📄 PRoADS: Provably Secure And Robust Audio Diffusion Steganography With Latent Optimization And Backward Euler Inversion
#音频安全 #扩散模型 #音频生成
✅ 6.5/10 | 前50% | #音频安全 | #扩散模型 | #音频生成
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 高
👥 作者与机构
- 第一作者:Yongpeng Yan(武汉大学国家网络安全学院)
- 通讯作者:Yanzhen Ren(武汉大学国家网络安全学院)
- 作者列表:Yongpeng Yan(武汉大学国家网络安全学院),Yanan Li(武汉大学国家网络安全学院),Qiyang Xiao(武汉大学国家网络安全学院),Yanzhen Ren(武汉大学国家网络安全学院,武汉大学航空航天信息安全与可信计算教育部重点实验室)
💡 毒舌点评
亮点: 本文精准地抓住了“初始噪声嵌入式”扩散隐写方法在逆向提取时的痛点——重建误差,并针对性地提出了“潜在空间优化”和“后向欧拉反演”两个技术改进,实验结果也清晰地证明了其有效性(BER显著降低),是一篇问题导向明确、解决方案扎实的改进型工作。 短板: 论文最大的软肋在于其核心实验基础——EzAudio模型——的复现信息几乎完全缺失,且未开源任何代码,这使得其宣称的“可复现”和“高效”大打折扣;同时,提取过程的高计算开销(106秒 vs 6.8秒)限制了其实时应用场景,论文对此的讨论也较为轻描淡写。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开PRoADS模型的权重。实验使用的是预训练的EzAudio模型,但论文未给出其具体获取方式或版本。
- 数据集:使用了公开的AudioCaps数据集,但未说明具体版本和使用方式。
- Demo:未提供在线演示。
- 复现材料:未提供训练细节(本方法无需训练)、配置文件、检查点或附录说明。复现依赖于对论文算法描述的理解和对EzAudio模型的自行配置。
- 论文中引用的开源项目:明确依赖于EzAudio [7] 音频扩散模型进行实验。其他基线方法(如GSD, DiffStega, Gaussian Shading)也多为已发表的工作,但本文未提供其代码链接。
📌 核心摘要
本文旨在解决基于扩散模型的生成式音频隐写术中,由于扩散模型逆向过程误差导致的秘密消息提取比特错误率(BER)过高的问题。其核心方法是提出PRoADS框架,通过正交矩阵投影将消息嵌入扩散模型初始噪声,并引入两项关键技术来最小化逆向误差:一是在编码器将隐写音频转为潜在表示后,进行潜在空间梯度优化以逼近原始潜在变量;二是采用更精确的后向欧拉迭代法替代朴素的DDIM反演来求解扩散逆过程。与现有方法(如Hu[17])相比,本文的主要新意在于同时从“潜在变量重构”和“扩散逆过程求解”两个层面减少误差。实验表明,在EzAudio模型上,PRoADS在64 kbps MP3压缩攻击下实现了0.15%的低BER,相比基线方法有显著提升(例如在DPMSolver下,较Hu[17]降低约0.5%)。该工作的实际意义在于为生成式音频隐写提供了更高鲁棒性的解决方案,主要局限性是提取过程计算开销大(106秒),且未提供开源代码和详细模型参数,限制了复现与应用。
🏗️ 模型架构
本文提出的PRoADS是一个音频隐写框架,其完整流程如下:
- 消息嵌入与隐写音频生成:
- 输入:秘密消息二进制比特流、一个预训练的音频扩散模型(EzAudio)及其编码器E(·)和解码器D(·)。
- 过程:首先,通过正交矩阵投影将消息映射为一个噪声矩阵,并填充、置乱、重塑为与模型潜在空间匹配的初始噪声
zs。然后,使用标准的音频扩散模型生成过程(与正常生成完全相同)将zs转换为隐写音频x。 - 输出:隐写音频
x。
- 秘密消息提取:
- 输入:接收到的(可能被攻击的)隐写音频
x、相同的扩散模型及参数。 - 过程:
潜在空间优化(Latent Optimization):使用编码器E(·)将音频
x编码为潜在表示z。由于编码器非完美可逆,通过梯度下降优化z,使其解码后尽可能还原x,得到优化后的潜在变量z。此步骤由Algorithm 1(功率法/梯度下降)实现。 后向欧拉反演(Backward Euler Inversion):将优化后的z作为扩散逆过程的起点。采用后向欧拉迭代法(而非标准DDIM的显式近似)逐步逆向求解扩散ODE,以更高精度恢复初始噪声z_hat_t0。论文提供了基于DDIM的一阶求解器(Algorithm 2)和基于DPM-Solver的二阶求解器(Algorithm 3)两种实现。- 消息恢复:对恢复的初始噪声
z_hat_t0执行与嵌入过程相反的操作(逆置乱、裁剪、正交矩阵逆投影)得到原始消息比特M。
- 消息恢复:对恢复的初始噪声
- 输出:提取的秘密消息
M。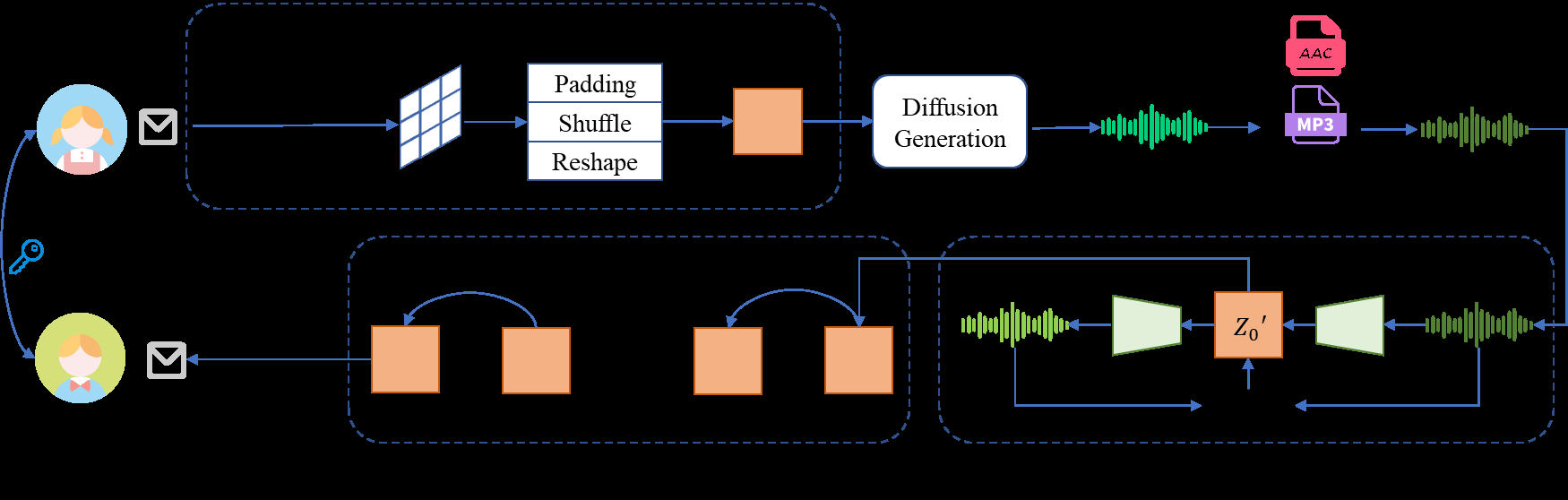 图1展示了上述框架。左侧为嵌入与生成流程:消息
图1展示了上述框架。左侧为嵌入与生成流程:消息M经投影、填充、置乱、重塑得到zs,再通过扩散模型生成x。右侧为提取流程:对x进行潜在空间优化得到z*,然后通过后向欧拉反演恢复初始噪声,最后经逆操作得到消息M。图中明确区分了正常生成(虚线箭头)与隐写过程(实线箭头),并突出了潜在优化和后向欧拉反演两个核心模块。
- 输入:接收到的(可能被攻击的)隐写音频
💡 核心创新点
- 潜在空间优化以减少编码器重构误差:针对潜在扩散模型中编码器-解码器非完美对偶性导致的潜在变量重建误差,提出在消息提取前对编码后的潜在表示进行基于梯度的迭代优化,使其更接近原始生成时的潜在状态,从而减少后续逆向过程的输入误差。
- 后向欧拉反演替代朴素扩散逆向:指出并解决现有初始噪声嵌入方法所使用的朴素逆向(如DDIM反演)在数值求解上的不精确性。通过引入隐式求解的后向欧拉迭代法,将相邻时间步的误差控制在阈值
ϵ内,显著提高了初始噪声的恢复精度。论文为此提供了针对一阶(DDIM)和二阶(DPM-Solver)求解器的具体算法。 - 适用于音频潜在空间的嵌入算法适配:对基于正交矩阵的消息嵌入算法进行调整,以适应音频扩散模型通常具有的不同形状的潜在空间(如[E, T]),引入了填充(Padding)和重塑(Reshape)操作。
🔬 细节详述
- 训练数据:使用了AudioCaps数据集进行实验。论文未说明训练集、验证集、测试集的划分,也未说明数据预处理细节(如音频长度、采样率统一化方法)。
- 损失函数:论文中未提及训练损失函数。本文工作是免训练的,其核心方法(潜在优化、后向欧拉反演)应用于预训练好的扩散模型(EzAudio),无需针对隐写任务进行重新训练。
- 训练策略:不适用。论文未进行任何模型训练。
- 关键超参数:
- 潜在优化:迭代步数
n和步长h(未说明具体数值)。 - 后向欧拉反演:迭代步长
h和收敛阈值ϵ(未说明具体数值)。 - 嵌入容量:统一为57344(14 × 64 × 64)比特。
- 扩散模型调度器:对比了DDIM和DPM-Solver。
- 潜在优化:迭代步数
- 训练硬件:未说明。
- 推理细节:
- 生成端:生成10秒24kHz音频耗时6.8秒,与正常生成过程无异。
- 提取端:由于需要迭代求解逆向过程,提取过程耗时106秒。论文承认计算开销大,但认为准确性更重要。
- 正则化或稳定训练技巧:不适用。
📊 实验结果
论文在AudioCaps数据集上,使用EzAudio模型评估了多种攻击下的比特错误率(BER)。
主要对比实验(Table 1):
| 调度器 | 方法 | 无攻击 | AAC压缩(64kbps) | MP3压缩(64kbps) | 重采样(下采样) | 高频衰减 |
|---|---|---|---|---|---|---|
| DDIM | Yang[16] | 6.55 | 6.81 | 9.57 | 7.23 | 8.31 |
| Kim[15] | 1.44 | 1.54 | 2.58 | 2.42 | 2.22 | |
| Hu[17] | 0.11 | 0.13 | 0.26 | 0.46 | 0.19 | |
| PRoADS | 0.09 | 0.11 | 0.21 | 0.25 | 0.15 | |
| DPMSolver | Yang[16] | 7.17 | 7.45 | 9.09 | 7.69 | 8.68 |
| Kim[15] | 1.71 | 1.82 | 2.97 | 2.44 | 2.56 | |
| Hu[17] | 0.62 | 0.62 | 0.84 | 0.83 | 0.75 | |
| PRoADS | 0.12 | 0.15 | 0.30 | 0.29 | 0.24 |
关键结论:PRoADS在所有攻击场景下均达到了最低的BER。在最具挑战性的64kbps MP3压缩攻击下,DDIM调度器的BER为0.21%,DPMSolver调度器的BER为0.30%,相比最强基线Hu[17]分别降低了0.04%和0.54%。
消融实验(Table 2):
| 攻击 | 基线 | +潜在优化(L.O.) | +后向欧拉(B.E.) | +L.O.+B.E. |
|---|---|---|---|---|
| 无 | 0.62 | 0.22 | 0.19 | 0.12 |
| AAC(192kbps) | 0.63 | 0.23 | 0.22 | 0.15 |
| AAC(64kbps) | 0.84 | 0.39 | 0.39 | 0.30 |
| 下采样 | 0.67 | 0.25 | 0.23 | 0.16 |
| 高频衰减 | 0.83 | 0.39 | 0.39 | 0.29 |
| 低频增强 | 0.61 | 0.21 | 0.19 | 0.13 |
关键结论:消融实验证明,潜在空间优化和后向欧拉反演均能独立降低BER,且两者结合效果最佳(L.O.+B.E.列)。在轻度攻击(如192kbps AAC)下B.E.略优,在重度攻击(64kbps AAC,高频衰减)下两者效果相当,结合使用提升约0.5%。
⚖️ 评分理由
- 学术质量:5.5/7。论文问题定位准确,提出的两项技术改进逻辑清晰,且通过消融实验验证了其有效性。实验比较了多个基线方法和多种攻击类型,结论有数据支撑。扣分点在于:1)创新性为增量改进而非开创性;2)核心依赖的音频扩散模型(EzAudio)的具体配置和训练细节缺失,可复现性存疑;3)未讨论后向欧拉迭代可能引入的额外误差或不稳定情况。
- 选题价值:1.5/2。音频隐写在信息隐藏和安全通信领域具有明确应用价值,本文提升了该领域的鲁棒性基准。但研究方向相对垂直,受众较窄,且生成式隐写本身面临监管和伦理挑战,限制了其更广泛的影响力。
- 开源与复现加成:-0.5/1。论文未提供任何代码、模型权重或详细的复现配置。虽然基于公开模型(EzAudio),但论文未说明其使用的具体模型版本、训练/微调状态、以及所有实验中的精确超参数(
n,h,ϵ)。这使得独立复现论文结果非常困难。