📄 Principled Coarse-Grained Acceptance For Speculative Decoding In Speech
#语音合成 #推测解码 #语音大模型 #自回归模型
✅ 7.5/10 | 前25% | #语音合成 | #推测解码 | #语音大模型 #自回归模型
学术质量 6.8/7 | 选题价值 1.6/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Moran Yanuka(1 Apple, 2 Tel-Aviv University)
- 通讯作者:未说明
- 作者列表:Moran Yanuka(Apple, 特拉维夫大学)、Paul Dixon(Apple)、Eyal Finkelshtein(Apple)、Daniel Rotman(Apple)、Raja Giryes(特拉维夫大学)
💡 毒舌点评
论文的亮点在于从第一性原理出发,将语音标记的“声学模糊性”转化为推测解码的“��势”,提出的重叠声学相似性组(ASG)和精确的组级拒绝采样框架在理论上很优雅,且实验显著提升了接受率与生成质量。短板在于其对比的基线(特别是SSD)相对较弱,且实验设置相对简单(单一8B模型、单一数据集、固定加速比),未能充分展示该方法在更复杂、更具挑战性场景下的鲁棒性和普适潜力,开源代码的缺失也影响了社区的快速验证。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:实验使用LibriTTS,这是一个公开数据集,但论文未说明具体使用方式。草稿模型训练使用的“Libri-heavy子集”未公开细节。
- Demo:未提及。
- 复现材料:论文提供了一些关键超参数(温度、推测长度、阈值范围)和模型规格(LLaSA-8B,3层草稿模型),但缺少完整的训练配置、代码和预训练权重,不足以支持完整复现。
- 论文中引用的开源项目:引用了LLaSA [12]、Libri-heavy [14]、WavLM [16] 等,但未说明是否使用了其开源实现或权重。
- 开源计划:论文中未提及开源计划。
📌 核心摘要
- 问题:在语音大模型的自回归生成中应用标准推测解码(SD)效率低下,因为许多离散语音标记在声学上是可互换的,严格的标记匹配会拒绝大量合理的草案,导致接受率低,速度提升有限。
- 方法核心:提出“原理性粗粒化”(PCG)框架。核心是构建“声学相似性组”(ASG):在目标模型的嵌入空间中,将余弦相似度超过阈值的语音标记聚合成重叠的组。验证时,不再比对单个标记,而是比对标记所属的组。
- 创新点:相比之前的启发式放宽(如SSD)或限制采样池(top-k)的方法,PCG为组变量定义了精确的重叠感知粗粒分布,并在组级别进行符合目标分布的拒绝采样,提供了严格的分布保证。同时,重叠的组设计保留了平滑的声学邻域。
- 主要实验结果:在LibriTTS数据集上,以LLaSA-8B为目标模型,在获得1.4倍加速时,PCG的WER为13.8,CER为7.8,均优于SSD(WER 18.5, CER 11.6),且说话人相似度(Sim-O)和自然度(NMOS)更高。消融实验表明,在ASG中随机替换标记仅引起微小的质量下降,验证了组内标记的可互换性假设。
- 主要结果对比表:
方法 加速比 WER ↓ CER ↓ Sim-O ↑ NMOS ↑ Draft模型 5.2× 52.8 ± 1.6 41.4 ± 1.8 36.3 ± 1.1 - Target + SD 0.98× 11.1 ± 0.6 5.5 ± 0.5 43.7 ± 0.3 4.38 ± 0.88 Target + SSD [3] 1.4× 18.5 ± 1.9 11.6 ± 1.7 42.5 ± 0.4 3.78 ± 1.21 Target + PCG 1.4× 13.8 ± 0.4 7.8 ± 0.3 43.7 ± 0.1 4.09 ± 1.13
- 主要结果对比表:
- 实际意义:提供了一种简单、通用且理论可靠的方法,可以显著提升基于离散标记的语音生成模型的推理速度,同时保持生成质量,特别适用于对延迟敏感的端侧应用。
- 主要局限性:实验主要集中在单个数据集和模型上;ASG的构建依赖目标模型的嵌入空间和阈值θ,其泛化性有待验证;论文未提供代码,限制了复现和快速应用。
🏗️ 模型架构
论文并未提出一个新的生成模型架构,而是提出了一个适用于现有自回归语音生成模型的推测解码框架。其整体流程如图2所示。
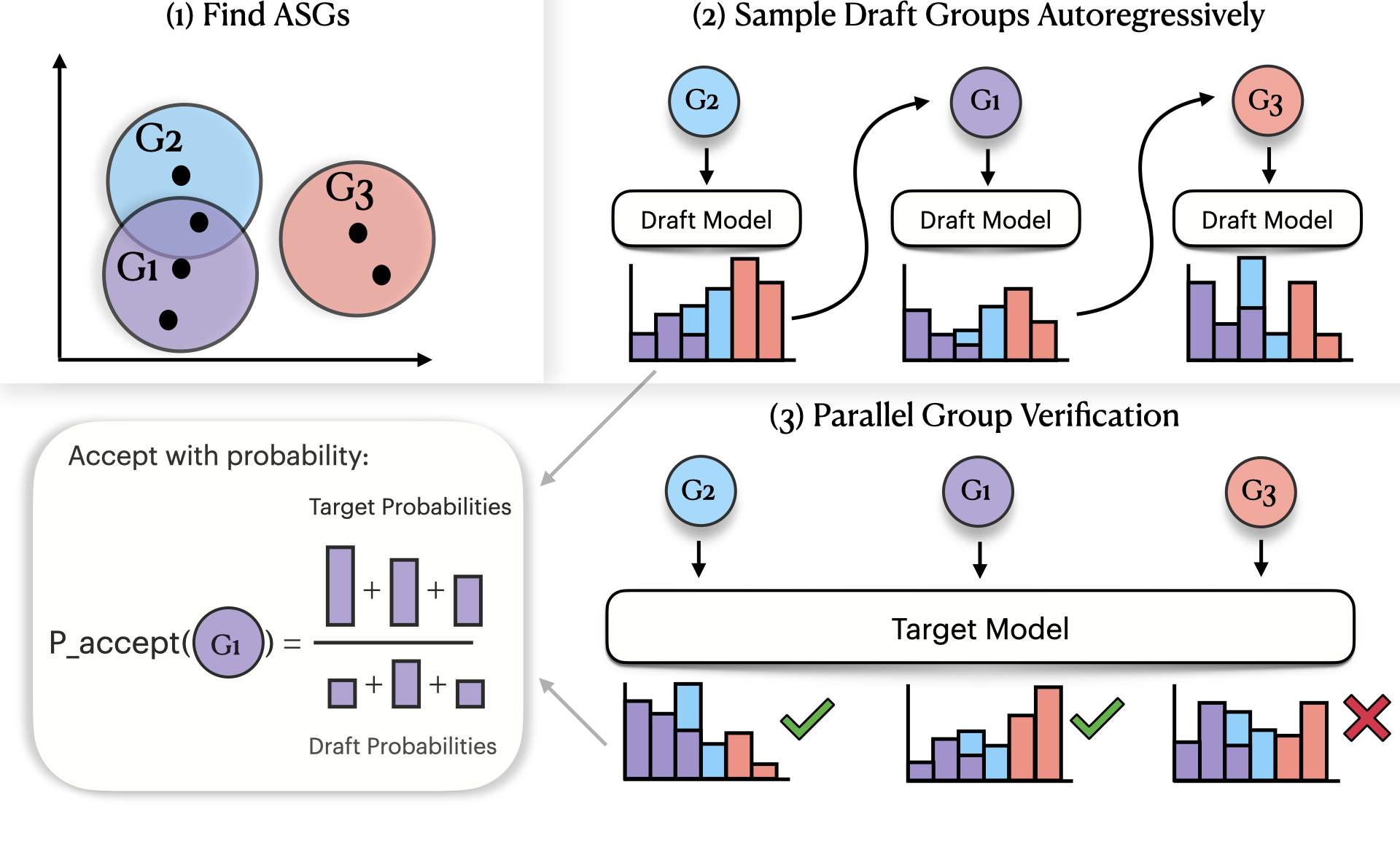
- 组件与数据流:
- 离线组构建:在目标模型 \(q\) 的嵌入空间中,根据余弦相似度阈值 \(\theta\) 为所有语音标记 \(t\) 构建声学相似性组(ASG)集合 \(\{G_k\}_{k=1}^M\)。一个标记可属于多个组(重叠)。
- 草稿模型提议:快速草稿模型 \(p\) 自回归地生成长度为 \(L_d\) 的草案标记序列 \(x_1, ..., x_{L_d}\)。
- 组级耦合与验证:对于每个草案标记 \(x_i\),根据预定义的权重 \(w_{k,x_i}\)(默认均匀划分)采样一个组标签 \(K_i\)(算法第3步)。目标模型 \(q\) 并行计算所有位置的粗粒分布 \(Q_c(G_k)\)。然后根据组级分布计算接受概率 \(r_i = \min(1, Q_c^{(i)}(G_{K_i}) / P_c^{(i)}(G_{K_i}))\),并进行接受/拒绝判定(算法第4-5步)。
- 残差采样:若拒绝,则从组级残差分布 \(R_c^{(i)} \propto [Q_c^{(i)} - P_c^{(i)}]_+\) 中采样一个新的组,并在该组内根据目标分布 \(q\) 采样一个具体标记(算法第6步,
GROUPRESIDUALSAMPLER)。 - 输出:输出的标记序列 \(T_{in}\) 在组级别上精确服从目标模型的粗粒分布 \(Q_c\)。
- 关键设计选择:
- 重叠组:允许一个标记属于多个组,避免了硬聚类造成的声学边界,保留了邻近声学空间。
- 组内概率分配:通过权重 \(w_{k,t}\) 将标记 \(t\) 的概率质量分配到其所属的各组中,确保粗粒分布 \(P_c\) 和 \(Q_c\) 是合法分布。
- 接受后保留草稿标记:为维持KV缓存有效性和计算效率,在组被接受后,使用原始草稿标记 \(x_i\) 作为代表,这牺牲了标记级的精确性,但保证了组级分布的正确性和实际加速。
💡 核心创新点
- 声学相似性组(ASG)与重叠设计:基于目标模型嵌入空间构建声学上不可区分的标记组。重叠设计是关键,它使得组能够反映声学空间的连续性,而非离散的、不相交的簇,这更符合语音的物理特性。
- 精确的粗粒化推测采样:提出了在重叠组变量上进行推测采样的数学框架。通过定义基于权重的概率分配和组级拒绝采样,严格证明了输出序列在组级别上精确匹配目标模型的粗粒分布,提供了现有方法所缺乏的理论保证。
- 面向语音的通用加速框架:该方法不依赖于特定模型架构或任务,只要生成过程是基于离散标记的自回归,且标记在嵌入空间中存在可捕捉的声学/语义相似性,即可应用。提供了一种“即插即用”的加速思路。
🔬 细节详述
- 训练数据:
- 目标模型(LLaSA-8B)的训练数据:未在本文说明。
- 草稿模型的训练数据:基于Libri-heavy [14](50,000小时读英语)的一个子集进行训练。未说明具体子集规模和划分。
- 损失函数:未说明草稿模型训练的具体损失函数。推测为标准的自回归交叉熵损失。
- 训练策略:草稿模型是3层的LLaSA-8B子集,使用LLaSA-8B参数初始化。未说明优化器、学习率、训练轮数等。论文提到“未进行重度优化(如知识蒸馏)”。
- 关键超参数:
- 目标模型:LLaSA-8B,码本大小65,536。
- 草稿模型:3层Transformer。
- 推理参数:温度0.8,推测长度(lookahead)\(L_d=3\)。
- PCG核心参数:ASG构建阈值 \(\theta \in [0.38, 0.45]\) 最优;组内权重 \(w_{k,t}\) 默认均匀分配。
- 训练硬件:未说明。
- 推理细节:在单张NVIDIA H100-80GB GPU上运行。标准推测解码流程,但验证部分替换为PCG的组级验证。
- 正则化或稳定训练技巧:未提及。
📊 实验结果
- 主要Benchmark与数据集:LibriTTS (test-clean) 上的零样本语音克隆任务。
- 主要指标:词错误率(WER,由HuBERT-large ASR计算)、字错误率(CER)、说话人相似度(Sim-O,由WavLM计算)、自然度平均意见分(NMOS,人工评测)。
- 与基线对比:
- vs. 标准推测解码(SD):标准SD在本设置下加速比仅为0.98×(几乎无加速),但WER/CER最低。PCG在实现1.4×加速的同时,WER/CER(13.8/7.8)远优于几乎无加速的SD(11.1/5.5),且与SD质量差距小于与SSD的差距。
- vs. 语音推测解码(SSD):在相同1.4×加速比下,PCG在所有指标上均优于SSD。WER降低25.4%(18.5->13.8),CER降低32.8%(11.6->7.8),说话人相似度更高(43.7 vs 42.5),自然度MOS也更高(4.09 vs 3.78)。统计检验表明PCG与SSD差异显著(p=0.039)。
- 消融实验:
- 组内标记替换压力测试:在目标生成的序列上,随机替换属于多成员组的标记。结果显示,即使替换超过90%的标记,相对目标原始输出的WER增加仅0.007,Sim-O下降0.027。这强力支持了ASG内标记可互换的假设。
- 相似性度量消融:对比使用梅尔频谱相似性和嵌入余弦相似性构建ASG。结果显示,基于余弦相似性的PCG在相同加速比下WER更低(12.6 vs 13.9),CER更低(6.6 vs 7.9),说话人相似度相当(43.7)。说明模型嵌入空间的结构比直接声学特征更适合作为分组依据。
- 推测长度消融:未给出具体数据,但论文指出推测长度为3时最优。
- 图表:
- 图3:精度-加速权衡曲线:
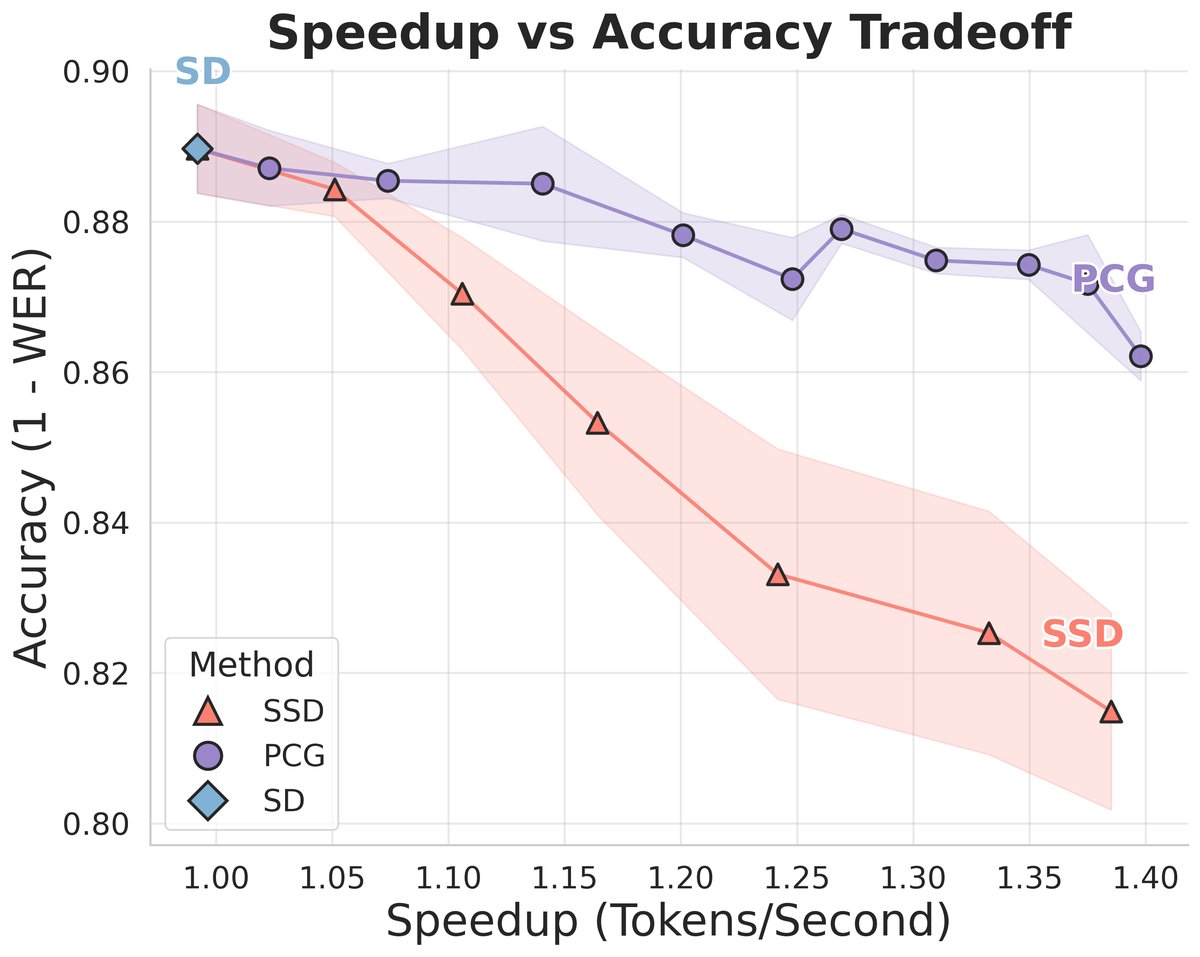
- 结论:该图展示了不同方法(SD, SSD, PCG)在WER与加速比之间的权衡。标准SD(蓝点)位于左下角(低加速、低WER)。SSD(橙点)位于其右上方,加速比提升但WER显著增加。PCG(绿点)的曲线位于SSD曲线的下方和左侧,表明在相同WER下PCG能获得更高加速比,或在相同加速比下WER更低,体现了更优的权衡。
- 图3:精度-加速权衡曲线:
⚖️ 评分理由
- 学术质量(6.8/7):方法有坚实的数学证明,实验设计合理,结论有数据支撑。创新点清晰,解决了语音推测解码中的具体问题。主要扣分点在于实验的广度和深度有限(单一数据集、模型、基线),且未与其他潜在的、更先进的推测解码变体对比。
- 选题价值(1.6/2):主题是当前大模型效率优化的热点方向,且针对语音特性提出了解决方案,具有明确的实用价值和推广潜力。扣分点在于研究范围较为狭窄,聚焦于一种特定技术路径。
- 开源与复现加成(0.0/1):论文完全未提供代码、模型或详细训练配方,严重阻碍复现和后续工作。这是主要的扣分项。