📄 Pianoroll-Event: A Novel Score Representation for Symbolic Music
#音乐生成 #自回归模型 #数据集 #模型评估
✅ 6.5/10 | 前25% | #音乐生成 | #自回归模型 | #数据集 #模型评估
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0 | 置信度 高
👥 作者与机构
- 第一作者:未说明(论文标注了“Equal contribution”,但未明确哪位是第一作者)
- 通讯作者:未说明(论文标注了“†Corresponding authors”,对应作者为Boyu Cao和Qi Liu)
- 作者列表:Lekai Qian(华南理工大学未来技术学院)、Haoyu Gu(华南理工大学未来技术学院)、Dehan Li(华南理工大学未来技术学院)、Boyu Cao(华南理工大学未来技术学院)、Qi Liu(华南理工大学未来技术学院)
💡 毒舌点评
亮点在于将钢琴卷帘的“空间感”与离散事件的“效率”巧妙结合,设计出的四种事件类型逻辑自洽,且在多个主流自回归模型上都展现出稳定的性能提升,说明方法具有一定的普适性。短板是创新的增量性较强,更像是对现有表示的“精装修”而非“新建材”,且完全未开源,对于旨在复现和比较的研究者来说不够友好。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据���:使用MuseScore数据集,但论文未说明该数据集的公开获取方式。
- Demo:未提及。
- 复现材料:论文提供了一些训练超参数(学习率、批大小、轮数、模型配置)和硬件信息(RTX 4090),但关键编码参数(帧长L、块高h)、优化器、具体推理策略等细节缺失,复现存在较大困难。
- 论文中引用的开源项目:论文引用了MIDI [3]、REMI [8]、Compound Word [9]、BPE [11]、MusicBERT/OctupleMIDI [10] 等作为基线或相关工作,但未明确依赖的具体开源实现。
- 总体而言,论文未提及开源计划。
📌 核心摘要
- 本文针对符号音乐表示中网格表示(如钢琴卷帘)数据稀疏、编码效率低,以及离散事件表示(如REMI)难以捕获结构不变性和空间局部性的互补局限,提出了一种新的编码方案Pianoroll-Event。
- 该方法核心是将钢琴卷帘表示先进行时间分帧,再沿音高维度分块,然后通过四种互补的事件类型(帧事件、间隙事件、模式事件、音乐结构事件)将稀疏的块信息高效地编码为一个离散事件序列。
- 与已有方法相比,Pianoroll-Event首次将基于帧的压缩(处理连续空块)与基于块的模式编码相结合,并在序列长度和词表大小之间取得了更优的平衡。
- 实验结果表明,在GPT-2、Llama、LSTM等多种架构上,使用该表示的模型在客观指标(如JS相似度)和主观评估(MOS)上均优于基线方法。例如,在GPT-2-Large模型上,其JS相似度达到68.86,显著高于REMI(35.85)和ABC表示(65.18)。编码效率分析显示,其预算感知难度指数(BDI)最低,相比ABC表示提升了7.16倍。
- 该工作为符号音乐生成提供了一个更高效、保真度更高的统一表示框架,有助于提升生成音乐的质量和模型训练效率。
- 主要局限性在于该表示依赖固定的帧和块大小,对极度不规则的节奏或非标准音域可能灵活性不足;此外,论文未提供开源代码,限制了其直接应用和后续研究。
🏗️ 模型架构
Pianoroll-Event本身不是一个神经网络模型,而是一个符号音乐表示的编码方案。其“架构”指的是将原始的钢琴卷帘矩阵转化为离散事件序列的流程。
完整输入输出流程:
- 输入:一个二值化的钢琴卷帘矩阵
P ∈ {0, 1}^{H×T},其中 H=88(标准钢琴音高),T 为时间步数。 - 输出:一个离散事件序列
S,由四种事件类型的令牌(token)拼接而成。
主要组件与流程(参照图1与算法1):
- 时间分帧(Temporal Framing):将整个钢琴卷帘
P沿时间轴切分成一系列长度固定为L的帧{F1, F2, ..., FN}。这保留了局部的时间依赖性,如和弦与旋律的连续性。 - 帧内音高分块(Block Partitioning):对于每个帧
Fi,将其沿音高维度切分成固定大小为h的块{B1, B2, ..., BK}。每个块Bi,j是一个h×L的子矩阵。 - 事件生成(Event Generation):对每个帧内的块序列进行压缩和编码,生成四种事件:
- 帧事件(Frame Event):标记帧的起始位置,并压缩帧开头的连续空块。
- 间隙事件(Gap Event):用一个令牌
Gap(r)高效表示块序列中连续的r个空块。 - 模式事件(Pattern Event):将非空块
Bi,j映射到一个唯一的令牌Pattern(Bi,j),精确保存该块内的音符激活模式。 - 音乐结构事件(Musical Structure Events):在小节边界等位置插入,编码节拍、拍号等元数据。
- 序列拼接:所有帧的编码结果与音乐结构事件按时间顺序拼接,形成最终的事件序列
S(公式2)。
关键设计选择与动机:
- 保留帧结构:动机是维持音乐的时间框架和局部结构,便于模型学习时序逻辑。
- 块化压缩:动机是利用钢琴卷帘的稀疏性。大部分块是空的,可以用单个“间隙事件”替代多个零值,大幅提升编码效率。
- 互补的事件类型:帧事件提供时间锚点,模式事件捕获局部和弦/旋律片段,间隙事件处理稀疏性,音乐结构事件提供全局乐理上下文。这种分工确保了编码既紧凑又信息丰富。
架构图:
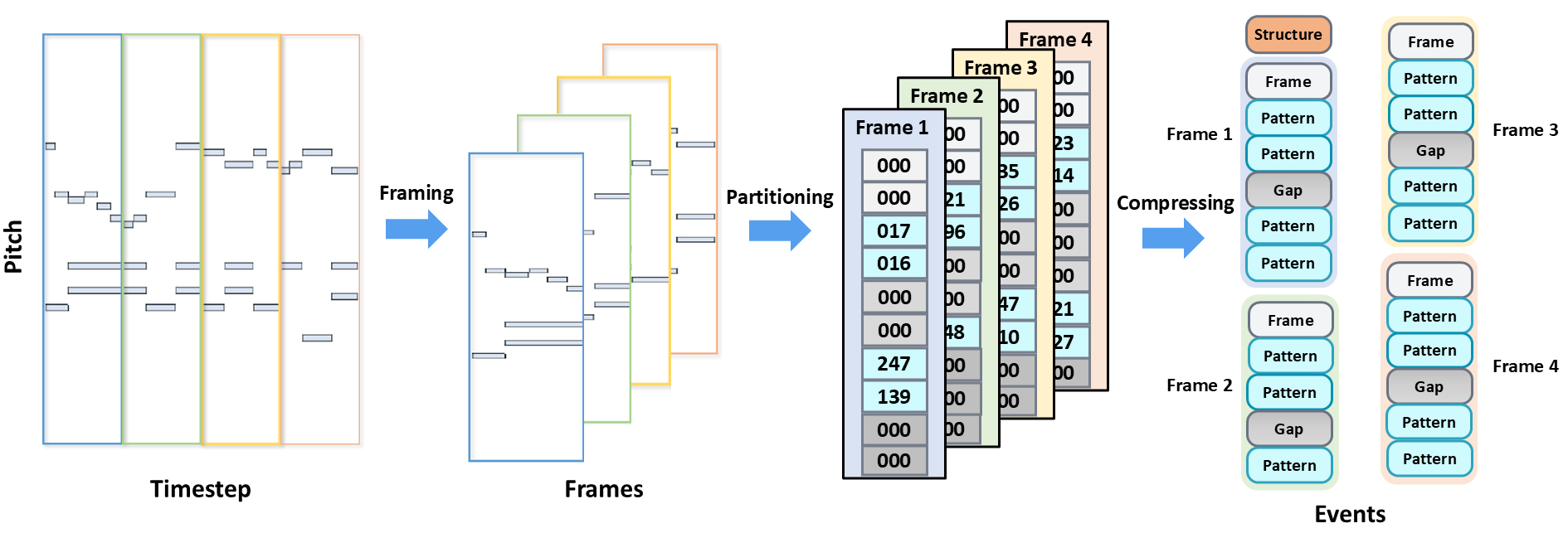 图中清晰展示了从钢琴卷帘输入,经过帧分割、块划分,再通过四种事件类型进行编码,最终生成紧凑事件序列的全过程。
图中清晰展示了从钢琴卷帘输入,经过帧分割、块划分,再通过四种事件类型进行编码,最终生成紧凑事件序列的全过程。
💡 核心创新点
- 提出Pianoroll-Event统一编码方案:这是最核心的创新。它不是对现有表示的简单修改,而是设计了一个新的编码框架,将连续时间的钢琴卷帘表示(网格结构)系统性地转化为离散事件序列。之前方法的局限:网格表示(如原始Pianoroll)数据稀疏、计算冗余;离散事件表示(如REMI)丢失了空间局部性。如何起作用:通过“分帧-分块-事件化”的流程,既保留了帧间的时间依赖和帧内的空间(音高)模式,又实现了高效压缩。收益:在序列长度和词表大小间取得最优平衡(BDI最低),并在多种生成模型上验证了其优越性。
- 设计四种互补的事件类型:创新地定义了Frame, Gap, Pattern, Musical Structure四类事件,各有明确语义。之前方法的局限:早期MIDI事件序列冗长;REMI等虽压缩但令牌语义混合或模糊。如何起作用:每种事件解决一个特定问题:帧边界、空区域压缩、非空模式编码、全局结构。收益:编码后的序列语义清晰,每个令牌都有明确含义,有利于模型学习。
- 提出预算感知难度指数(BDI)评估指标:创新性地提出了一个综合评估编码效率的指标
BDI = ℓ^2 * √V。之前方法的局限:通常只看序列长度或词表大小,不能全面反映对Transformer模型计算复杂度和参数效率的影响。如何起作用:该指标同时考虑了自注意力机制的二次复杂度(与序列长度平方相关)和词表过大导致的参数稀释效应(与词表大小平方根相关)。收益:能更准确地评估不同表示方案对下游模型的计算压力,证明了Pianoroll-Event的优化效果。
🔬 细节详述
- 训练数据:使用MuseScore数据集,包含14万首双轨钢琴谱,时长1-5分钟。将乐谱转换为多热数组钢琴卷帘,时间分辨率为1/16拍。
- 损失函数:未在论文中明确说明。通常对于自回归音乐生成,使用标准的下一个令牌预测交叉熵损失。
- 训练策略:
- 优化器:未说明。
- 学习率:1e-4。
- Batch size:256。
- 训练轮数:20 epochs。
- 学习率调度:未说明。
- 硬件:NVIDIA RTX 4090 GPU。
- 训练时长:未说明。
- 关键超参数:
- 模型架构:测试了GPT-2-Small(4层,512隐藏维度),GPT-2-Large(8层,768隐藏维度),Llama(6层,768隐藏维度),LSTM(4层,512隐藏维度)。
- Pianoroll-Event参数:帧长
L、块高h的具体值未在正文中给出,但属于编码的关键超参数。
- 推理细节:
- 解码策略:未说明(如贪心、束搜索、核采样)。
- 温度、beam size:未说明。
- 生成时长:目标生成40-90秒的音乐片段。
- 正则化或稳定训练技巧:未说明。
📊 实验结果
论文在编码效率、生成质量和消融研究三个方面进行了全面实验。
编码效率对比(表1)
方法 平均序列长度 (ℓ) 词表大小 (V) BDI (↓) 相对Ours (↓) Ours 749.8 347 1.048 × 10^7 1.00× REMI 1339.7 330 3.261 × 10^7 3.11× MIDILike 1398.9 448 4.143 × 10^7 3.96× REMI-BPE 317.8 20,000 1.429 × 10^7 1.36× ABC Notation 2575.0 128 7.504 × 10^7 7.16× 结论:Pianoroll-Event(Ours)在BDI指标上显著优于所有基线,实现了序列长度与词表大小的最佳折中。相比长序列的ABC表示,效率提升7.16倍;相比使用BPE压缩的REMI-BPE,效率提升1.36倍。 生成质量对比(以GPT-2-Large为例,表3)
方法 PR (↑) GC (↑) SC (↑) JS (↑) MOS (↑) REMI 0.751 0.992 0.710 35.85 1.07 REMI-BPE 0.286 0.815 0.878 55.27 2.93 MIDI-Event 0.748 0.855 0.709 40.53 2.03 CP 0.719 0.726 0.799 49.93 3.00 Octuple 0.078 0.916 0.909 50.61 2.33 ABC 0.261 0.997 0.966 65.18 2.00 Ours 0.742 0.936 0.962 68.86 4.27 GT 0.583 0.980 0.943 - 4.83 结论:在GPT-2-Large模型上,Pianoroll-Event在综合指标JS相似度和主观MOS上均取得最佳,分别达到68.86和4.27,远超大多数基线,且与地面真实(GT)的MOS差距最小。在多节奏一致性(GC)和尺度一致性(SC)上也保持很高水平。 消融研究(GPT-2-Large,表6)
方法 (组件) JS (↑) MOS (↑) P (仅模式事件) 50.16 2.20 PF+ (P + 帧压缩起始) 60.92 3.20 PF (PF+ + 帧压缩结束) 62.96 3.67 Proposed (PF + 间隙事件) 68.86 4.07 结论:每添加一个编码组件(压缩首部空块、去除尾部空块、引入间隙令牌),模型的JS相似度和MOS都稳步提升,证明四种事件类型的设计都是必要且有效的。
⚖️ 评分理由
- 学术质量:6.5/7 - 论文创新了一种融合网格与离散事件优点的符号音乐表示方法,技术方案完整、清晰。实验设计严谨,在多个模型架构上进行了充分的对比和消融分析,数据支持其结论。创新点属于领域内扎实的渐进式改进,未达到理论或范式上的重大突破。
- 选题价值:1.5/2 - 符号音乐表示是音乐生成领域的关键基础问题,优化表示方法能直接提升生成效率和质量,具有明确的理论和应用价值。该工作对该特定领域的研究者有较高参考价值。
- 开源与复现加成:0/1 - 论文未提供任何代码、预训练模型或详细复现指南,极大地阻碍了后续工作的验证和扩展,因此此项得分为0。