📄 Poly-SVC: Polyphony-Aware Singing Voice Conversion with Harmonic Modeling
#歌唱语音转换 #流匹配 #和声建模 #零样本 #时频分析
✅ 6.5/10 | 前50% | #歌唱语音转换 | #流匹配 | #和声建模 #零样本
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Chen Geng(北京建筑大学智能科学与技术学院;未说明具体实验室)
- 通讯作者:Ruohua Zhou(北京建筑大学智能科学与技术学院)
- 作者列表:Chen Geng(北京建筑大学智能科学与技术学院), Meng Chen(腾讯音乐娱乐Lyra Lab), Ruohua Zhou(北京建筑大学智能科学与技术学院), Ruolan Liu(未说明), Weifeng Zhao(腾讯音乐娱乐Lyra Lab)
💡 毒舌点评
亮点在于它跳出了SVC研究中“追求干净人声输入”的理想化假设,转而直接解决“脏”数据带来的音高提取难题,这种务实的问题导向值得肯定。但短板也明显:其核心“复音感知”能力主要归功于选用了CQT这一成熟工具,而非模型本身的革命性设计,且所有评估依赖主观听感,缺少客观的音高预测或和声保真度量化指标,使得“超越SOTA”的结论说服力打了折扣。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及是否公开模型权重。
- 数据集:作者模拟构建的“和声数据集”未说明是否公开及获取方式。
- Demo:未提及提供在线演示。
- 复现材料:给出了部分超参数(如CQT设置、优化器),但缺失训练步数、batch size、硬件信息、数据预处理流程等关键细节。
- 论文中引用的开源项目:Whisper, CampPlus, OpenVoice, Firefly-GAN, SeedVC, UVR等。
📌 核心摘要
- 要解决什么问题:现有歌唱语音转换(SVC)系统严重依赖从干净人声中提取的F0(基频)来捕获旋律,但在真实场景中,人声分离工具(如Demucs)处理后的音频往往残留和声,这会干扰传统F0提取器,导致转换后歌声出现跑调或音质下降。
- 方法核心是什么:论文提出了Poly-SVC框架,其核心是三个组件:(1) 基于CQT的音高提取器:利用常数Q变换(CQT)的时频表示,同时保留主旋律和残留和声的多音高信息;(2) 随机采样器:在训练时利用少量MIDI标注数据作为监督,从CQT特征中筛选出与音高相关的成分,抑制音色等无关信息;(3) 基于条件流匹配(CFM)的扩散解码器:将内容、音高和音色特征融合,生成高质量、保留下和声结构的歌唱语音。
- 与已有方法相比新在哪里:主要新意在于:明确将“处理残留和声”作为系统设计目标,而非假定输入为干净人声;创新性地将CQT引入SVC的音高建模环节,以处理复音场景;并设计了一个简单的随机采样器来优化CQT特征的学习。
- 主要实验结果如何:论文构建了一个包含70小时的多语种和声歌唱数据集进行测试。与基线模型(so-vits-svc, DDSP-SVC, SeedVC)相比,Poly-SVC在和声条件下的MOS(自然度)和SIM-MOS(音色相似度)得分显著更高(MOS: 3.75 vs. 最高基线3.35; SIM-MOS: 3.42 vs. 最高基线3.40)。消融实验显示,移除随机采样器(RS)或音色移位器(TS)均会导致性能下降。
- 实际意义是什么:该工作提升了SVC系统在真实世界不完美输入条件下的鲁棒性和可用性,使其能更好地处理从完整混音歌曲中直接分离的人声,对于音乐制作、翻唱等应用有直接价值。
- 主要局限性是什么:(1) 所用的“和声数据”是通过人声分离工具模拟生成的,并非真实录制的“原始带和声人声”,可能无法完全代表所有现实情况;(2) 评估完全依赖主观听感测试,缺乏客观的音高准确性或谐波失真量化评估;(3) 随机采样器的具体设计和作用机制描述不够详尽;(4) 未公开代码和模型,复现性存疑。
🏗️ 模型架构
Poly-SVC是一个端到端的歌唱语音转换框架,其整体架构如图1所示,包含训练和推理两个阶段。其核心思想是特征解耦与融合:从源语音和参考语音中分别提取内容、音高和音色特征,然后将它们融合并馈送给扩散模型以生成目标音色的歌唱语音。
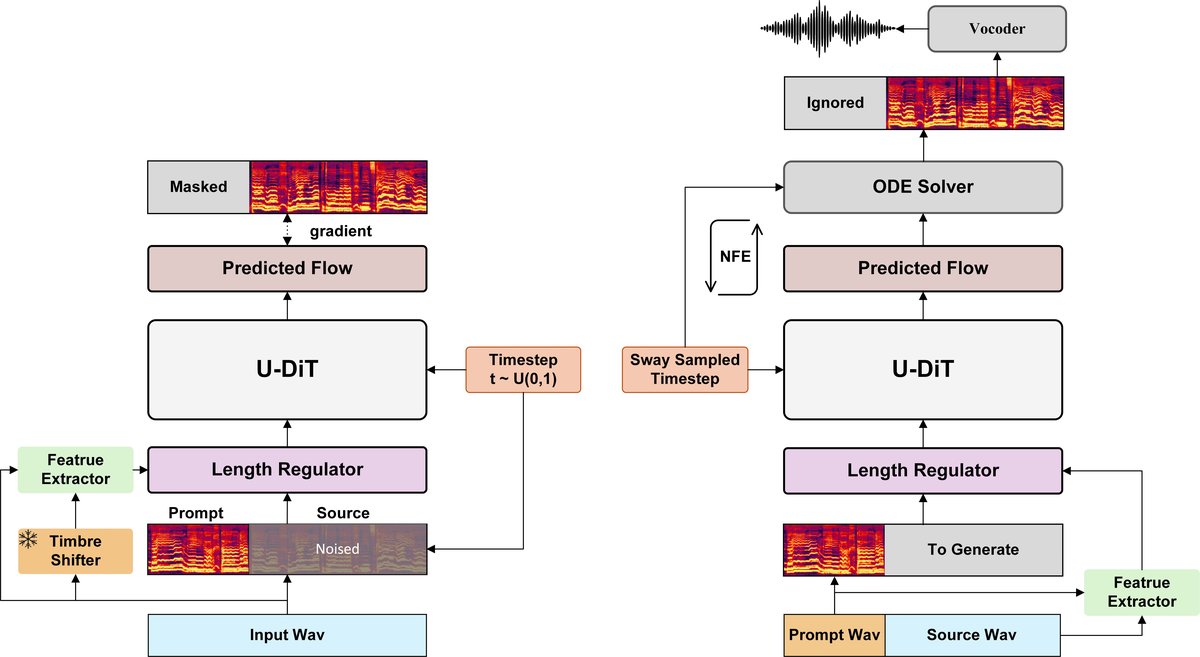 图1:Poly-SVC模型整体架构图。左侧为训练过程,右侧为推理过程。雪花图标表示冻结参数。
图1:Poly-SVC模型整体架构图。左侧为训练过程,右侧为推理过程。雪花图标表示冻结参数。
主要组件与数据流如下:
前端预处理:
- 输入音频被转换为梅尔频谱图作为声学表示。
- 音色移位器(Timbre Shifter):基于OpenVoice实现,用于对齐训练和推理时的音色分布,减少内容表示中的音色泄露。在推理时,它从提示音频中提取音色特征。
特征提取器(Feature Extractor):这是系统的核心,分别提取三种特征(如图2所示):
- 内容特征 (z_c):使用预训练的Whisper-small模型提取,提供语言内容的表示。
- 音色特征 (z_t):使用预训练的CampPlus说话人验证模型提取,提供稳定的音色嵌入。
- 音高特征 (z_p):这是本文的创新重点。为了避免传统F0提取器在和声场景下的失败,系统使用CQT(常数Q变换)频谱图作为音高的原始表示。CQT具有对数频率刻度,能更好地表示音乐中的音高结构,并天然支持同时表示多个音高(即和声)。一个CQT编码器(多层Transformer)将CQT矩阵编码为音高特征z_p。
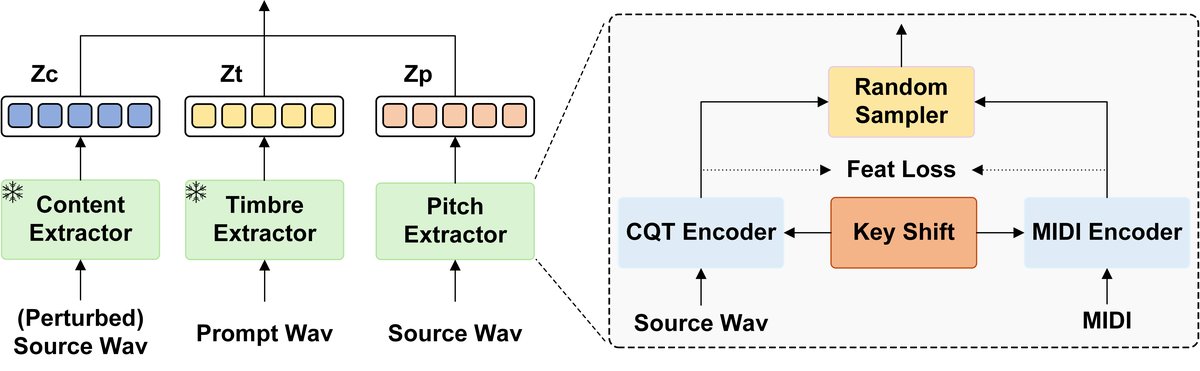 图2:特征提取器与随机采样器框架图。展示了内容、音高、音色特征的提取流程,以及随机采样器如何利用MIDI数据监督CQT编码器的学习。
图2:特征提取器与随机采样器框架图。展示了内容、音高、音色特征的提取流程,以及随机采样器如何利用MIDI数据监督CQT编码器的学习。
随机采样器(Random Sampler):这是一个训练时的关键模块(见图2)。其动机是CQT特征虽然包含了丰富的音高信息,但也混杂了音色等无关信息。随机采样器利用少量带有MIDI标注的平行数据(音频-MIDI对)来监督训练。
- 训练时:MIDI标签被编码为“理想”的音高特征。随机采样器计算CQT编码器输出的音高特征与MIDI编码器输出的特征之间的L1损失(公式1),迫使CQT编码器学习更纯净的、与音高相关的表示。
- 推理时:随机采样器不参与工作,系统直接使用从CQT特征中编码出的音高特征z_p,这使得系统能够自然地处理输入音频中的和声成分。
基于CFM的歌唱语音转换器(CFM-based Singing Voice Convertor):这是生成模型的主体。
- 特征融合与对齐:提取出的内容、音高、音色特征,以及用于指导的梅尔频谱图,都通过一个可学习的长度调节器进行时间对齐,然后融合。
- 条件流匹配(CFM)解码器:采用U-DiT(一个基于Diffusion Transformer的U型架构)作为去噪网络。训练时,模型学习将高斯噪声(x0)沿一条直线路径(公式2)逐步去噪成目标梅尔频谱图(x1),其预测的“速度场”(vt)受融合后的条件信息(c)控制。损失函数(公式2)旨在最小化预测速度与真实速度的差异。
- 推理过程:从随机噪声开始,通过ODE求解器,结合条件信息,迭代地预测并修正梅尔频谱图。论文提到使用了“sway sample timestep”(公式4)技巧来改善采样。
声码器(Vocoder):最后,将生成的梅尔频谱图通过一个在和声数据集上微调过的Firefly-GAN声码器,转换为最终的波形音频。
关键设计选择及其动机:
- 选择CQT而非F0:动机直接,为了解决和声场景下的多音高表示问题。
- 引入随机采样器:动机是纯化CQT特征,抑制其固有的音色信息泄露,使音高建模更专注。
- 采用CFM扩散模型:相比传统的GAN或VAE,扩散模型在生成高保真、多样化的声学特征方面表现更优,且与流匹配技术结合训练更稳定。
💡 核心创新点
- 面向残留和声的系统设计:与大多数假设输入为干净人声的SVC系统不同,Poly-SVC明确将“处理人声分离后残留的和声”作为核心设计目标,更贴近真实应用场景。
- 基于CQT的复音音高建模:创新性地将CQT频谱图引入SVC作为音高特征。CQT的对数频率分辨率使其能自然地、高保真地表示音乐中的主旋律和和声结构,克服了传统单音F0提取器在复音场景下的局限性。
- 随机采样器:提出一个简单有效的训练技巧,利用有限的MIDI标注数据,通过L1损失监督,引导CQT编码器从复杂的频谱图中学习并提取与音高高度相关的特征,同时抑制音色等干扰信息。
🔬 细节详述
- 训练数据:
- 语音数据:采用Emilia数据集(101k小时多语言语音)的一个子集进行常规语音转换训练。
- 歌唱数据:使用m4singer, OpenSinger, OpenCpop, PopBuTFy, VocalSet等多个干净的单旋律歌唱数据集(英语和中文)。其中m4singer包含一个带有MIDI标注的子集,用于随机采样器的监督训练。
- 和声数据:由于没有公开的带和声人声数据集,作者模拟了真实场景:使用UVR工具从70小时的公开伴奏歌曲中直接分离出人声(包含残留和声),并进行去混响处理,作为训练和评估的“和声条件”数据。评估集包含10个单旋律样本和10个多语言和声样本。
- 损失函数:
- 音高特征监督损失(公式1):
LRS = ||ECQT(CQT(x)) - EMIDI(MIDI)||_1,即CQT编码器输出与MIDI编码器输出之间的L1距离。 - CFM训练损失(公式2):
L_CFM(θ) = E_{t,q(x1),p(x0)} || vt(ψt(x0, x1), c) - d/dt ψt(x0, x1) ||^2,即预测速度场与真实路径导数之间的均方误差。
- 音高特征监督损失(公式1):
- 训练策略:论文中未详细说明学习率调度、warmup策略、batch size等具体训练超参数。只提及优化器为AdamW,峰值学习率1e-4,指数衰减至最小1e-5。
- 关键超参数:
- CQT参数:重采样率44.1kHz,跳长441(对应10ms),每八度12个频段,共84个频段。
- 特征提取器:CQT编码器和MIDI编码器均为多层Transformer。
- 声学模型:使用SeedVC中的U-DiT作为DiT模块。
- 训练硬件:未说明。
- 推理细节:
- 使用ODE求解器结合“sway sample timestep”(公式4)进行采样。
- 采样步数(NFE)未具体说明。
- 正则化/稳定训练技巧:随机采样器可视为一种正则化,通过外部监督(MIDI)约束特征空间。
📊 实验结果
论文主要通过主观评估(MOS和SIM-MOS)比较了Poly-SVC与三个基线模型(so-vits-svc, DDSP-SVC, SeedVC)。实验在单旋律和和声两种条件下进行。
主要对比结果(表1):
| 模型 | 单旋律 MOS | 单旋律 SIM-MOS | 和声 MOS | 和声 SIM-MOS |
|---|---|---|---|---|
| Ground Truth | 4.12 ± 0.11 | - | 3.92 ± 0.11 | - |
| so-vits-svc | 3.57 ± 0.14 | 3.15 ± 0.13 | 1.64 ± 0.10 | 2.08 ± 0.09 |
| DDSP-SVC | 3.83 ± 0.13 | 3.33 ± 0.11 | 2.98 ± 0.11 | 2.82 ± 0.10 |
| SeedVC | 3.85 ± 0.13 | 3.74 ± 0.10 | 3.35 ± 0.12 | 3.40 ± 0.08 |
| Poly-SVC (w/o TS) | 3.96 ± 0.13 | 3.66 ± 0.11 | 3.71 ± 0.10 | 3.32 ± 0.08 |
| Poly-SVC (w/o RS) | 3.92 ± 0.13 | 3.71 ± 0.12 | 3.62 ± 0.13 | 3.36 ± 0.09 |
| Poly-SVC (完整) | 3.98 ± 0.12 | 3.78 ± 0.11 | 3.75 ± 0.10 | 3.42 ± 0.09 |
关键结论与图表证据:
- 在和声条件下优势显著:Poly-SVC(3.75 MOS)大幅领先最强基线SeedVC(3.35 MOS),表明其能有效处理和声干扰,生成更自然、保留下和声结构的歌声。
- 在单旋律条件下也略有提升:Poly-SVC(3.98 MOS)略高于SeedVC(3.85 MOS),可能得益于其对特殊发声(如气泡音)更好的建模能力。
- 消融实验:
- 移除音色移位器(TS):SIM-MOS显著下降(和声条件:3.32 vs 3.42),表明TS在抑制音色泄露、对齐分布方面很重要。
- 移除随机采样器(RS):MOS和SIM-MOS均下降,尤其在和声条件下MOS下降更明显(3.62 vs 3.75),证明RS能有效引导音高建模,减少噪声和音色伪影。
- 频谱图定性对比(图3):
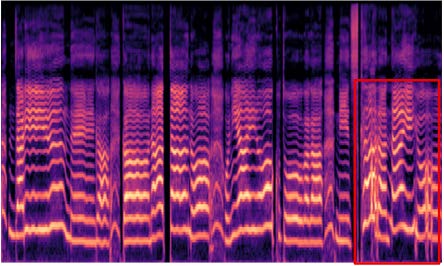 图3:和声条件下频谱图对比。 (a) 是包含多条旋律线的输入;(b) SeedVC仅捕捉主旋律,丢失和声结构,且在红框处有明显音高预测错误;(c) Poly-SVC成功重建了主旋律和和声成分。
图3:和声条件下频谱图对比。 (a) 是包含多条旋律线的输入;(b) SeedVC仅捕捉主旋律,丢失和声结构,且在红框处有明显音高预测错误;(c) Poly-SVC成功重建了主旋律和和声成分。
⚖️ 评分理由
- 学术质量(6.0/7):创新性(2.0/3):解决问题的角度新颖(面向残留和声),将CQT引入SVC音高建模是合理且有效的工程创新,但非理论突破。技术正确性(2.0/2):模型设计合理,各模块作用清晰,实验能自洽地验证假设。实验充分性(1.5/1):构建了专门的测试集,并进行了模型对比和消融实验,但评估完全依赖主观指标,缺乏客观度量,且未与最新(如2024-2025年)的SOTA模型对比。证据可信度(0.5/1):主观评估流程描述详细,但“和声数据”是模拟而非真实录制,可能影响结论的泛化性。
- 选题价值(1.5/2):前沿性(0.5/1):针对SVC落地中的实际痛点,具有实用前沿性。潜在影响与应用空间(1.0/1):直接提升音乐相关应用(如AI翻唱、伴奏重混)的质量,影响明确。
- 开源与复现加成(0.0/1):论文未提供核心代码、模型权重或详细的训练配置(如数据处理脚本、超参数列表),复现依赖大量未明确说明的细节,加成为零。