📄 Prototype-Guided Cross-Modal Contrastive Learning for Continual Audio-Visual Sound Separation
#语音分离 #对比学习 #持续学习 #多模态模型 #音视频
✅ 7.5/10 | 前25% | #语音分离 | #对比学习 | #持续学习 #多模态模型
学术质量 6.5/7 | 选题价值 1.0/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Wanrong Ma (国防科技大学计算机科学与技术学院,2. 国防科技大学并行与分布式计算国家重点实验室) (注:论文标注为共同第一作者)
- 通讯作者:Kele Xu (国防科技大学计算机科学与技术学院,2. 国防科技大学并行与分布式计算国家重点实验室)
- 作者列表:Wanrong Ma(国防科技大学计算机科学与技术学院;国防科技大学并行与分布式计算国家重点实验室)、Hongyu Wen(国防科技大学计算机科学与技术学院;国防科技大学并行与分布式计算国家重点实验室)、Zijian Gao(国防科技大学计算机科学与技术学院;国防科技大学并行与分布式计算国家重点实验室)、Qisheng Xu(国防科技大学计算机科学与技术学院;国防科技大学并行与分布式计算国家重点实验室)、Kele Xu(国防科技大学计算机科学与技术学院;国防科技大学并行与分布式计算国家重点实验室)
💡 毒舌点评
该工作在持续学习与多模态声音分离的交叉领域做得扎实,用原型和对比学习“框住”特征空间的想法巧妙且实验效果显著。但任务场景较为细分,且论文完全没提代码开源,对于想快速复现或在其他多模态任务上借鉴的读者不太友好。
🔗 开源详情
论文中未提及代码链接。 论文中未提及模型权重公开。 数据集MUSIC-21是公开的,但论文未说明具体获取方式或是否修改。 论文中未提及Demo。 论文提供了一定的训练细节(优化器、学习率、批大小、部分超参数),但缺少完整配置、检查点和代码,复现材料不充分。 论文中引用的开源项目/工具包括:iQuery [5] (用于特征提取流程参考)、Video-MAE [15] (预训练视频编码器)、CLIP [16] (预训练视觉编码器)。 论文中未提及开源计划。
📌 核心摘要
- 问题:本文研究持续音视频声音分离(CAVSS),即模型需在不断学习新声音类别的同时,不忘记如何分离已学类别的声音。主要挑战是灾难性遗忘(学新忘旧)和跨模态干扰(不同类别或不同模态的特征在表示空间中纠缠不清)。
- 方法核心:提出原型引导的跨模态对比学习(PGCCL) 框架。核心是为每个声音类别维护一个类级原型(该类别所有样本多模态特征的平均),将其作为锚点来构建和约束多模态表示空间。训练时,原型与当前批次的样本特征一起,进行成对的跨模态对比学习(音频-运动、音频-物体、运动-物体),以增强类间可分性和类内一致性。同时,使用指数移动平均(EMA) 机制更新模型参数和原型以稳定特征,并结合掩码蒸馏保留旧任务知识。
- 创新点:与现有基于样本回放或参数正则化的方法(如AV-CIL, ContAV-Sep)相比,PGCCL的创新在于:(1) 引入类级原型作为稳定锚点,直接结构化表示空间;(2) 设计了一种将原型融入批次进行跨模态对比学习的机制,同时强化实例判别和类别对齐;(3) 结合EMA和掩码蒸馏,在持续学习中更好地平衡稳定性与可塑性。
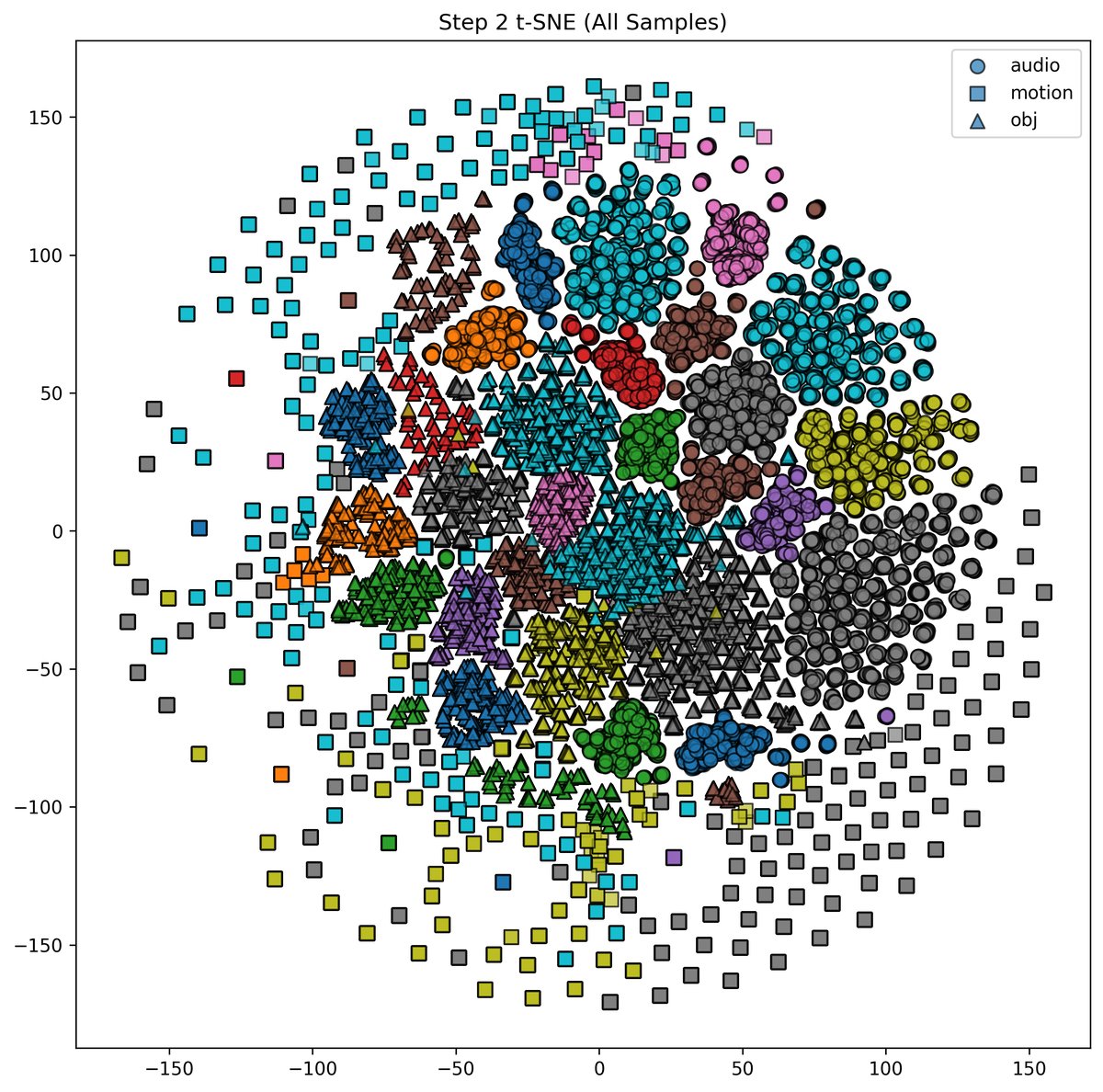
- 实验结果:在MUSIC-21数据集上的实验表明,PGCCL显著优于所有基线方法。在最后一个学习步骤上,其SDR达到8.16(最强基线ContAV-Sep为6.49),SIR和SAR也分别为14.11和13.26。在所有步骤的平均性能上,SDR为6.87。消融实验证明原型对比学习(PRO)、EMA和掩码蒸馏(MD)三个组件共同作用时性能最佳(SDR 7.88)。增加回放样本数(NS)能持续提升性能。t-SNE可视化(图2)显示PGCCL产生的多模态特征边界更清晰,重叠更少。
- 实际意义:为动态环境中的音频-视觉协同处理(如机器人、增强现实、辅助听觉设备)提供了一种可扩展的持续学习解决方案。
- 主要局限性:实验仅在一个数据集(MUSIC-21,仅21类乐器)上进行,验证了方法在该设置下的有效性,但对其在更复杂、更多样的真实世界声音场景中的泛化能力尚未验证。此外,论文未提供代码,限制了可复现性和快速验证。
🏗️ 模型架构
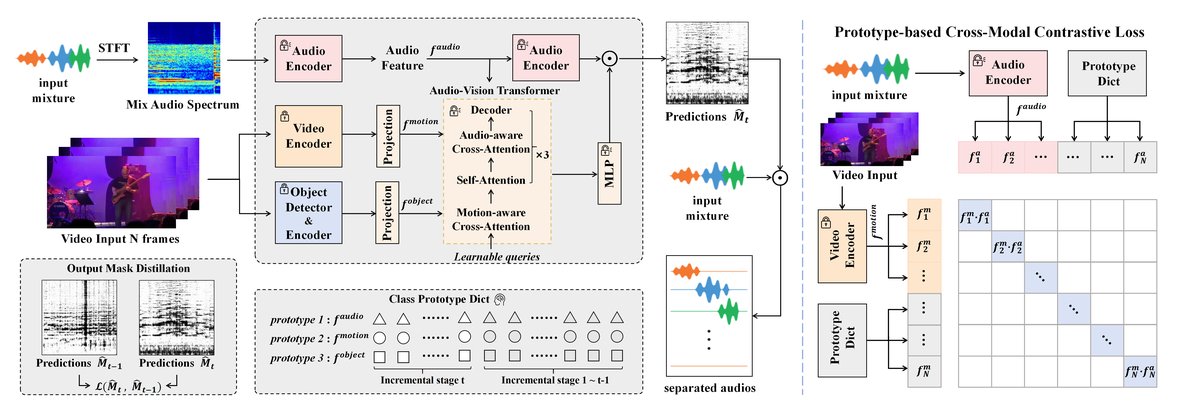
PGCCL框架(图1)旨在处理持续音视频声音分离任务。其整体流程和核心组件如下:
输入与特征提取:对于每个训练样本(混合音频A, 视觉线索V={V1, V2}),模型提取三种模态的特征:
- 音频特征(f_audio):来自声音分离模型的U-Net编码器。
- 运动特征(f_motion):来自预训练且冻结的Video-MAE编码器,捕捉时序动态。
- 物体特征(f_object):来自预训练且冻结的CLIP视觉编码器,捕捉语义信息。
- 运动和物体特征通过可学习的线性层投影到与音频特征共享的嵌入空间。
原型字典与构建:维护一个类级原型字典。在每个学习阶段结束时,为已见类别c计算其原型
p_c,即该类别所有样本的音频、运动、物体特征的平均值(公式5)。原型作为该类多模态表示的紧凑、稳定的“代表”。训练批次构建与对比学习:在训练新阶段时,一个批次的特征包含:
- 新类别样本特征(F_new)
- 旧类别样本在当前模型下的特征(F_old)
- 旧类别样本在上一阶段模型下的特征(F_hat_old)
- 以概率r随机采样的旧类别原型({p_c})。
- 所有这些特征被拼接(公式6),然后在其所有模态对(a-m, a-o, m-o)上计算跨模态对比损失。该损失包含两部分:
- 实例级对比损失(L_instance)(公式7):拉近同一样本不同模态的特征,推远不同样本的特征。
- 类别级对比损失(L_class)(公式8):拉近同一类别不同样本、不同模态的特征(包括原型),推远不同类别的特征。
- 最终原型增强对比损失为两者加权和(公式9)。
知识保留机制:
- 掩码蒸馏:对于旧任务样本,计算当前模型预测的掩码与上一阶段模型预测的掩码之间的蒸馏损失(公式10),以保留旧任务的分离能力。
- EMA稳定:采用指数移动平均更新模型参数(公式12),形成更稳定的长期记忆,缓解特征漂移。
总体目标:最终损失是分离损失、原型增强对比损失和蒸馏损失的加权和(公式11),共同优化模型以适应新类别、保留旧知识并保持跨模态对齐。
💡 核心创新点
- 基于原型的多模态表示空间结构化:提出将类级原型作为稳定锚点,显式地组织多模态特征空间。这不仅为新类提供了学习参考,也为旧类提供了“防遗忘”的约束边界,有效缓解跨模态干扰和灾难性遗忘。局限:原型是静态平均,对类内多样性或分布变化不敏感。
- 原型引导的跨模态对比学习框架:设计了一种创新的批次构建方式,将原型与新旧样本特征混合,并进行成对的跨模态对比学习。这同时实现了实例判别(区分不同样本)和类别对齐(聚合同类别不同模态),增强了特征的可判别性与跨模态一致性。收益:实验证明该框架在消融研究中贡献显著(去掉后SDR下降1.54)。
- EMA与掩码蒸馏的协同稳定机制:结合了参数级的EMA稳定和输出级的掩码蒸馏,在持续学习过程中从两个层面(特征表示和最终预测)巩固历史知识,形成了更鲁棒的稳定性-可塑性平衡。证据:消融实验显示,移除EMA或MD均会导致性能下降,三者结合效果最优。
🔬 细节详述
- 训练数据:使用MUSIC-21数据集,包含21种乐器独奏视频(共985个)。划分为训练集(794)、验证集(93)和测试集(96)。论文未说明具体的数据预处理或增强方法。
- 损失函数:
L_sep:声音分离重建损失,具体形式未详细说明(公式2中ℓ未定义,但通常为L1或L2损失)。L_b_proto-contra:原型增强跨模态对比损失,由实例级损失L_instance和类别级损失L_class加权组成(公式9),温度系数τ未具体说明。L_distill:掩码蒸馏损失,具体损失函数Loss未说明(公式10)。L_total:总损失,为三者加权和(公式11),权重λ_distill未说明。
- 训练策略:使用Adam优化器,学习率为
1e-4。批大小为32。训练细节(如总轮数、早停策略)未提供。 - 关键超参数:
- EMA动量系数
α:设为0.85。 - 原型拼接概率
r:设为0.6(消融实验中为0.5)。 - 回放样本数
NS:消融实验中测试了1, 2, 3, 4, 10。
- EMA动量系数
- 训练硬件:未说明。
- 推理细节:未说明。
- 正则化或稳定训练技巧:使用了EMA稳定训练过程。
📊 实验结果
实验在MUSIC-21数据集上进行,采用持续学习设置(逐步增加类别)。评估指标为SDR(信号失真比)、SIR(信号干扰比)和SAR(信号伪影比),数值越高越好。
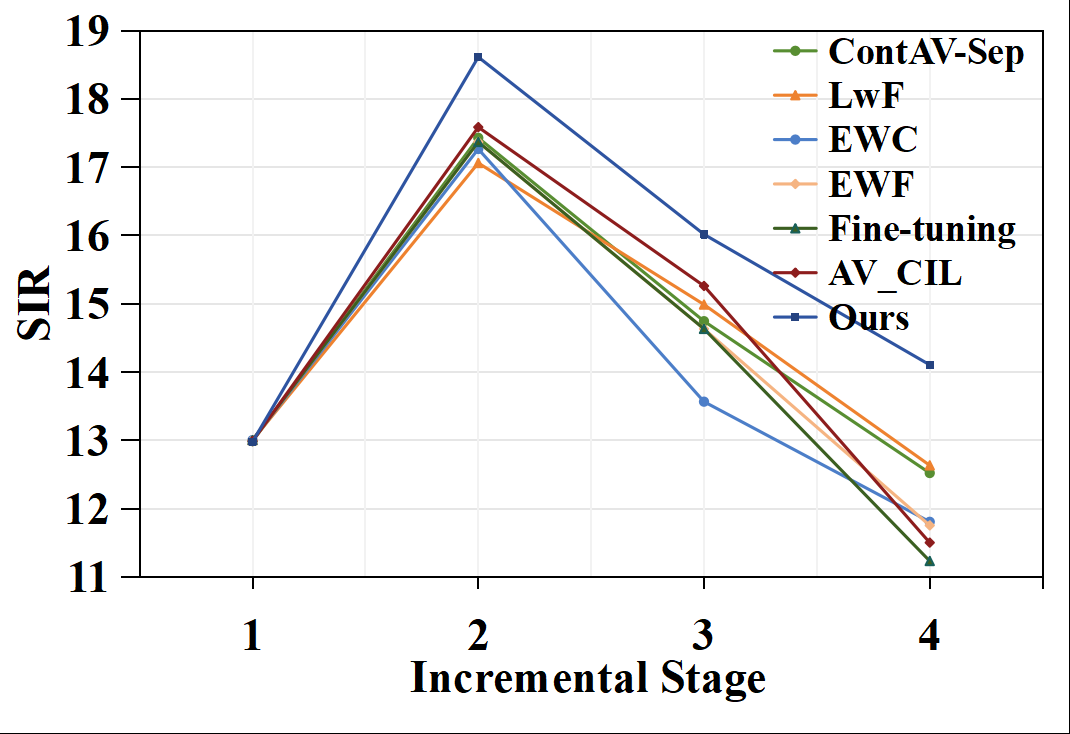
主要对比结果(表1):下表总结了在最后一个学习步骤(Last)和所有步骤平均(Avg)下的性能。PGCCL在所有指标上均显著优于所有基线方法。
| 方法 | Last SDR↑ | Last SIR↑ | Last SAR↑ | Avg SDR↑ | Avg SIR↑ | Avg SAR↑ |
|---|---|---|---|---|---|---|
| Fine-tuning | 5.12 | 11.23 | 11.36 | 5.62 | 8.89 | 12.14 |
| EWC | 5.55 | 11.81 | 11.99 | 5.91 | 9.38 | 11.94 |
| LWF | 6.20 | 12.63 | 12.00 | 6.16 | 9.49 | 12.32 |
| EWF | 5.33 | 11.75 | 11.49 | 5.79 | 9.32 | 11.37 |
| AV-CIL | 5.43 | 11.50 | 11.81 | 6.46 | 9.74 | 12.50 |
| ContAV-Sep | 6.49 | 12.52 | 11.96 | 6.46 | 9.65 | 12.65 |
| PGCCL (Ours) | 8.16 | 14.11 | 13.26 | 6.87 | 10.23 | 12.80 |
| Upper Bound | 9.93 | 16.80 | 13.92 | - | - | - |
消融研究(表2左):验证了PGCCL三个核心组件(PRO:原型对比, EMA, MD:掩码蒸馏)的必要性。完整模型(三者全用)性能最佳。
| PRO | EMA | MD | SDR / SIR / SAR |
|---|---|---|---|
| ✗ | ✓ | ✓ | 6.34 / 12.32 / 12.51 |
| ✓ | ✗ | ✓ | 6.07 / 11.11 / 13.46 |
| ✓ | ✓ | ✗ | 7.27 / 13.64 / 12.56 |
| ✓ | ✓ | ✓ | 7.88 / 13.88 / 13.15 |
回放样本数影响(表2右):增加用于知识保留的旧任务样本数(NS)持续提升分离性能。
| NS | SDR | SIR | SAR |
|---|---|---|---|
| 1 | 7.88 | 13.88 | 13.15 |
| 2 | 7.90 | 14.00 | 13.28 |
| 3 | 8.00 | 14.33 | 13.03 |
| 4 | 8.34 | 14.86 | 13.20 |
| 10 | 9.17 | 15.62 | 13.65 |
可视化结果:论文展示了t-SNE可视化(图2)和跨阶段性能曲线(图3)。图2显示PGCCL的特征表示比基线EWF具有更清晰的类间边界和更少的模态间重叠。图3显示PGCCL在持续学习的各个阶段均保持领先的SDR和SIR。
⚖️ 评分理由
- 学术质量:6.5/7。论文聚焦于一个具体且新兴的交叉问题(CAVSS),提出了一个逻辑清晰、组件设计合理的解决方案(PGCCL)。创新在于有效组合了原型学习、对比学习和持续学习技术来解决多模态表示空间的特定问题。实验设置规范,在标准数据集上与多个相关基线进行了比较,并通过消融研究验证了各组件的有效性,结果具有说服力。扣分点在于创新更多是“组合式”和“适配性”的,而非提出全新的核心思想或解决更大范围的问题。
- 选题价值:1.0/2。持续多模态学习是前沿方向,本文所选的CAVSS任务具有理论价值和潜在应用场景(如动态环境下的机器人、AR)。然而,任务本身非常垂直和细分,应用广度有限。论文未充分论证该任务对于更广泛的语音/音频研究社区的核心重要性。
- 开源与复现加成:0.0/1。论文未提及任何代码、模型、数据或详细配置的开源计划,严重限制了其他研究者快速验证和扩展其工作的可能性。