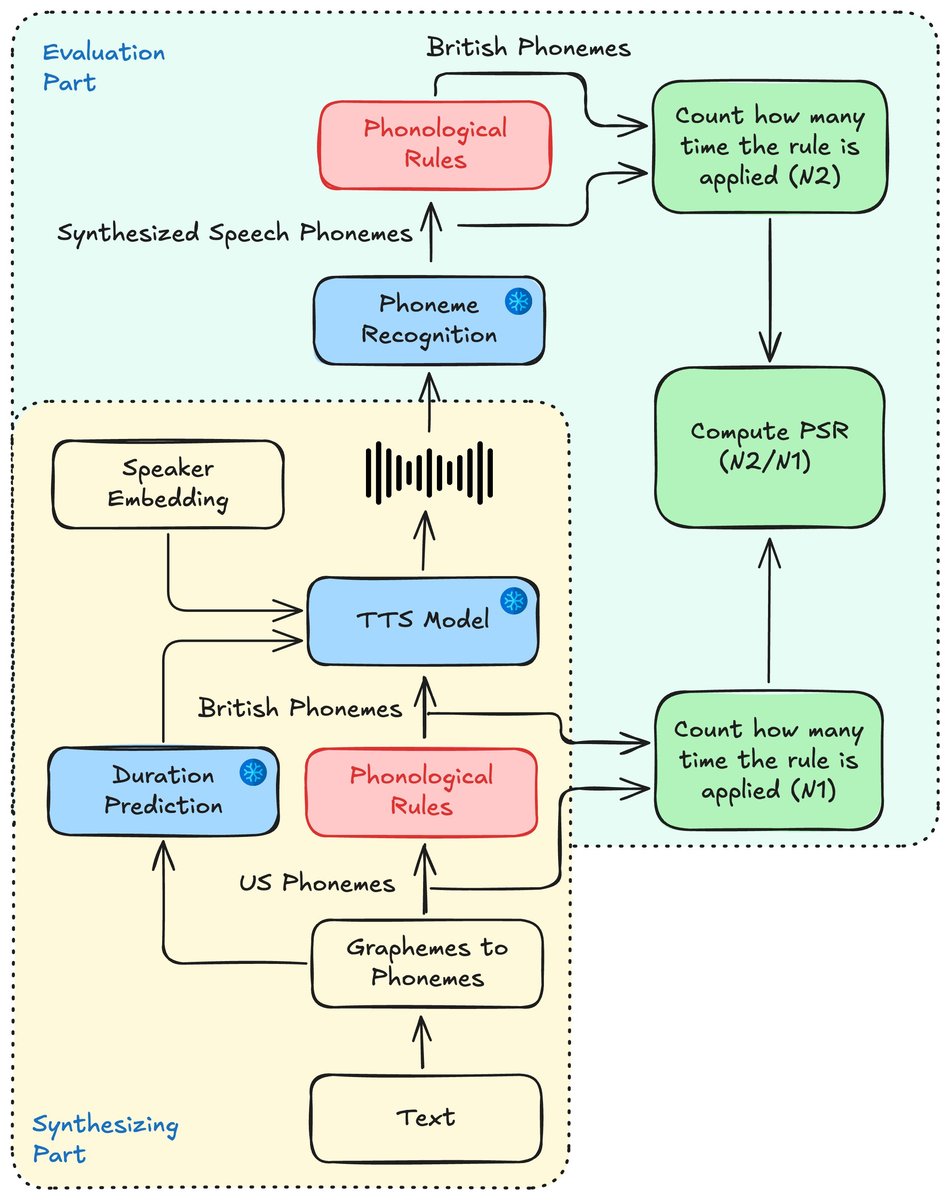 图2:不同条件下,每个语句中被规则改变的音素数量的分布。应用规则后(“British Speaker Embedding with Rules”曲线)分布明显向左偏移,表明更少的音素需要被再次改变,即规则保留度更高。
图2:不同条件下,每个语句中被规则改变的音素数量的分布。应用规则后(“British Speaker Embedding with Rules”曲线)分布明显向左偏移,表明更少的音素需要被再次改变,即规则保留度更高。
- 实际意义:为TTS系统提供了一种结合语言学知识与数据驱动模型的口音控制思路,PSR指标可为评估模型解耦能力提供新工具。
- 主要局限性:1)音韵规则是粗粒度的,无法捕捉口音的所有细微差别;2)评估高度依赖外部预训练模型(Vox-Profile, Wav2Vec2Phoneme),其本身可能存在偏见或误差;3)未涉及非英语口音或更复杂的口音混合场景。
🏗️ 模型架构
本文并非提出一个新的TTS模型架构,而是设计了一个分析框架和实验流程,以研究现有TTS模型中规则与嵌入的交互。其核心流程如图1所示:
图1:合成与评估流程图
- 输入:规范化的英文文本。
- G2P转换:使用“Misaki G2P”工具将文本转换为美式英语音素序列。
- 规则转换:应用预定义的三组音韵规则(闪音、卷舌性、元音对应),将美式音素序列映射为英式英语音素序列。
- 语音合成:使用“Kokoro TTS”预训练模型进行语音合成。输入为:
- 音素序列:美式或英式序列。
- 说话人嵌入:从预设的美式或英式说话人嵌入中选择。
- 音素时长:固定(从特定美式说话人中提取)。
- 输出:合成的语音波形。
- 评估:
- 口音强度:使用“Vox-Profile”分类器预测口音概率和嵌入相似度。
- 规则保留度(PSR):将合成语音通过“Wav2Vec2Phoneme”模型进行音素识别,得到实际输出的音素序列。然后,对这个实际输出序列再次应用相同的规则,统计需要应用的规则次数(N2)。PSR = N2 / N1(N1为原始目标转换次数)。
- 自然度:使用“UTMOS”模型进行客观MOS预测。
关键设计选择:论文明确控制变量,保持音素数量和时长在所有条件下不变,确保观察到的差异仅来源于音素内容(规则)和说话人嵌入的交互,而非时序或文本归一化的混淆因素。
💡 核心创新点
- 提出音素移位率(PSR)指标:这是一个新颖的、用于量化TTS模型中规则与嵌入交互强度的客观指标。它超越了简单的“规则是否被遵守”,能够刻画出梯度性的保留或覆盖程度,为评估模型“解耦”能力提供了可解释的工具。
- 将显式音韵规则作为口音控制探针:论文没有追求用规则完全替代数据驱动模型,而是将精心选择的、具有语言学依据的“大笔触”规则作为探针,注入到TTS流程中。这种方法为分析和干预“黑箱”TTS模型中的口音表示提供了一个可控的实验范式。
- 系统分析嵌入与规则的交互模式:通过大量对比实验(表1),论文揭示了不同规则(如元音对应)和不同说话人嵌入在影响口音合成时的相对强度、互补性以及可能的“纠缠”现象。例如,发现英式嵌入本身已有较强的口音倾向,但规则能进一步强化并降低PSR。
🔬 细节详述
- 训练数据:论文中未说明。实验使用了预训练模型,未提及任何新的训练过程。
- 损失函数:未说明。
- 训练策略:未说明。
- 关键超参数:论文未提供TTS模型(Kokoro-82M)的详细架构参数。规则应用的具体条件(如闪音出现的语音环境)基于语言学文献,但具体实现代码在提供的GitHub仓库中。
- 训练硬件:未说明。
- 推理细节:合成语音时,输入了固定的音素时长(来自“af heart”说话人),确保时长一致性。解码策略等细节未说明,应由预训练模型决定。
- 正则化或稳定训练技巧:未说明。
- 实验数据集:用于合成的文本来自“LibriTTS-R”数据集的“train-clean-100”子集,总计约3.3万条语句,55.4小时。说话人嵌入使用“Kokoro-82M”模型自带的28个预设嵌入(20个美式,8个英式)。
- 评估数据集:用于口音分类评估的“Vox-Profile”和“Wav2Vec2Phoneme”模型均使用其官方或提及的训练/测试数据(论文中未详述这些评估集的构成)。
📊 实验结果
实验结果主要围绕三个核心问题展开,并由三张关键表格和一张分布图支持。
- 音韵规则对语音合成的影响(表1)
- 主要结果:
- 自然度:应用规则对自然度影响极小(UTMOS美式
4.4,英式3.7)。 - 口音概率与相似度:规则能有效改变口音方向。在美式嵌入上应用所有英式规则,使美式概率从86.5%降至58.8%,英式概率从3.79%升至17.3%。在英式嵌入上应用规则,英式概率从67.8%升至78.4%。
- PSR:规则应用降低了PSR(英式嵌入从0.775降至0.628),表明规则在一定程度上得以保留。
- 单个规则效果:在英式嵌入下,元音对应规则对提升口音概率(77.8%)和降低PSR(0.693)效果最显著;卷舌性规则对提升相似度(0.78)效果明显;闪音规则单独作用弱,但具有叠加效果。
- 自然度:应用规则对自然度影响极小(UTMOS美式
- 说话人嵌入对规则应用效果的影响(表2与图2)
- 主要结果:PSR中的N2(需二次应用规则的次数)显示,说话人嵌入会部分覆盖规则效果。例如,美式嵌入会使卷舌性规则的N2从期望的83.5千次减少到57.9千次(表2),说明嵌入“拉回”了一些本应被删除的/r/。应用规则后,N2普遍减少(图2分布左移),表明规则输入增强了保留度。
- 不同说话人嵌入与规则的交互差异(表3)
- 主要结果:不同说话人嵌入对规则的响应不同。“Fable”等嵌入对规则依赖度更高,PSR下降幅度大(14.7%);而“Daniel”等本身就具有高口音概率的嵌入,规则主要起微调和进一步强化作用,PSR下降也达16.3%。这反映了嵌入编码的口音特征存在不同强度的“纠缠”。
关键局限:所有评估指标(口音概率、音素识别)均来自外部预训练模型,其自身的偏见和准确性直接影响论文结论的可靠性。论文也承认未来需引入更多识别模型和人工评估。
⚖️ 评分理由
- 学术质量:5.5/7:论文工作扎实,提出PSR指标有一定新意,实验设计合理,控制了变量,消融实验充分。但核心贡献在于分析方法和评估工具,而非生成模型本身的突破。研究深度受限于“分析现有系统”,而非“设计新系统”。
- 选题价值:1.0/2:口音控制是TTS的一个实际应用方向,将语言学知识工程化应用于该问题的思路有启发性。但问题本身较为具体和垂直,对语音合成领域整体发展的推动力有限。
- 开源与复现加成:0.0/1:论文提供了核心代码(音韵规则实现)、指明了使用的预训练TTS模型和评估工具,复现该研究框架的门槛较低。但未提供训练细节(因其不涉及训练)和自有模型权重,加成适中。