📄 PICOAUDIO2: Temporal Controllable Text-to-Audio Generation with Natural Language Description
#音频生成 #扩散模型 #文本到音频 #时间控制
✅ 7.5/10 | 前25% | #音频生成 | #扩散模型 | #文本到音频 #时间控制
学术质量 6.0/7 | 选题价值 1.0/2 | 复现加成 0.5 | 置信度 中
👥 作者与机构
- 第一作者:Zihao Zheng†(†标注表明该作者贡献部分在实习期间完成,其正式单位为上海交通大学MoE人工智能重点实验室X-LANCE实验室和上海AI实验室)
- 通讯作者:Mengyue Wu(上海交通大学MoE人工智能重点实验室X-LANCE实验室)
- 作者列表:Zihao Zheng(上海交通大学X-LANCE实验室 & 上海AI实验室)、Zeyu Xie(未说明具体单位,但根据作者排序和实验室隶属,推测可能同属X-LANCE或上海AI实验室)、Xuenan Xu(上海交通大学X-LANCE实验室 & 上海AI实验室)、Wen Wu(上海AI实验室)、Chao Zhang(上海AI实验室)、Mengyue Wu(上海交通大学X-LANCE实验室)
💡 毒舌点评
亮点:论文在数据处理上“两条腿走路”,既用LLM增强仿真数据的自然性,又用TAG模型从真实数据中挖掘时间信息,这种务实的混合训练策略有效弥合了合成与真实数据的鸿沟。短板:虽然声称在时序控制上达到SOTA,但核心生成骨架(DiT)是沿用已有工作(EzAudio),而时间戳矩阵的概念也源自其前身PicoAudio,因此“新瓶装旧酒”的成分略重,原创性打了点折扣。
📌 核心摘要
PicoAudio2旨在解决当前可控文本到音频(TTA)生成模型在音频质量(常依赖合成数据)和控制灵活性(受限于固定词汇)方面的不足。该方法的核心是提出一套结合仿真数据和真实数据(通过LLM和TAG模型标注时间)的混合数据处理流程,并设计了一个新颖的生成框架,该框架同时处理粗粒度的自然语言描述(TCC)和细粒度的、包含具体事件描述及时间戳的矩阵(TDC)。与现有方法相比,PicoAudio2首次实现了对开放域自由文本事件的细粒度时间控制,同时保持了高质量音频生成。实验证明,PicoAudio2在时间可控性(Segment-F1达0.857,多事件F1达0.771)和音频质量(IS达12.347,CLAP达0.383)上均优于AudioComposer、MAA2等基线,尤其在多事件时间对齐任务上表现突出。其实际意义在于为音视频内容创作、虚拟现实等需要精确音频时序编排的场景提供了更强大的工具。主要局限在于当前模型主要在时间上不重叠的真实数据子集上训练,因此对事件重叠场景的时间控制能力有限,这也是作者指出的未来工作方向。
🏗️ 模型架构
PicoAudio2的整体架构(如图2所示)基于扩散Transformer(DiT),旨在将文本语义和细粒度的时间控制信息融合,生成高质量的音频。
完整输入输出流程:
- 训练阶段:输入为音频波形、时间粗描述(TCC,如“a dog barks and a man speaks”)和时间细描述(TDC,包含事件描述和时间戳,如“dog barking at 1-3s, man speaking at 5-7s”)。音频经VAE编码为潜变量
A;TCC经冻结的Flan-T5文本编码器得到语义特征C;TDC经时间戳编码器得到时间戳矩阵T。三者输入扩散骨干网络进行训练。 - 推理阶段:用户可提供TCC或TDC。若只提供TCC,系统会通过一个外部的LLM将其转化为TDC(如图3所示)。之后流程与训练类似:
C来自TCC,T来自TDC(若无TDC,则T使用一个固定的嵌入序列)。模型通过扩散过程从噪声生成音频潜变量A,再经VAE解码为波形。
主要组件及数据流:
- VAE(变分自编码器):采用冻结的EzAudio VAE。编码器将原始音频波形压缩为潜变量
A;解码器在推理时将生成的A还原为波形。功能是降低扩散模型的计算维度。 - 文本编码器(Flan-T5):冻结的预训练语言模型。负责两重任务:1) 编码TCC得到全局语义特征
C;2) 在时间戳编码器中,将TDC里的单个事件描述编码为事件级特征a。 - 时间戳编码器:PicoAudio2的核心创新之一。它接收TDC,并利用Flan-T5编码其中的每个事件描述得到特征
a_i���然后,根据每个事件i的发生时间区间,在对应的时间步t上将a_i累加到矩阵T的对应位置(公式:T_t = Σ_i a_i if event i occurs at t, else 0),生成与音频潜变量A时间轴对齐的特征矩阵T。对于没有TDC的弱时间标注数据,T被设为一个固定嵌入向量。 - 扩散骨干网络(Diffusion Transformer, DiT):24层Transformer,是生成的核心。数据流如下:
- 音频潜变量
A首先通过自注意力层(配合处理扩散时间步τ的AdaLN)进行内部建模。 - 然后,
A与时间戳矩阵T在时间维度上拼接(Concat(A, T))。这一步是融合细粒度时间信息的关键,使得时间信号能够直接影响后续的注意力计算。 - 拼接后的特征通过交叉注意力层,与文本语义特征
C进行交互,从而将全局语义与细粒度时间对齐信息结合。 - 最后通过前馈网络(FFN,配合AdaLN)输出。
- 音频潜变量
- 训练与推理:训练采用标准的扩散损失(速度预测目标)。推理时使用Classifier-Free Guidance(CFG)来增强文本条件。
关键设计选择:
- 冻结编码器:VAE和Flan-T5在训练时冻结,专注于训练扩散骨干和时间戳编码器,这降低了训练成本并利用了预训练模型的强大表征能力。
T与A的拼接:将时间特征矩阵T与音频特征A在通道维度拼接,然后一起送入交叉注意力与文本特征交互。这种设计使得模型可以在融合了精确时间信息的“增强特征”上进行语义理解,比单纯将时间信息作为额外条件更紧密。- 对弱时间数据的兼容性:当输入为弱时间数据(TCC)时,
T使用固定嵌入,这使得同一个模型架构可以处理两种质量的数据,增加了训练灵活性。
💡 核心创新点
混合数据处理管道:
- 是什么:设计了针对仿真数据和真实数据的两套独立处理流程,最终统一为音频-TCC-TDC三元组形式,用于训练。
- 局限:以往方法要么只用仿真数据(如AudioComposer),质量差;要么只用真实数据但缺乏精确时间标注。
- 如何起作用:仿真数据管道利用AudioTime生成精确的合成音频-时间对,并通过LLM将类别标签转为自由文本。真实数据管道则利用LLM分解描述,并用TAG模型估计时间,再通过过滤保证数据质量。
- 收益:结合了仿真数据的时间精确性和真实数据的分布真实性,消融实验(表4)证明了混合训练对音质和时控性能的全面提升。
基于自由文本描述的时间戳矩阵:
- 是什么:时间戳矩阵
T的每个时间步的特征,由在该时间步发生的所有事件的自由文本描述的嵌入向量求和得到。 - 局限:前作PicoAudio的
T由预定义类别标签映射而来,无法处理开放词汇的自由文本。 - 如何起作用:通过Flan-T5将自然语言事件描述编码为向量,再按时间戳填充到矩阵中。这使得
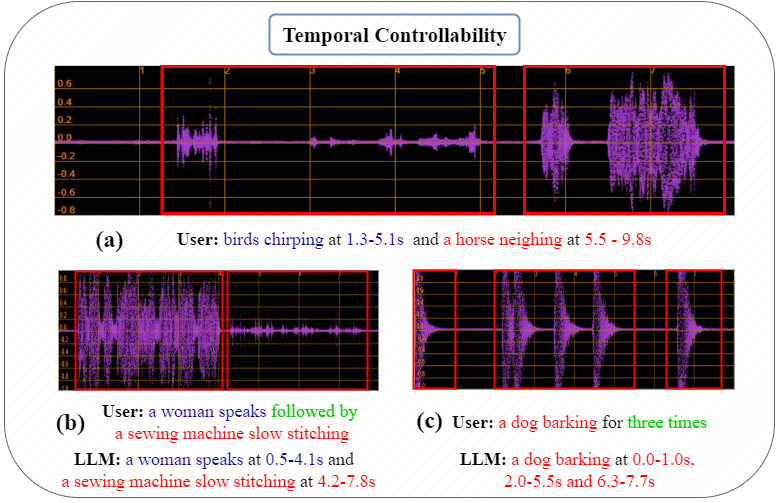
T既编码了“何时”,又编码了“是什么(用自然语言)”。 - 收益:实现了对任意自然语言描述的事件进行精确的时间控制,突破了固定词汇表的限制,如图3所示,用户可以输入非常灵活的时序指令。
- 是什么:时间戳矩阵
架构解耦与统一:
- 是什么:模型架构统一处理“时间强数据”(有TDC)和“时间弱数据”(仅有TCC)。
- 局限:许多时控模型无法处理无时间标注的数据。
- 如何起作用:当没有TDC时,将
T替换为固定嵌入。这使得模型可以利用所有可用的音频-文本对进行训练,包括那些没有时间标注的大量现有数据集。 - 收益:增强了模型的泛化能力和对多样化数据的适应性。
🔬 细节详述
- 训练数据:
- 仿真数据:约64K条音频,最长10秒,包含1-4个事件,源自AudioTime方法并经过增强(标签转自由文本)。
- 真实数据:约113K条“时间强数据”(来自AudioCaps和WavCaps-ASSL子集,经处理得到TCC-TDC)和约106K条“时间弱数据”(原始的音频-文本对)。训练时两者采样比为1:2(弱:强)。
- 损失函数:标准扩散损失,采用速度(velocity)预测目标。
- 训练策略:
- 优化器:未明确说明,但提到权重衰减为
1e-6。 - 学习率:最大学习率
1e-4,线性衰减。 - 训练轮数:50个epoch。
- 训练硬件:未说明。
- 优化器:未明确说明,但提到权重衰减为
- 关键超参数:
- 时间分辨率:时间戳矩阵
T的分辨率为20ms。 - 模型大小:DiT骨干网络包含24层,16个注意力头,隐藏维度为1024。
- 时间分辨率:时间戳矩阵
- 推理细节:
- 分类器自由引导(CFG)尺度:7.5。
- 当输入仅为TCC时,使用LLM(具体型号未说明)将其转换为TDC。
- 正则化/稳定训练技巧:未明确提及。采用了残差连接和自适应层归一化(AdaLN)来稳定Transformer训练。
📊 实验结果
主要Benchmark与数据集:主要在AudioCaps测试集和其子集AudioCaps-DJ(无时间重叠或遗漏的样本)上评估。
主要对比指标与结果(关键数据见下表):
- 一般音频质量:使用FD↓、KL↓、IS↑、CLAP↑、MOS-Q↑。PicoAudio2在所有音频质量指标上与主流模型(如AudioLDM2, Tango2, MAA2)相当或更优。例如,在AudioCaps上,其IS(12.347)和CLAP(0.383)均为最佳。
- 时间可控性:使用Seg-F1↑和MOS-T↑。PicoAudio2在此方面表现最优。在最具挑战性的AudioCaps-DJ多事件子集上,其Seg-F1-ME达到0.771,远超最强基线AudioComposer的0.613。MOS-T得分4.15,也显著高于其他方法(最高为AudioComposer的3.80)。
| 模型 | FD↓ | KL↓ | IS↑ | CLAP↑ | MOS-Q↑ | Seg-F1↑ | Seg-F1-ME↑ | MOS-T↑ |
|---|---|---|---|---|---|---|---|---|
| AudioCaps-DJ | ||||||||
| AudioLDM2 | 28.982 | 2.447 | 9.333 | 0.340 | 2.77 | 0.644 | 0.396 | 2.05 |
| Tango2 | 37.315 | 2.534 | 10.844 | 0.365 | 3.49 | 0.659 | 0.433 | 2.90 |
| MAA2 | 43.407 | 2.364 | 9.427 | 0.351 | 3.30 | 0.647 | 0.434 | 2.60 |
| AudioComposer | 46.833 | 3.002 | 6.202 | 0.254 | 2.47 | 0.690 | 0.613 | 3.80 |
| PicoAudio2 | 39.961 | 2.618 | 12.253 | 0.370 | 3.29 | 0.857 | 0.771 | 4.15 |
| PicoAudio2 (w/o T) | 37.861 | 2.626 | 11.610 | 0.373 | 2.83 | 0.659 | 0.432 | 2.42 |
 (注:原论文中此位置可能为其他图表,但根据提供的描述“Fig. 3”已贴出,此处不再重复。上表已完整呈现核心对比数据)
(注:原论文中此位置可能为其他图表,但根据提供的描述“Fig. 3”已贴出,此处不再重复。上表已完整呈现核心对比数据)
关键消融实验:
- 移除时间戳矩阵(w/o T):时间可控性指标(Seg-F1从0.857降至0.659, Seg-F1-ME从0.771降至0.432)急剧下降,证明时间戳矩阵是实现精确控制的核心。同时,部分音频质量指标(如IS)也下降,说明解耦时间信息有助于提升生成多样性。
- 仅用仿真数据训练:在表4中,对比“Simulation”与“Simulation+Real”,加入真实数据后,FD从41.859降至39.961,CLAP从0.256升至0.370,Seg-F1从0.589大幅提升至0.857。这验证了混合数据策略的巨大成功。
⚖️ 评分理由
- 学术质量:6.0/7。论文工作系统、完整,解决了现有TTA时控模型的两个真实痛点(数据与灵活性)。技术方案合理,实验设计充分,包括主实验、消融实验、主客观评估,结论可信。扣分点在于:1) 核心组件(DiT,时间戳矩阵概念)并非完全原创,属于对前作的改进和组合;2) 在部分音频质量指标(如FD)上并未全面超越最强基线(如AudioLDM2)。
- 选题价值:1.0/2。可控音频生成,特别是时间可控,是提升AI生成音频可用性的关键环节,有明确的实用价值(如视频配音、游戏音效)。但该任务相对于语音识别、语音合成等更通用的任务,受众和影响力相对有限。
- 开源与复现加成:+0.5/1。论文提供了相对详实的训练细节(学习率、epoch、采样比、模型层数等)、数据规模和消融实验配置,为复现提供了基础。但代码、预训练模型权重、以及用于生成仿真数据的具体脚本均未提及开源,因此只能给予中等加成。