📄 Qastanet: A DNN-Based Quality Metric for Spatial Audio
#空间音频 #信号处理 #多通道 #模型评估
✅ 7.5/10 | 前50% | #空间音频 | #信号处理 | #多通道 #模型评估
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Adrien Llave (Orange Research, France)
- 通讯作者:未说明
- 作者列表:Adrien Llave (Orange Research, France)、Emma Granier (Orange Research, France)、Grégory Pallone (Orange Research, France)
💡 毒舌点评
亮点:这篇论文巧妙地在“纯知识驱动”和“纯数据驱动”的音频质量评估之间找到了一个平衡点,用仅730个参数的小网络和精心设计的专家特征,在有限数据下实现了强相关性,务实且有效。 短板:其“SOTA”的宣称略显底气不足,因为对比的基线较少且部分(如Ambiqual)在其核心测试场景(混响)上本就预知会失效;此外,评估仅限于一种编解码器(IVAS),其宣称的“通用性”还需更广泛的验证。
🔗 开源详情
- 代码:提供。论文明确给出开源代码仓库链接:
https://github.com/Orange-OpenSource/QASTAnet,实现语言为Python/PyTorch。 - 模型权重:未提及是否公开预训练模型权重。
- 数据集:未公开。论文指出,由于未找到同时包含HOA内容和MUSHRA分数的开源数据库,故自行构建了数据集,且未提及计划公开。
- Demo:未提及。
- 复现材料:非常充分。论文详细说明了训练集构成(刺激类型、失真类型、比特率)、测试集构成、所有网络超参数(层数、通道数、池化方式、参数量)、训练优化器设置(Adam, lr=0.003)、损失函数、早停准则、以及推理时多头平均的具体做法(使用20组不同HRTF)。
- 论文中引用的开源项目:提到了使用IEM套件的
AllRADecoder插件进行Ambisonic解码。
📌 核心摘要
- 问题:在空间音频(如Ambisonics、双耳音频)技术发展中,依赖耗时耗力的主观听音测试评估质量,而现有客观指标泛化能力差,尤其难以处理真实混响信号和编解码失真。
- 方法核心:提出QASTAnet,一种结合专家建模与小型深度神经网络(DNN)的质量评估模型。前端使用模拟听觉系统低级处理的专家特征(包络、ILD、互相关、扩散度),后端用轻量级DNN建模高级认知判断过程,总参数仅730个。
- 创新点:相比纯数据驱动的GML(需大量数据)和纯知识驱动的eMoBi-Q(手工规则难优化),QASTAnet采用混合范式,在数据有限时仍能有效训练;引入针对Ambisonics的“扩散度”特征;将特征时间分辨率从400ms降至40ms以更好捕捉编解码伪影。
- 实验结果:在一个自建的MUSHRA测试数据集(364个训练样本)上,QASTAnet在预测MUSHRA分数方面的表现优于两个公开基线Ambiqual和eMoBi-Q。关键指标对比如下:
| 指标 | 方法 | 全部测试集 (all) | 仅编解码失真 (codecs) | 仅空间混响 (spat. rev.) |
|---|---|---|---|---|
| Pearson ↑ | Ambiqual LA | 0.61 | 0.77 | 0.58 |
| Ambiqual LQ | 0.51 | 0.48 | 0.40 | |
| eMoBi-Q | 0.72 | 0.55 | 0.63 | |
| QASTAnet | 0.90 | 0.86 | 0.89 | |
| Spearman ↑ | QASTAnet | 0.92 | 0.88 | 0.89 |
| RMSE ↓ | QASTAnet | 18.4 | 19.7 | 18.4 |
| RMSE* ↓ | QASTAnet | 15.3 | 16.5 | 15.2 |
(注:表格数据整理自论文Table 1,QASTAnet行已加粗) QASTAnet的预测值与主观分数高度一致(图3),尤其是在包含空间混响的复杂信号上优势明显。消融研究证明了40ms时间分辨率、扩散度特征和预加权模块的有效性。 5. 实际意义:为空间音频编解码器的快速、可靠开发提供了一个有潜力的客观评估工具,可减少对主观测试的依赖,其开源代码也促进了研究复现。 6. 主要局限性:评估仅针对IVAS编解码器;训练数据集由作者构建且规模有限,可能影响模型泛化性;预测存在轻微的系统性低估偏差。
🏗️ 模型架构
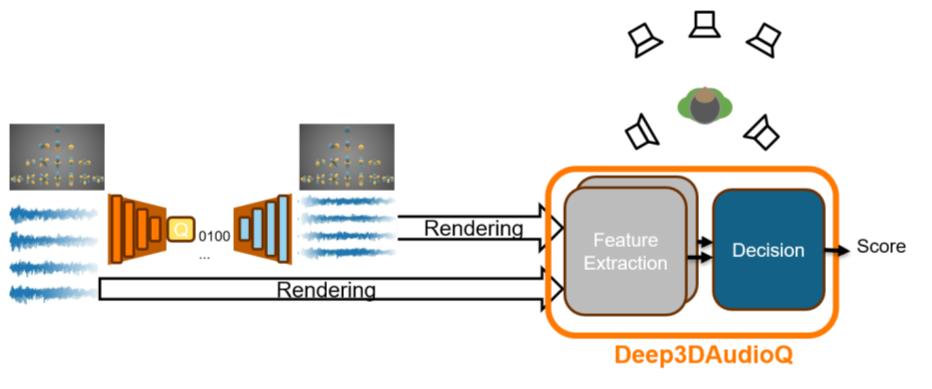
QASTAnet的整体架构如图1所示,是一个典型的“特征提取-比较-回归”的全参考质量评估模型。
 完整流程:
完整流程:
- 输入:一对参考和失真的空间音频信号(3阶Ambisonics格式)。
- 特征提取:
- 双耳特征分支:首先将Ambisonics信号通过双耳化(HOA to Bin)转换为双耳信号。然后提取三个心理声学特征:单耳包络(Envelop)、耳间强度差(ILD)和耳间相干性(Inter Coh.)。这些特征模拟了人耳低级听觉处理。
- 空间特征分支:直接在Ambisonics域计算一个新特征——扩散度(Diffuseness)(公式1)。它量化了声场中扩散成分(如混响)的比例,这是纯双耳特征可能丢失的信息。
- 特征比较:将参考和失真信号对应的每个特征进行逐点比较,采用二次差(quadratic difference)。结果是一个多通道的特征差异图。
- 神经网络处理:
- 预加权(Pre-weighting):一个可学习的加权层,为每个特征和每个频率带分配权重,让网络关注更重要的失真信息。
- 卷积块:三个逐点(Point-wise)二维卷积层(Conv2D),每层后接LeakyReLU激活。卷积核仅在时间-频率平面操作,通道数分别为16、16、6。这部分旨在从低级特征差异中学习更高级的失真模式表征。
- 频率池化:使用可学习的加权平均,将卷积输出在频率维度上进行压缩。
- 时间池化:采用Softmax加权平均池化,对时间维度进行自适应的压缩,突出对质量判断影响最大的时间段。
- 回归输出:经过一个LeakyReLU全连接层(16维)映射后,最后一个带Sigmoid激活的全连接层输出0到1之间的预测MUSHRA分数。 关键设计选择:
- 混合范式:使用专家特征(eMoBi-Q + 扩散度)大幅减少了模型需要从数据中学习的内容,使得仅730个参数的网络就能有效工作,降低了对大数据量的依赖。
- 高时间分辨率:将特征计算的时间窗口从常见的400ms缩短到40ms,以更灵敏地捕捉快速变化的编解码伪影。
- 多头部平均:为减少双耳化滤波器(HRTF集)选择对结果的影响,在推理时使用多达20套不同HRTF集生成的结果取平均。
💡 核心创新点
- 专家特征与轻量DNN的混合架构:在空间音频质量评估中,首次提出并验证了这种平衡点。既利用了可解释的、符合听觉机理的专家特征作为稳定输入,又利用DNN强大的非线性拟合能力来优化从特征到主观分数的复杂映射(模拟认知判断),克服了纯手工规则(如eMoBi-Q)难以优化和纯深度学习(如GML)需要海量数据的缺点。
- 引入Ambisonics域的扩散度特征:针对Ambisonics格式,提出了基于强度矢量和能量的扩散度特征。这直接建模了真实空间声场的关键属性(直达声与扩散声比例),弥补了仅使用双耳特征在评估含混响信号时的不足,实验消融研究证明了其有效性。
- 采用40ms的高时间分辨率:将音频特征的分析时间分辨率从传统(如eMoBi-Q)的400ms大幅提升至40ms。这一调整使得模型能更精确地定位和评估短时发生的编解码伪影,是其在编解码失真评估任务上性能提升的关键因素之一。
- 针对有限数据的训练策略:论文承认并正面应对了空间音频主观标注数据稀缺的问题。通过构建混合架构、采用小网络、并利用多头平均等策略,实现了在仅364个训练样本上的有效训练,为低资源场景下的音频质量建模提供了范例。
🔬 细节详述
- 训练数据:
- 数据集名称:作者自建数据集,未公开。
- 来源:通过一场6个会话(4个用于训练)的MUSHRA主观测试构建。
- 规模:共546个例子(刺激×失真组合),其中364个用于训练。每个刺激约10秒。
- 预处理:所有信号双耳化后响度归一化至-30 LUFS,采样率48kHz,截断为3阶Ambisonics。
- 数据增强:未提及。但使用多达20组不同HRTF集进行推理平均,可视为一种测试时增强。
- 损失函数:
- 名称:均方误差(MSE)。
- 作用:最小化模型预测分数与MUSHRA测试平均分之间的欧氏距离。
- 未提及损失权重。在尝试缓解偏差时,曾测试过epsilon-insensitive RMSE(RMSE*)作为损失函数,但效果不佳。
- 训练策略:
- 优化器:Adam。
- 学习率:0.003。
- 批量大小:32。
- 训练步数/轮数:平均进行约2.5k步,相当于约220个epoch。
- 调度策略:早停法(Early Stopping)。当验证集上的Pearson相关系数r连续15个epoch不再提升时停止训练,并保留最佳模型。
- 训练细节:训练时排除了隐藏参考(hidden reference)数据。
- 关键超参数:
- 模型总参数���730。
- 卷积层通道数:16, 16, 6。
- 特征时间分辨率:40ms。
- 时间池化方式:Softmax加权平均池化。
- 推理时多头部平均数量:最多20个。
- 训练硬件:论文中未说明。
- 推理细节:使用PyTorch实现。对于输入信号,会用最多20组不同的HRTF集分别进行双耳化、特征提取和预测,最后将所有预测分数取平均作为最终输出。
- 正则化或稳定训练技巧:采用了早停法防止过拟合。网络本身参数量很小(730),是最大的正则化手段。
📊 实验结果
主要benchmark为作者自建的MUSHRA测试数据集,评估指标为Pearson相关系数、Spearman秩相关系数、RMSE和RMSE*。
表1:客观指标与主观评分对比(关键数据)
| 指标 | 方法 | 全部测试集 (all) | 仅编解码失真 (codecs) | 仅空间混响 (spat. rev.) |
|---|---|---|---|---|
| Pearson r ↑ | Ambiqual LA | 0.61 | 0.77 | 0.58 |
| Ambiqual LQ | 0.51 | 0.48 | 0.40 | |
| eMoBi-Q | 0.72 | 0.55 | 0.63 | |
| QASTAnet | 0.90 | 0.86 | 0.89 | |
| Spearman ρ ↑ | QASTAnet | 0.92 | 0.88 | 0.89 |
| RMSE ↓ | QASTAnet | 18.4 | 19.7 | 18.4 |
| RMSE* ↓ | QASTAnet | 15.3 | 16.5 | 15.2 |
(注:表格数据整理自论文Table 1,加粗为最优结果)
关键结论:
- QASTAnet在所有相关性指标上全面超越了Ambiqual和eMoBi-Q基线。特别是在处理空间混响信号(spat. rev.)时,优势显著(Pearson r: 0.89 vs 0.63/0.40)。
- Ambiqual LA在编解码失真上相关性尚可(0.77),但完全无法评估低通锚点失真(仅音色变化),且LQ表现较差。
- eMoBi-Q在消声信号上表现良好,但在混响信号上性能下降,且对某些编解码失真评估不准。
- 消融研究显示:
- 将时间分辨率从400ms改为40ms,Pearson r从0.85提升至0.90。
- 添加扩散度特征,相关性有小幅提升(0.88 -> 0.90)。
- 添加预加权模块,进一步提升相关性(0.89 -> 0.90)。
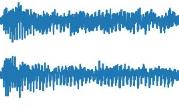
图3:预测分数与主观分数散点对比
 左图为QASTAnet,右图为eMoBi-Q。不同颜色和形状代表不同的刺激与失真组合。黑色点代表消声平面波合成信号,橙色点代表含空间混响的信号。关键结论:QASTAnet的散点更紧密地沿对角线(理想预测线)分布,尤其是在橙色点(混响信号)区域,表明其预测更准确、偏差更小。
左图为QASTAnet,右图为eMoBi-Q。不同颜色和形状代表不同的刺激与失真组合。黑色点代表消声平面波合成信号,橙色点代表含空间混响的信号。关键结论:QASTAnet的散点更紧密地沿对角线(理想预测线)分布,尤其是在橙色点(混响信号)区域,表明其预测更准确、偏差更小。
图2:MUSHRA分数分布直方图
此图展示了训练集和测试集(不含隐藏参考)的主观评分分布。关键结论:训练集(红色)的分数分布相对于测��集(蓝色)有向低分偏移的趋势。论文推测这可能是导致QASTAnet预测存在系统性低估偏差的原因之一。
⚖️ 评分理由
- 学术质量:5.5/7:论文在技术正确性和实验充分性上表现良好。方法设计有理有据,实验覆盖了多种内容类型,并进行了详尽的消融研究,结果可信。创新性方面,提出了一个实用且有效的混合框架和新特征,属于渐进式创新而非范式变革。主要扣分点在于证据的普适性:使用自建且未公开的小数据集训练,并在单一编解码器上验证,其“超越现有方法”和“通用”的结论强度有所折扣。
- 选题价值:1.5/2:前沿性和应用空间明确。空间音频质量评估是实际工程需求,该工作直接面向编解码器开发痛点。潜在影响较大,能推动相关工具的发展。但任务相对垂直,对更广泛的语音/音频研究社区的直接吸引力有限。
- 开源与复现加成:0.5/1:代码完全开源(PyTorch),链接已提供。论文提供了极其详尽的复现细节,包括所有超参数、网络结构、训练流程。主要遗憾是数据集未公开,这使得他人无法完全复现其训练过程,也限制了在其基础上进行更深入研究的可能性。