📄 Prosody-Guided Harmonic Attention for Phase-Coherent Neural Vocoding in the Complex Spectrum
#语音合成 #生成模型 #信号处理 #实时处理
🔥 8.0/10 | 前25% | #语音合成 | #生成模型 | #信号处理 #实时处理
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Mohammed Salah Al-Radhi(布达佩斯理工大学电信与人工智能系)
- 通讯作者:未说明
- 作者列表:Mohammed Salah Al-Radhi(布达佩斯理工大学电信与人工智能系),Riad Larbi(布达佩斯理工大学),Mátyás Bartalis(布达佩斯理工大学电信与人工智能系),Géza Németh(布达佩斯理工大学电信与人工智能系)
💡 毒舌点评
这篇论文的亮点在于它没有“头痛医头”,而是构建了一个从F0引导到相位预测的统一框架,直接针对传统声码器的两大顽疾(音高不准、相位丢失),实验也做得扎实,对比了多个强基线。不过,它对F0的依赖完全建立在外部提取器(Harvest)上,论文并未讨论F0预测不准时的鲁棒性,这在与真实TTS管线对接时可能是个隐患;另外,虽然声称有潜力用于实时应用,但并未提供任何关于模型复杂度、推理速度的量化分析。
🔗 开源详情
- 代码:论文提供了一个公开的代码仓库链接:
https://github.com/malradhi/PACodec。 - 模型权重:论文中未提及是否公开预训练模型权重。
- 数据集:使用的是公开的标准数据集(LJSpeech, VCTK),获取方式是公开的,论文中未提供特定的预处理脚本。
- Demo:论文中未提及在线演示。
- 复现材料:论文中提供了主要的训练超参数(优化器、学习率、批次大小、权重衰减)和部分预处理细节(STFT参数、F0提取算法)。但损失函数的具体权重、模型架构的详细尺寸、训练步数等关键信息未说明。
- 论文中引用的开源项目:论文依赖公开的Harvest F0估计算法。
📌 核心摘要
这篇论文旨在解决神经声码器中存在的音高(F0)建模能力有限和相位重建不准确的问题,这两个问题直接影响合成语音的音高保真度和自然度。其核心方法是提出一个统一的神经声码器框架,包含三个关键组件:1)一个由F0引导的谐波注意力机制,用于在编码阶段增强对有声段和谐波结构的建模;2)一个直接预测复数频谱(实部和虚部)的解码器,以实现相位相干的波形重建;3)一个多目标感知训练策略,结合了对抗损失、频谱损失和相位感知损失。与依赖梅尔谱、相位信息丢失或需要后处理的现有方法(如HiFi-GAN, AutoVocoder)相比,该工作的创新点在于首次将F0引导的注意力机制与直接复数谱预测结合在一个端到端的框架中,从而同时、显式地提升音高精度和相位连贯性。在LJSpeech和VCTK数据集上的实验表明,该方法在所有评估指标上均优于HiFi-GAN和AutoVocoder等基线:F0均方根误差(F0-RMSE)相比HiFi-GAN降低了22%,浊音/清音错误率降低了18%,平均意见得分(MOS)提升了0.15分。其实际意义在于为更自然、更具表现力的语音合成(如情感语音、语音克隆)提供了更强大的声码器基础。主要局限性在于F0信息依赖外部算法提取,且论文未评估模型在F0预测不准时的��棒性,也未充分验证其声称的实时处理能力。
论文关键数据表
| 系统 | F0 RMSE ↓ | V/UV Error (%) ↓ | MCD ↓ | MOS ↑ |
|---|---|---|---|---|
| Original | - | - | - | 4.6 |
| Anchor | 34.8 | 11.5 | 1.21 | 2.1 |
| HiFi-GAN | 21.6 | 7.9 | 0.84 | 4.2 |
| AutoVocoder | 19.7 | 7.1 | 0.79 | 4.3 |
| Vocos | 20.5 | 7.3 | 0.81 | 4.1 |
| Proposed | 16.8 | 6.5 | 0.72 | 4.45 |
🏗️ 模型架构
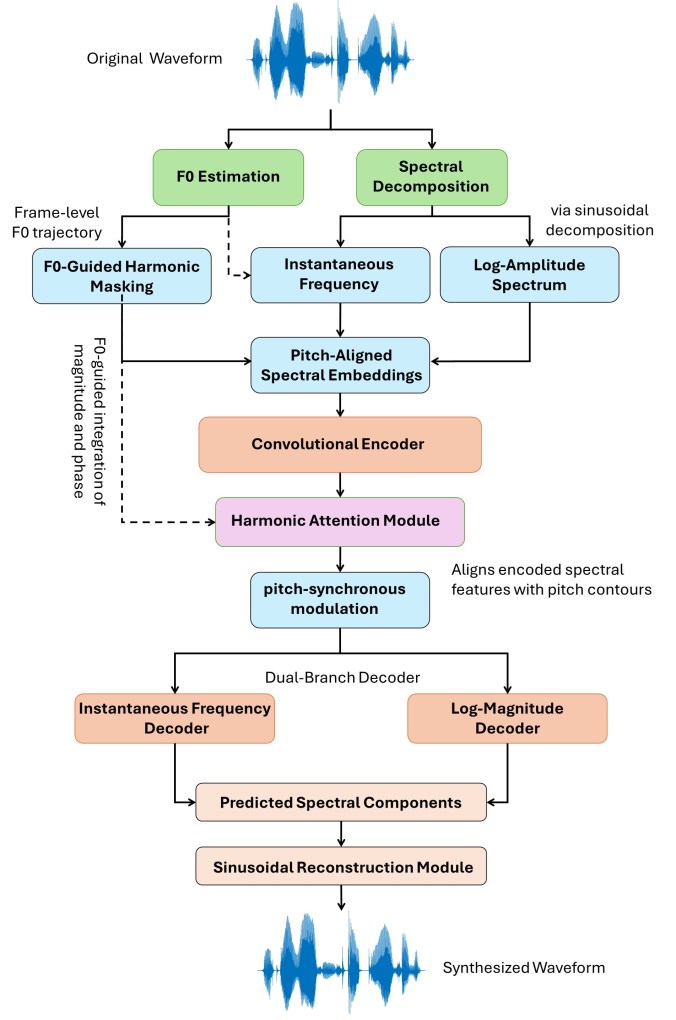
该声码器的整体架构如图1所示,是一个端到端的编码器-解码器模型,最终输出由逆短时傅里叶变换(ISTFT)生成的波形。
- 输入:输入是声学特征(由STFT得到的频谱帧)和韵律线索,主要是基频(F0)。
- 卷积-残差编码器:输入的频谱特征首先通过一个卷积-残差编码器。该编码器的主要功能是提取局部的时间-频率模式。论文未详细说明编码器的具体层数、卷积核大小等内部结构。
- 韵律引导的谐波注意力模块:这是模型的核心创新之一。编码器输出的特征
H与提取并嵌入的F0特征F在此模块交互。该模块计算注意力权重(公式1),使得模型能够根据F0的指示,强调有声区域和谐波结构,同时让无声帧不受影响。这个过程被称为“音高同步调制”。它确保了韵律线索在感知最关键的区域被保留和加强。 - 解码器:经过注意力增强的表示
H'被传递到解码器。解码器是一个卷积-上采样结构,负责将特征扩展到频谱分辨率。最终通过一个线性投影层,为每个帧输出2F个值,分别对应复数频谱的实部(R)和虚部(I)。 - 波形生成:预测的复数频谱
S_hat通过ISTFT直接转换为时域波形。这种设计从构造上保证了相位的连贯性,无需像梅尔谱声码器那样进行额外的相位估计或后处理。
数据流总结:原始波形/STFT特征 + F0 → 编码器 → 韵律引导的谐波注意力(F0注入)→ 解码器 → 预测的复数频谱 → ISTFT → 输出波形。
💡 核心创新点
F0引导的谐波注意力机制:
- 之前局限:以往的声码器(如HiFi-GAN)将F0作为辅助特征拼接或简单融入,或完全忽略。这导致模型无法在编码阶段主动、显式地利用F0信息来强化有声段和谐波结构,从而可能引起音高漂移和谐波模糊。
- 如何起作用:该机制计算基于F0的注意力权重,对编码特征进行“音高同步调制”。它像一个由F0控制的“滤镜”,增强与基频谐波相关的时频成分,抑制无关成分。
- 收益:实验证明,该设计显著降低了F0-RMSE(音高误差)和V/UV错误率(浊音/清音判断错误率),表明其有效提升了韵律建模的保真度。
直接复数频谱预测:
- 之前局限:主流声码器(如HiFi-GAN)在梅尔谱域操作,只预测幅度谱,相位信息被丢弃,需要通过Griffin-Lim等启发式方法或单独的模块进行重建,这会引入相位不连续、时间模糊等伪影。
- 如何起作用:解码器直接输出频谱的实部和虚部,形成一个完整的复数频谱预测。ISTFT操作直接利用这个复数谱重建波形,从而天然地保证了相位的连贯性。
- 收益:与依赖后处理相位估计的方法相比,该设计消除了相位建模的中间环节,实现了更精确的相位重建。实验中更低的MCD(梅尔倒谱失真)和更高的MOS得分支持了这一结论。
多目标感知训练策略:
- 之前局限:单一的损失函数(如仅使用L1距离或仅使用对抗损失)可能难以全面优化语音的多个感知维度(频谱细节、相位一致性、自然度)。
- 如何起作用:训练目标整合了三部分:(a)多分辨率STFT损失,提供多尺度的频谱保真度监督;(b)基于GAN的对抗损失,提升感知自然度;(c)新颖的相位感知损失,通过归一化后的复数谱差异显式惩罚相位失配。
- 收益:该组合损失函数引导模型同时优化频谱精度、相位连贯性和整体自然度,使得模型在所有评估指标上取得均衡提升。
🔬 细节详述
- 训练数据:
- 数据集:使用了LJSpeech 1.1(单说话人,约24小时,22.05kHz)和VCTK(109位说话人,22.05kHz)两个基准数据集。
- 预处理:波形通过1024点FFT、汉宁窗(窗长1024)、256帧移转换为STFT频谱。使用Harvest算法提取F0,并与STFT帧率对齐。
- 数据增强:论文中未提及使用了特定的数据增强技术。
- 损失函数:
- 多分辨率STFT损失:作为互补约束,提供频谱监督。论文未给出其具体权重
λ。 - 对抗损失:采用类似HiFi-GAN的轻量级对抗设置,包含多周期和多分辨率判别器。判别器直接作用于从预测复数谱重建的波形。
- 相位感知损失:公式(3)计算预测与真实复数谱(归一化为单位幅度后)之间的差异,仅关注相位对齐,对幅度缩放不变。论文未给出其具体权重
λ。 - 总损失:公式(4)为各项损失的加权和,权重
λ通过经验调优确定,具体值未说明。
- 多分辨率STFT损失:作为互补约束,提供频谱监督。论文未给出其具体权重
- 训练策略:
- 优化器:AdamW,初始学习率2×10⁻⁴,β1=0.8,β2=0.99,权重衰减0.01。
- 批大小:16。
- 训练硬件/时长:在单个NVIDIA GPU上运行,具体型号和训练时长未说明。
- 训练步数/轮数:未说明。
- 调度策略:未说明是否使用学习率调度器。
- 关键超参数:模型大小(参数量)、层数、隐藏维度、卷积核大小等关键超参数在论文中均未详细说明。
- 推理细节:推理时输入声学特征和相同的Harvest算法提取的F0轮廓。论文强调了在此实验中为隔离声码器性能,使用了“oracle F0”(即来自真实波形的F0),并未讨论F0预测不准时的处理。
- 正则化/稳定训练技巧:除使用AdamW的权重衰减外,未提及其它特定的正则化技巧。
📊 实验结果
主要实验在LJSpeech和VCTK两个数据集上进行。评估包括客观指标和主观MOS测试。与之对比的系统包括原始音频、Griffin-Lim重建(Anchor)、HiFi-GAN、AutoVocoder和Vocos。
主要基准结果(可能基于LJSpeech):
| 系统 | F0 RMSE ↓ | V/UV Error (%) ↓ | MCD ↓ | MOS ↑ |
|---|---|---|---|---|
| Original | - | - | - | 4.6 |
| Anchor | 34.8 | 11.5 | 1.21 | 2.1 |
| HiFi-GAN | 21.6 | 7.9 | 0.84 | 4.2 |
| AutoVocoder | 19.7 | 7.1 | 0.79 | 4.3 |
| Vocos | 20.5 | 7.3 | 0.81 | 4.1 |
| Proposed | 16.8 | 6.5 | 0.72 | 4.45 |
关键发现:
- 音高精度:提出的方法在F0-RMSE上取得了最佳结果(16.8),相比强基线HiFi-GAN(21.6)降低了约22%,相比AutoVocoder(19.7)降低了约15%。V/UV错误率也最低(6.5%),表明其对浊/清音的判断更可靠。
- 频谱保真度:MCD指标显示提出的方法(0.72)优于所有基线,其中比HiFi-GAN(0.84)降低了约14%,表明其生成的频谱更接近原始语音。
- 主观质量:MOS得分达到4.45,显著高于HiFi-GAN(4.2)、AutoVocoder(4.3)和Vocos(4.1)。偏好测试中,提出的方法在88%的情况下被听众偏好。
- 残差分析:图2展示了逐帧的梅尔能量残差。提出的方法残差峰值最低,且整体水平最低,直观地证明了其在时间-频率结构上与原始信号的对齐更紧密,谐波细节保留更好。
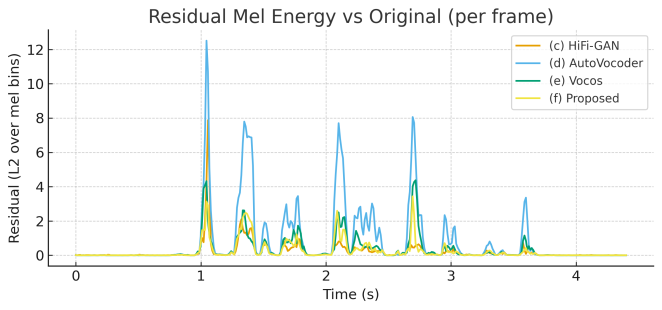
图2说明:该图绘制了每个时间帧上,重建语音与原始语音在梅尔谱能量上的残差。更大的峰值表示时频结构上的失配。AutoVocoder显示出频繁的尖峰,HiFi-GAN和Vocos有中等幅度的波动,尤其在高能量区域。相比之下,提出的声码器与参考信号跟踪得最紧密,残差持续保持在较低水平。这一可视化结果支持了客观指标的结论:更清晰的谐波细节和韵律对齐不仅体现在数字上,也体现在更小的逐帧能量误差中。
消融实验:论文中未明确提供针对各个组件(如谐波注意力、相位感知损失)的消融实验及其具体数值。仅通过与不同基线的对比来论证整体设计的有效性。
⚖️ 评分理由
- 学术质量:6.0/7
- 创新性:提出了将F0引导的谐波注意力与直接复数谱预测相结合的统一框架,针对了两个关键痛点,具有明确的创新组合价值。新颖的相位感知损失也值得注意。
- 技术正确性:方法描述清晰,模型流程符合声学信号处理原理(如STFT/ISTFT的使用)。实验设计合理,对比基线(HiFi-GAN, AutoVocoder, Vocos)是当前主流且有代表性的。
- 实验充分性:在两个标准数据集上进行了实验,评估指标全面(F0-RMSE, V/UV错误, MCD, MOS),并提供了直观的能量残差分析。但缺乏关键的消融研究来证明每个组件的独立贡献。
- 证据可信度:结果数字具体,对比明显,主观测试说明了听众偏好。但训练超参数、模型细节的缺失影响了完全复现的可信度。
- 选题价值:1.5/2
- 前沿性与影响:语音合成的自然度和表现力是持续的研究热点。解决声码器在音高和相位上的瓶颈,对于提升TTS、语音克隆等应用的效果具有直接价值。
- 应用空间:论文提到该工作为富有表现力的神经语音编码奠定了基础。改进后的声码器可应用于需要高保真度和自然韵律的场景。
- 读者相关性:对于从事语音合成、语音处理的研究和工程师来说,这是一项相关且有价值的工作。
- 开源与复现加成:0.5/1
- 代码:论文明确提供了代码仓库链接(
https://github.com/malradhi/PACodec),这是重要的加分项。 - 模型/数据/细节:虽然提供了代码,但论文正文未提及是否公开预训练模型权重、具体的配置文件或训练脚本。关键的超参数(如损失权重、模型维度)在论文中也未完全公开,复现时仍需较多调试。
- 总体:开源代码的存在显著提升了可复现性,但由于训练细节和模型配置的不完全公开,加成不能给满。
- 代码:论文明确提供了代码仓库链接(