📄 Production-Scale Dynamic Vocabulary ASR Biasing with Word-Level FST and Robust Training
#语音识别 #上下文偏差 #动态词汇 #有限状态转录机 #工业应用
✅ 7.5/10 | 前25% | #语音识别 | #上下文偏差 | #动态词汇 #有限状态转录机
学术质量 7.0/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 高
👥 作者与机构
- 第一作者:José E. García Lainez(微软核心AI)
- 通讯作者:未说明
- 作者列表:José E. García Lainez(微软核心AI), Tianyang Sun(微软核心AI), Shaoshi Ling(微软核心AI), Yifan Gong(微软核心AI), Huaming Wang(微软核心AI)
💡 毒舌点评
亮点:这篇论文没有停留在提出一个“新方法”,而是系统性地诊断并解决了其前身DynVoc技术在走向生产部署时会遇到的所有“硬骨头”(如短语重叠、虚警、无偏退化),展现了非常扎实的工程问题解决能力。 短板:所有实验均在微软未公开的大规模内部数据上进行,这虽然是工业论文的常态,但极大地限制了方法的可验证性和可复现性,使得学术界难以直接跟进和公平比较。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用了微软内部未公开的数据(6万小时英语语音及内部测试集),未公开。
- Demo:未提供。
- 复现材料:论文提供了详细的模型架构(层数、维度)、关键超参数(
γ, Pmax, Dmax, κ, δ, λ, θ, β)和训练策略(如干扰项采样、无偏采样),但缺失学习率、优化器、批次大小、训练轮数等核心训练细节。综合来看,复现材料不充分。 - 论文中引用的开源项目:论文引用了多种ASR偏差方法作为对比(如[11] KMP FST),但未明确说明使用了哪些外部开源代码库或模型作为实现基础。
📌 核心摘要
这篇论文旨在解决动态词汇语音识别偏差技术在生产环境部署中面临的三大挑战:1) 对重叠或多词短语的处理能力差,易导致重复识别;2) 偏差过强,虚警率高;3) 引入偏差训练后,在无偏差场景下基础ASR性能下降。为此,作者提出了一套改进方案:核心方法是引入词级有限状态转录机来保留多词短语的序列信息,解决歧义;同时采用训练时扩充干扰项、动态对数几率缩放和边缘损失来降低虚警;并通过在训练中引入无偏批次采样来恢复无偏性能。在基于6万小时英语语音训练的510M参数混合CTC/注意力模型上,实验表明,改进后的方法相比原始DynVoc方法,在召回率上绝对提升6.34%,虚警率绝对降低4.72%,同时将无偏场景的词错率恢复至基线水平。该工作首次将DynVoc技术扩展到生产规模并系统性地解决了其实用化障碍,显著提升了上下文偏差的准确性和可靠性。
🏗️ 模型架构
论文基于一个混合CTC/注意力架构的端到端ASR模型,主要组件及数据流如下:
- 编码器:24层Conformer编码器(注意力维度1024,16头),将输入的语音特征转换为高级表示。
- 解码器:3层Transformer解码器(注意力维度1024,16头),结合CTC和注意力分数进行自回归解码。
- 偏差列表编码器:一个独立的6层Transformer编码器(注意力维度1024,4头),负责处理偏差短语。输入为每个短语的词片嵌入序列,输出经过均值池化得到短语嵌入向量
V。 - 动态词汇生成:在解码每一步,利用解码器隐藏状态
ht与短语嵌入V计算动态词汇的对数几率αb(公式4),将其与原始静态词汇对数几率αn拼接,形成扩展的输出概率分布(公式3)。 - 词级FST解码:在拼接后的对数几率基础上,应用一个基于词的有限状态转录机(FST)进行后处理。该FST保留了多词短语的序列信息,当模型输出匹配到某个短语的第二个及之后的词时,会给予额外的偏置加成
γ,同时抑制其他部分匹配的路径(公式6)。
该架构的关键设计选择在于:偏差列表编码器独立于主模型,可以处理任意长度的短语;将FST作用于“词”级别而非“词片”级别,是为了解决多词短语的歧义问题。
论文中未提供模型架构图。
💡 核心创新点
- 词级FST解决重叠短语歧义:创新点在于将传统用于词片级的FST偏差方法,改造并应用于“动态词汇”生成的词序列上。在训练时将多词短语分解为单个词,但在解码时用FST重新校验序列的合理性。这解决了原始DynVoc无法区分“Ilia”和“Ilia Topuria”这类前缀重叠短语的问题,避免了重复识别和错误组合。
- 动态对数几率缩放:根据当前偏差列表的大小,自动、动态地调整动态词汇对数几率的强度(公式7)。列表越大,单个实体的先验置信度越低,缩放的衰减越强。这比手动在测试时调节权重更自适应,能有效控制大列表下的虚警。
- 边缘损失函数:首次在上下文偏差ASR中引入边缘损失(公式8,9)。它强制要求正确类别的对数几率与动态词汇中所有非正确类别的对数几率之间保持一个最小差距
δ,从而增加静态词汇与动态词汇、正确实体与错误实体之间的区分度,直接对抗“过偏差”倾向。 - 无偏训练采样:在训练数据批次中,以一定概率
β完全移除偏差列表,让模型在没有外部提示的情况下也能正确识别,从而缓解因训练时过度依赖动态词汇而导致的无偏场景性能退化问题。
🔬 细节详述
- 训练数据:使用了60,000小时的微软内部去标识化英语语音数据。
- 损失函数:总损失为加权和:
L = (1−λ)·L_CE + λ·L_CTC + θ·L_margin。其中L_CE是交叉熵损失,L_CTC是CTC损失,L_margin是针对动态词汇的边缘损失。权重λ=0.2,θ=0.01。 - 训练策略:论文未明确说明学习率、warmup、优化器、训练轮数等信息。仅提到了用于无偏采样的超参数
β=0.25。 - 关键超参数:模型参数量:ASR模型510M,偏差列表编码器92M。偏差偏置权重
γ=5。正样本采样数Pmax=10,负样本(干扰项)采样数Dmax=300。边缘超参数δ=2。动态缩放超参数κ=1.5。稀有词阈值T=20000。 - 训练硬件:未说明。
- 推理细节:使用结合CTC和注意力分数的束搜索解码器。推理时会根据偏差列表大小动态应用对数几率缩放(公式7),并通过扫描
dynvoc权重(0.01-1.0)来获得不同的召回-虚警工作点。 - 正则化技巧:使用了干扰项(Distractors) 和边缘损失作为主要的正则化手段,以防止模型过拟合于训练时的特定偏差列表并降低虚警。
📊 实验结果
测试集包括公开的Earnings 21和15个内部测试集,共包含8,487个实体。评估指标为词错率(WER)、实体词错率(EWER)、召回率(Recall)和虚警率(FA)。
表2:无偏条件性能对比
| 方法 | WER | EWER | Recall | FA |
|---|---|---|---|---|
| 基线ASR | 9.39 | 35.42 | 61.15 | 10.87 |
| DynVoc (原始) [12] | 9.58 | 37.51 | 58.80 | 11.18 |
| DynVoc (本文) | 9.39 | 35.55 | 60.76 | 11.03 |
| 结论:原始DynVoc在所有指标上均变差,本文方法成功恢复了基线性能。 |
表3:偏差条件下性能对比(平均)
| 方法 | WER | EWER | Recall | FA |
|---|---|---|---|---|
| 基线(无偏) | 9.39 | 35.42 | 61.15 | 12.26 |
| FST [11] | 9.24 | 22.47 | 75.44 | 20.02 |
| DynVoc (原始) [12] | 9.45 | 23.67 | 74.00 | 25.00 |
| DynVoc (本文) | 9.15 | 17.32 | 80.34 | 20.28 |
| 结论:本文方法在EWER、Recall和FA上全面超越了两个基线。特别是在理想偏差列表+200干扰项的条件下(更现实的场景),本文方法EWER为17.28,远好于原始DynVoc的23.21和FST的22.00。 |
表4:消融实验(三个偏差条件的平均)
| 模型 | dynvoc权重 | WER | EWER | Recall | FA |
|---|---|---|---|---|---|
| DynVoc (原始) | 0.01 | 9.45 | 23.67 | 74.00 | 25.00 |
| + 多词转单词 | 0.01 | 9.38 | 22.08 | 75.58 | 20.86 |
| + FST | 0.01 | 9.36 | 21.08 | 76.68 | 20.43 |
| + 干扰项 | 0.03 | 9.35 | 20.42 | 77.44 | 19.52 |
| + 动态缩放 | 0.10 | 9.37 | 20.02 | 77.47 | 19.13 |
| + 边缘损失 | 0.30 | 9.26 | 16.92 | 80.79 | 20.67 |
| + 无偏训练 | 0.30 | 9.15 | 17.32 | 80.34 | 20.28 |
| 结论:每一项改进都逐步带来了EWER的降低和Recall的提升。最终系统相比原始版本,EWER下降了6.35个点,Recall提升了6.34个点。 |
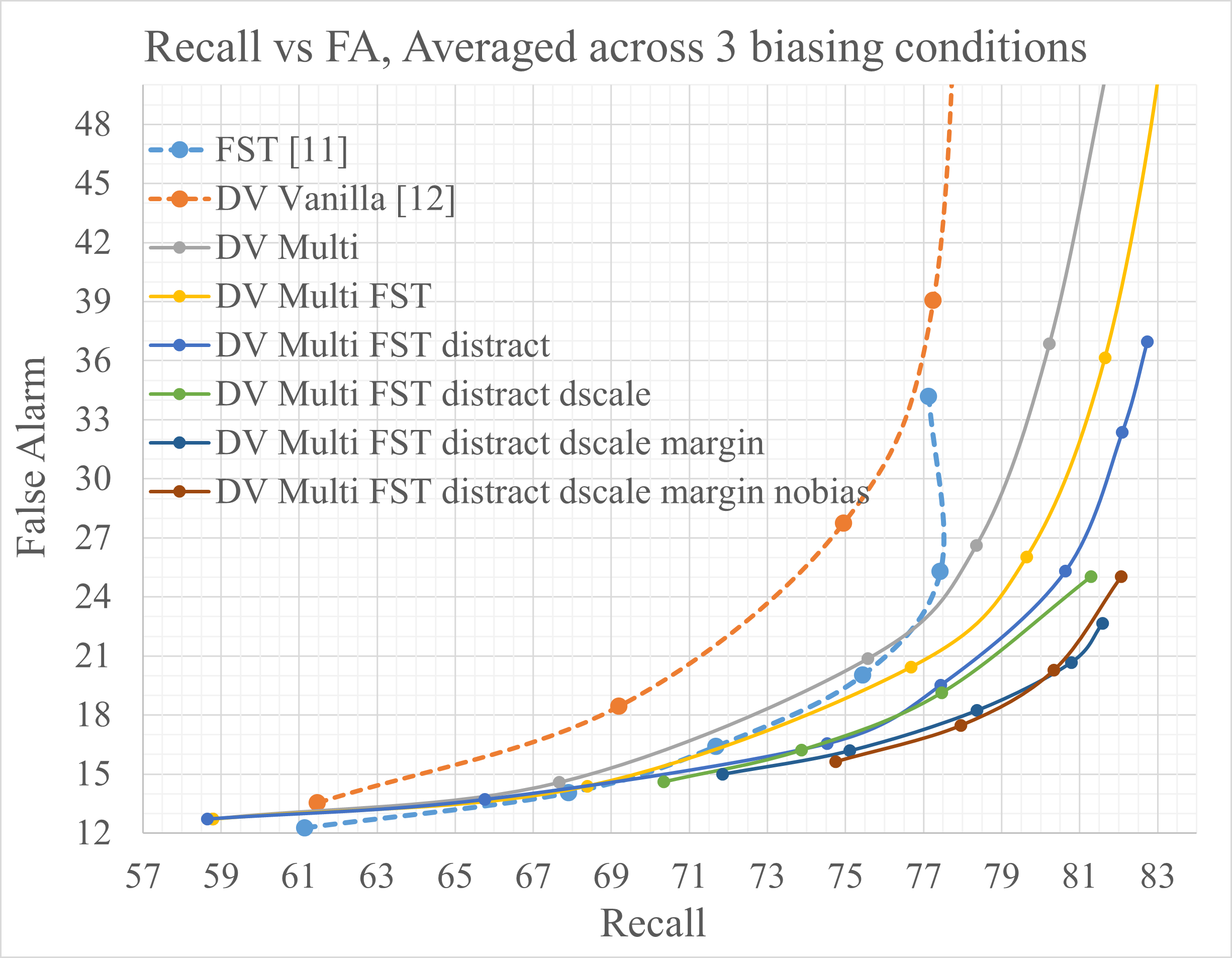 图1描述:该图展示了不同偏差系统在调整
图1描述:该图展示了不同偏差系统在调整dynvoc权重时,召回率(Recall)与虚警率(FA)的权衡曲线。曲线越靠右下角,表示在相同虚警率下召回率越高,或相同召回率下虚警率越低,性能越好。图中“DynVoc (Ours)”的曲线明显位于“DynVoc Vanilla”和“FST”基线的右下方,直观地证明了本文所提技术对召回-虚警权衡曲线的显著改善。
⚖️ 评分理由
- 学术质量:7.0/7。论文针对一个明确的生产化问题,提出了一系列相互配合、动机清晰的技术解决方案(FST、动态缩放、边缘损失、无偏训练)。实验设计全面,包含多条件对比和深入的消融研究,数据规模大,证据扎实。扣分点在于,虽然解决了DynVoc的特定问题,但对更广泛的上下文偏差领域(如与Pointer-Generator等方法的对比)着墨较少,且部分方法(如多词转单词)会损失信息。
- 选题价值:1.5/2。上下文偏差是ASR产品化的核心难题,动态词汇是近年来的热点技术。本文直面该技术从实验室到生产线的“最后一公里”问题,具有极高的实际应用价值和行业参考意义。
- 开源与复现加成:-0.5/1。论文完全基于未公开的微软内部数据,且未提供代码、模型或详细训练流程。尽管论文中披露了大量超参数和架构细节,但外部研究者无法复现其核心实验,这严重限制了成果的开放性和可验证性。